






计算机组成原理 | 硬件电路整理
- 桶形移位器原理图
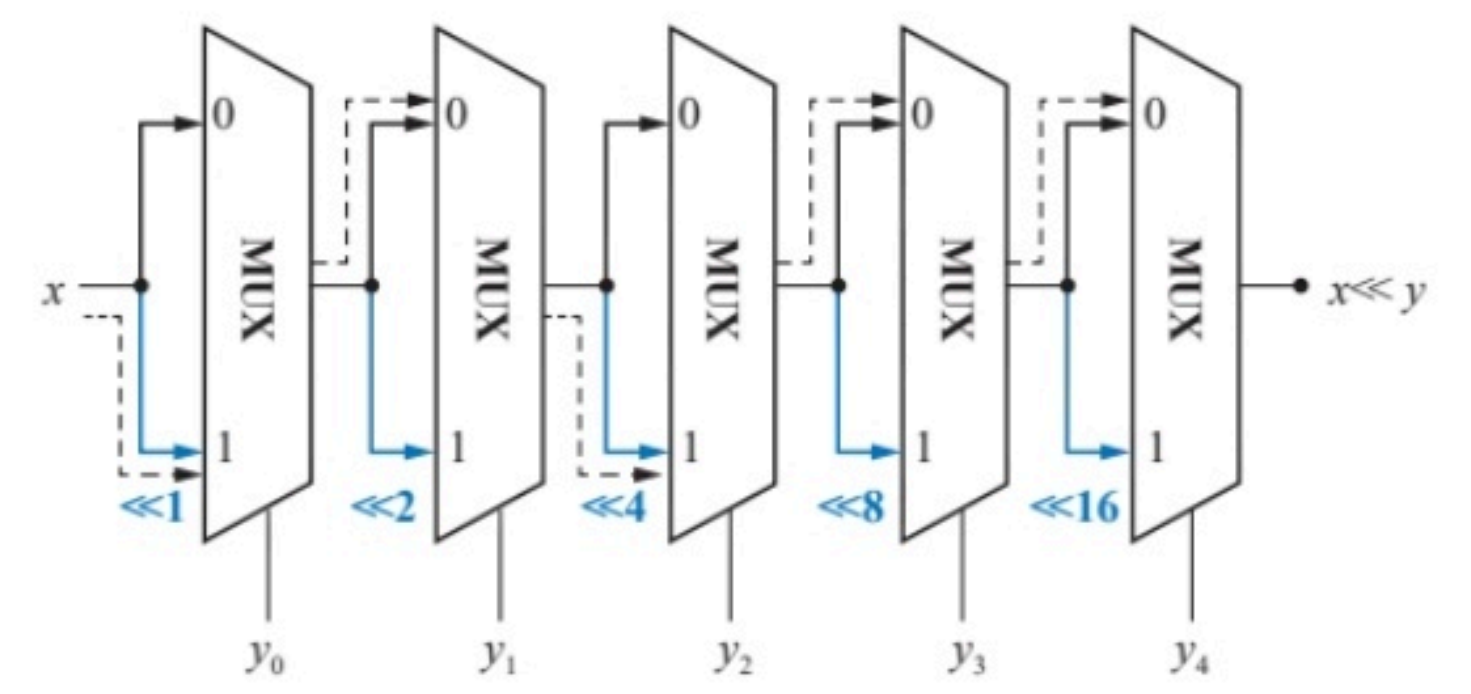
桶形移位器是纯组合逻辑电路,该电路巧妙地利用5个二路选择器串联构成,移位参数
y
y
y的5个二进制位、为
y
1
,
y
2
,
y
3
,
y
4
,
y
5
y_1,y_2,y_3,y_4,y_5
y1,y2,y3,y4,y5分别连接到5个二路选择器的选择控制端,而二路选择器的两个输入端分别对应前一级二路选择器的输出,以及该输出按当前选择控制位对应权值进行移位后的结果。图中虚线所示的路径为x<<5的运算路径。相比位运算的一级逻辑门电路实现,移位运算逻辑需要5个二路选择器的时间延迟,一个二路选择器需要2级基本门电路延迟,所以 32 位可变移位器的时间延迟为10级门电路延迟,时间略长。
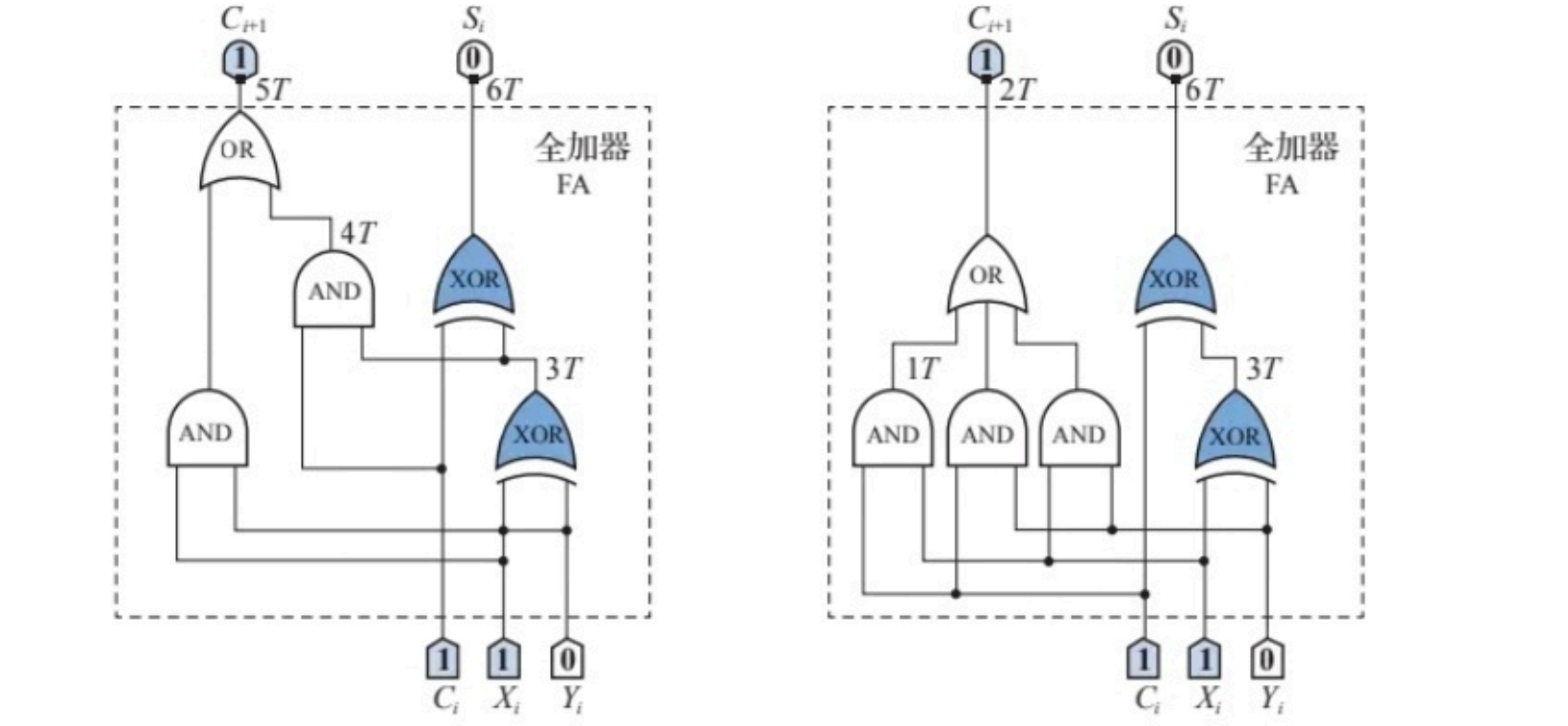
- 全加器逻辑框图
S
i
=
X
i
⊕
Y
i
⊕
C
i
C
i
+
1
=
X
i
Y
i
+
(
X
i
+
Y
i
)
C
i
C
i
+
1
=
X
i
Y
i
+
(
X
i
⊕
Y
i
)
C
i
S_i=X_i \oplus Y_i \oplus C_i \\ C_{i+1}=X_iY_i+(X_i+Y_i)C_i \\ C_{i+1}=X_iY_i+(X_i \oplus Y_i)C_i
Si=Xi⊕Yi⊕CiCi+1=XiYi+(Xi+Yi)CiCi+1=XiYi+(Xi⊕Yi)Ci
对于
n
n
n位串行加法器,高位的全加器必须等待低位进位后才能开始运算,注意当进位信号产生时,已经经过了5T,考虑组合逻辑电路的并行性,所有位的
X
i
⊕
Y
i
X_i \oplus Y_i
Xi⊕Yi都已并行运算完毕,此时只需要经过一个异或门时间延迟 3T就可以得到当前位的和,再经过2T的时间延迟就可以生成进位输出信号。
- 多位可控加减法电路逻辑框图
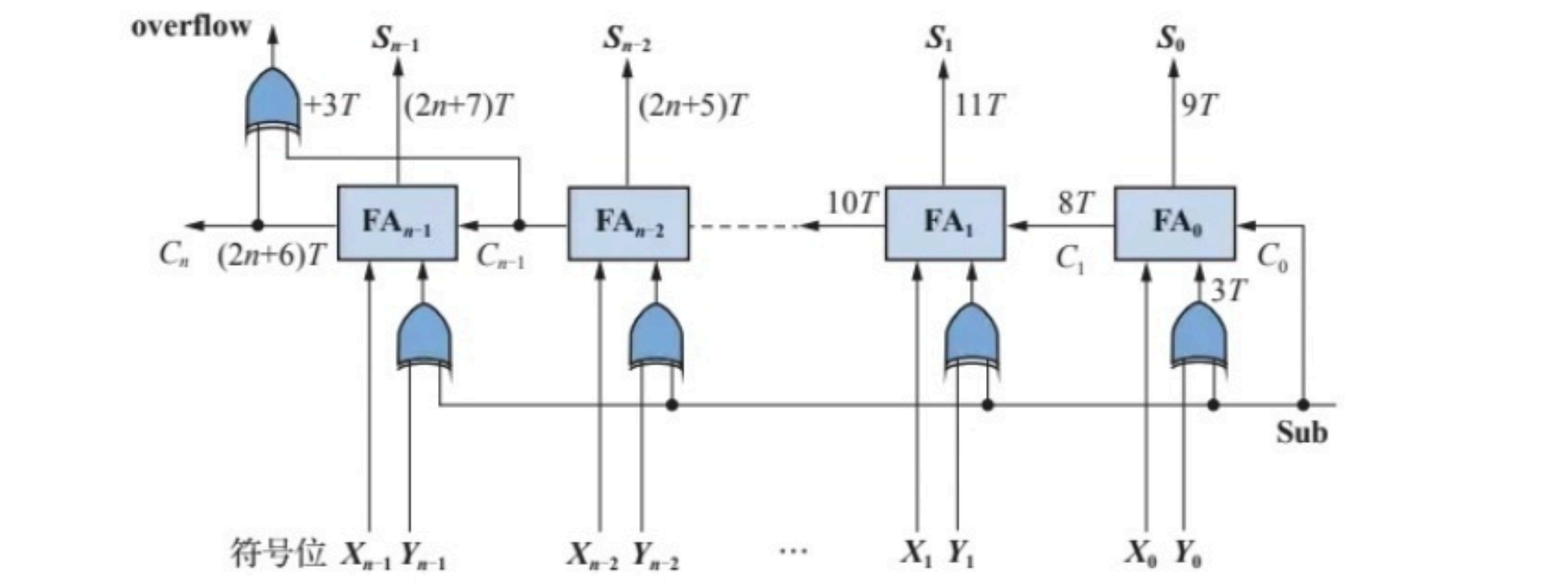
图所示是多位可控加减法电路逻辑框图,该电路在n位串行加法器中引入
S
u
b
Sub
Sub控制信号,操作数
Y
Y
Y的所有位
Y
i
Y_i
Yi均与
S
u
b
Sub
Sub信号进行异或后被送入
n
n
n位串行加法器。当
S
u
b
=
0
Sub=0
Sub=0时,送入加法器的是
Y
Y
Y本身;当
S
u
b
=
1
Sub=1
Sub=1时,送入加法器的是
Y
Y
Y的反码。另外
S
u
b
Sub
Sub 连接到加法器最低位的进位输入,实现了对
Y
Y
Y操作数逐位取反、末位加1的求补过程,从而完成减法操作。而当
S
u
b
=
0
Sub=0
Sub=0时低位进位为0,不影响加法结果的正确性。
- 可级联的4位先行进位电路
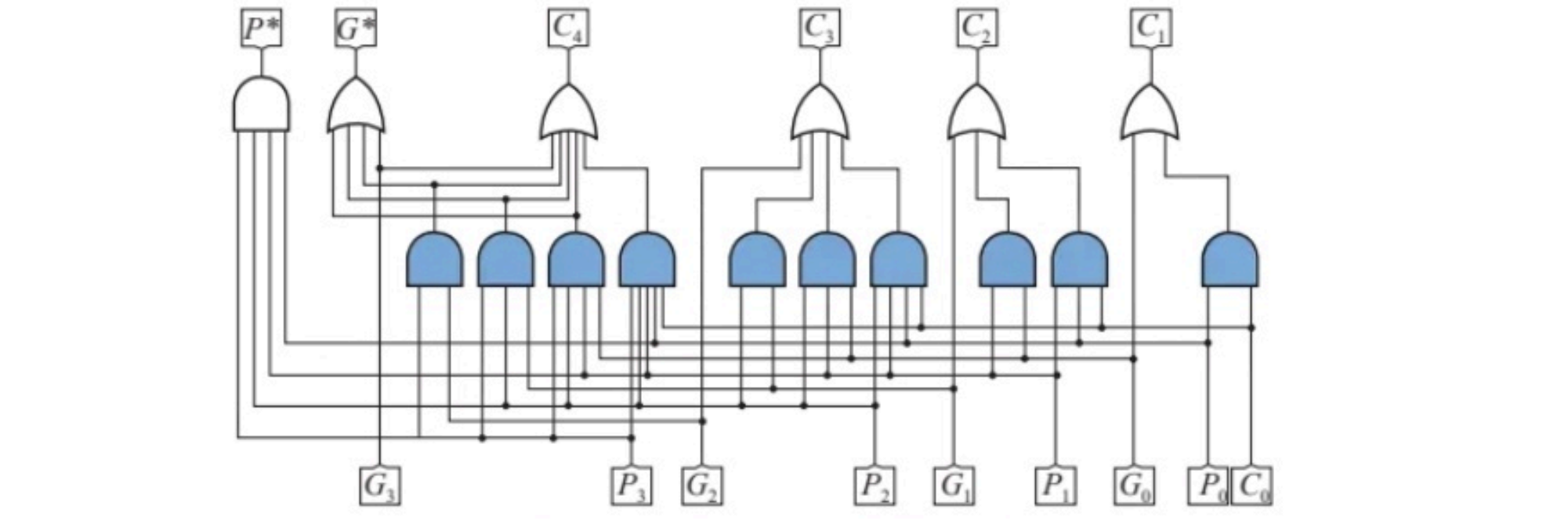
假设
G
i
=
X
i
Y
i
,
P
i
=
X
i
⊕
Y
i
G_i=X_iY_i,P_i=X_i \oplus Y_i
Gi=XiYi,Pi=Xi⊕Yi。当
G
i
=
1
G_i=1
Gi=1时,
C
i
+
1
C_{i+1}
Ci+1一定为1,所以将
G
G
G,称为进位生成函数;当
P
i
=
1
P_i=1
Pi=1时也就是
X
i
、
Y
i
X_i、Y_i
Xi、Yi相异时,进位输入信号
C
i
C_i
Ci才能传递到进位输出
C
i
+
1
C_{i+1}
Ci+1处,所以将
P
i
P_i
Pi称为进位传递函数,有了进位生成函数和传递函数,有如下公式:
S
i
=
P
i
⊕
C
i
C
i
+
1
=
G
i
+
P
i
C
i
C
n
=
G
n
−
1
+
P
n
−
1
G
n
−
2
+
P
n
−
1
P
n
−
2
G
n
−
3
.
