






nnU-Netv2新手教程,训练用数据集BraTs2021
nnUnet方法源自论文
大佬文章 https://www.nature.com/articles/s41592-020-01008-z
《Automated Design of Deep Learning Methods for Biomedical Image Segmentation》,来自德国癌症研究中心。
源码地址:https://github.com/MIC-DKFZ/nnUNet。
nnUNet浓缩了医学图像的语义分割领域的大部分知识,并且具备自动为不同任务设计不同训练方案的框架,不需要人工进行调参。
安装Anaconda
方式一:从官网下载
官网首页:https://www.anaconda.com/
官网下载页:https://www.anaconda.com/products/individual#Downloads
根据你的系统选择相应的installer即可
方式二:清华镜像下载(中国大陆推荐)
在官网下载比较慢,而且容易断开连接,推荐用下面清华镜像方式:
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
打开后,可以通过时间排序找到最新版本下载,或者选一个你想要的版本。
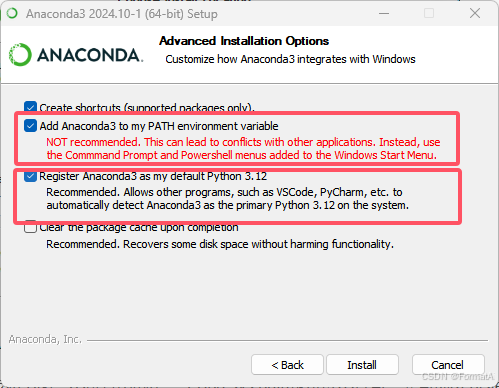
勾选添加环境变量(不勾选的话,需要手动添加)
第二个勾选则是选择anaconda的python优先级最高,不管电脑是否安装了其他版本的python
手动添加环境变量如下:
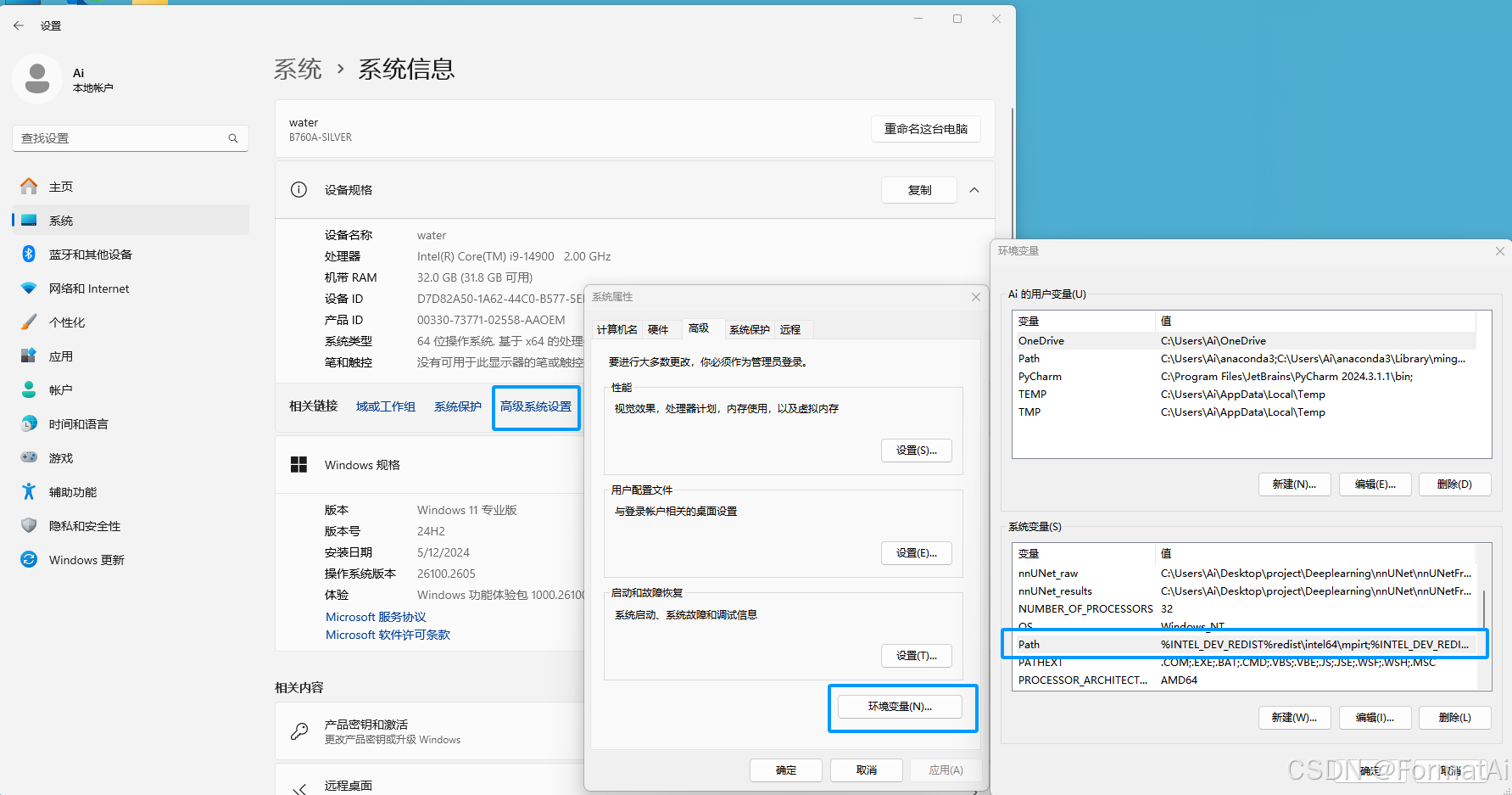
硬盘已分区的情况下,不建议将Anaconda安装在C盘,建议安装在D盘等非系统盘
