






学习之初
神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向--深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
医学影像分割是医学图像处理领域的一个重要任务,它旨在将图像中的不同组织或结构进行精确的划分。近年来,随着深度学习技术的发展,基于卷积神经网络的医学影像分割方法取得了显著的进步。nnUNet(nn-U-Net)是其中之一,是一个为医学影像分割任务量身打造的深度学习框架。
其基于U-Net架构的深度学习模型,特别适用于医学影像分割任务。U-Net是一种编码器-解码器结构,通过跳跃连接将低层次的特征和高层次的特征相结合,从而实现精确的像素级分割。nnUNet在U-Net的基础上进行了改进,包括数据预处理、模型训练、后处理等方面,使得其在医学影像分割任务上取得了优异的表现。
其具有以下几个特点:
自适应框架:nnUNet能够根据具体的医学图像分割任务自动调整模型结构、训练参数等,从而避免了繁琐的手工调参过程。
自动化流程:nnUNet包含了从数据预处理到模型训练、验证及测试的全流程自动化工具,大大简化了使用深度学习进行医学图像分割的复杂度。
自适应网络结构调整:根据输入数据集的特点,nnUNet能够自动选择和配置合适的网络深度、宽度等超参数,确保模型在复杂性和性能之间取得平衡。
本教程重在实践,仅对基础简单知识进行相关概述,更多的详细知识请自行了解
本教程为在自己的电脑上用pycharm和anaconda配置,需求docker/服务器等教程请另寻
设备要求与环境配置
设备要求
我跑通了三台电脑(laptop),见到了大部分的问题,以我个人的两台laptop为例子为大家讲解
电脑配置:
CPU :12700H R9 7495HX
显卡 : 3070TI(8G) 4080(12G)
CUDA: 12.0 12.2
操作系统: Windows
内存:8G × 2
CPU和内存尽量性能好一些,预处理时会占用大量CPU和内存(可能会爆内存)
显卡必须为N卡,支持使用cuda 建议显卡至少为4060及以上,否则较难完成任务

环境配置
本教程使用anaconda对环境进行配置,不会用的小伙伴可以关注我,后期我会再写一篇关于Python环境配置的教程
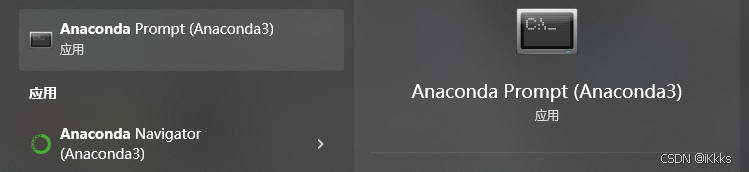
首先打开anaconda版的cmd,创建一个虚拟环境,创建指令为:
conda create -n nnU-Net python=3.9 加载后询问y/n,输入y即可(推荐python版本为3.9,也可以按照自己需求设置为3.10或其他,建议初学者按照我的教程来,避免不必要的bug)我已经下载好了就给大家展示一下环境列表,注意有分盘的小伙伴,后面的路径最好不要装在c盘
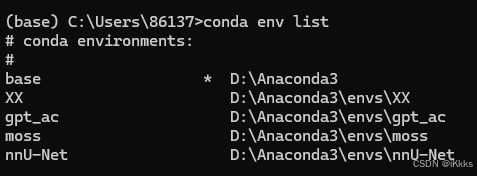
此处留意,星号指当前环境选择,在图中第一行的括号中也可以看出当前为base环境,后续安装pytorch和nnunet时记得在nnU-Net环境下进行,而不要在base下安装哦
创建完成后激活环境,指令为:
conda activate nnU-Net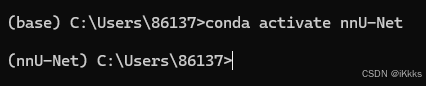 如图所示
如图所示