.
.
P
n
−
1
P
n
−
2
.
.
.
P
1
P
0
C
0
S_i=P_i \oplus C_i \quad C_{i+1}=G_i+P_iC_i\\ C_n=G_{n-1}+P_{n-1}G_{n-2}+P_{n-1}P_{n-2}G_{n-3}...P_{n-1}P_{n-2}...P_1P_0C_0
Si=Pi⊕CiCi+1=Gi+PiCiCn=Gn−1+Pn−1Gn−2+Pn−1Pn−2Gn−3...Pn−1Pn−2...P1P0C0
G ∗ G* G∗称为成组进位生成函数, P ∗ P* P∗生成成组进位传递函数。
- 4位快速加法器
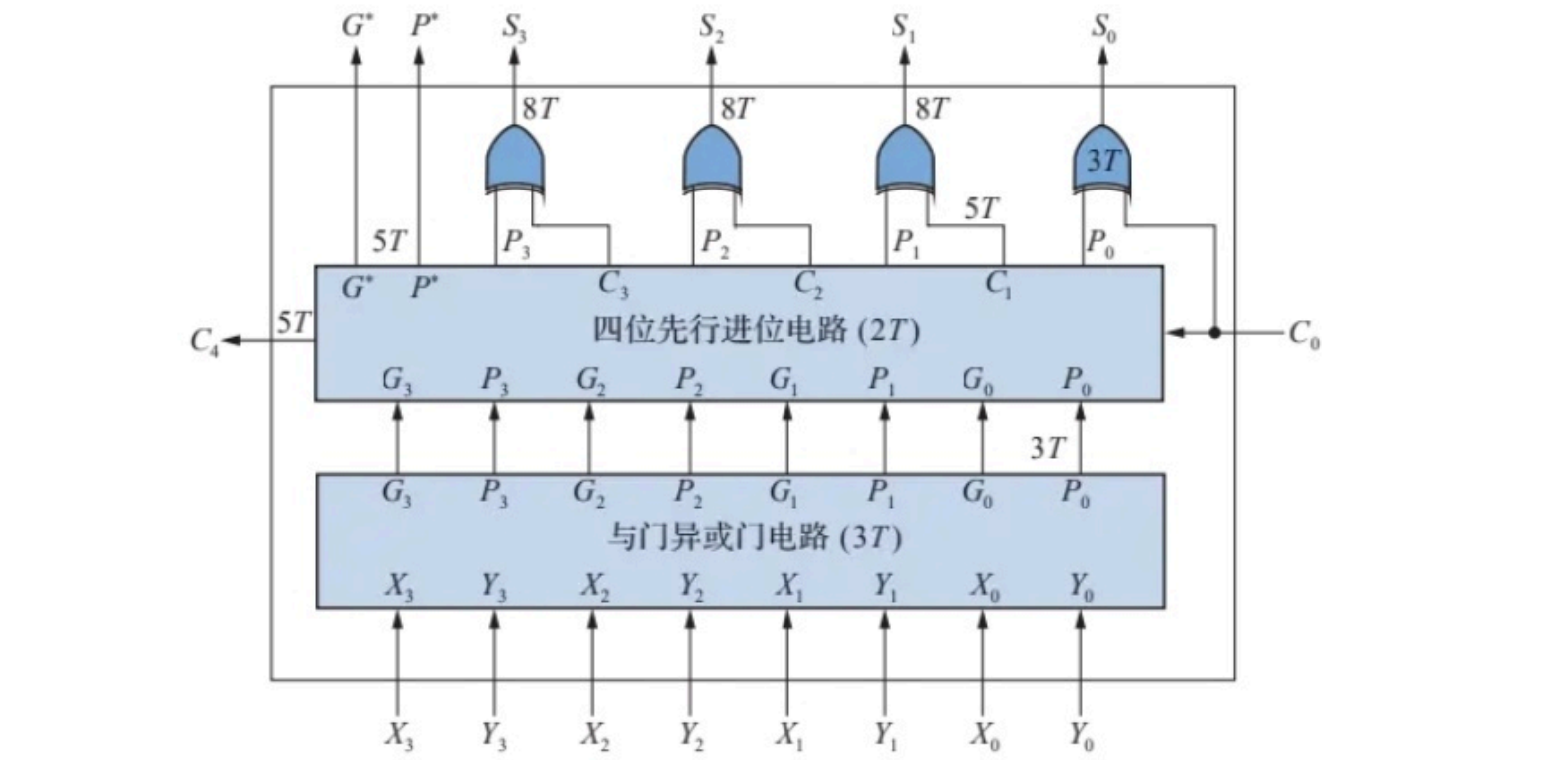
- 16位组内并行、组间并行加法器
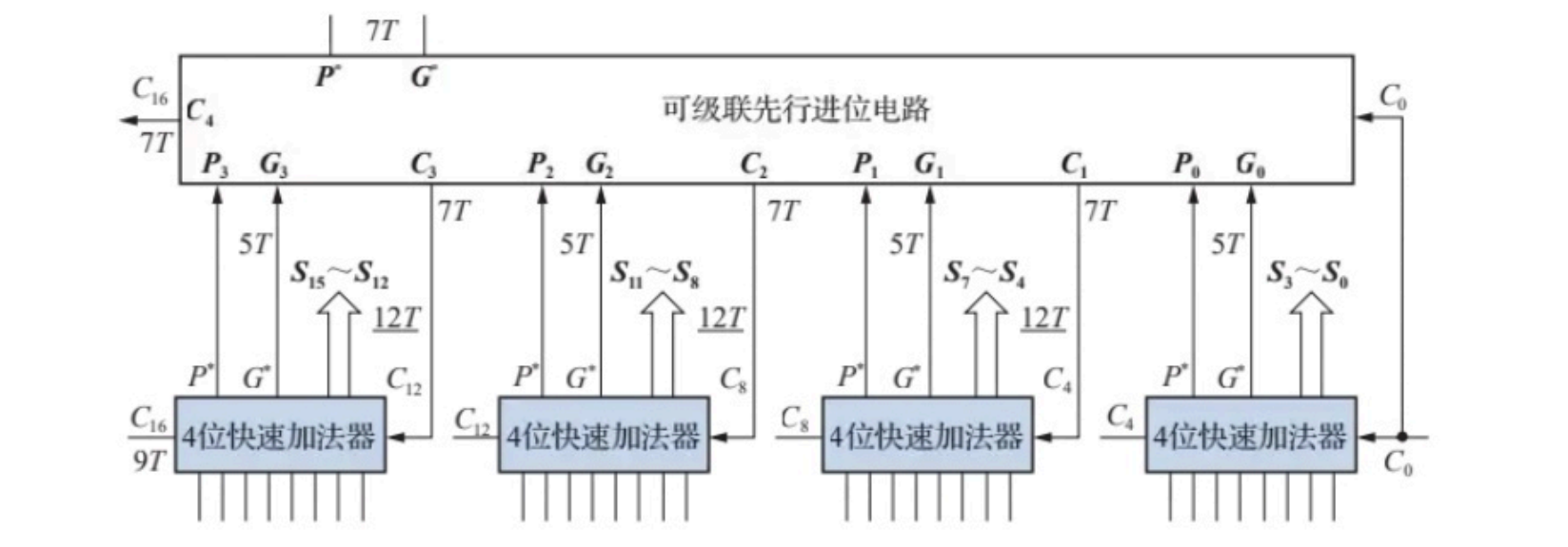
注意图中所有4位快速加法器产生成组生成的进位函数 G ∗ , P ∗ G^*,P^* G∗,P∗的时间延迟为5T,而先行进位电路的时间延迟为 2 T 2T 2T,所以生成 C 4 、 C 8 、 C 12 、 C 16 C_4、C_8、C_{12}、C_{16} C4、C8、C12、C16的时间延迟为7T。当这些信号就绪后,此时4位快速加法器内部的与门异或门电路已经运算完毕,需要2T生成进位输出信号,需要5T输出和数,因此,整个电路的关键时间延迟为和数信号的时间延迟12T。相比16位组内并行、组间串行加法器,其关键时间延迟少了2T。如果采用这种方式进一步级联构成 64位快速加法器,则时间延迟为16T。
- 实现原码一位乘法的逻辑框图
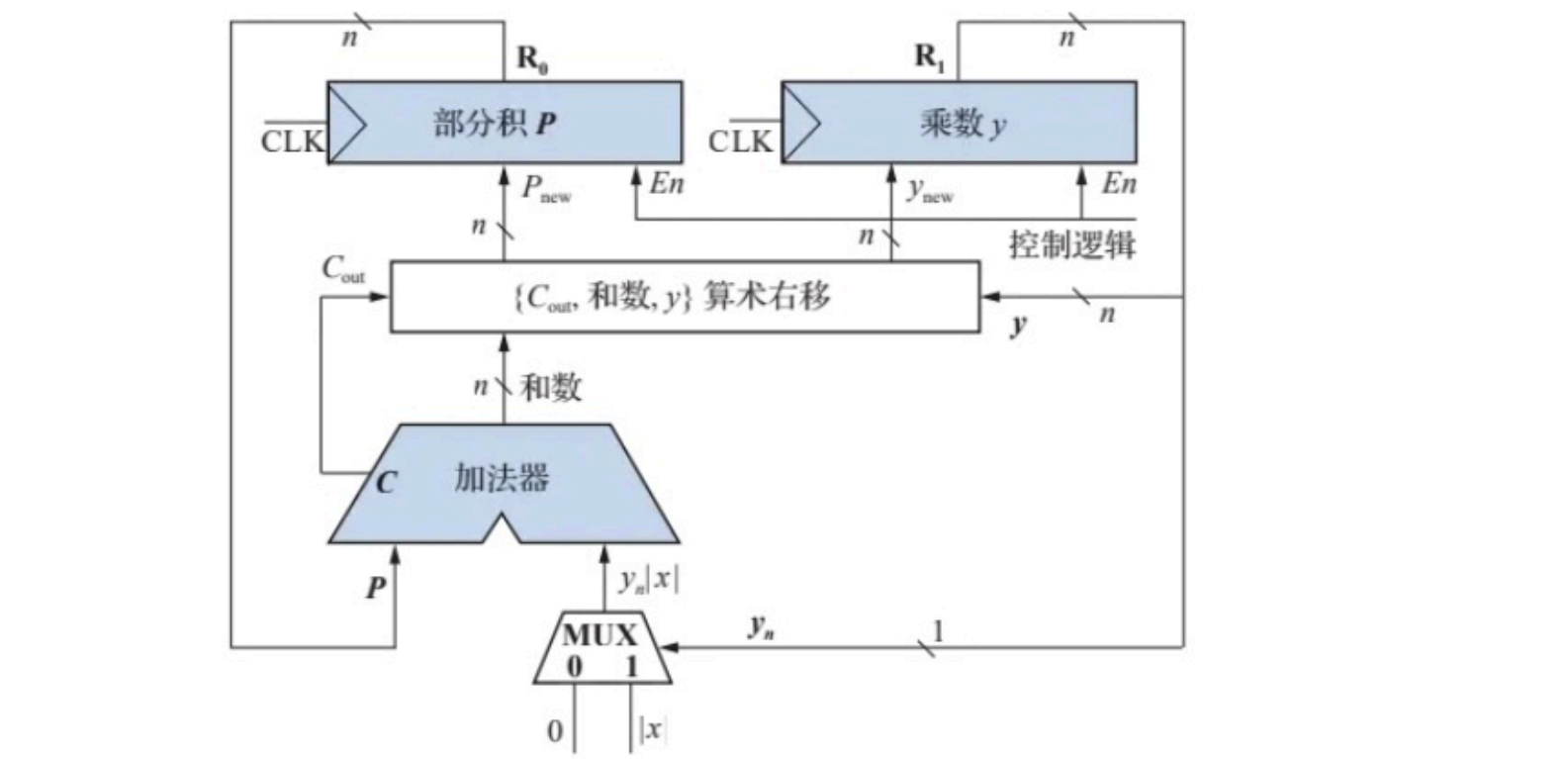
图中
n
n
n位寄存器
R
0
R_0
R0存放部分积
P
,
n
P,n
P,n位寄存器
R
1
R_1
R1,存放乘数
y
y
y,最低位
y
n
y_n
yn为判断位。注意寄存器是时序逻辑,需要连接时钟信号,用蓝色表示,当使能控制端
E
n
=
1
En=1
En=1,时钟触发时输入端数据会载入寄存器。
n
n
n位加法器实现部分积的累加
P
=
P
+
y
n
∣
x
∣
P=P+y_n|x|
P=P+yn∣x∣一个操作数来自
R
0
R_0
R0中的部分积
P
P
P,另一个操作数为
y
n
∣
x
∣
y_n|x|
yn∣x∣,由
y
n
y_n
yn通过多路选择器选择实现。加法器进位输出
C
o
u
t
C_{out}
Cout、运算结果以及寄存器
y
y
y的值 同步算术右移一位,移位结果的高
n
n
n位数据
P
n
e
w
P_{new}
Pnew送入
R
0
R_0
R0,的输入端,低
n
n
n位数据
y
y
y送入
R
1
R_1
R1,的输入端。
控制逻辑受时钟驱动,负责循环计数和算术移位结果的载入控制,加法器和算术移位逻辑是组合逻辑,会自动进行累加与算术右移操作。但运算结果必须由控制逻辑控制使能端并配合时钟才能载入寄存器
R
0
、
R
1
R_0、R_1
R0、R1中,控制逻辑必须保证前
n
n
n个时钟
E
n
=
1
En=1
En=1,第
n
+
1
n+1