将以下环境变量,相应用户的目录可能会有所不同,但是后面的路径名相同。点击编辑,添加至path中
C:\anaconda3
C:\anaconda3\Scripts
C:\anaconda3\Library\bin
C:\anaconda3\Library\mingw-w64\bin
安装完成后,在CMD下输入conda
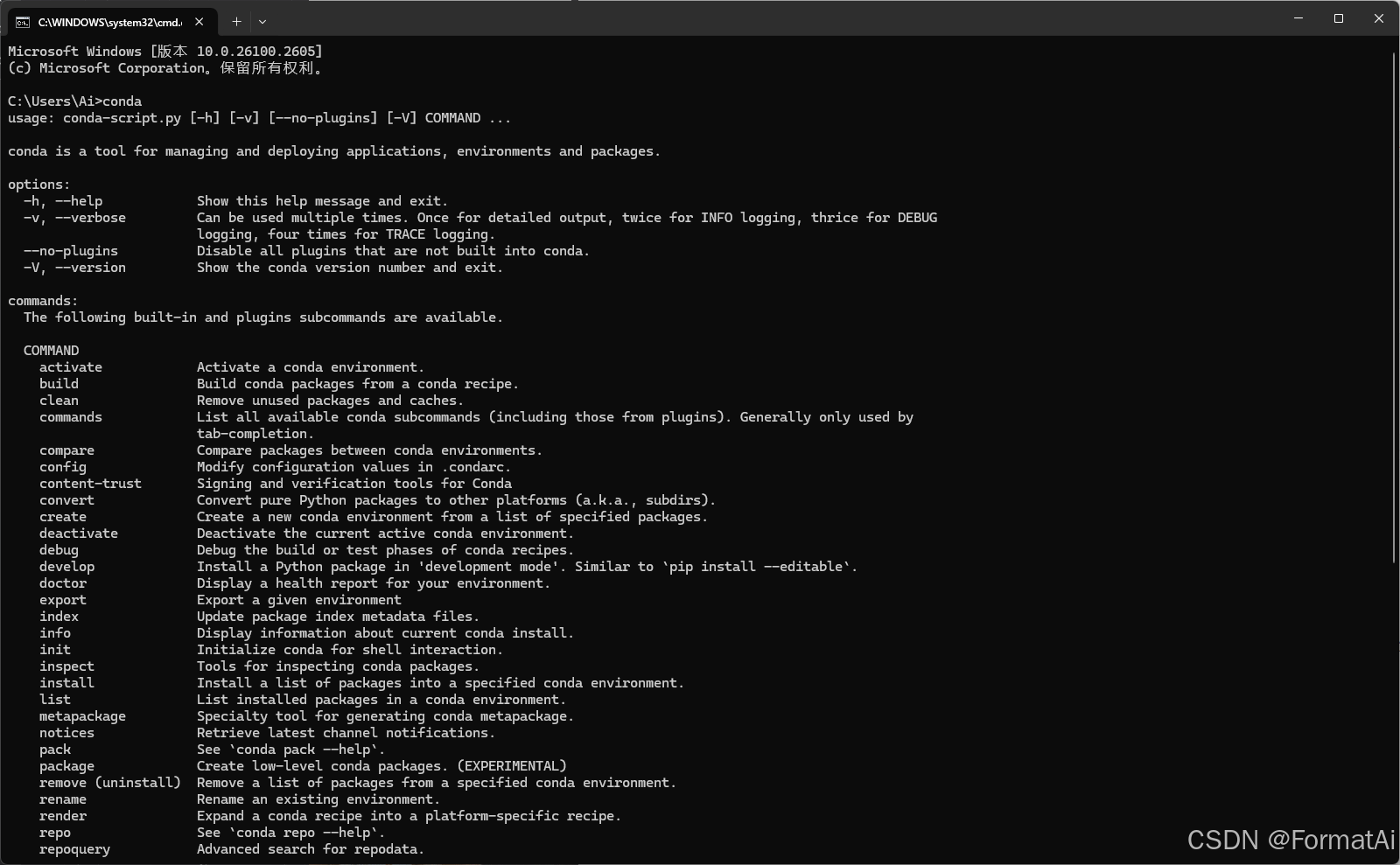
显示如图即安装成功
首先打开anaconda版的cmd(Anaconda Prompt),创建一个虚拟环境,创建指令为
conda create -n nnU-Net python=3.9


proceed 选择 y
创建完成后激活环境,指令为:
conda activate nnU-Net

我们可以看到已经切换到之前创建的nnU-Net环境
安装Pytorch,指令为:
在cmd下输入指令:nvidia-smi 红框为自己电脑的cuda版本。查看自己显卡的cuda版本
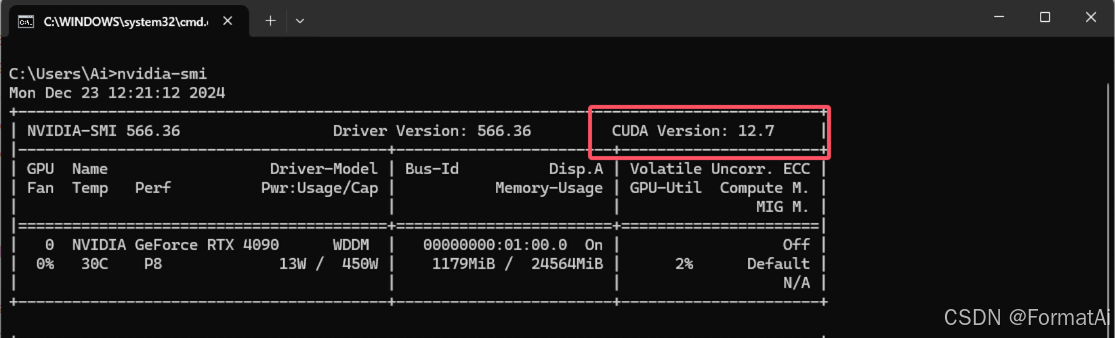 注意,下载pytorch时,cuda只能向下兼容,例如我的cuda为12.0,那么选择11.8,不能选择12.1及以上,另一台电脑为12.7则选择12.4,12.1和11.8均可,建议选择与自己版本相近的)
注意,下载pytorch时,cuda只能向下兼容,例如我的cuda为12.0,那么选择11.8,不能选择12.1及以上,另一台电脑为12.7则选择12.4,12.1和11.8均可,建议选择与自己版本相近的)
ps:如果自己显卡cuda过旧,可点击红框,下载先前的pytorch版本,注意要选择自己对应的操作系统

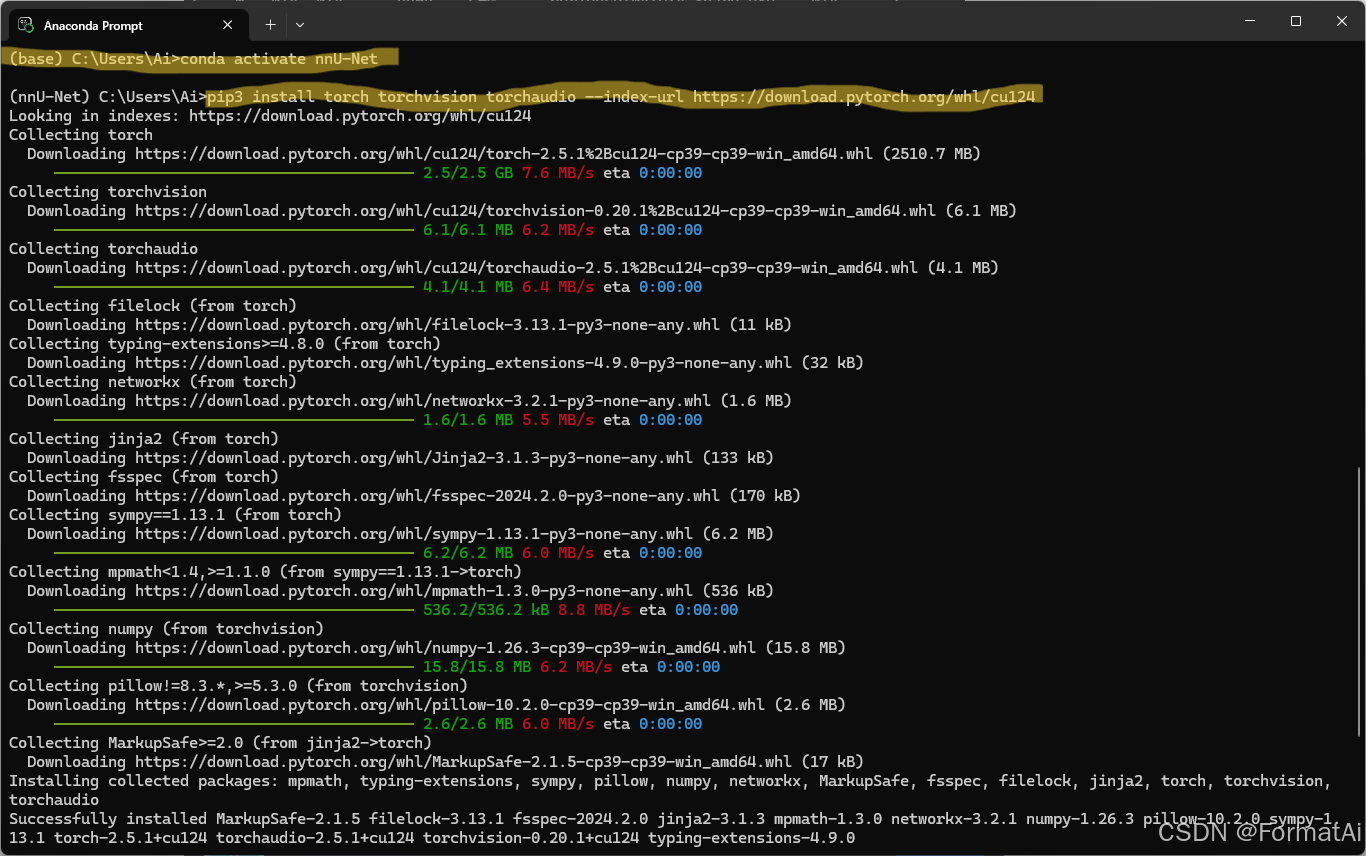