然后开始我们的后续任务,安装pytorch和nnunet包,
pytorch
打开pytorch官网
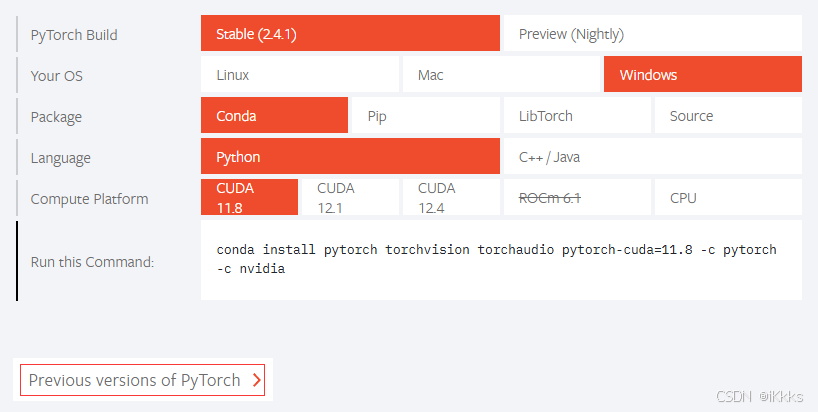
下滑到install页面,选择stable稳定版,windows系统,conda、python,cuda选择匹配自己电脑的版本(win+r打开运行框,输入cmd打开命令提示符,输入指令:nvidia-smi 红框为自己电脑的cuda版本。注意,下载pytorch时,cuda只能向下兼容,例如我的cuda为12.0,那么选择11.8,不能选择12.1及以上,另一台电脑为12.2则选择12.1和11.8均可,建议选择与自己版本相近的) ps:如果自己显卡cuda过旧,可点击红框,下载先前的pytorch版本,注意要选择自己对应的操作系统
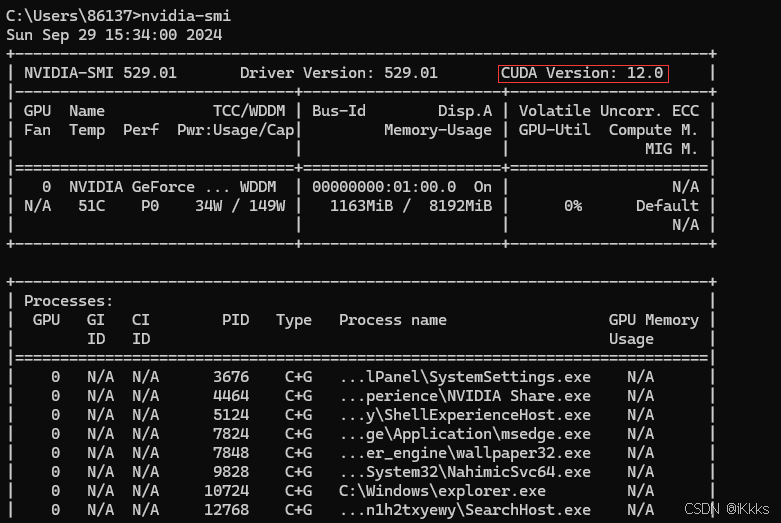
检查cuda版本无误后复制命令并在anaconda prompt中执行即可(如若遇到下载时间过长可尝试更换镜像源,挂vpn,切换网络等各种方法,大家自己多多尝试)
等待安装完成后可以开始在python中进行配置了,打开pycharm,点击右下角的解释器设置(我使用了中文插件,大家自适应中英切换),添加解释器,按照图片步骤一步步来
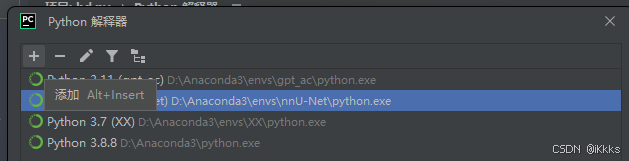
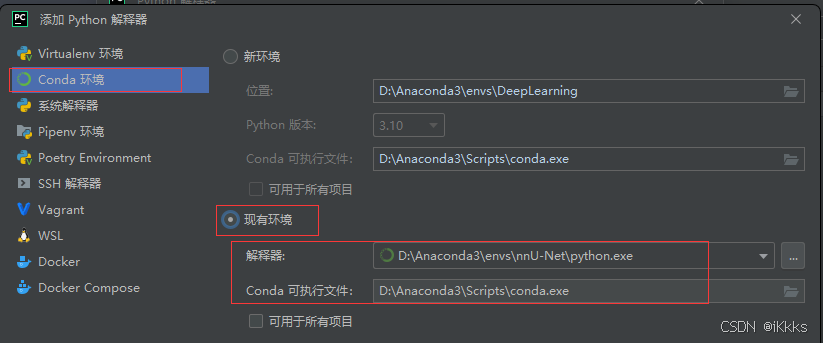
路径如图所示,尽量一次设置完成
设置完成后检查gpu和cuda是否可用
import torch
# 查看cuda是否可用
print(torch.cuda.is_available())
# 返回当前设备索引
print(torch.cuda.current_device())
# 返回GPU的数量
print(torch.cuda.device_count())
# 返回gpu的名字,设备索引默认从0开始
print(torch.cuda.get_device_name(0))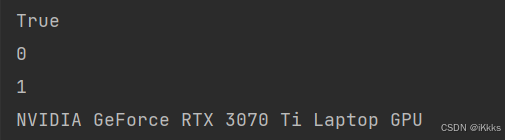 运行结果如图
运行结果如图
接下来开始安装nnunet包
nnunet
首先在设置中将工具终端的shell路径设置为cmd(个人习惯在pycharm终端进行项目管理)
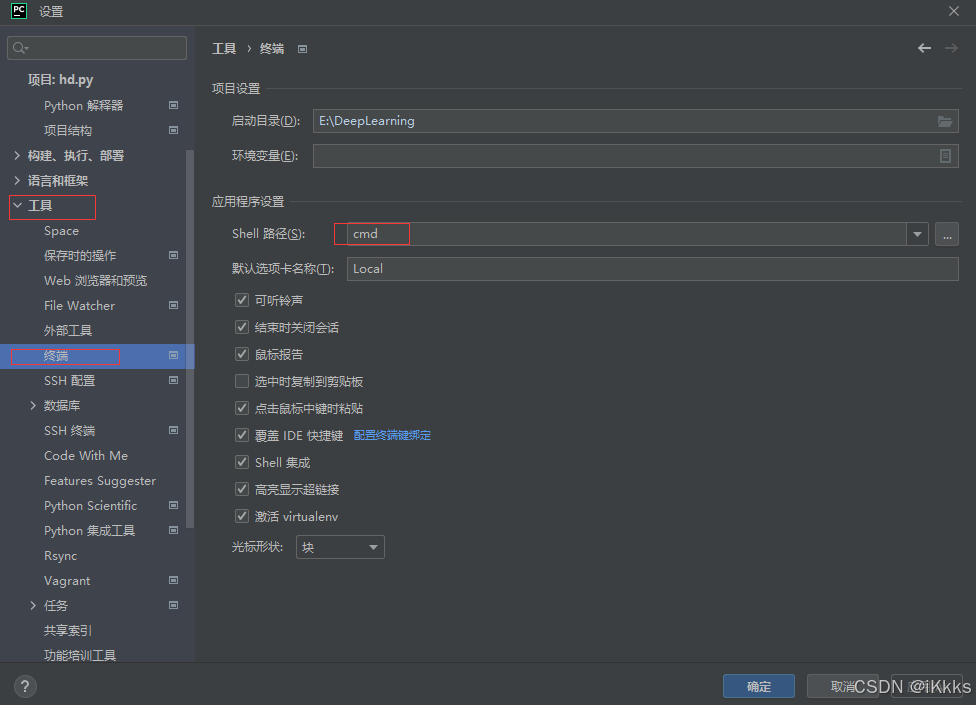
使用说明可以参照官方作者的github
github.com![]() https://github.com/MIC-DKFZ/nnUNet我们安装使用git方法,确定自己的pycharm设置好了git,否则无法使用git命令(可以先在该页面进行test测试是否有安装设置git)没有的话就直接百度GIT下载然后按照下图设置路径即可
https://github.com/MIC-DKFZ/nnUNet我们安装使用git方法,确定自己的pycharm设置好了git,否则无法使用git命令(可以先在该页面进行test测试是否有安装设置git)没有的话就直接百度GIT下载然后按照下图设置路径即可
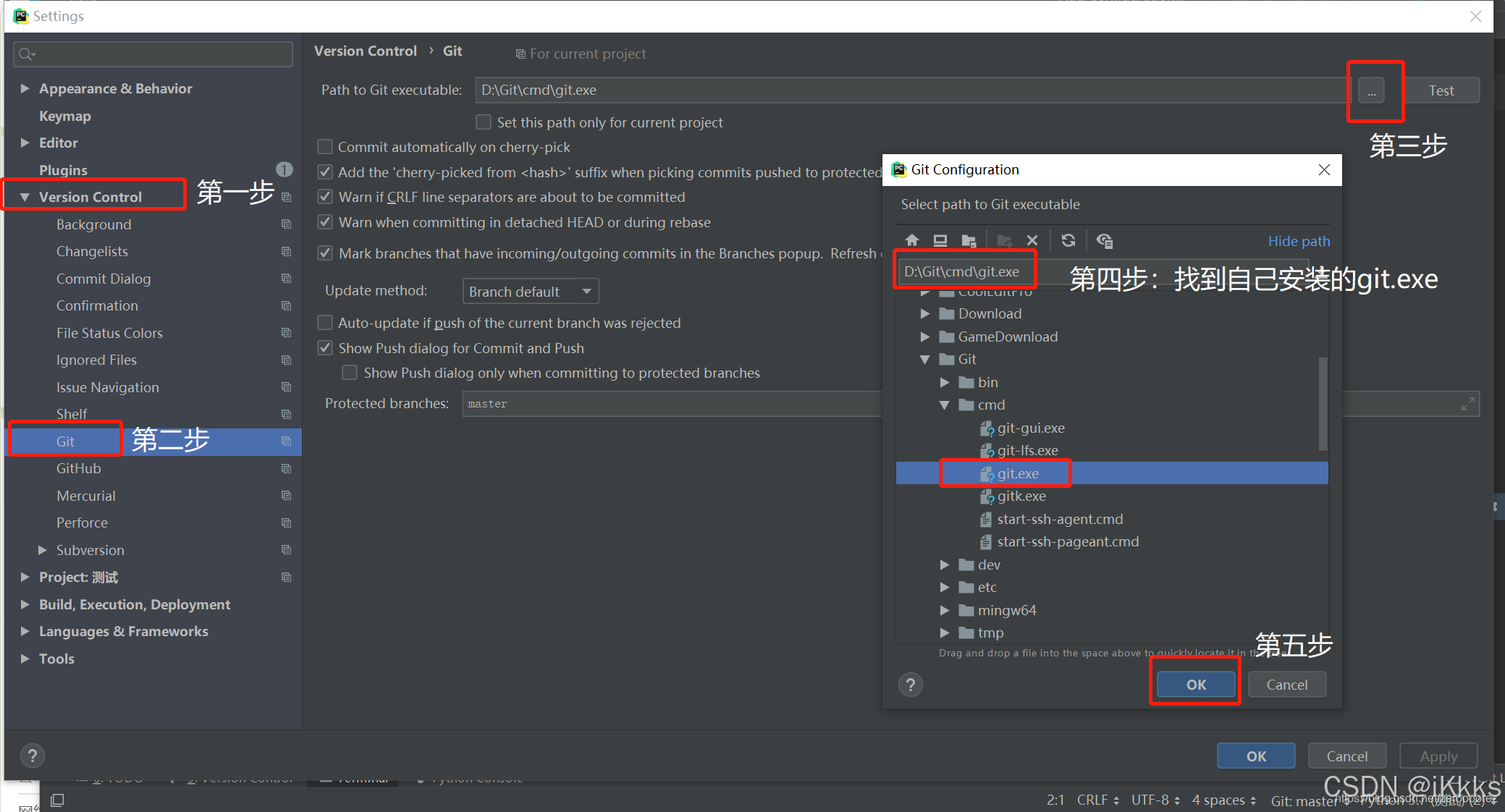
(图片来自leotongxue1234,因为写的非常详细就直接使用了)