n+1个时钟之后
E
n
=
0
En=0
En=0,这样
2
n
2n
2n位乘积会最终锁存在
R
0
、
R
1
R_0、R_1
R0、R1,这两个
n
n
n位寄存器中。
原码一位乘(n+1位乘):符号位不参与运算,需单独计算符号位;数值为加一次,右移一次,总共进行n次最终结果为2n位加符号位2n+1位。
- 补码一位乘法的逻辑框图
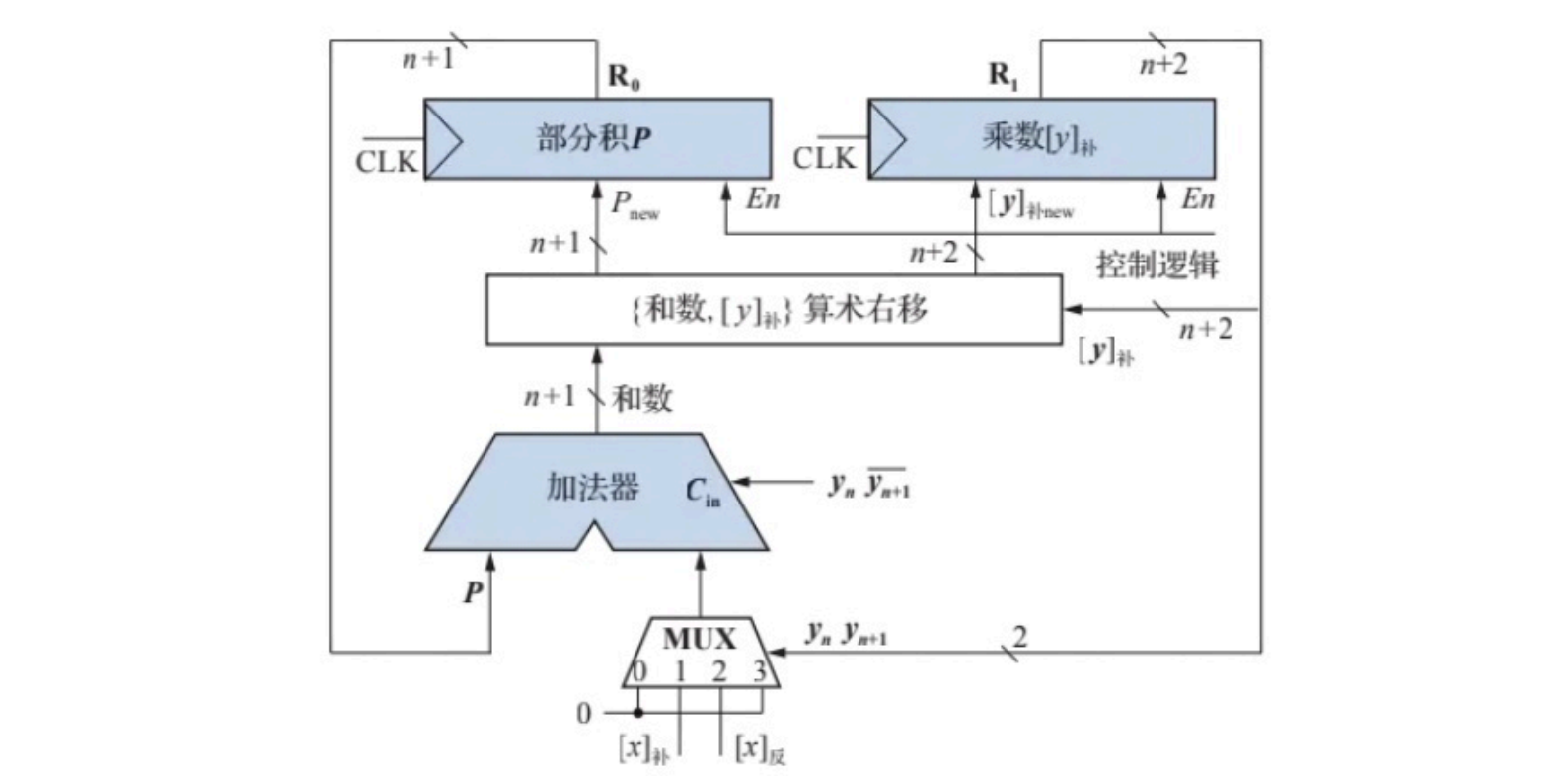
补码一位乘法器和原码一位乘法器逻辑结果十分相似,有几处不同。如 R 0 R_0 R0有 n + 1 n+1 n+1包括符号位, R 1 R_1 R1有 n + 2 n+2 n+2位包括符号位和补充的 y n + 1 y_{n+1} yn+1。运算器输入添加了一个多路选择逻辑, y n y n + 1 y_ny_{n+1} ynyn+1为00或11时输入为0,当 y n y n + 1 y_ny_{n+1} ynyn+1为01时输入为 [ x ] 补 [x]_补 [x]补,当 y n y n + 1 y_ny_{n+1} ynyn+1为10时输入为 [ x ] 补 ‾ \overline{[x]_补} [x]补同时 c i n = y n y n + 1 ‾ c_{in}=y_n \overline{y_{n+1}} cin=ynyn+1即输入 − [ x ] 补 = [ − x ] 补 -[x]_补=[-x]_补 −[x]补=[−x]补
补码一位乘法(n+1位乘):符号位参与运算,不需要单独计算符号位;
计算 [ x ] 补 , [ − x ] 补 = [ [ x ] 补 ] 补 , [ y ] 补 [x]_补,[-x]_补=[[x]_补]_补,[y]_补 [x]补,[−x]补=[[x]补]补,[y]补,同时 [ y ] 补 [y]_补 [y]补添加一位 y n + 1 = 0 y_{n+1}=0 yn+1=0,
加n+1次,右移n次,最后一次加不右移。结果2n+1位符号位包含在数值运算结果中。
{ P , y } = { ( P + ( y n + 1 − y n ) [ x ] 补 ) , y } / 2 \{P,y\}=\{(P+(y_{n+1}-y_{n})[x]_补),y\}/2 {P,y}={(P+(yn+1−yn)[x]补),y}/2
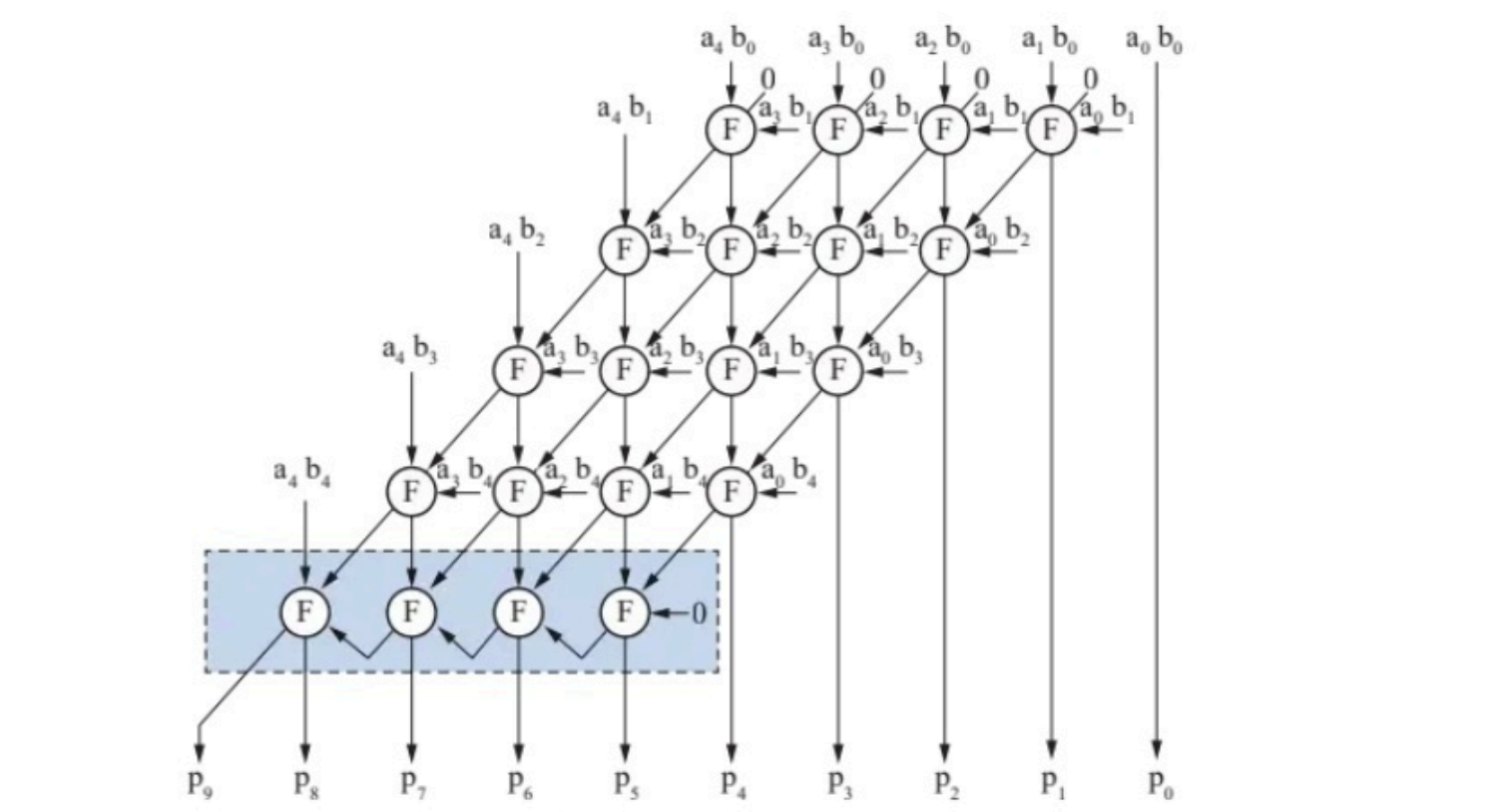
- 无符号数阵列乘法器
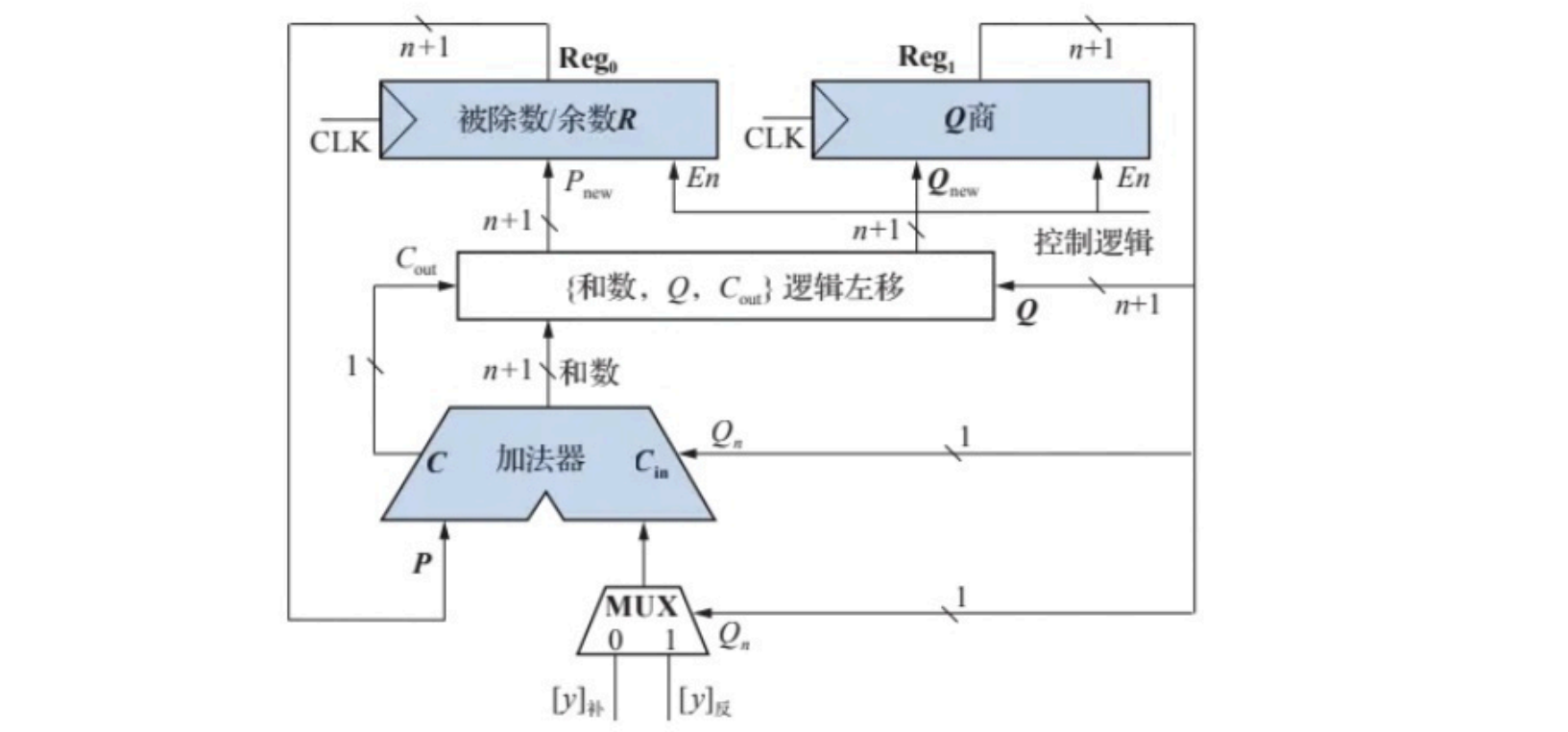
- 原码不恢复余数法硬件逻辑框图
如果
R
1
≥
0
R_1 ≥ 0
R1≥0,上商位
q
i
=
1
q_i=1
qi=1,则将余数
R
R
R左移一位再减除数
y
y
y,得到新余数
R
i
+
1
R_{i+1}
Ri+1,具体计算过程如下:
R
i
+
1
=
2
R
i
−
y
(
R
i
≥
0
)
R_{i+1}=2R_i-y \quad (R_i \geq 0)
Ri+1=2Ri−y(Ri≥0)
如果
R
i
<
0
R_i<0
Ri<0,上商位
q
i
=
0
q_i=0
qi=0,应将余数
R
i
R_i