复制Run this Command,安装pytorch(cmd下) 选择cuda对应的版本(cuda向下兼容)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
创建文件夹,用pycharm打开 Open Folder as PyCharm Project
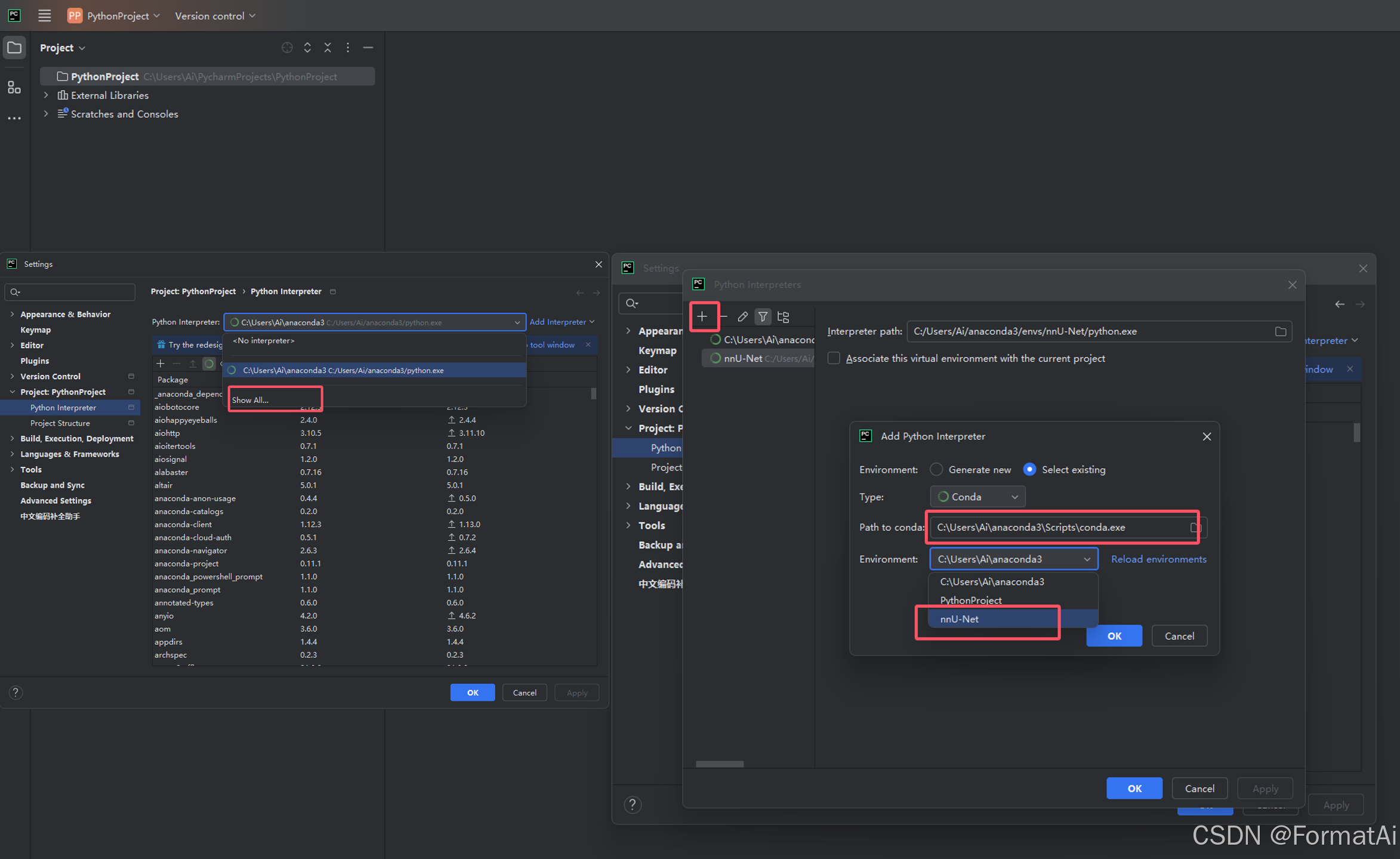
打开pycharm,给项目添加解释器,将conda下面的nnU-Net环境添加至项目
配置完成后检查cuda和CPU是否可用
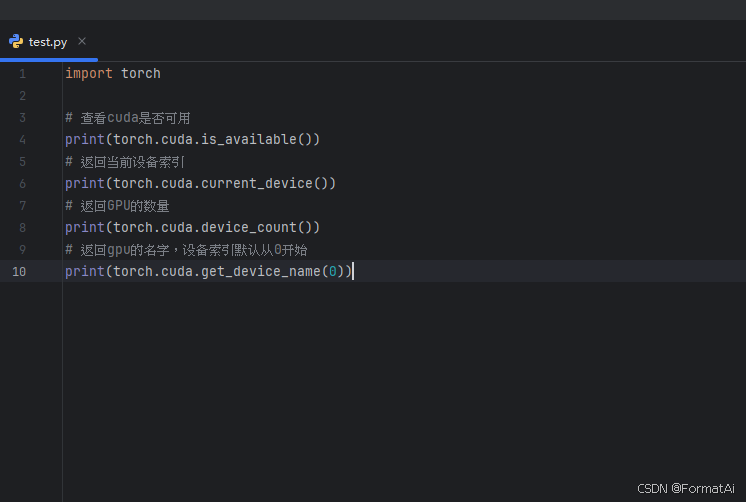
返回结果
安装Git插件,在pycharm设置Git路径
下载安装
对pycharm进行git的配置
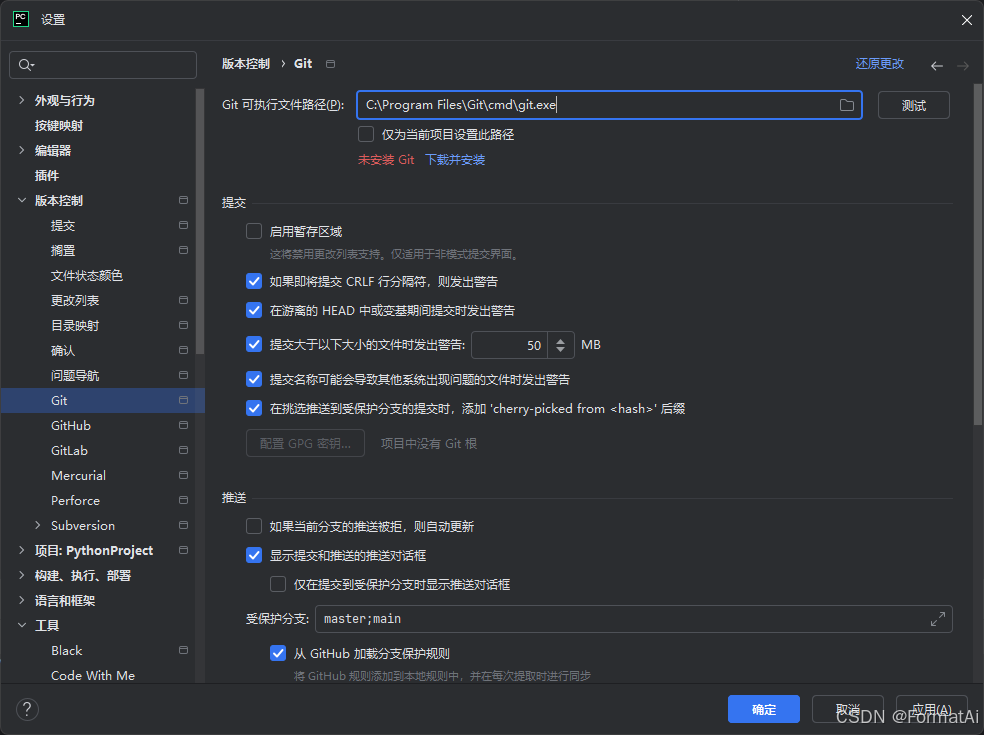
选择正确的git路径,点击测试,即可显示版本
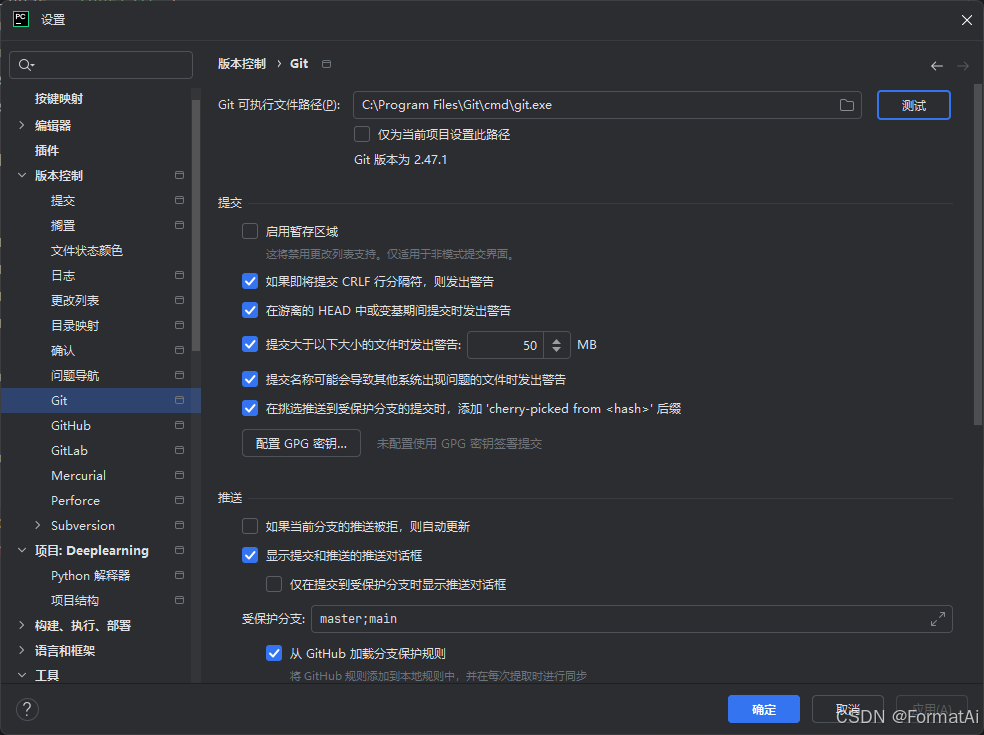
安装nnunet库(使用Git的方法安装):
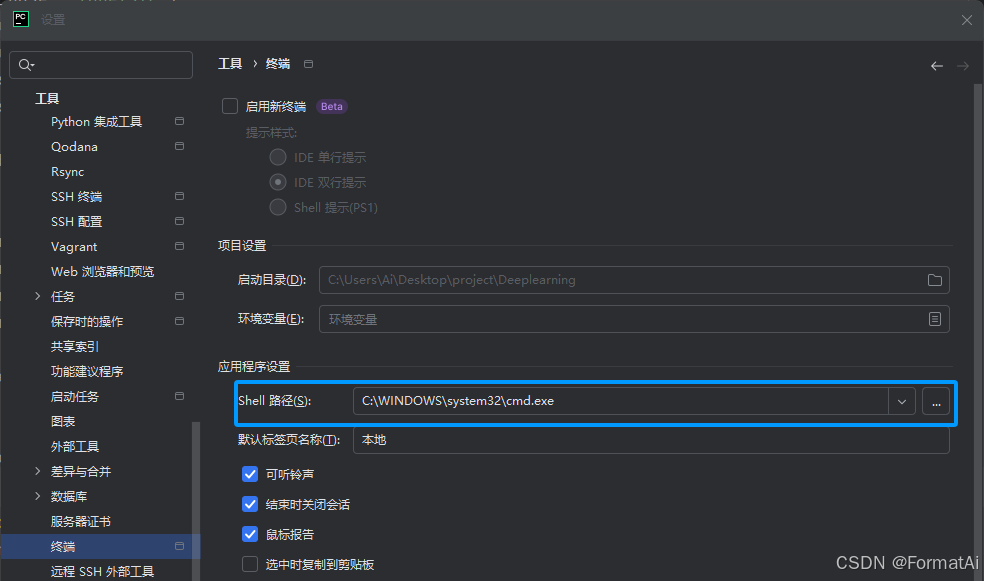
首先在设置中将工具终端的shell路径设置为cmd(以便于在pycharm终端进行项目管理)
在pycharm打开终端,开始安装nnU-Netv2
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
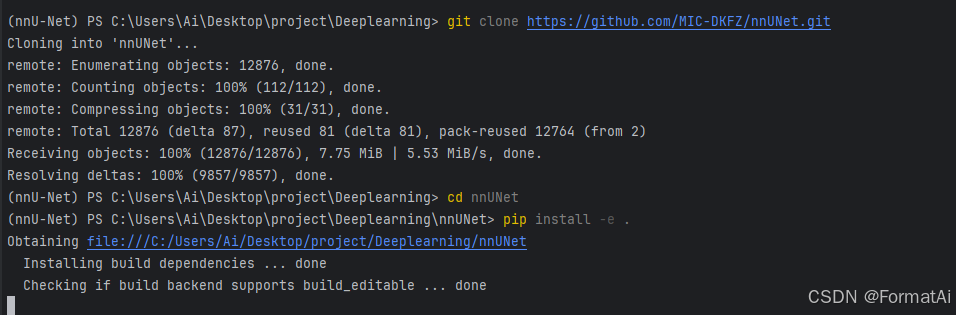
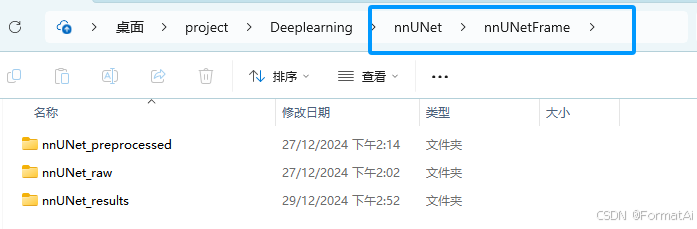
在nnUNet文件夹中创建一个新文件夹nnUNetFrame,在该文件夹中新建三个文件夹:
nnUNet_raw
nnUNet_preprocessed
nnUNet_results
文件夹名称固定(raw存放原始数据集,preprocessed存放预处理后的训练计划,results存放训练结果等
修改data_process.py,用于处理BraTS2021 原始数据集
原始数据集并不满足nnU-Net的数据规范,因此我们需要将数据转换为规范数据。
这里data_process.py的编写,可以参考Deeplearning\nnUNet\nnunetv2\dataset_conversion目录下的文件
这里我们用到的是BraTS2021的数据集,因此可以参考Dataset137
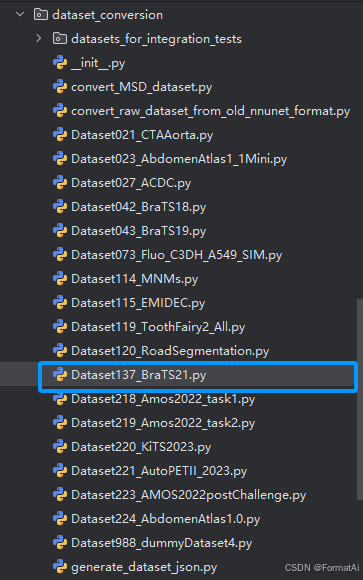
data_process.py代码如下
import multiprocessing
import shutil
from multiprocessing import Pool
import SimpleITK as sitk
import numpy as np
from batchgenerators.utilities.file_and_folder_operations import *
from nnUNet.nnunetv2.dataset_conversion.generate_dataset_json import generate_dataset_json
#定义函数 将BraTS标签转换为nnU-Net格式
def copy_BraTS_segmentation_and_convert_labels_to_nnUNet(in_file: str, out_file: str) -> None:
# use this for segmentation only!!!
# nnUNet wants the labels to be continuous. BraTS is 0, 1, 2, 4 -> we make that into 0, 1, 2, 3
img = sitk.ReadImage(in_file)
img_npy = sitk.GetArrayFromImage(img)
uniques = np.unique(img_npy)
for u in uniques:
if u not in [0, 1, 2, 4]:
raise RuntimeError('unexpected label')
seg_new = np.zeros_like(img_npy)
seg_new[img_npy == 4] = 3
seg_new[img_npy == 2] = 1
seg_new[img_npy == 1] = 2
img_corr = sitk.GetImageFromArray(seg_new)
img_corr.CopyInformation(img)
sitk.WriteImage(img_corr, out_file)
#定义函数 将标签转换回BraTS格式
def convert_labels_back_to_BraTS(seg: np.ndarray):
new_seg = np.zeros_like(seg)
new_seg[seg == 1] = 2
new_seg[seg == 3] = 4
new_seg[seg == 2] = 1
return new_seg
def load_convert_labels_back_to_BraTS(filename, input_folder, output_folder):
a = sitk.ReadImage(join(input_folder, filename))
b = sitk.GetArrayFromImage(a)
c = convert_labels_back_to_BraTS(b)
d = sitk.GetImageFromArray(c)
d.CopyInformation(a)
sitk.WriteImage(d, join(output_folder, filename))
#定义函数 处理包含预测结果的文件夹
def convert_folder_with_preds_back_to_BraTS_labeling_convention(input_folder: str, output_folder: str, num_processes: int = 12):
"""
reads all prediction files (nifti) in the input folder, converts the labels back to BraTS convention and saves the
"""
maybe_mkdir_p(output_folder)
nii = subfiles(input_folder, suffix='.nii.gz', join=False)
with multiprocessing.get_context("spawn").Pool(num_processes) as p:
p.starmap(load_convert_labels_back_to_BraTS, zip(nii, [input_folder] * len(nii), [output_folder] * len(nii)))
if __name__ == '__main__':
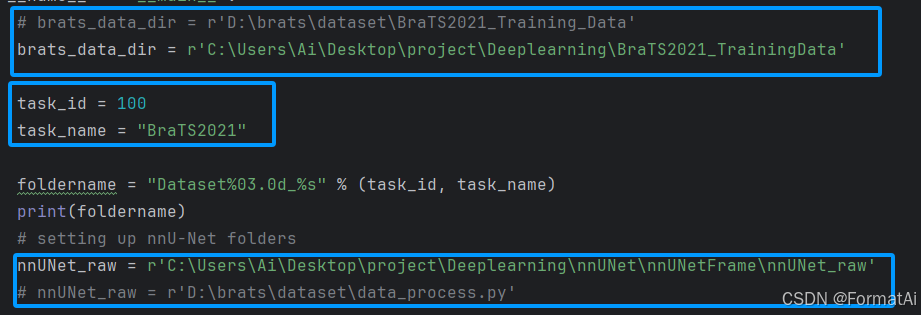
# brats_data_dir = r'D:\brats\dataset\BraTS2021_Training_Data'
brats_data_dir = r'C:\Users\Ai\Desktop\project\Deeplearning\BraTS2021_TrainingData'
task_id = 100
task_name = "BraTS2021"
foldername = "Dataset%03.0d_%s" % (task_id, task_name)
print(foldername)
# setting up nnU-Net folders
nnUNet_raw = r'C:\Users\Ai\Desktop\project\Deeplearning\nnUNet\nnUNetFrame\nnUNet_raw'
# nnUNet_raw = r'D:\brats\dataset\data_process.py'
print(nnUNet_raw)
out_base = join(nnUNet_raw, foldername)
imagestr = join(out_base, "imagesTr")
labelstr = join(out_base, "labelsTr")
# imagestr = join(out_base, "imagesTs")
# labelstr = join(out_base, "labelsTs")
maybe_mkdir_p(imagestr)
maybe_mkdir_p(labelstr)
case_ids = subdirs(brats_data_dir, prefix='BraTS', join=False)
for c in case_ids:
shutil.copy(join(brats_data_dir, c, c + "_t1.nii.gz"), join(imagestr, c + '_0000.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "_t1ce.nii.gz"), join(imagestr, c + '_0001.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "_t2.nii.gz"), join(imagestr, c + '_0002.nii.gz'))
shutil.copy(join(brats_data_dir, c, c + "_flair.nii.gz"), join(imagestr, c + '_0003.nii.gz'))
copy_BraTS_segmentation_and_convert_labels_to_nnUNet(join(brats_data_dir, c, c + "_seg.nii.gz"),
join(labelstr, c + '.nii.gz'))
generate_dataset_json(out_base,
channel_names={0: 'T1', 1: 'T1ce', 2: 'T2', 3: 'Flair'},
labels={
'background': 0,
'whole tumor': (1, 2, 3),
'tumor core': (2, 3),
'enhancing tumor': (3, )
},
num_training_cases=len(case_ids),
file_ending='.nii.gz',
regions_class_order=(1, 2, 3),
license='see https://www.synapse.org/#!Synapse:syn25829067/wiki/610863',
reference='see https://www.synapse.org/#!Synapse:syn25829067/wiki/610863',
dataset_release='1.0')
将本代码中的brats_data_dir改为实际的数据集地址
nnUNet_raw改为上一步中nnUNet_raw的地址
同时可以用task_id,name自定义编号和项目名
运行代码,初始化后的数据即可载入在nnUNet_raw文件夹
值得一提的是,我们可以使用更改输出文件名的方法,在数据集里面选择子集,后创建测试集(imageTs,labelTs)
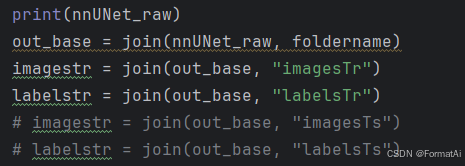
运行data_process.py 可以看到nnUNet_raw文件夹下有处理好的数据文件。
imageTr,labelsTr均为训练集,可建立imagesTs文件夹作为模型的测试集,这里并不会自动创建。之后要将测试集的数据项放入imagesTs文件夹
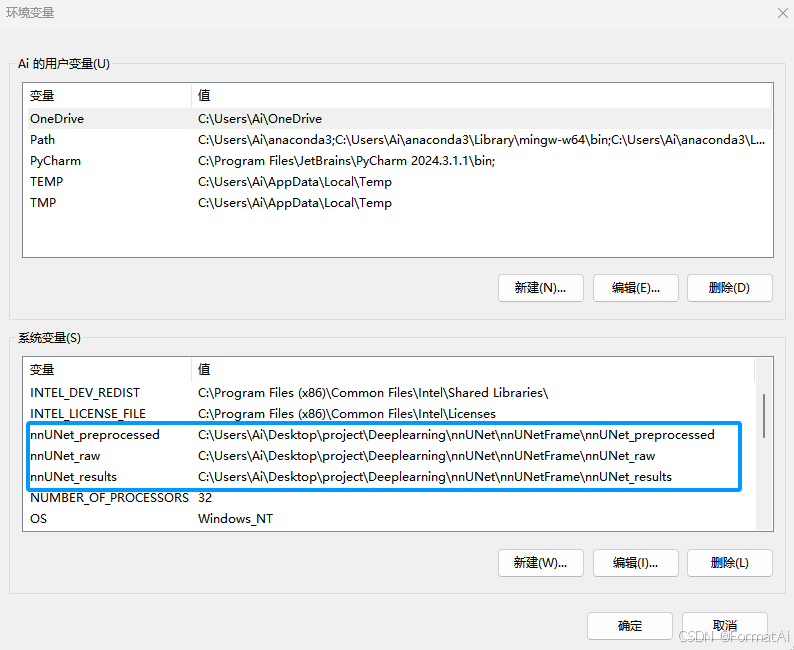
修改环境变量:
$Env:nnUNet_raw = "nnUNet_raw文件夹位置"
$Env:nnUNet_preprocessed = "nnUNet_preprocessed文件夹位置"
$Env:nnUNet_results = "nnUNet_results文件夹位置"
将引号内路径修改为实际文件夹路径,在cmd命令行中运行
*本方法修改环境变量为一次性,关闭命令行重新打开需重新输入
或者直接在系统中添加环境变量,添加nnUNet_raw、nnUNet_preprocessed、nnUNet_results三个变量,其path对应为所在位置。
进行预处理,命令行运行
nnUNetv2_plan_and_preprocess -d 100 --verify_dataset_integrity
进行数据预处理。
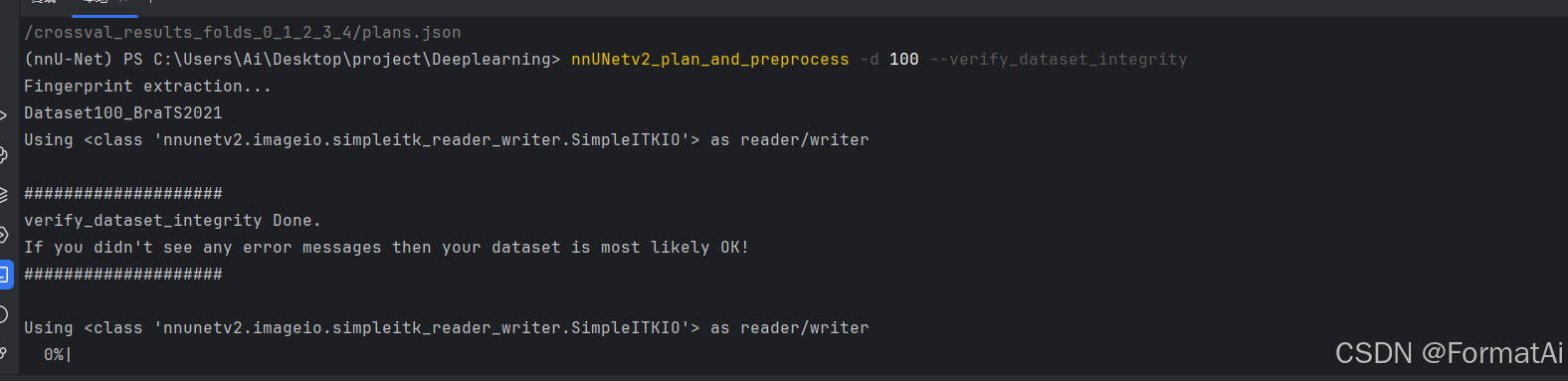
这里系统会提示
Dropping 3d_lowres config because the image size difference to 3d_fullres is too small.