接下来我们在c盘以外的盘(D/E都可以,后续预处理会占用大量存储空间)创建一个文件夹DeepLearning(根据个人习惯命名)然后用pycharm打开该文件夹,记得设置解释器,如图所示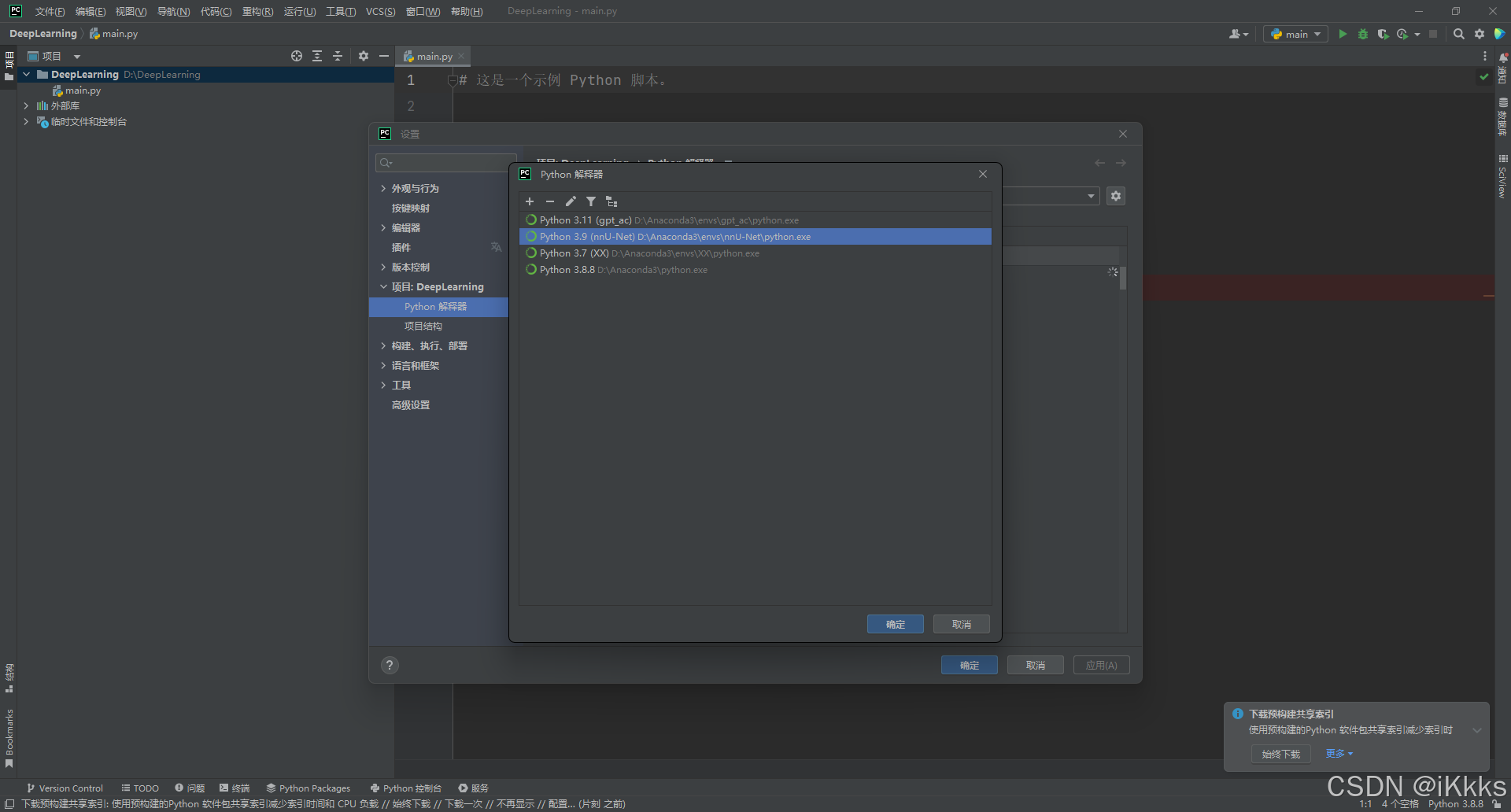
打开终端后如图所示,环境为nnU-Net,启动路径为DeepLearning即正确
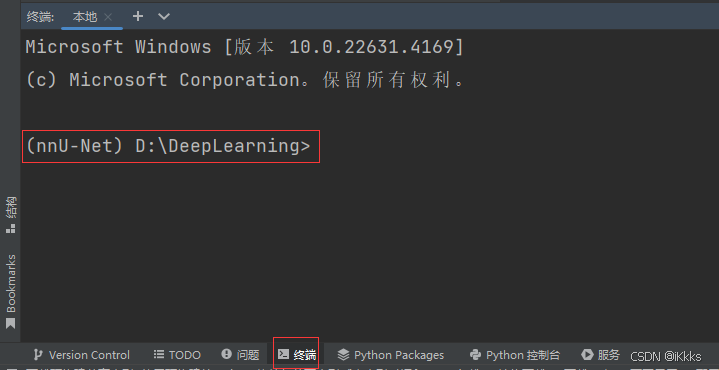
我们采用源码安装的方式,方便对配置进行修改(在终端中一行一行执行下列命令)
(在使用pip install -e .时,不要在nnUNet文件夹下创建其他文件夹,更改文件夹结构会导致报错)
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
如果出现这种情况是无法连接到github的缘故,请修改网络设置,能打开github就能完成该步骤
这里我改用手机热点后git clone就成功了,完成后如下图
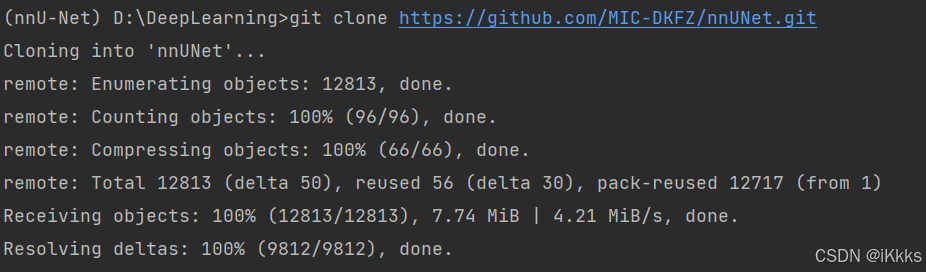
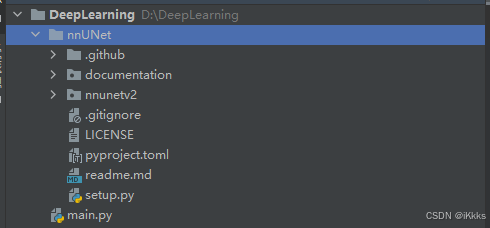
可以发现DeepLearning项目中多了nnUNet文件夹,我们cd进入该文件夹(启动目录更改为DeepLearning\nnUNet),如有前置文件夹我们需要一直cd到nnUNet(包含setup.py)

然后我们开始安装nnunet包,输入指令:pip install -e .
这句相当于运行setup.py文件
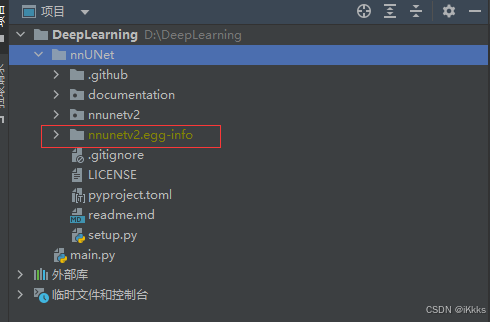
安装完成后可以看到多了红框中的这个文件夹,其作用是向终端添加几个新命令。这些命令用于运行整个nnU-Net pipeline。所有nnU-Net命令都带有前缀“nnUNet_”,以便于识别。
#
请注意,使用pip install -e . 时会自动安装最新版本的环境依赖
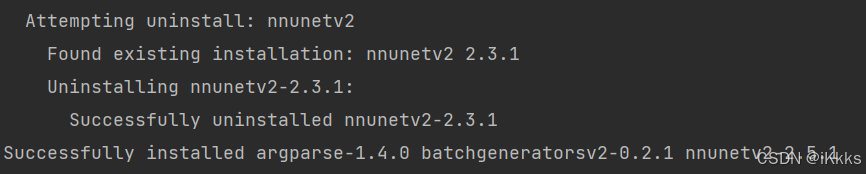
(我第一次跑通时nnunetv2最新版本为2.4.0,版本有bug无法正常跑通,后来改用2.3.1正常,写这篇教程时我没有检查2.5.1是否可用,如果不是对最新版本有要求,我推荐使用2.3.1,是绝对没有问题的)
指令为:pip install nnunetv2==2.3.1)
pip install nnunetv2==2.3.1修改完成后如下图
#
接下来我们退回到文件夹中,在nnUNet文件夹中创建一个新文件夹nnUNetFrame(该文件夹名称可以自拟)
在新文件夹中创建下列三个文件夹,文件夹名称固定(raw存放原始数据集,preprocessed存放预处理后的训练计划,results存放训练结果等,个人理解,如有错误可在评论区指正)
文件夹创建完毕后我们回到pycharm中
(建议大家创建一个test.py文件,存放常用的指令,比如环境变量和后续的训练命令等)
每次重新打开该项目进行训练或其他处理时,都需要先设置环境变量(复制粘贴到pycharm终端运行,建议对环境、库、包管理在anaconda prompt中进行,对项目管理都在pycharm中进行)
set nnUNet_preprocessed=D:/DeepLearning/nnUNet/nnUNetFrame/nnUNet_preprocessed