Ri先加上除数
y
y
y然后恢复余数,再左移一位后减除数
y
y
y得到新余数
R
i
+
1
R_{i+1}
Ri+1,具体计算过程如下:
R
i
+
1
=
2
(
R
i
+
y
)
⏟
恢复余数
−
y
=
2
R
i
+
y
(
R
i
<
0
)
R_{i+1}=2\underbrace{(R_i+y)}_{\text{恢复余数}}-y=2R_i+y \quad (R_i < 0)
Ri+1=2恢复余数
(Ri+y)−y=2Ri+y(Ri<0)
实现原码不恢复余数法的硬件逻辑框图如图所示。其中寄存器
R
e
g
0
Reg_0
Reg0,在除法开始前存放被除数
x
x
x,在运算过程中存放余数
R
R
R;商存放在
R
e
g
1
Reg_1
Reg1中。加法器进行什么运算由商寄存器最低位
Q
n
Q_n
Qn决定
Q
n
Q_n
Qn的值是上一步运算所上的商。当
Q
n
=
1
Q_n=1
Qn=1时,下一步减
∣
y
∣
|y|
∣y∣,这里减法采用反码末位加1 的方式实现;当
Q
n
=
0
Q_n=0
Qn=0时,则下一步进行加
∣
y
∣
|y|
∣y∣的操作。注意
Q
n
Q_n
Qn初始值应该为1,以保证第一次运算为减法。而当前运算的上商位由加法器进位位
C
o
u
t
C_{out}
Cout决定,和数、
Q
Q
Q、加法器进位位
C
o
u
t
C_{out}
Cout同步左移后,高位部分
P
n
e
w
P_{new}
Pnew被送入余数寄存器R中,低位部分
Q
n
e
w
Q_{new}
Qnew被送入商寄存器
Q
Q
Q中,在时钟到来时载入,这样每次新的上商位
C
o
u
t
C_{out}
Cout都可以加载到商寄存器
Q
Q
Q的
Q
n
Q_n
Qn位。
原码恢复余数法(n+1位除):商初始化n+1位包括符号位(最后一位运算过程中不会变),符号位单独计算 x 0 ⊕ y 0 x_0 \oplus y_0 x0⊕y0。原码除法需要计算 ∣ x ∣ , [ ∣ y ∣ ] 补 , [ − ∣ y 补 ∣ ] |x|,[|y|]_补,[-|y_补|] ∣x∣,[∣y∣]补,[−∣y补∣]。加n+1次,左移n次,最后一次加不左移。结果商n位,加符号位n+1位和一个n+1位的余数。
注意:运算结果中余数如果位负数,需要一次余数恢复。
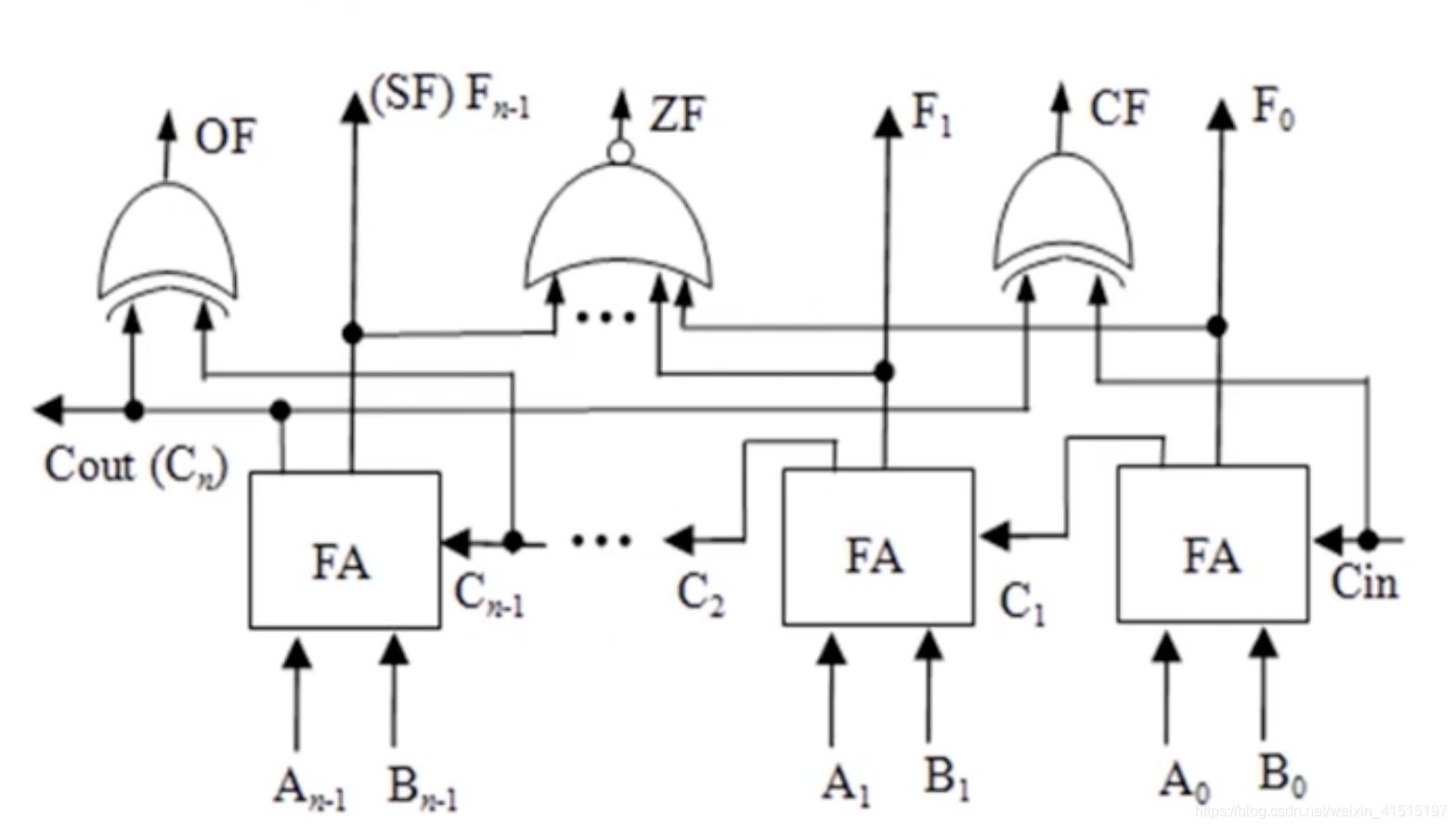
- 基本算数逻辑运算单元
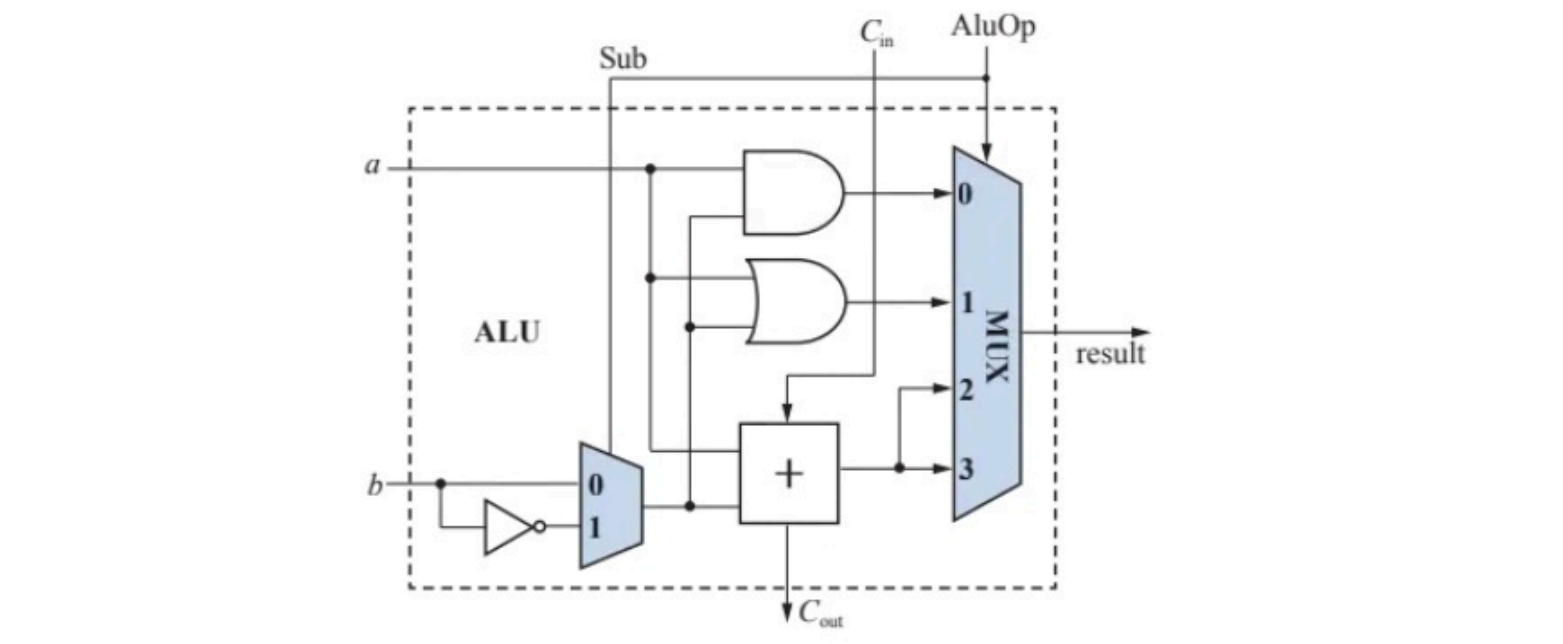
- n位ALU
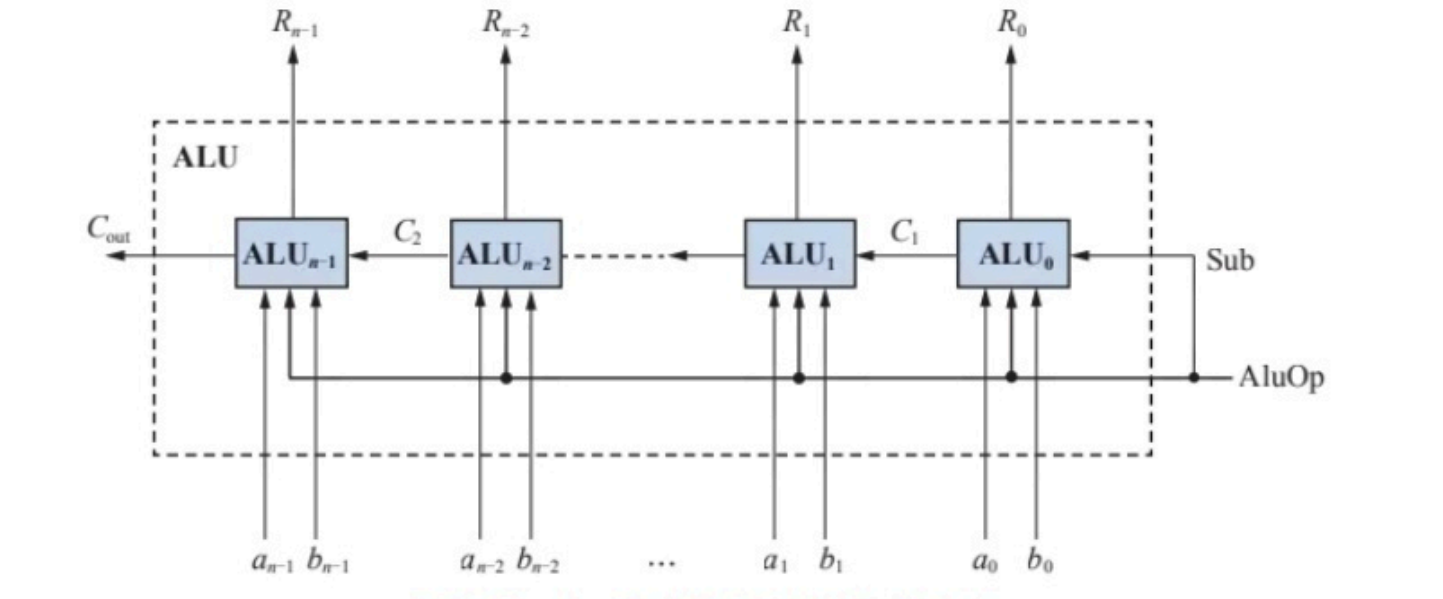
- 六管SRAM存储单元
-
电路状态
假设 A 点为高电位,根据 MOS管特性,栅极高电位则源级和漏极导通,低电位则截止,所以 A 点高电位使 T 2 T_2 T2, 管导通,B点与接地端导通,变成低电位;而B点的低电位又使 T 1 T_1 T1管截止A 点的高电位和漏极接地端隔离。这样 T 1 、 T 2 T_1、T_2 T1、T2,管一个截止、一个导通,A点高电位,B 点低电位,形成一个稳定的状态,用来存储数据“1”。由于电路是对称的,因此当B点为高电位时,A 点则为低电位,也可以构成另一个稳态,可用这个状态表示数据“0”。注意带电情况下,A、B 点电平信号相同时的状态都是不稳定状态,电路最终会变成稳定状态。