INFO: Configuration 3d_lowres not found in plans file nnUNetPlans.json of dataset Dataset100_BraTS2021. Skipping.
这里是因为nnU-Net觉得数据中lowres的分辨率和3d_fullers的分辨率差别不大,因此跳过3d_lowres的预处理
所以为了彻底解决这类提示,应该对BraTS2021数据集进行部分的重采样,降低分辨率。(暂时没有做出来)
为了实现the 3D full resolution U-Net of the cascade,
提出解决方案,在nnUNetPlans.json新建3d_lowers的plan,重新运行预处理命令,可以得到3d_lowers的预处理数据。
nnUNetPlans.json位置 :nnUNet\nnUNetFrame\nnUNet_preprocessed\数据集名称(例如:Dataset100_BraTS2021)

训练数据集:
包括三种U-Net网络配置,分别是2D U-Net,3D全分辨率U-Net,3D
U-Net级联(包括3D低分辨率U-Net和3D全分辨率U-Net),要进行级联下的3D全分辨率U-Net需先完成3D低分辨率U-Net。注意不是所有的数据集都能触发级联,在完成数据集预处理的图中可以看到,本数据集仅有2d和3d_fullres,3d_lowres,对于部分数据集来说,还有3d_lowres, 3d_cascade_fullres
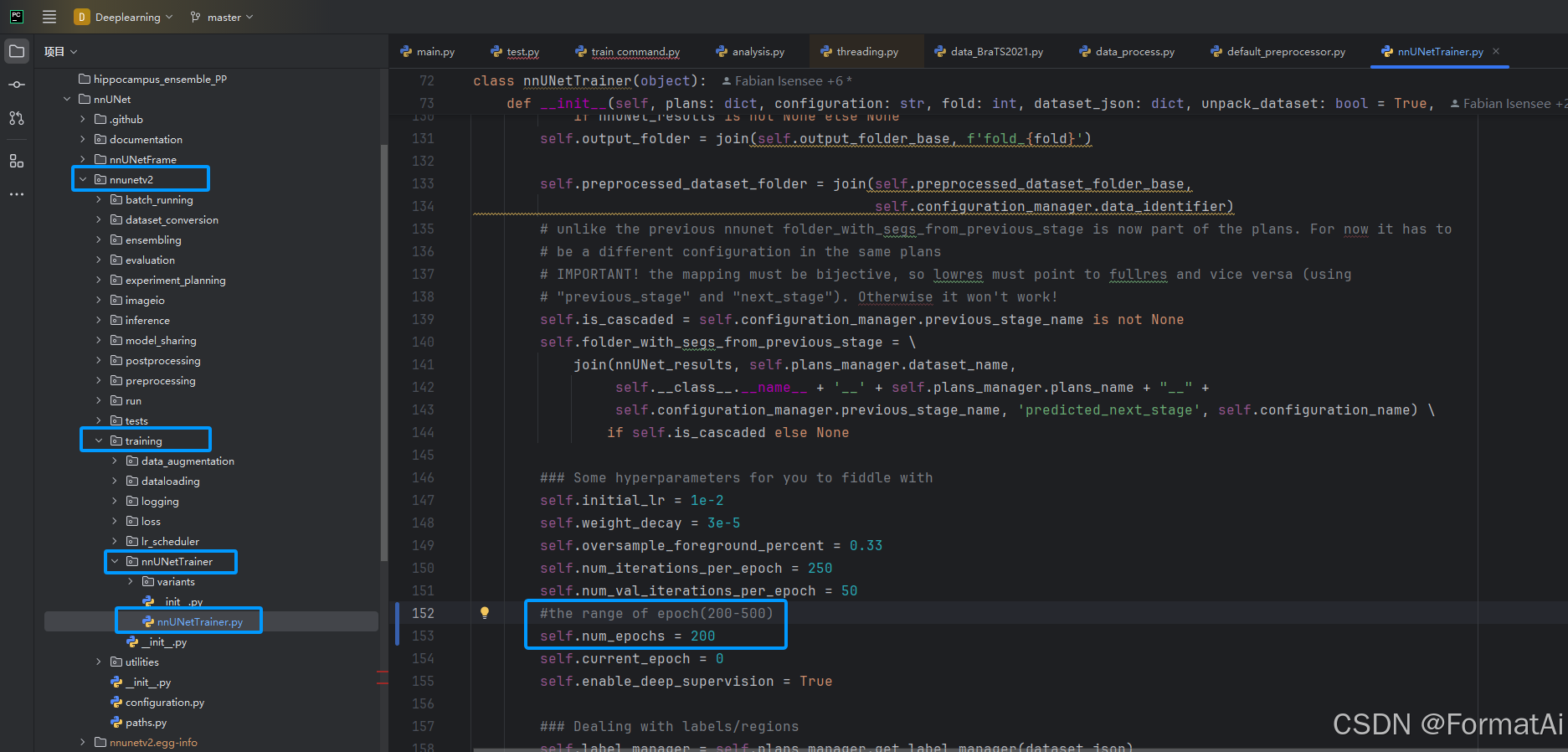
在开始训练之前,我们需要修改epoch,epoch初始默认为1000,这样会极大延长训练时间
推荐在200-500个epoch之间,不要过高或过低
nnUNetv2_train 100 UNET_CONFIGURATION FOLD -npz
UNET_CONFIGURATION为选择的训练设置
有以下可选项:
2d
3d_fullres
3d_lowres
3d_cascade_fullres
FOLD为0至4的数字,代表第几折,因为nnUNet采用了五折交叉验证,每次训练后都会得到一个模型,一共五个,对这五个模型在验证集上的性能进行评估,得到可靠的模型性能指标。
Note that the 3D full resolution U-Net of the cascade requires the five folds of the low resolution U-Net to be completed!