set nnUNet_raw=D:/DeepLearning/nnUNet/nnUNetFrame/nnUNet_raw
set nnUNet_results=D:/DeepLearning/nnUNet/nnUNetFrame/nnUNet_results至此环境配置结束,接下来我们正式进入nnUNetv2
nnUNetv2的训练测试
1、下载数据集
我使用的是参加bme比赛的hcc肝细胞肿瘤的数据集(10g),仅有训练集(289样本)及标签和测试集(50个样本)(无测试集标签,如需要该数据集可在评论区留言)
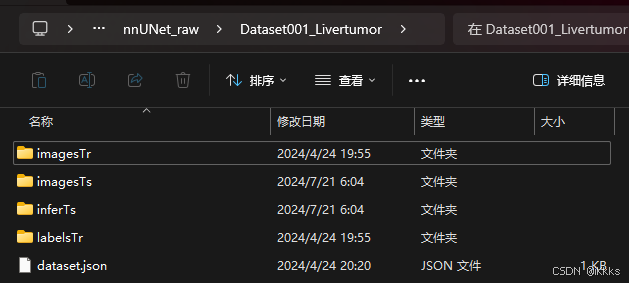
下载完成后如图(imagesTr为训练集,labelsTr为其标签,imagesTs为测试集,infreTs为对分割结果的预测,刚开始下载的数据集里没有,在处理完后需要与测试集的原标签进行比对,提交到官网上会给出你的分割成绩)
2、数据集转换(大部分不需要)
现在基本所有提供的数据集都为Dataset格式,但考虑到可能还是有少部分小伙伴仍使用旧版本数据集,本教程还是提供了数据集转换这一教程
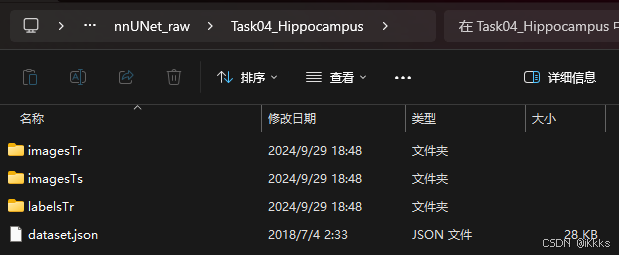
nnUNetv1和v2对数据集的格式要求不同,以MSD挑战赛的Task04_Hippocampus数据集(该数据集很小,十分适用于练习和测试)为例,附上下载地址Task04_Hippocampus_数据集-飞桨AI Studio星河社区 (baidu.com)![]() https://aistudio.baidu.com/datasetdetail/126985正常下载该数据集后,文件夹内容如图(注意上方为Task)
https://aistudio.baidu.com/datasetdetail/126985正常下载该数据集后,文件夹内容如图(注意上方为Task)
在终端执行以下命令
nnUNetv2_convert_MSD_dataset -i D:\DeepLearning\nnUNet\nnUNetFrame\nnUNet_raw\Task04_Hippocampus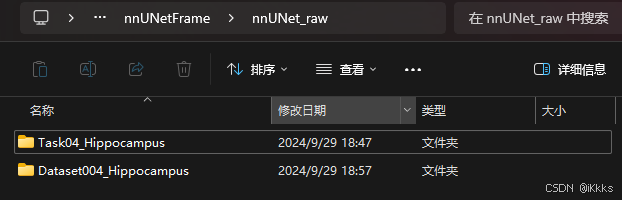
转换后出现了Dataset004_Hippocampus,说明数据集格式转换完成(Task数据集保存位置任意,命令中的-i后接的是Task数据集的存储位置,转换后自动将Dataset数据集存储在raw中)
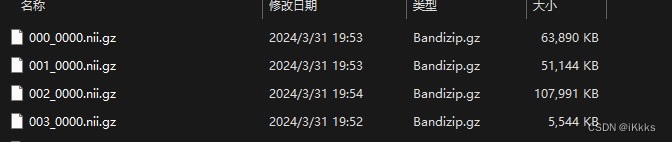
正确数据集后缀格式如图
3、数据集预处理
在pycharm终端执行下列命令
nnUNetv2_plan_and_preprocess -d 004 --verify_dataset_integrity-d后的数字为数据集编号,可以是004也可以是4(如果是上面肝细胞肿瘤的数据集则为001或1)
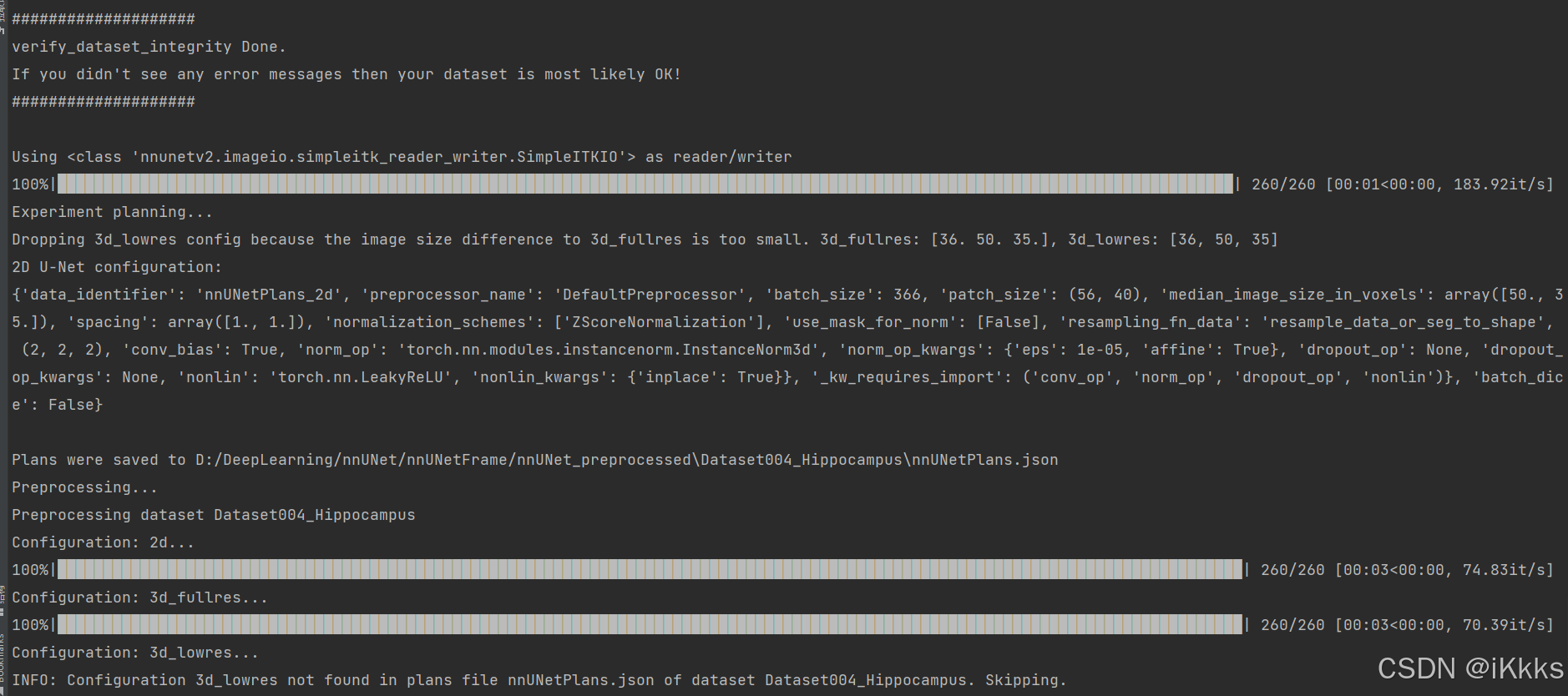
运行后如图(因为数据集超小,所以大概五秒完成,如果使用肝细胞肿瘤的数据集,预处理需花费大约30分钟,占用存储空间约100g,后续演示都用这个小数据集进行演示)
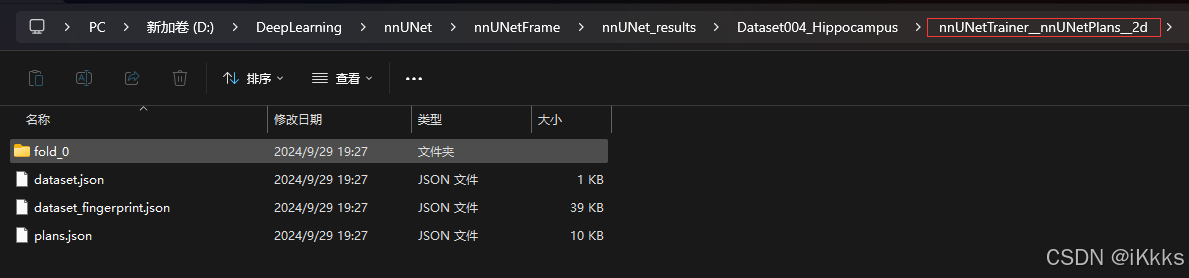