-
信息保持
当不对存储单元进行读写操作时,不用给出行、列选通信号,门控管 T 5 T_5 T5~ T 8 T_8 T8截止,电源Vcc通过负载管 T 3 、 T 4 T_3、T_4 T3、T4,不断为 T 1 T_1 T1 或 T 2 T_2 T2,提供电流,以保存信息。只要电源不断,存储单元的状态就一直保持不变,并且在读出时也不破坏原有数据。
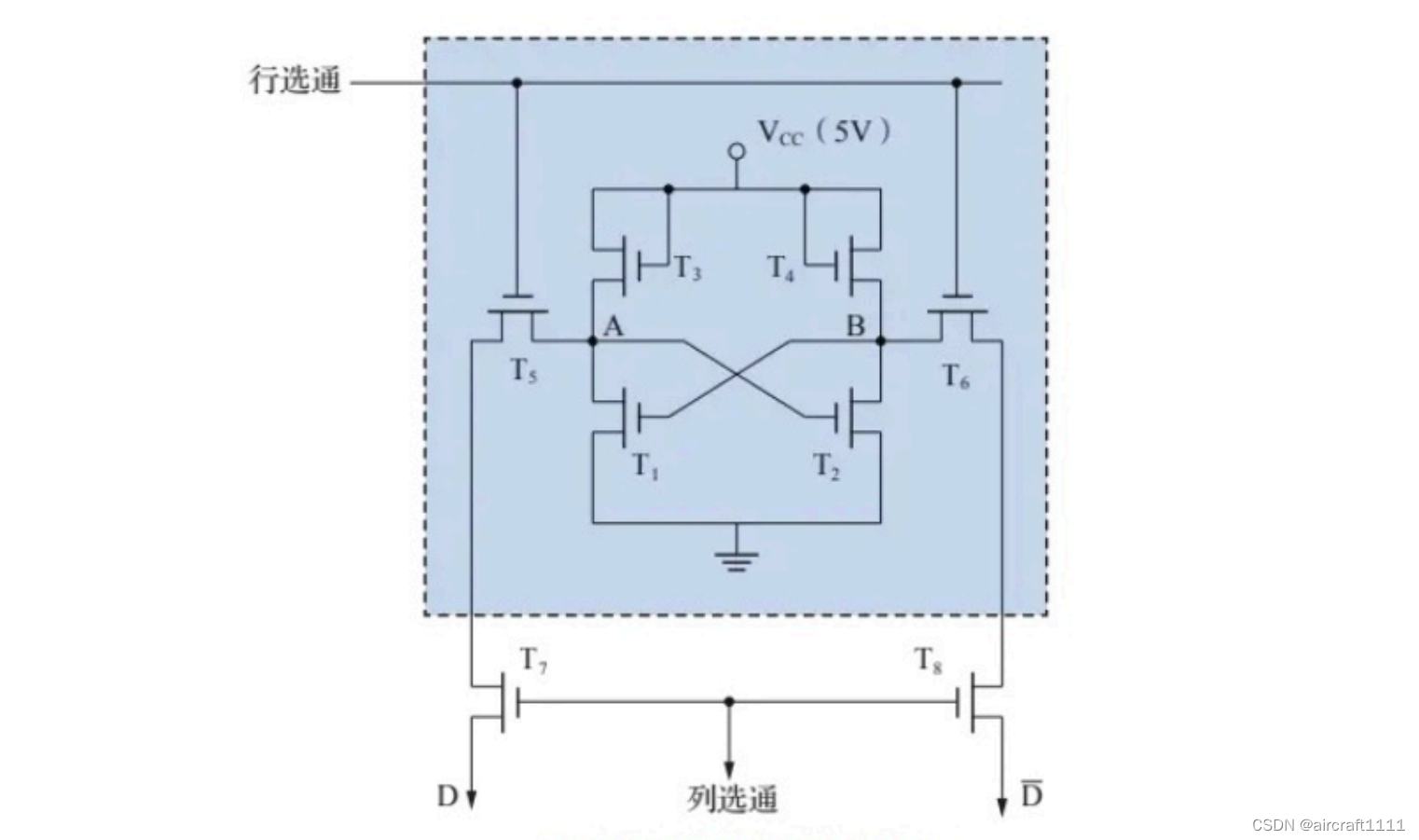
- SRAM存储单元行列扩展
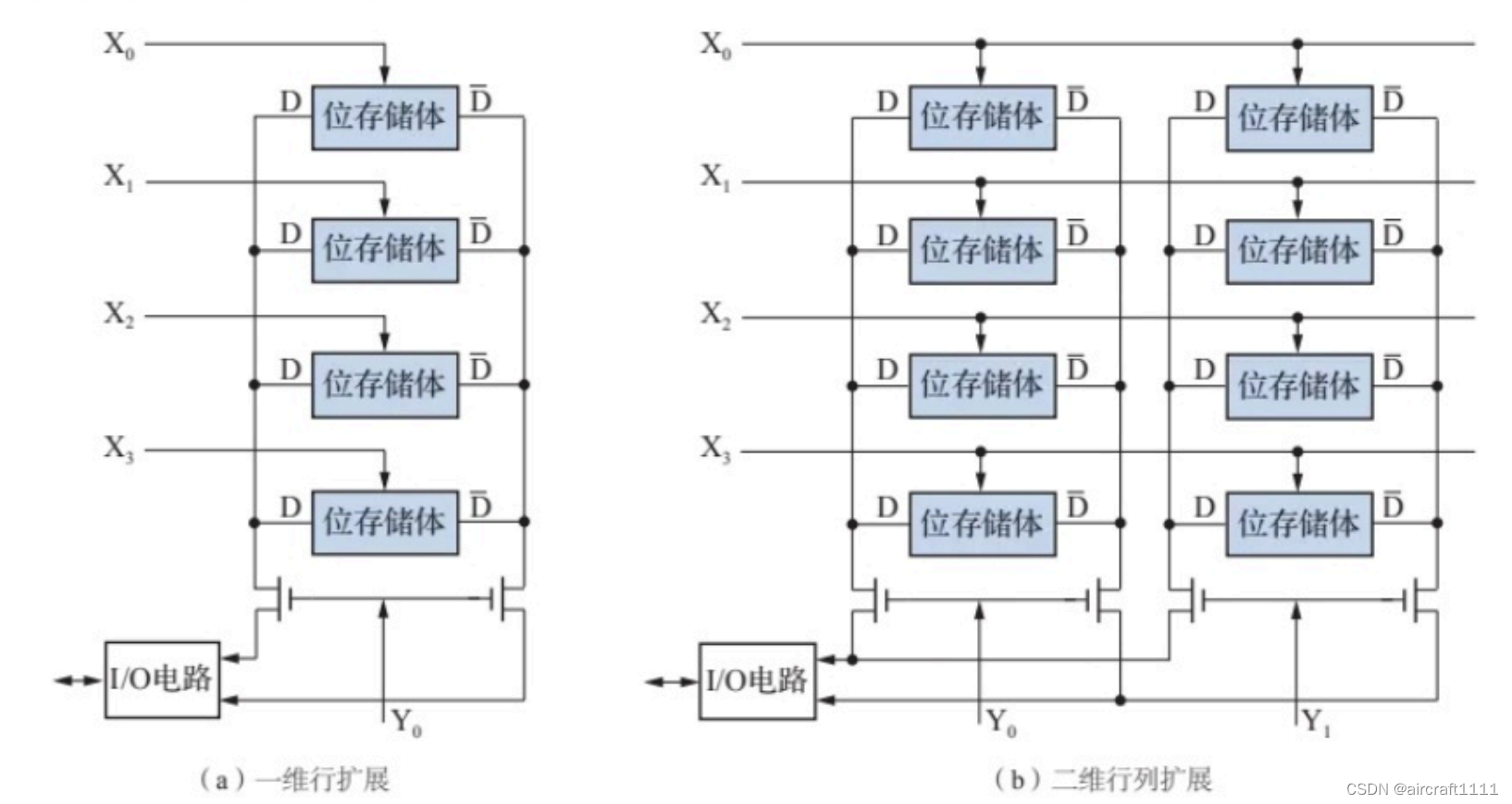
- 4096×4位的静态MOS存储器结构框图
-
地址译码器
存储器中地址译码器的作用是将地址翻译成驱动存储单元门控管的行、列选通信号,并选中相应的存储单元,这里采用的是双译码结构。
-
驱动器
每个行译码输出信号都要同时驱动这一行上所有位存储体的 T 5 、 T 6 T_5、T_6 T5、T6。两个门控管,考虑4个存储阵列并发,每一根行译码输出信号线要驱动64x2x4=512个门控管,负载较大,因此用驱动器来增强其负载能力。而每一个列译码器的输出信号要打开 T 7 、 T 8 T_7、T_8 T7、T8两个门控管,4位存储体需要驱动8个门控管,所以也需要增加Y向驱动器增强其负载能力。
-
片选信号和读写控制电路
由于一块集成芯片的容量有限,要组成一个大容量的存储器,往往需要将多块芯片连接起来使用。此时,存储器被访问时并不是所有的芯片都会同时工作,通过片选信号可以很好地解决存储芯片的选择问题。只有片选信号 C S ‾ \overline{CS} CS有效的存储芯片才能进行读或写操作。读或写操作通过CPU发出读写命令控制 W E ‾ \overline{WE} WE来实现。
- Intel 2114 结构
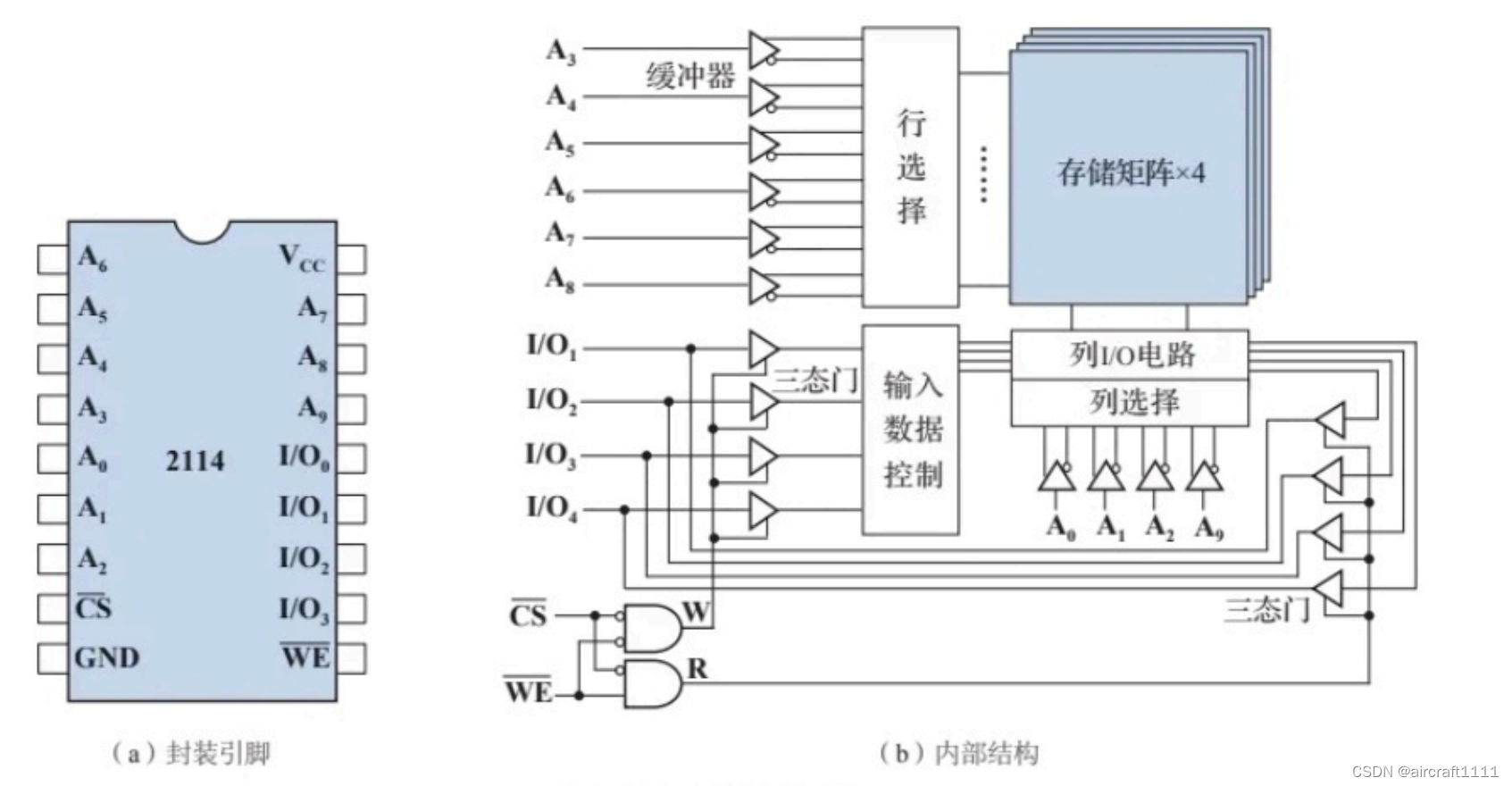
行选通后该行的所有信号可以同时传送的列I/O电路中。
I O 1 IO_1 IO1~ I O 4 IO_4 IO4,用于连接双向数据总线。这里利用三态门进行数据总线的传输方向控制。由片选信号 C S ‾ \overline{CS} CS和写使能信号 W E ‾ \overline{WE} WE控制左右两组三态门的写入或读出。写入时, C S ‾ \overline{CS} CS和 W E ‾ \overline{WE} WE均有效(低电平)W端为高电平,打开左侧的一组三态门,数据总线上的数据经输入数据控制逻辑写入存储器。读出时, W E ‾ \overline{WE} WE无效(高电平),R端为高电平,右边的一组三态门被打开,数据从存储器读出并由列 I/O电路送入数据总线。由于读和写是分时的,W和R信号互斥,因此数据总线上的数据不会出现混乱。
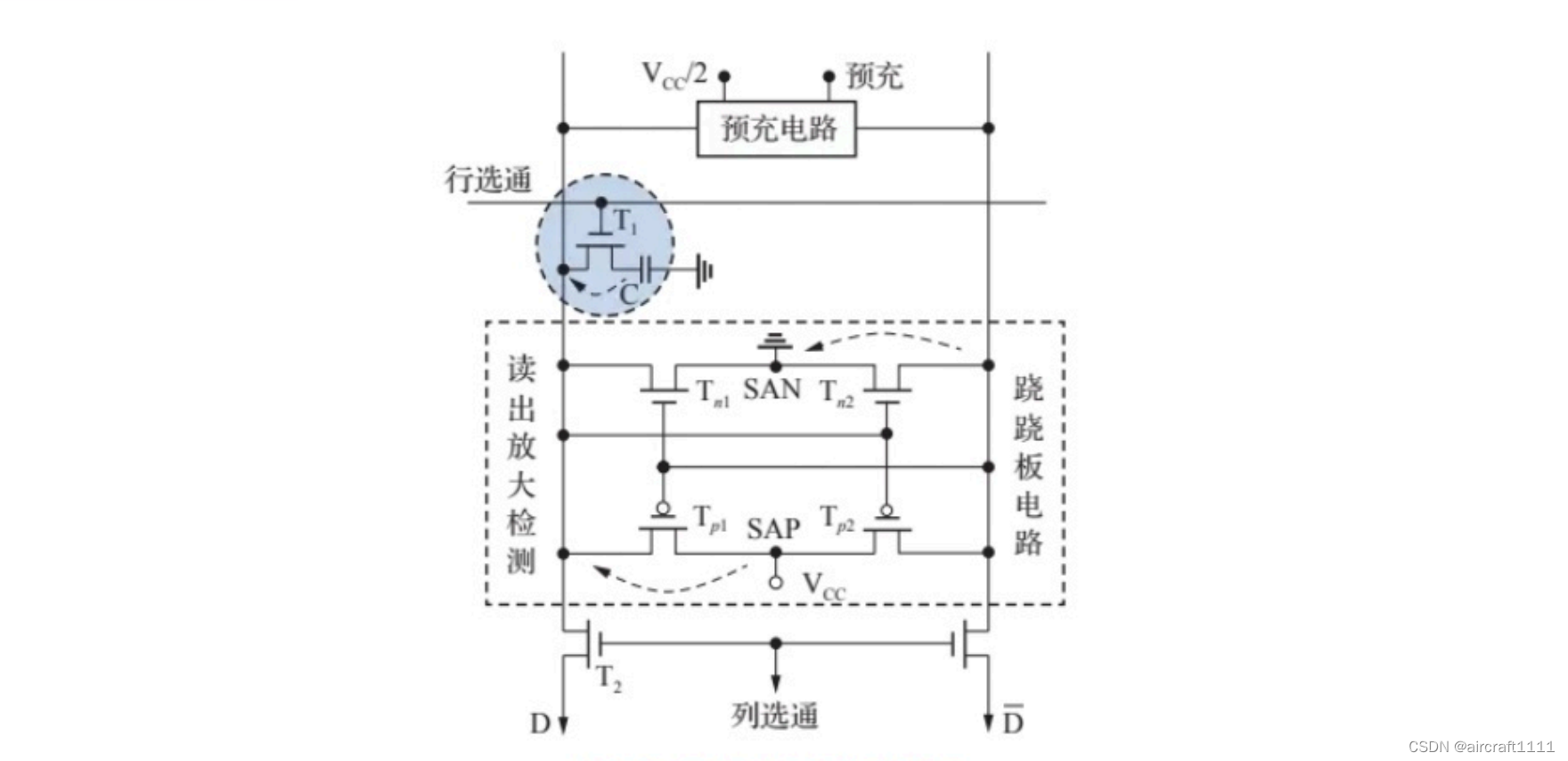
- 单管DRAM内部电路
-
预充操作