要想进行3d_cascade_fullres的训练,必须先完成3d_lowres
实例命令:
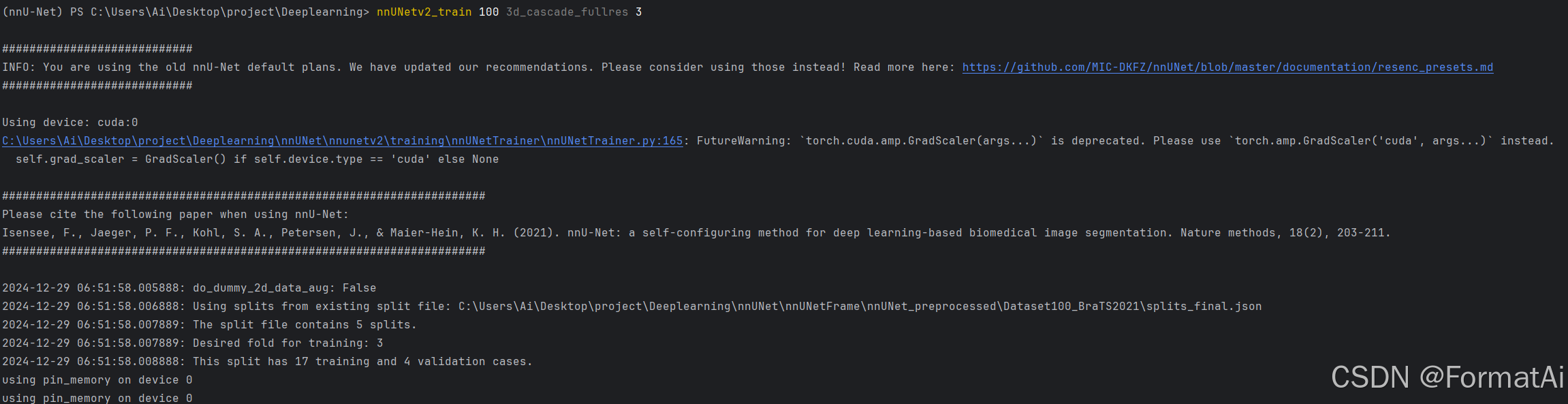
nnUNetv2_train 100 3d_fullres 0
训练正常启动如下:
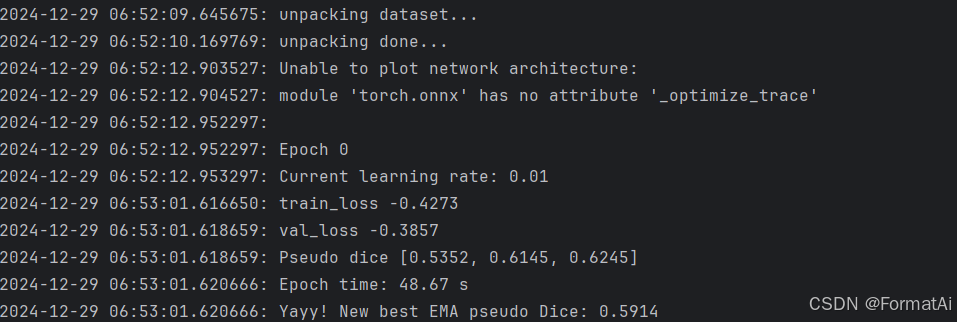
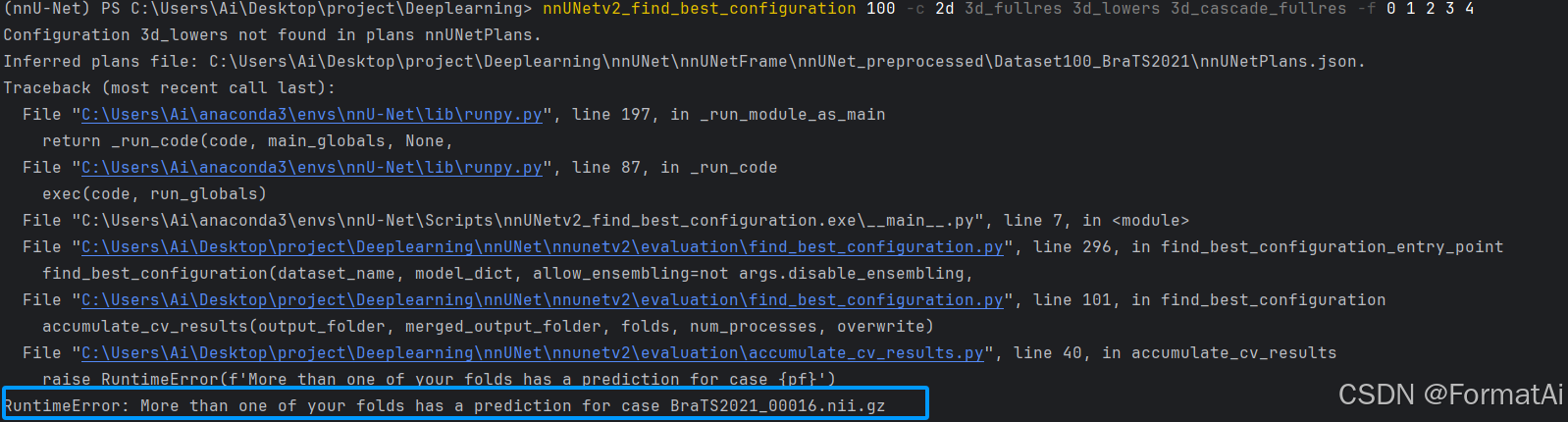
心得:若是重新启动了同一个数据集的模拟,建议清空所属results文件夹,不然模型寻优的时候会出现以下结果
RuntimeError: More than one of your folds has a prediction for case BraTS2021_00016.nii.gz
验证、推理和模型寻优
可以使用如下命令,这里用明确指定所有折-f 0 1 2 3 4,避免 nnU-Net 自动寻找 fold all(集成文件夹)
验证
对训练完后的模型输入以下命令(例如100数据集只训练了2d和3d_fullers,就输入以下命令)
nnUNetv2_train 100 2d 0 --val --npz
nnUNetv2_train 100 2d 1 --val --npz
nnUNetv2_train 100 2d 2 --val --npz
nnUNetv2_train 100 2d 3 --val --npz
nnUNetv2_train 100 2d 4 --val --npz
nnUNetv2_train 100 3d_fullres 0 --val --npz
nnUNetv2_train 100 3d_fullres 1 --val --npz
nnUNetv2_train 100 3d_fullres 2 --val --npz
nnUNetv2_train 100 3d_fullres 3 --val --npz
nnUNetv2_train 100 3d_fullres 4 --val --npz
nnUNetv2_train 100 3d_cascade_fullres 0 --val --npz
nnUNetv2_train 100 3d_cascade_fullres 1 --val --npz
nnUNetv2_train 100 3d_cascade_fullres 2 --val --npz
nnUNetv2_train 100 3d_cascade_fullres 3 --val --npz
nnUNetv2_train 100 3d_cascade_fullres 4 --val --npz
模型寻优
nnUNetv2_find_best_configuration 100
nnUNetv2_find_best_configuration 100 -c 2d 3d_fullres 3d_lowres 3d_cases_fullres -f 0 1 2 3 4
你会得到
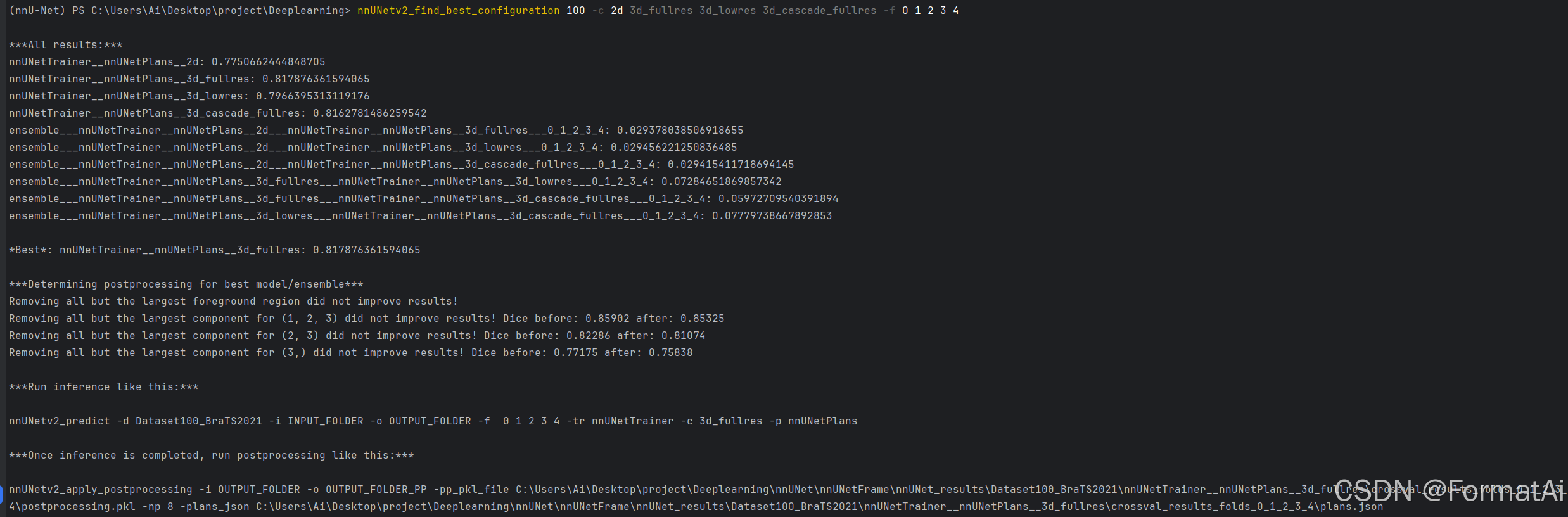
Best: nnUNetTrainer__nnUNetPlans__3d_fullres: 0.817876361594065
Determining postprocessing for best model/ensemble Removing all but the largest foreground region did not improve results! Removing
all but the largest component for (1, 2, 3) did not improve results!