可以看到preprocessed文件夹中出现了以下文件,个人理解为训练计划
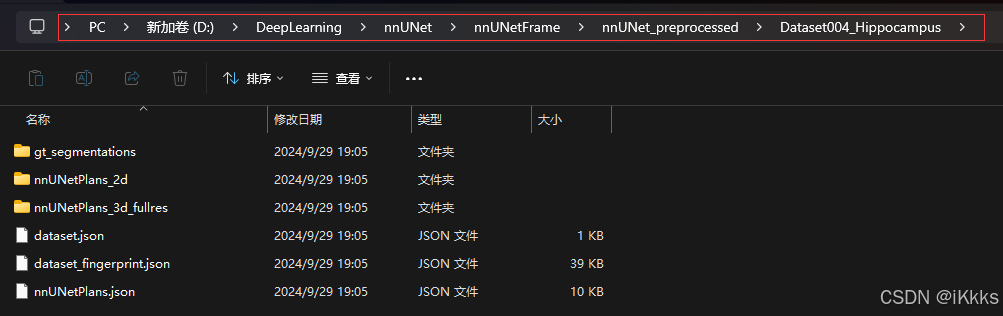
4、训练介绍
包括三种U-Net网络配置,分别是2D U-Net,3D全分辨率U-Net,3D U-Net级联(包括3D低分辨率U-Net和3D全分辨率U-Net),要进行级联下的3D全分辨率U-Net需先完成3D低分辨率U-Net。注意不是所有的数据集都能触发级联,在完成数据集预处理的图中可以看到,本数据集仅有2d和3d_fullres,对于部分数据集来说,还有3d_lowres, 3d_cascade_fullres,而肝细胞肿瘤数据集就可以触发级联(暂时还不明白这是不是与数据集大小有关0.0)
修改epoch
初始默认为1000,推荐在200-500个epoch之间,不要过高或过低
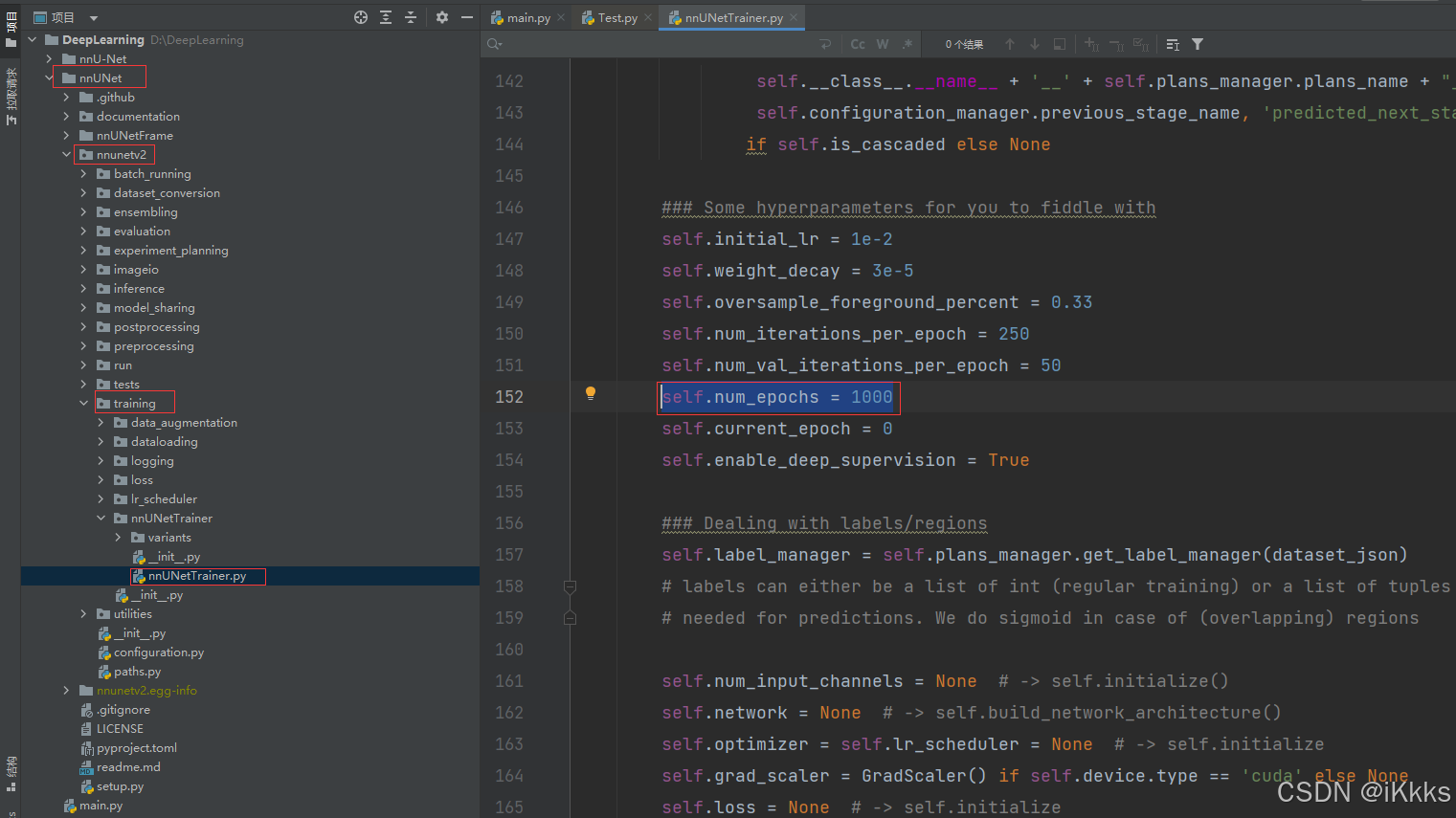
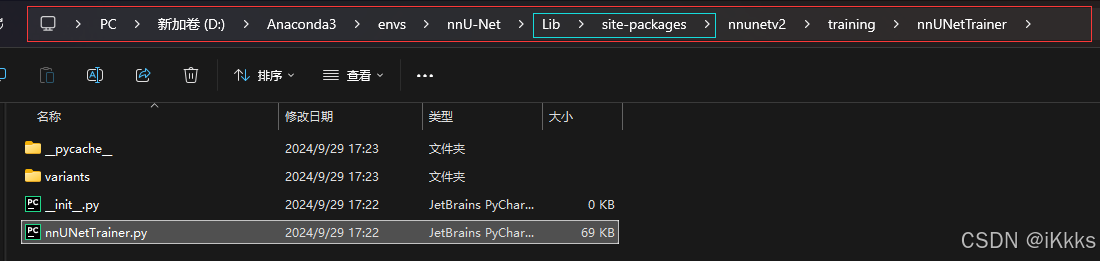
如果修改后epoch到达指定数目没有改变,我们就通过另一个方式来进行修改
回到anaconda目录,从site-packages中找到同名文件打开进行修改(原理我还不知道0.0)
训练命令
nnU-Net默认使用5折交叉验证来训练所有U-Net配置
train后面的第一个数字为数据集编号,后面的2d为本次训练所使用的模型,2d后面的数字为第几折,因为使用的是五折交叉验证,那么我们需要训练5次,注意要使用一个模型需要跑完五折后再使用其进行下一步
2D训练指令如下
nnUNetv2_train 4 2d 0
nnUNetv2_train 4 2d 1
nnUNetv2_train 4 2d 2
nnUNetv2_train 4 2d 3
nnUNetv2_train 4 2d 4
执行nnUNetv2_train 4 2d 0 后可以看到开始训练了
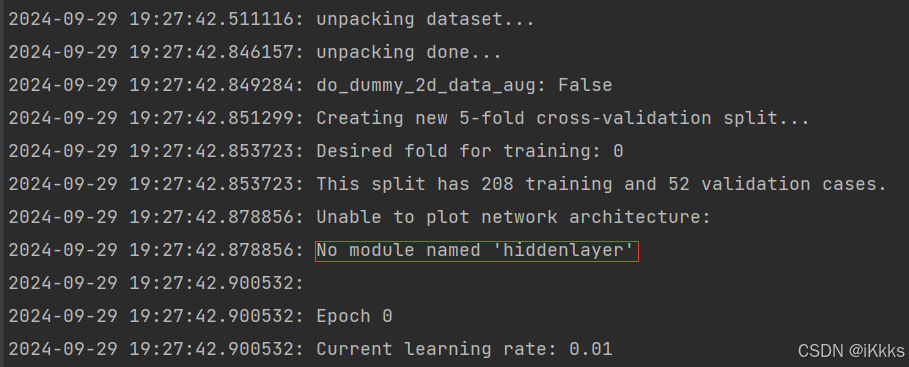
红框为没有安装hiddenlayer,其实并不影响,只是一个绘制模型结构的模块,其效果也不好
3D全分辨率模型训练指令如下
nnUNetv2_train 4 3d_fullres 0
nnUNetv2_train 4 3d_fullres 1
nnUNetv2_train 4 3d_fullres 2
nnUNetv2_train 4 3d_fullres 3
nnUNetv2_train 4 3d_fullres 4 级联(因为004数据集不支持级联,这里的nnUNetv2_trian后的数字改为了1,指的是肝细胞肿瘤数据集)
nnUNetv2_train 1 3d_lowres 0
nnUNetv2_train 1 3d_lowres 1
nnUNetv2_train 1 3d_lowres 2
nnUNetv2_train 1 3d_lowres 3
nnUNetv2_train 1 3d_lowres 4
nnUNetv2_train 1 3d_cascade_fullres 0
nnUNetv2_train 1 3d_cascade_fullres 1
nnUNetv2_train 1 3d_cascade_fullres 2
nnUNetv2_train 1 3d_cascade_fullres 3