给出预充信号,由预充电路将位线 D D D和 D ‾ \overline{D} D预充到 Vcc/2的电压后撤除预充信号,此时位线上的寄生电容保持Vcc/2的电压;预充的目的是加速读取的过程,类似将跷跷板支撑到一定的高度方便跷跷板一上一下。
-
访问操作
给出行选通信号, T 1 T_1 T1管导通,存储电容和位线上的寄生电容进行电荷重分配,假设存储电容上有电荷,存储数据“1”则位线D上的电压将略大于 Vc2;反之如果存储电容上没有电荷,则位线D上的电压将略低于 Vcc/2。
-
信号检测
启动读出放大检测电路,将SAN接地,SAP电压为Vcc,由于左侧电压略高,跷跷板电路平衡被打破, T n 2 、 T p 1 T_{n2}、T_{p1} Tn2、Tp1。相对而言更容易导通,交叉连接的 MOS 管形成正反馈,电路稳定后 D D D线上的电压上为稳定的逻辑“1”高电平 Vc,而 D ‾ \overline{D} D线上则为逻辑“0”低电平。
-
数据恢复
经过信号检测阶段后,位线 D D D变成稳定的逻辑“1”高电平Vcc,该电平会给存储电容进行充电,使得存储电容的电荷恢复到之前的状态;由于同一行上所有列都可以并发进行前4步的操作,因此同一行上的所有存储单元中的数据都会被刷新一遍,读操作可以实现行刷新的功能;由于数据恢复过程的时间延迟较长,因此通常将多列的读取并发进行以提高读性能,也就是按行进行批量读取。
-
数据输出
给出列选通信号,位线 D D D和 D ‾ \overline{D} D上的数据就可以输出到外部;由此可知 DRAM 的行选通和列选通信号并不是同时给出的,因此DRAM 存储器通常将行、列地址复用,以减少地址引脚数目;完成数据的读操作后,撤除行选通信号,关闭读出放大检测电路。
- 动态MOS存储器芯片2116的逻辑符号及内部结构
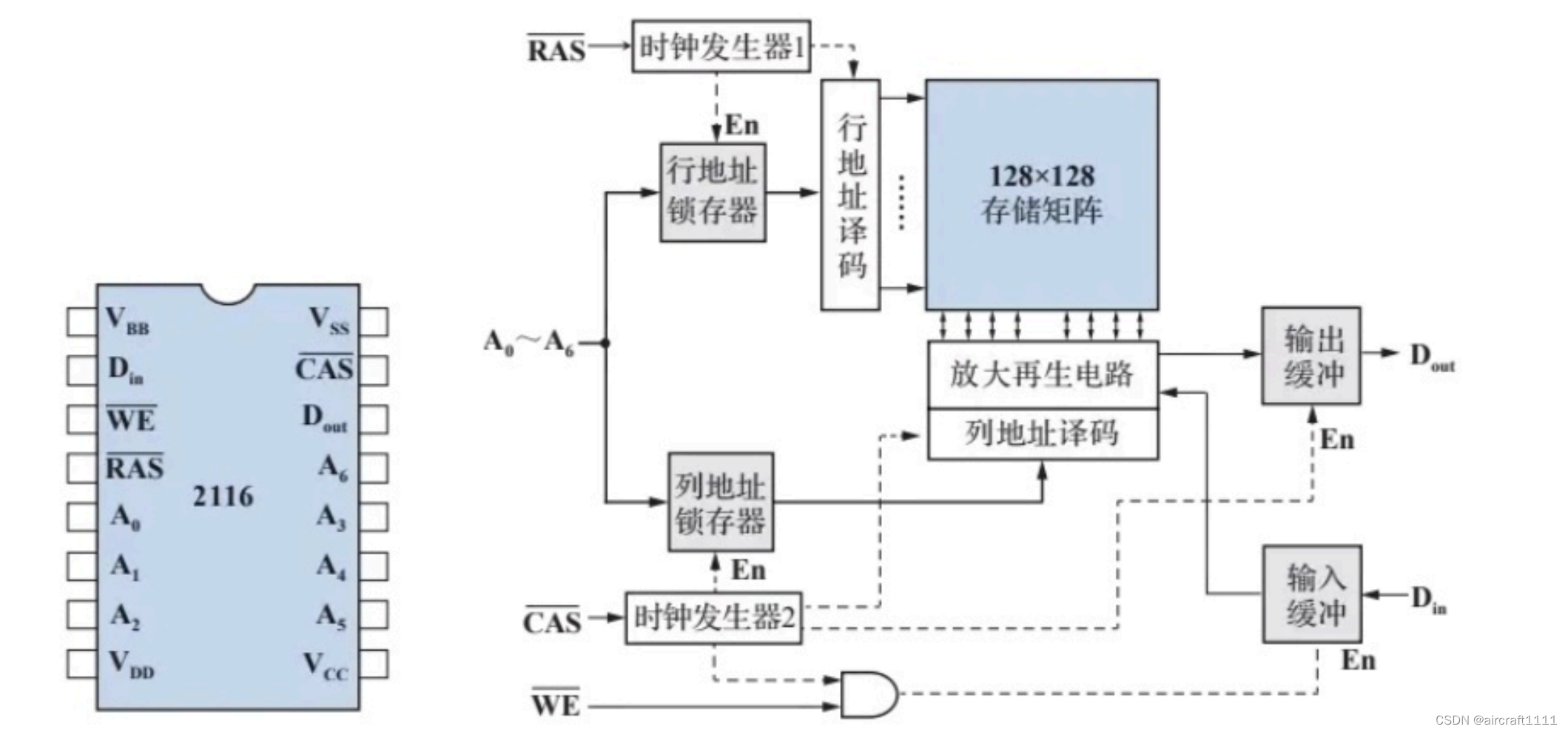
2116表示16Kx1位存储芯片,其采用地址复用技术,分别由行地址选通信号
R
A
S
‾
\overline{RAS}
RAS和列地址选通信号
C
A
S
‾
\overline{CAS}
CAS先后将7位地址
A
0
A_0
A0~
A
6
A_6
A6分别锁存到行地址锁存器与列地址锁存器中。存储矩阵为128x128结构;7条行地址线也可作为刷新地址,刷新时用于地址计数,逐行刷新。
行、列地址译码后均产生128条选择线。选中某行时,该行的128个存储元都被选通到放大再生电路中,在那里每个存储单元会进行预充、访问、检测、恢复的过程。而列译码器中只选通 128个放大器中的一个,将读出的信息送入输出缓冲器中。
从前面的分析可看出,DRAM的结构大体与SRAM 存储芯片相似,二者的不同点如下
- 地址线一般采用复用技术,即CPU分时传送行、列地址,并分别由行选通信号 R A S ‾ \overline{RAS} RAS和列选通信号 C A S ‾ \overline{CAS} CAS选通。
- DRAM无片选信号,通常可由 R A S ‾ \overline{RAS} RAS和 C A S ‾ \overline{CAS} CAS选通信号代替)