Dice before: 0.85902 after: 0.85325 Removing all but the largest
component for (2, 3) did not improve results! Dice before: 0.82286
after: 0.81074 Removing all but the largest component for (3,) did not
improve results! Dice before: 0.77175 after: 0.75838Run inference like this:
nnUNetv2_predict -d Dataset100_BraTS2021 -i INPUT_FOLDER -o
OUTPUT_FOLDER -f 0 1 2 3 4 -tr nnUNetTrainer -c 3d_fullres -p
nnUNetPlansOnce inference is completed, run postprocessing like this:
nnUNetv2_apply_postprocessing -i OUTPUT_FOLDER -o OUTPUT_FOLDER_PP
-pp_pkl_file C:\Users\Ai\Desktop\project\Deeplearning\nnUNet\nnUNetFrame\nnUNet_results\Dataset100_BraTS2021\nnUNetTrainer__nnUNetPlans__3d_fullres\crossval_results_folds_0_1_2_3_4\postprocessing.pkl
-np 8 -plans_json C:\Users\Ai\Desktop\project\Deeplearning\nnUNet\nnUNetFrame\nnUNet_results\Dataset100_BraTS2021\nnUNetTrainer__nnUNetPlans__3d_fullres\crossval_results_folds_0_1_2_3_4\plans.json
(nnU-Net) PS C:\Users\Ai\Desktop\project\Deeplearning>
nnUNetv2_evaluate -d 100 -c 3d_fullres -f 0 1 2 3 4
你也可以在nnUNet_results/DATASET_NAME可以找到inference_instructions.txt,内有预测时建议使用的命令。

找到最佳预测,推理后续代码
推理预测
nnUNetv2_predict -d Dataset00100_BraTS2021 -i INPUT_FOLDER -o OUTPUT_FOLDER -f 0 1 2 3 4 -tr nnUNetTrainer -c 3d_fullres -p nnUNetPlans
例子
nnUNetv2_predict -i C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFrame/nnUNet_raw/Dataset100_BraTS2021/imagesTs -o C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFrame/nnUNet_results/BraTS2021_3d_predict -d 100 -c 3d_lowres -f 0 1 2 3 4 --save_probabilities
nnUNetv2_ensemble -i hippocampus_2d_predict hippocampus_3d_fullres_predict -o hippocampus_ensemble -np 8
例子
nnUNetv2_ensemble -i C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFrame/nnUNet_results/BraTS2021_3d_predict -o C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFrame/nnUNet_results/BraTS2021_3d_ensemble -np 8
nnUNetv2_apply_postprocessing -i C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFrame/nnUNet_results/BraTS2021_3d_ensemble -o C:/Users/Ai/Desktop/project/Deeplearning/nnUNet/nnUNetFram
e/nnUNet_results/BraTS2021_3d_ensemble_PP -pp_pkl_file C:\Users\Ai\Desktop\project\Deeplearning\nnUNet\nnUNetFrame\nnUNet_results\Dataset100_BraTS2021\nnUNetTrainer__nnUNetPlans__3d_fullres\crossval_results_folds_0_1_2_3_4\postprocessing.pkl -np 8 -plans_json C:\Users\Ai\Desktop\project\Deeplearning\nnUNet\nnUNetFrame\nnUNet_results\Dataset100_BraTS2021\nnUNetTrainer__nnUNetPlans__3d_fullres\crossval_results_folds_0_1_2_3_4\plans.json
在对应nnUNet_results文件夹查看dice值,progress.png以及其他数据。
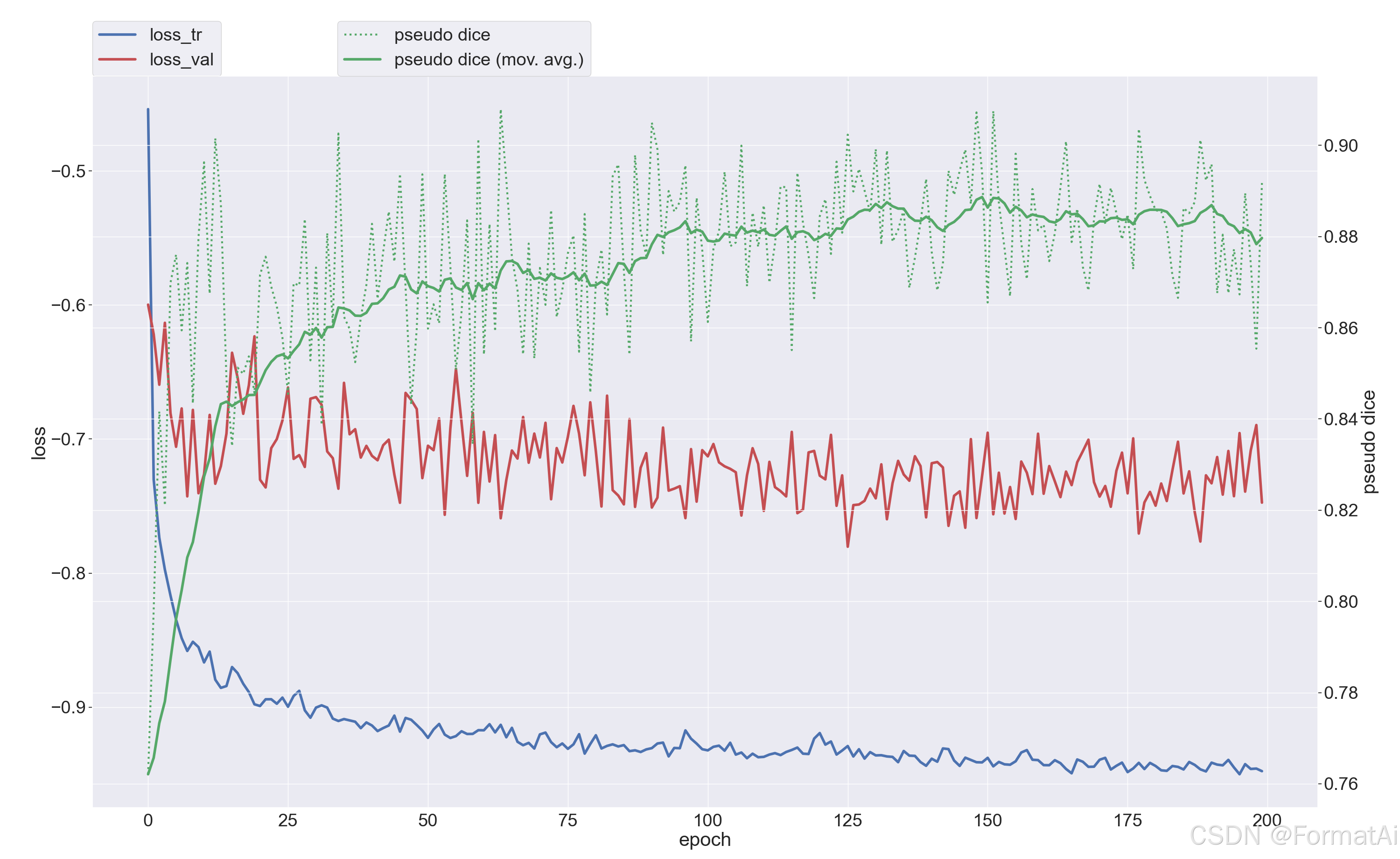
summary.json: 包含验证集的指标(如 Dice、Hausdorff 距离等)

prediction_n.nii.gz: 模型对验证集样本的预测结果,保存为 NIfTI 格式文件
如有其他心得后续继续更新
写在起起伏伏的2024年,能够为今年划上完美的句号
所有的前进都可能伴随着苦痛和弯曲
未来的道路也不会是阔野坦途
道之所在,虽千万人吾往矣
祝大家2025年新年快乐

















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