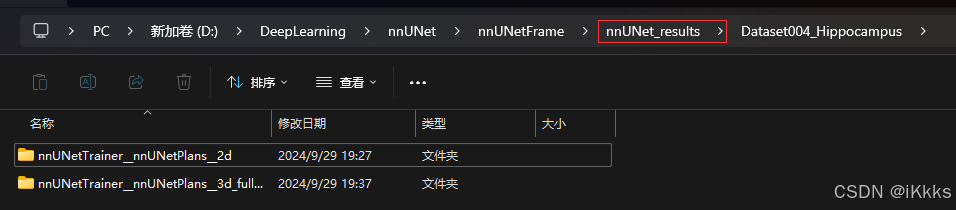
nnUNetv2_train 1 3d_cascade_fullres 4可以看到训练后在results文件夹中会分折数的实时保存你各个模型的训练状况,包括训练日志和训练结果
验证、推理和模型寻优
1、验证
对训练完后的模型输入以下命令(例如004数据集只训练了2d和3d_fullers,就输入以下命令)
nnUNetv2_train 4 2d 0 --val --npz
nnUNetv2_train 4 2d 1 --val --npz
nnUNetv2_train 4 2d 2 --val --npz
nnUNetv2_train 4 2d 3 --val --npz
nnUNetv2_train 4 2d 4 --val --npz
nnUNetv2_train 4 3d_fullres 0 --val --npz
nnUNetv2_train 4 3d_fullres 1 --val --npz
nnUNetv2_train 4 3d_fullres 2 --val --npz
nnUNetv2_train 4 3d_fullres 3 --val --npz
nnUNetv2_train 4 3d_fullres 4 --val --npz运行以上命令后,nnUNet_results文件夹的每折validation文件夹出现npz文件
2、推理寻优
nnUNetv2_find_best_configuration 4 -c 2d 3d_fullres 3d_lowers -f 0 1 2 3 4运行该命令后会自动ensemble寻优,集成出最好效果的模型(该图为我以前跑通时截下的,所以路径和大家不同,模型多包含了3d_lowers)
#
肝细胞肿瘤为例(-i -o指令需要自己给,建议大家-o输出的文件夹名称合规一些,不然容易把自己搞晕,这里的路径是我最开始跑的,大家不要参照,学习格式后自己给)
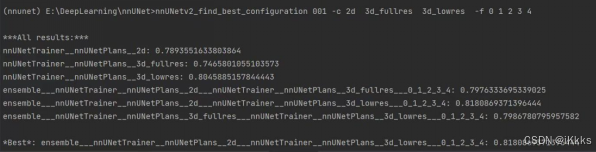
#nnunetv2会自动给你后续的推理代码#
An ensemble won! What a surprise! Run the following commands to run predictions with the ensemble members:
nnUNetv2_predict -d Dataset001_Livertumor -i E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/Dataset001_Livertumor/imagesTs -o E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/predict2d -f 0 1 2 3 4 -tr nnUNetTrainer -c 2d -p nnUNetPlans --save_probabilities
nnUNetv2_predict -d Dataset001_Livertumor -i E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/Dataset001_Livertumor/imagesTs -o E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/predict3d_lowres -f 0 1 2 3 4 -tr nnUNetTrainer -c 3d_lowres -p nnUNetPlans --save_probabilities运行完成后执行下列代码保存ensemble策略