- 数据输入( D I N D_{IN} DIN)和数据输出( D o u t D_{out} Dout)分开且可锁存。
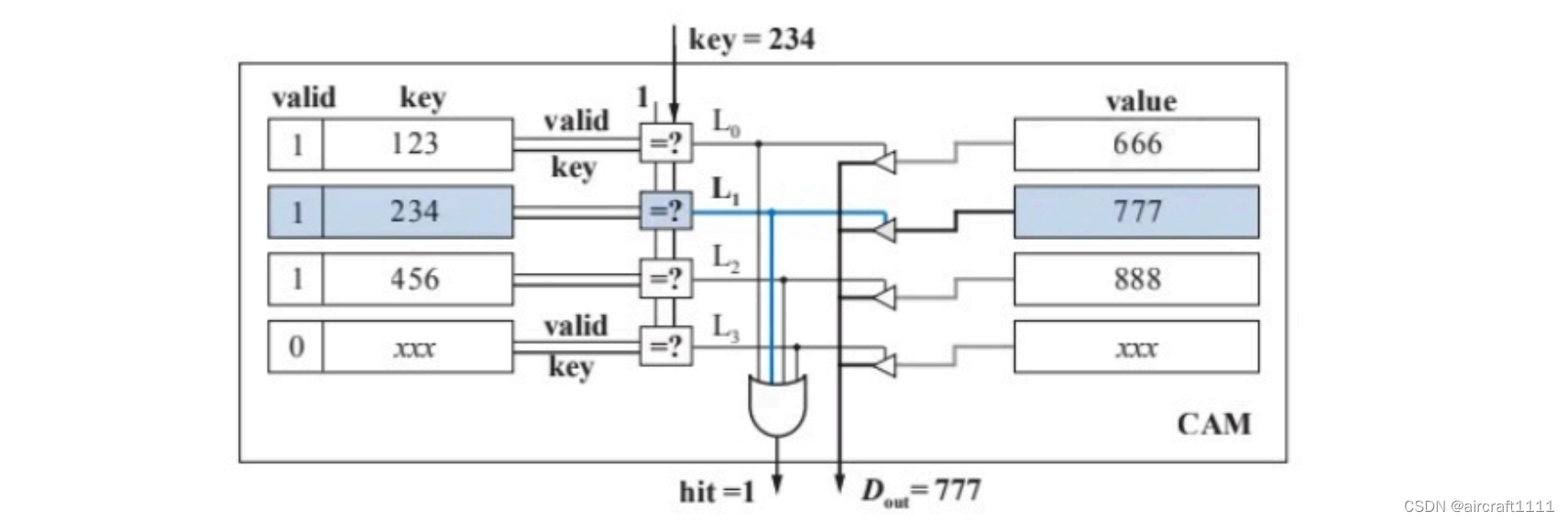
- CAM基本原理
- 全相联映射的硬件逻辑实现框图
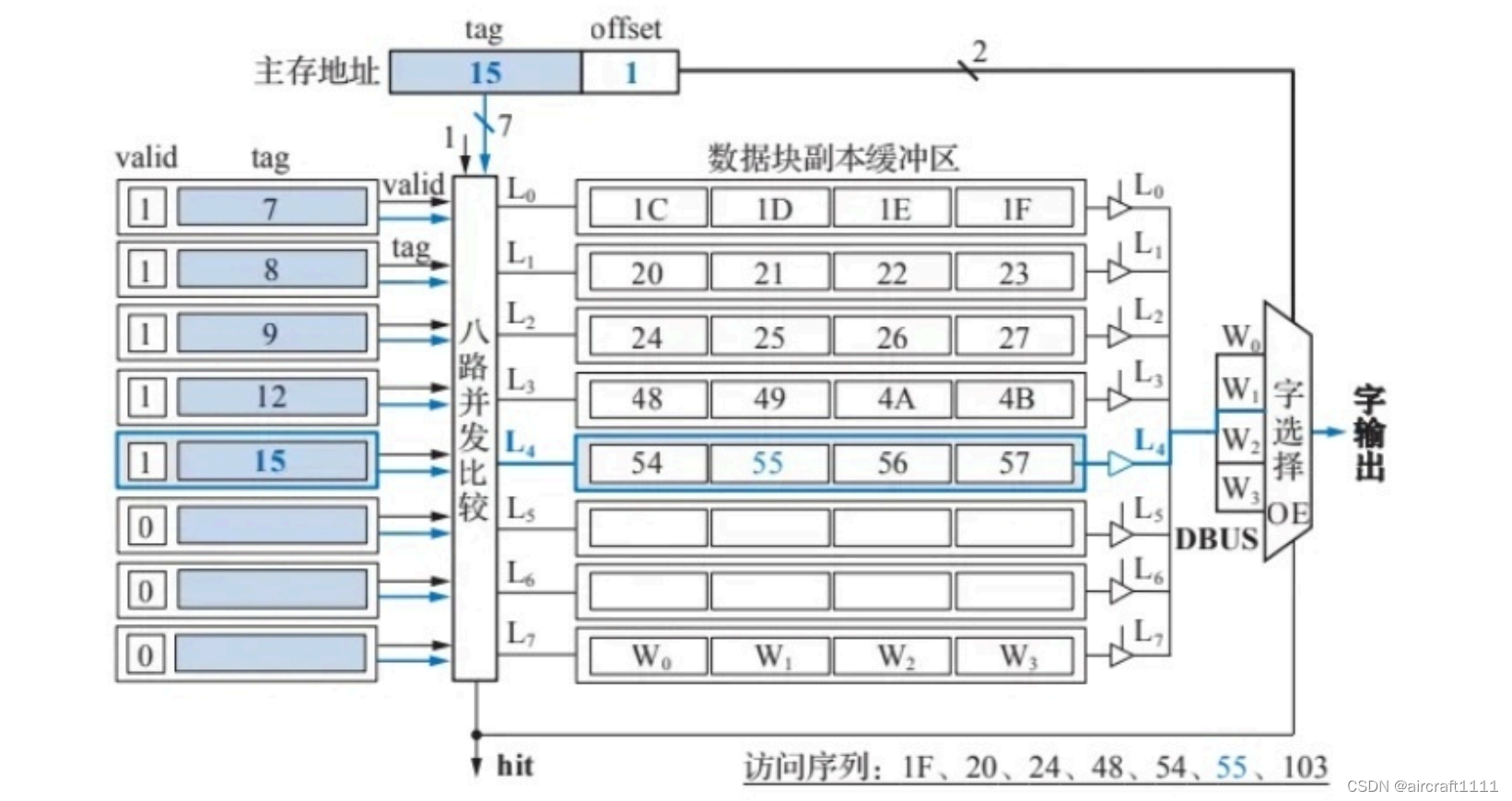
- 直接相联映射的硬件逻辑实现框图
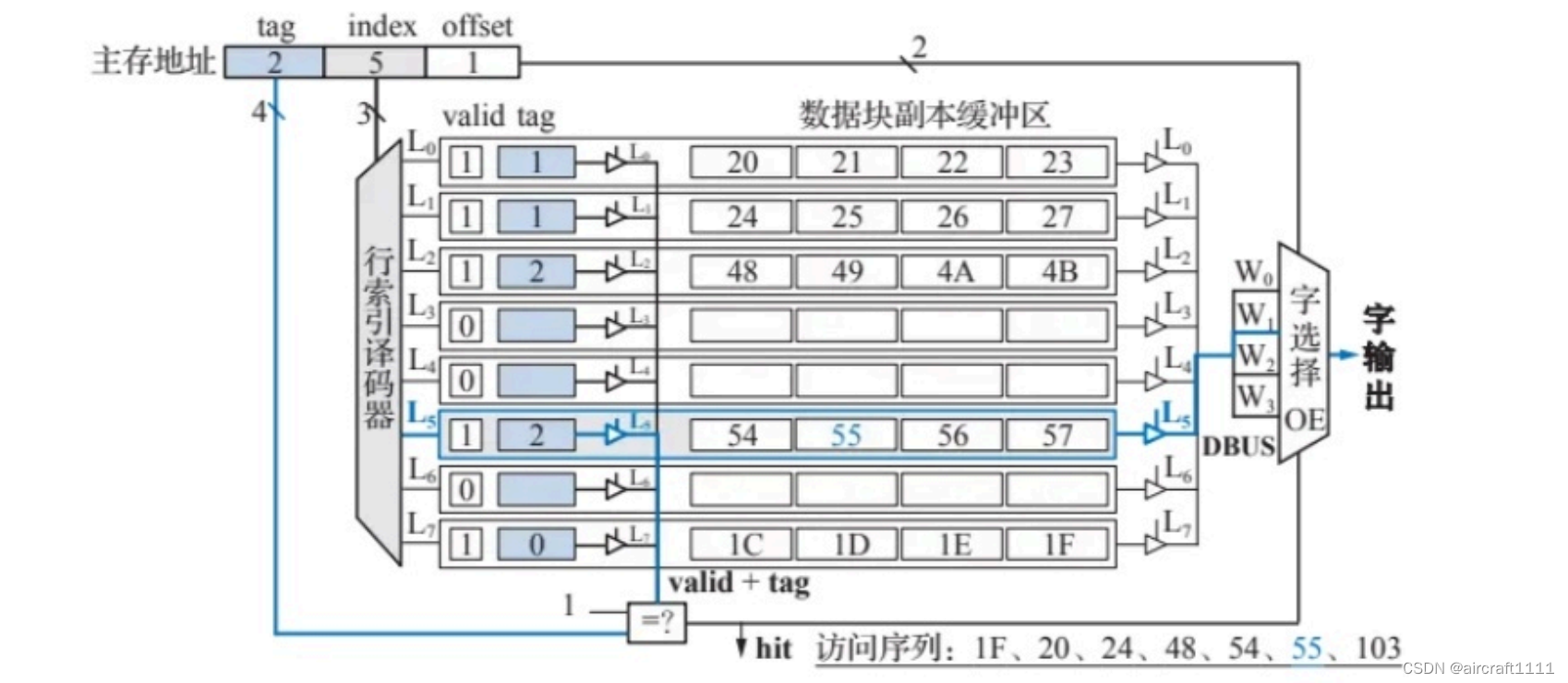
- 组相连映射的硬件逻辑实现框图
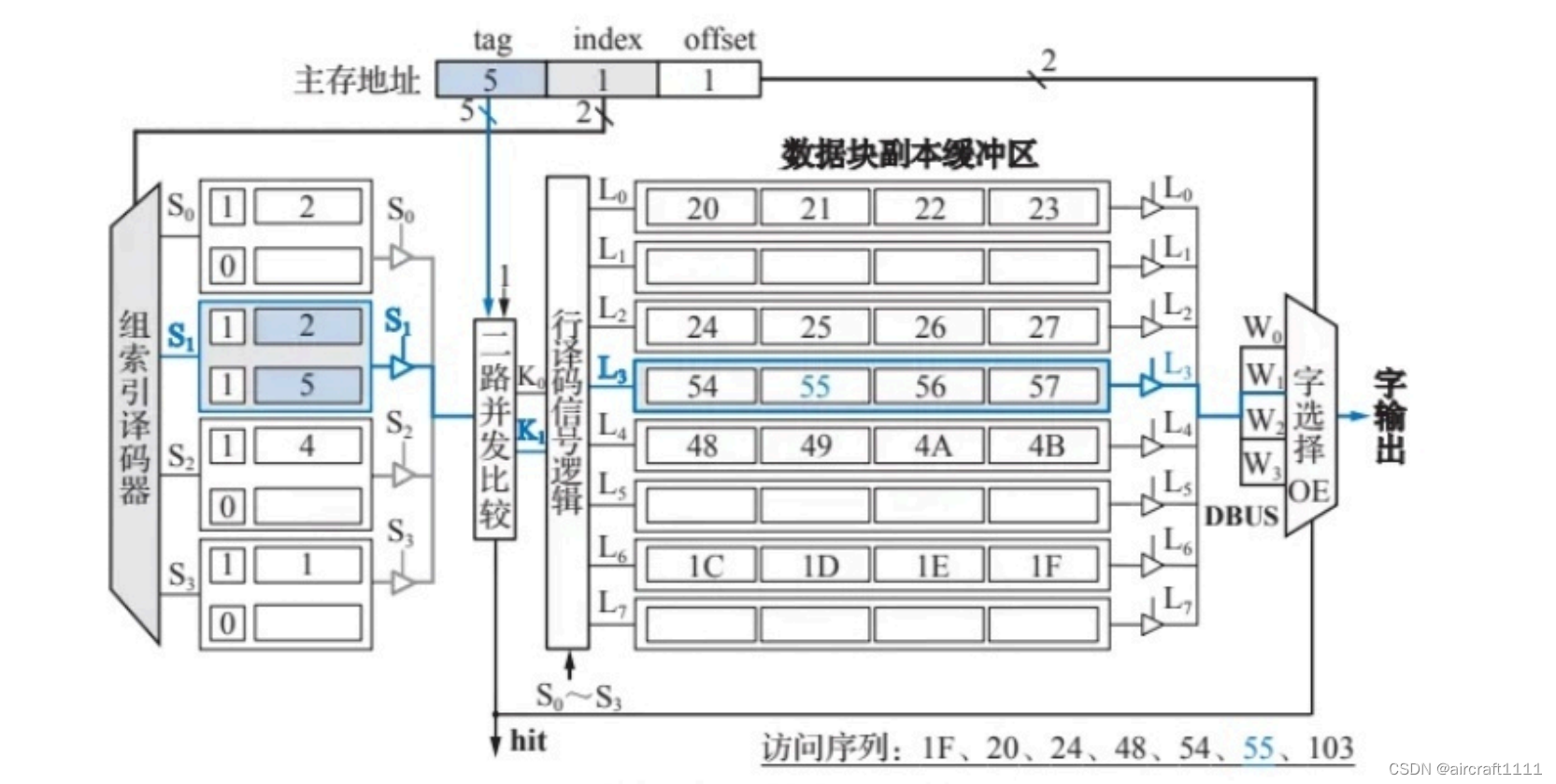
- 基于TLB的虚拟地址到物理地址的转换
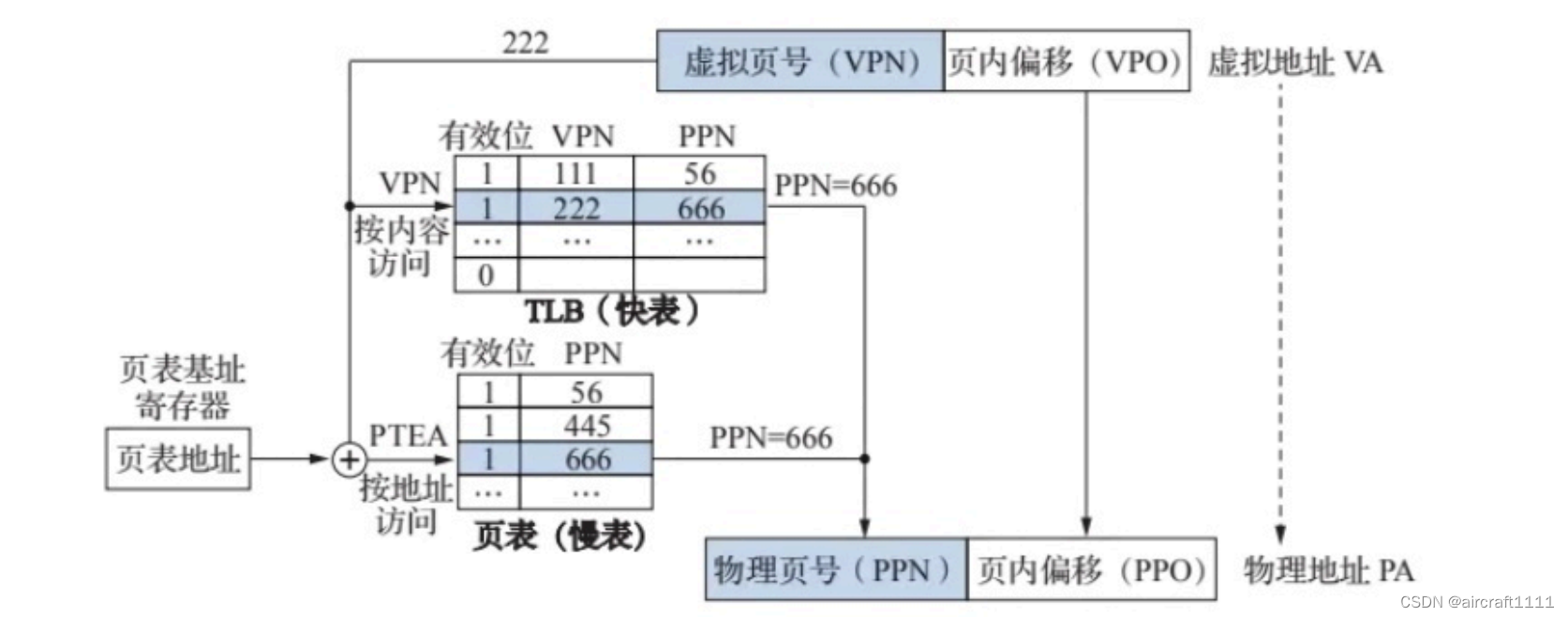
- CPU基本组成
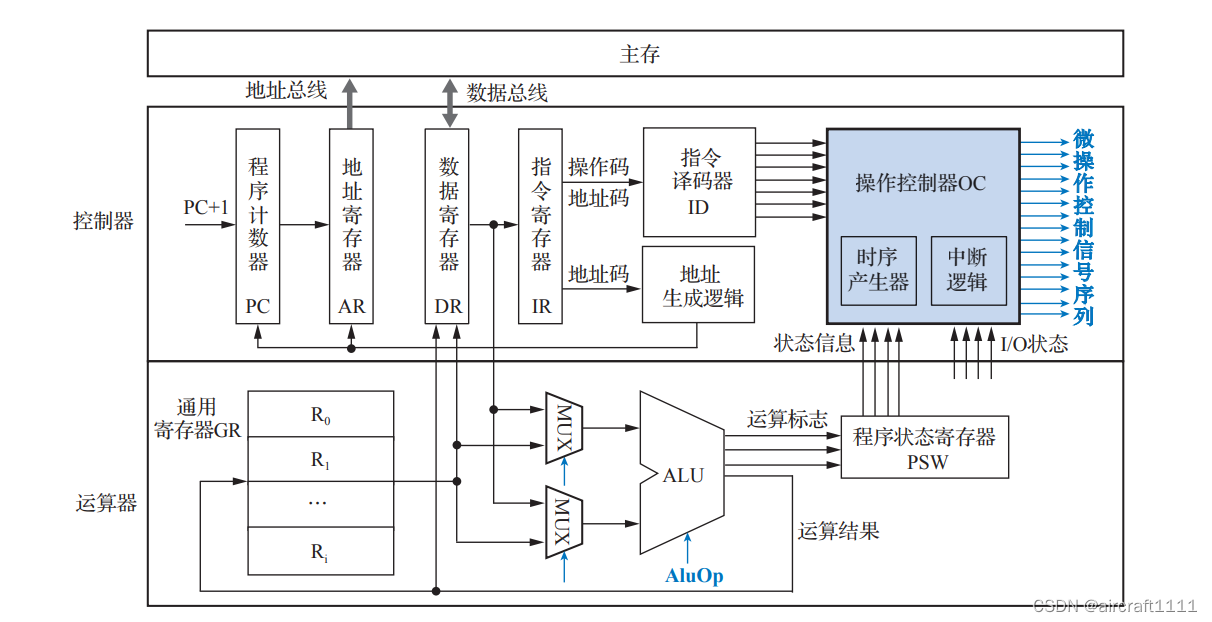
CPU 执行指令的过程就是 CPU 控制信息流的过程,操作控制器是控制的决策机构,其产生的微操作控制信号序列就是控制流。信息流的控制就是将操作控制器生成的微操作控制信号序 列送到各功能部件的控制门、多路选择器、触发器或锁存器处,依时间先后顺序打开或关闭某 些特定的门电路,使数据信息按完成指令功能需要经过的路径——数据通路从一个功能部件传 送到另一个功能部件,实现对数据加工处理的控制。
- 数据通路与时钟周期
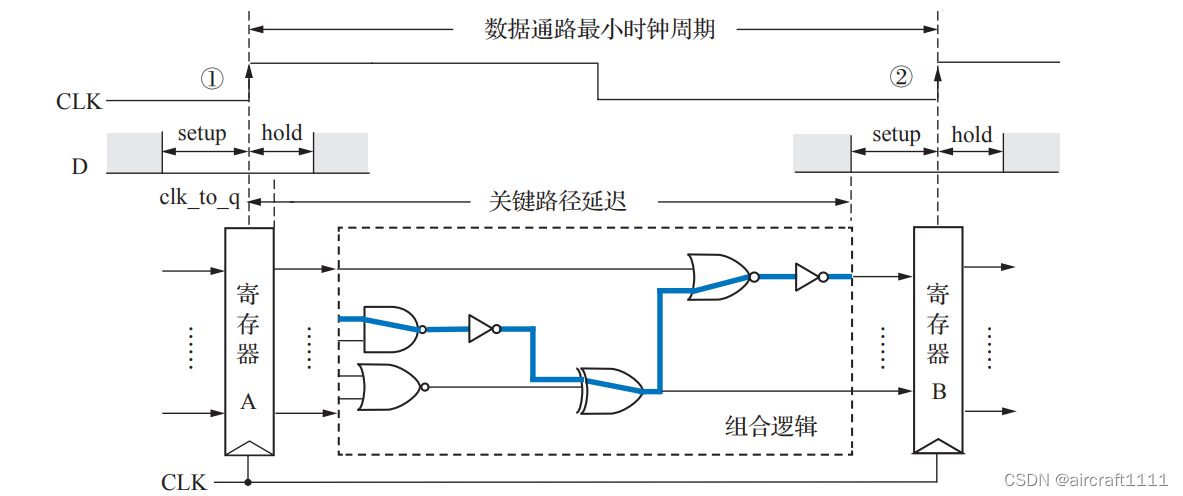
数据处理单元由组合逻辑电路构成,其输出只与当前的输入有关,负责对数据进行加工处理,如 ALU、符号扩展单元、译码器等。状态存储单元(状态单元)是指带有存储功能的单元,如存储器和寄存器。状态单元一般包含输入端、写使能控制端、时钟输入端和输出端。数据只有在写使能信号有效且时钟脉冲到来时才能写入状态单元(边沿触发),如果每个时钟脉冲都写入数据,则不需要设置写使能控制端。
CPU 的主要功能是执行指令,控制数据信息的流动,实现数据的存储、处理和传输。而这 些都依赖于数据通路的建立,通用数据通路模型可以利用一个数据处理单元连接两个状态单元 的方式构成
假设状态单元 1 和状态单元 2 分别对应寄存器 A 和 B,各自的写使能信号一直有效,由于时钟上跳沿时两寄存器会同时锁存新值,从时钟上跳沿时刻到寄存器 A 输出稳定的时间称为寄存器延迟 T c l k _ t o _ q T_{clk\_to\_q} Tclk_to_q,数据处理单元对寄存器 A 的输出数据进行处理加工时有一个关键路径延迟 T m a x T_{max} Tmax(所有输出信号稳定的延迟)。根据寄存器的时序特性,寄存器 B 要将寄存器 A 经过组合逻 辑传递过来的数据正确锁存,在下一个时钟上跳沿到来之前,还需要让输入数据保持一段稳定 时间 T s e t u p T_{setup} Tsetup(寄存器建立时间),另外时钟上跳沿到来之后输入数据还需要一段稳定时间 Thold(寄 存器保持时间)
- 单总线结构的计算机框图
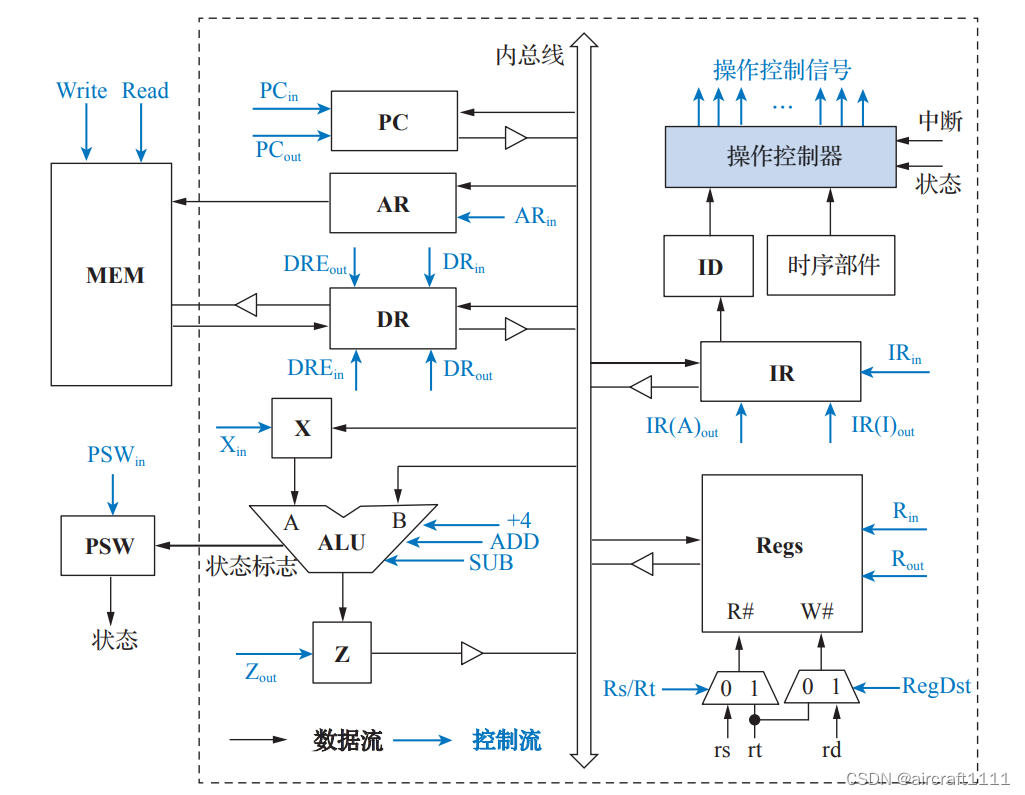
