







一文读懂混合专家模型(MoE)
概述
混合专家模型(Mixture of Experts,MoE)是一种机器学习和深度学习中的模型架构,它通过多个“专家”子模型来处理不同类型的输入数据或任务。在MoE模型中,输入数据通过一个“门控网络”(gating network)来选择和分配给最适合的专家模型,最终的预测结果由这些专家的输出加权合并而成。这种结构尤其适用于复杂任务或大规模数据,因为不同的专家可以专注于数据的特定特征或任务的某个方面,从而提升整体模型的效率和性能。
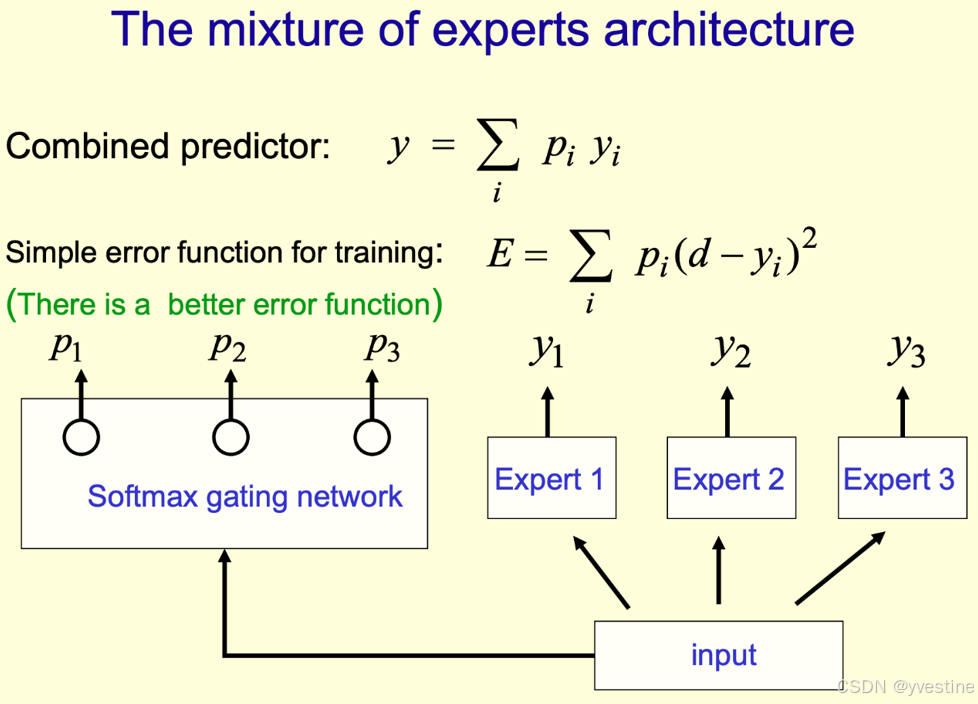
- 专家网络(Experts):MoE的核心是多个“专家”模型,每个专家是一个独立的子模型或网络,负责对不同类型的输入或特定任务进行处理。每个专家可以是神经网络、决策树、支持向量机等模型,视任务需求而定。
- 门控网络(Gating Network):门控网络在模型运行时决定输入应该分配给哪些专家。门控网络基于输入的特征生成一个权重分布,用于选择和组合专家的输出。这通常是一个小型神经网络,它会输出一个概率分布,指示每个专家被选择的权重或激活的程度。
- 加权输出:经过门控网络的选择和分配后,每个专家对输入产生一个预测,最终结果由门控网络给出的权重对专家的预测进行加权求和得到。这使得MoE能够在保持性能的同时降低计算成本,因为门控网络可以选择性地激活少数专家。
MoE的工作原理可以概括为“任务分解-专家处理-结果汇总”。具体来说,当模型接收到一个输入时,门控网络首先分析输入数据的特征,然后根据这些特征决定哪些专家网络应该被激活以处理该输入。每个被激活的专家网络都会独立地处理输入数据的一部分,并产生相应的输出。最后,所有专家网络的输出会被汇总起来,形成最终的模型输出。
大模型时代的MoE
模型规模是提高模型质量的最重要因素之一。给定固定的计算预算,训练较大的模型(使用较少的步骤)要比训练较小的模型(使用较多的步骤)更好。
混合专家使模型能够以更少的计算量进行预训练,这意味着可以以与密集模型相同的计算预算大幅扩大模型或数据集的大小。特别是,MoE 模型在预训练期间应该可以更快地达到与其密集模型相同的质量。
以Transformer为例,解释MoE究竟是什么。
Transformer中,MoE主要由两个主要元素组成:
- 使用稀疏 MoE 层代替密集前馈网络 (FFN) 层。MoE 层具有一定数量的“专家”(例如 8 个),其中每个专家都是一个神经网络。实际上,专家是 FFN,但它们也可以是更复杂的网络,甚至是 MoE 本身,从而形成分层 MoE!
- 门网络或路由器,决定将哪些令牌发送给哪个专家。我们可以将一个令牌发送给多个专家,如何将令牌路由给专家是使用 MoE 时需要做出的重大决定之一 。路由器由学习到的参数组成,并与网络的其余部分同时进行预训练。

MoE的优缺点
优点
- 与传统的Dense模型相比,MoE能够在远少于前者所需的计算资源下进行有效的预训练,计算效率更高、速度更快,进而使得模型规模得到显著扩大,获得更好的AI性能。
- 由于MoE在模型推理过程中能够根据输入数据的不同,动态地选择不同的专家网络进行计算,这种稀疏激活的特性能够让模型拥有更高的推理计算效率,从而让用户获得更快的AI响应速度。
- 由于MoE架构中集成了多个专家模型,每个专家模型都能针对不同的数据分布和构建模式进行搭建,从而显著提升大模型在各个细分领域的专业能力,使得MoE在处理复杂任务时性能显著变好。
- 针对不同的专家模型,AI研究人员能够针对特定任务或领域的优化策略,并通过增加专家模型数量、调整专家模型的权重配比等方式,构建更为灵活、多样、可扩展的大模型。
缺点
-
由于MoE需要把所有专家模型都加载在内存中,这一架构对于显存的压力将是巨大的,通常涉及复杂的算法和高昂的通信成本,并且在资源受限设备上部署受到很大限制。
-
此外,随着模型规模的扩大,MoE同样面临着训练不稳定性和过拟合的问题、以及如何确保模型的泛化性和鲁棒性问题、如何平衡模型性能和资源消耗等种种问题,等待着大模型开发者们不断优化提升。

















 8011
8011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