nnUNetv2_ensemble -i E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/predict2d E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/predict3d_lowres -o E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/Livertumor_ensemble -np 8
采取后处理后得到对测试集的分割结果
nnUNetv2_apply_postprocessing -i E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/Livertumor_ensemble -o Livertumor_ensemble_pp -pp_pkl_file E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/ensembles/ensemble___nnUNetTrainer__nnUNetPlans__2d___nnUNetTrainer__nnUNetPlans__3d_lowres___0_1_2_3_4/postprocessing.pkl -np 8 -plans_json E:/DeepLearning/nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_Livertumor/ensembles/ensemble___nnUNetTrainer__nnUNetPlans__2d___nnUNetTrainer__nnUNetPlans__3d_lowres___0_1_2_3_4/plans.json
预测结果路径"E:\DeepLearning\nnUNet\Livertumor_ensemble_pp"
#
004Hippocampus数据集为例
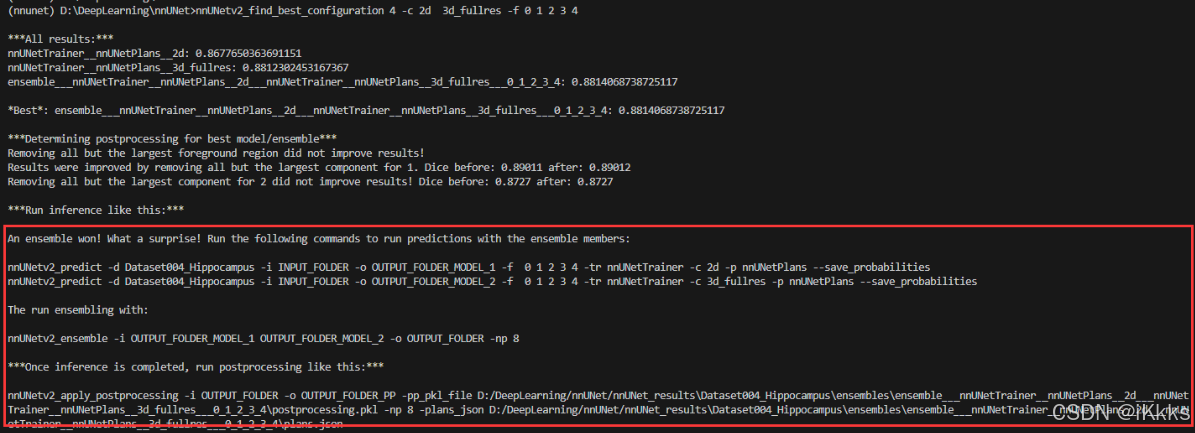
(因为我并没实际把004数据集跑完,这里借用了另一个博主justld的图)
保存nnunet提供的命令并运行
nnUNetv2_predict -d Dataset004_Hippocampus -i nnUNet_raw\Dataset004_Hippocampus\imagesTs -o hippocampus_2d_predict -f 0 1 2 3 4 -tr nnUNetTrainer -c 2d -p nnUNetPlans --save_probabilities
nnUNetv2_predict -d Dataset004_Hippocampus -i nnUNet_raw\Dataset004_Hippocampus\imagesTs -o hippocampus_3d_fullres_predict -f 0 1 2 3 4 -tr nnUNetTrainer -c 3d_fullres -p nnUNetPlans --save_probabilities-d后接数据集名 -i 我理解为input输入imageTs测试集地址,-o为output输出,保存ensemble推理结果的位置
nnUNetv2_ensemble -i hippocampus_2d_predict hippocampus_3d_fullres_predict -o hippocampus_ensemble -np 8推理完成后进行后处理,结构与上述命令一致,大家注意好自己的路径不要写错
nnUNetv2_apply_postprocessing -i hippocampus_ensemble -o hippocampus_ensemble_pp -pp_pkl_file D:/DeepLearning/nnUNet/nnUNetFrame/nnUNet_results/Dataset004_Hippocampus/ensembles/ensemble___nnUNetTrainer__nnUNetPlans__2d___nnUNetTrainer__nnUNetPlans__3d_fullres___0_1_2_3_4/postprocessing.pkl -np 8 -plans_json D:/DeepLearning/nnUNet/nnUNetFrame/nnUNet_results/Dataset004_Hippocampus/ensembles/ensemble___nnUNetTrainer__nnUNetPlans__2d___nnUNetTrainer__nnUNetPlans__3d_fullres___0_1_2_3_4/plans.json
至此我们完成了对该数据集包括训练集训练和测试集预测,可以将结果提交给官方检测得到你的检测分数(训练时给出的为伪dice,是训练过程里波动最高的dice,会不断递增,但递增会随着epoch增长减慢,不超过1,到达设定epoch再经过一段推理才得到每折的最终dice成绩,最后寻优ensemble过程中比较的也是dice。衡量分割结果我个人主要看的参数为DSC/dice,HD/HD95两者有区别,IoU这三样)
(2025.3.1)PS:默认给出的训练summary只有dice和少量几个评价指标,如果需要其他指标可以自己在网上搜索相关参数的计算方法,写一个脚本函数覆写即可,博主有一个自己的覆写脚本,有需要的可以私信加qq发(主要指标如下,这个脚本的Dice计算方法和默认的有所区别,所以会有0.几个百分点的误差,影响不大)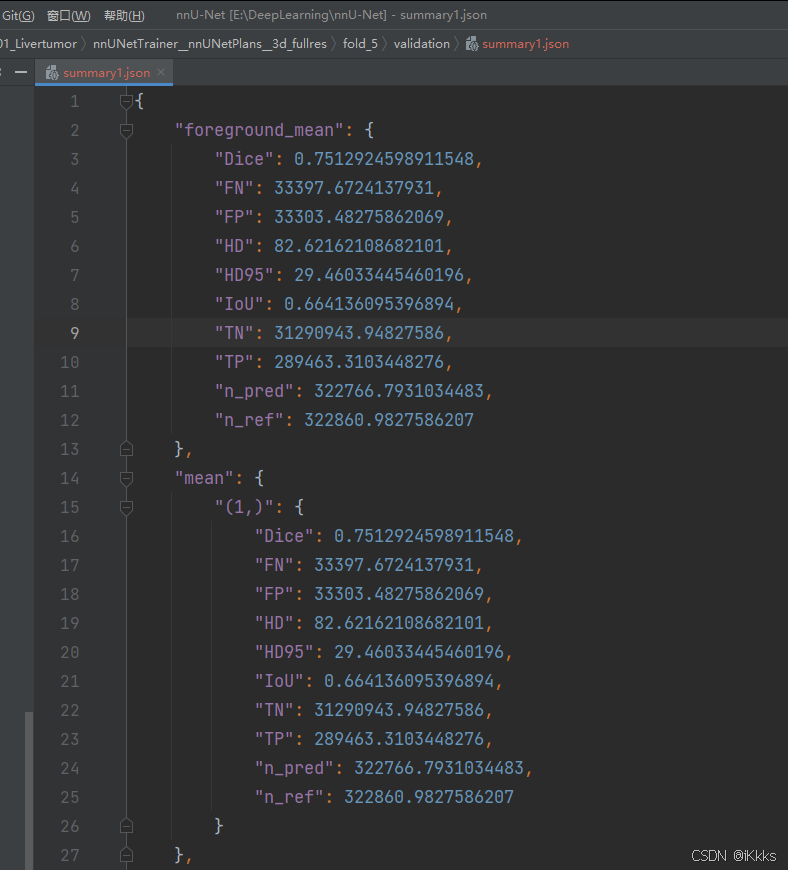
#这是本人的第一篇博客,创作灵感就当作散文来写到最后吧。写下这篇博客是看到各位师兄师姐纷纷推免,难免心生羡慕,不知明年此时我会是怎样的光景。心有怅然,不知所为,遂写下此篇
初步跑通是24年5月左右大二下,写下这篇已过约莫半年,已是大三上,希望能为各位小伙伴提供帮助的同时,也作为个人学习nnunetv2的备忘录。本人也是刚刚接触深度学习,如有错误欢迎大家在评论区指正。#

















 1810
1810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