对单总线结构而言,总线 上可以有多个模块同时接收数据,但某一时刻只能有一个模块向总线发送数据,否则会出现数据 冲突。因此,连接到总线上的部件都需要进行输出控制,以防止总线上出现数据冲突。
- 单周期MIPS处理器的数据通路高层视图
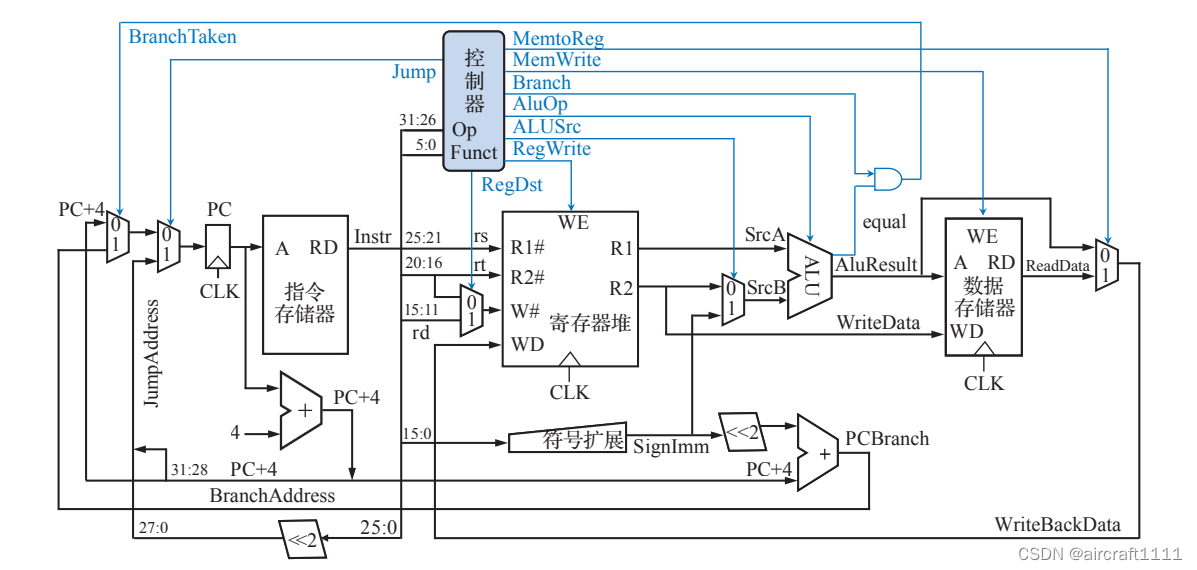
最为典型的专用数据通路结构就是单周期 MIPS 处理器,单周期 MIPS 处理器是指所有指令在一个时钟周期内完成的 MIPS 处理器尽管不同指令的执行时间可能不同,但基于木桶原理,单周期处理器的时钟周期取决于执行速度最慢的指令。由于只能在一个时钟周期内完成指令的取出和执行操作, 指令执行过程中数据通路的任何资源都不能被重复使用,都应该是专用的数据通路,需要被多次使用的资源(如加法器)都需要设置多个;取指令和取操作数操作都需要访问存储器,因此将指令和数据分别存放在指令存储器和 数据存储器中,以避免资源冲突。这是设计单周期处理器中的数据通路时必须考虑的重要环节。
- 多周期MIPS处理器的数据通路高层视图
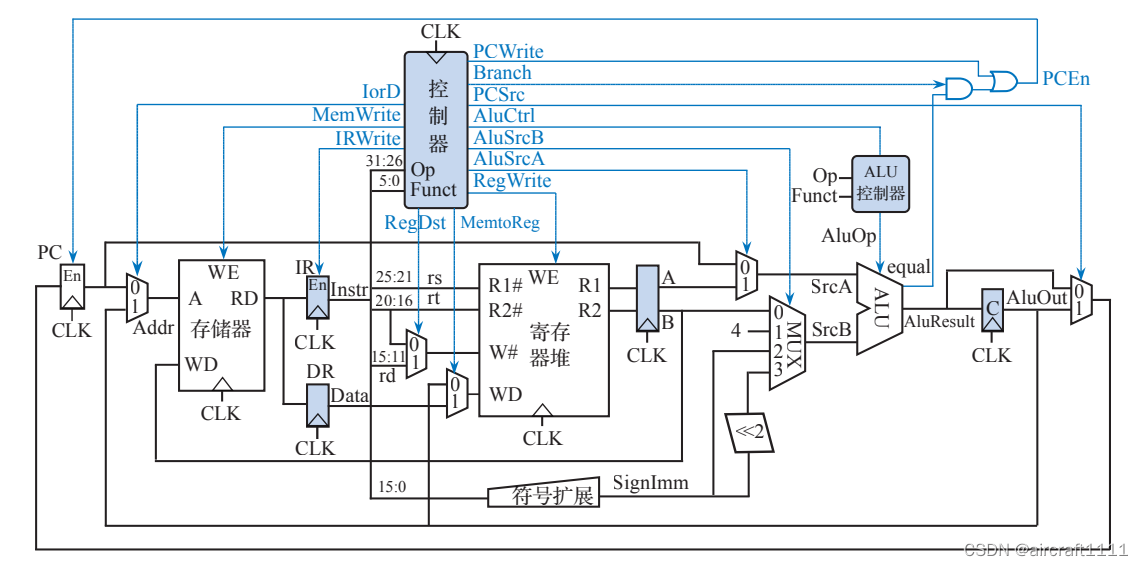
所谓多周期方式是指根据指令执行所需要的功能操作,将一条指令的执行过程细分为若干 个更小的步骤,每个时钟周期执行其中一部分操作,并将操作结果暂存在相关寄存器中,供下 一个时钟周期进行处理,直至指令执行完毕。与单周期数据通路不同的是,多周期数据通路中 的功能部件单元可在一条指令执行过程的不同时钟周期中被多次使用。这种共享复用方式一方 面能提高硬件实现效率,另一方面也对处理器结构提出了与单周期不同的需求。
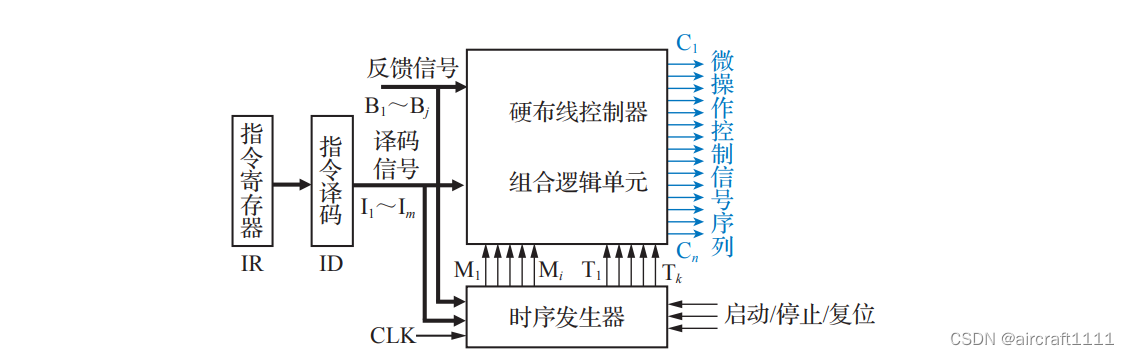
- 传统三级时序逻辑硬布线模型
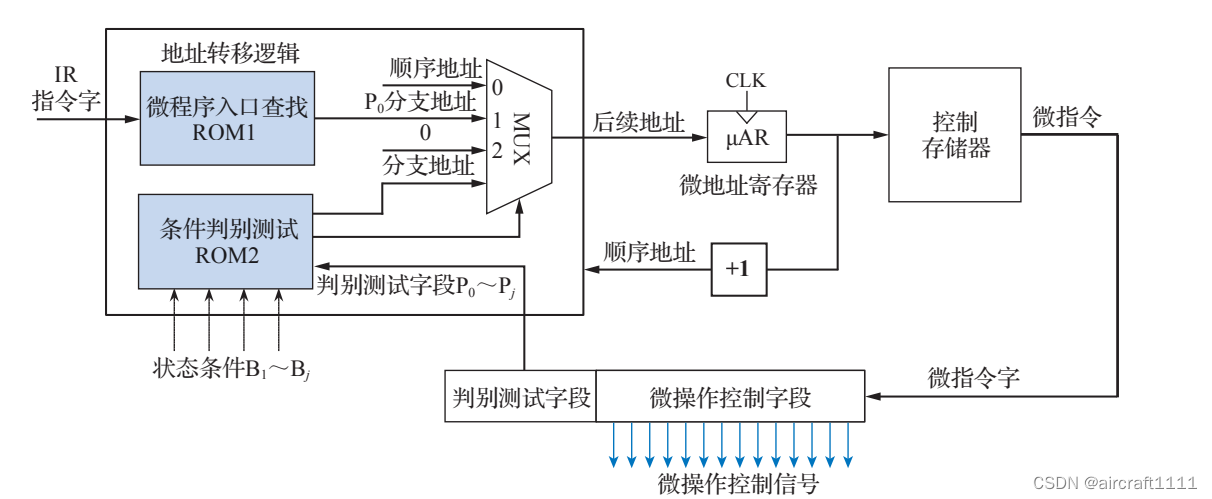
- 采用ROM实现的地址转移逻辑
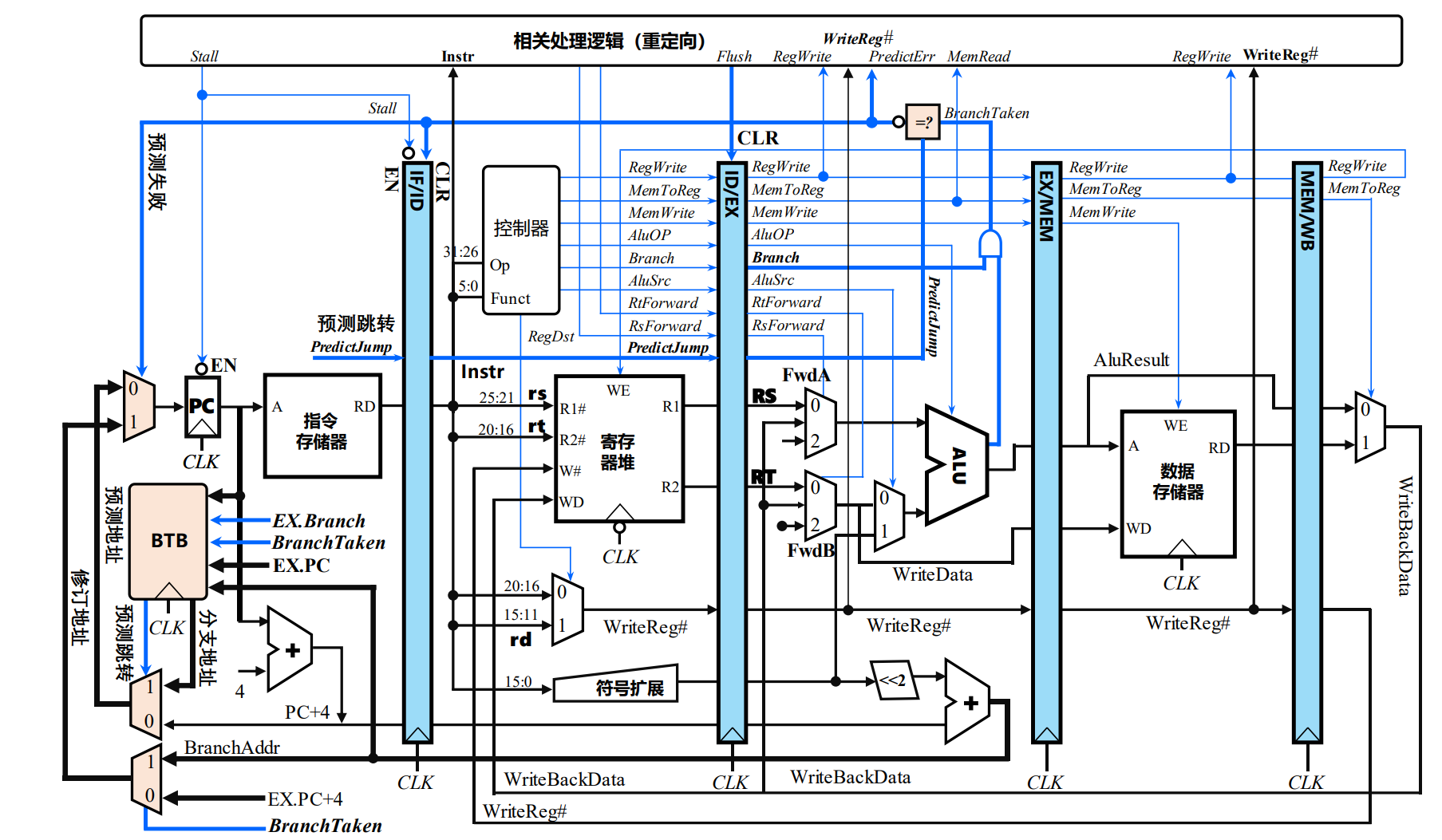
- 支持动态分支预测的MIPS五段流水
- I/O接口通用结构
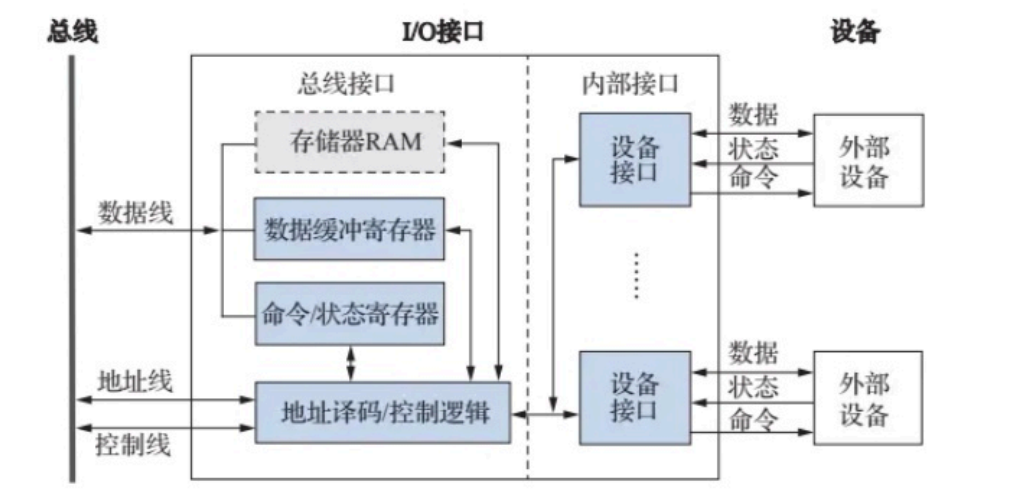
- 数据缓冲寄存器(DBR):用于缓冲数据,以匹配 CPU与外部设备之间的速度差异。CPU 执行输入操作时,DBR 存放从IO设备读取的数据,该数据将被CPU通过总线读取并送入CPU寄存器中;执行输出操作时 DBR暂存CPU送来的数据,该数据最终会被输出至具体外部设备。
- 设备状态寄存器(DSR):用于反馈设备状态,常见的状态信息如设备忙、设备就绪设备错误等。在程序查询方式中,CPU通过读取状态寄存器来判断设备的状态,以确定程序下一步操作。
- 设备命令寄存器(DCR):用于接收CPU发送的设备控制命令,如设备复位、设备识别读写控制等,不同设备所能支持的命令不同,简单设备甚至没有命令寄存器,如简单的键盘输入和字符终端输出设备。有时状态和命令寄存器是合二为一的。
- 设备存储器:这部分并不是必需的,常用于设备自身的运算和处理,如显卡中的显存。
- 地址译码器:用于识别地址总线上的地址是否是当前IO接口连接的外部设备。
- 数据格式转换逻辑:进行串并或并串传送的转换。
- 中断查询方式的I/O接口
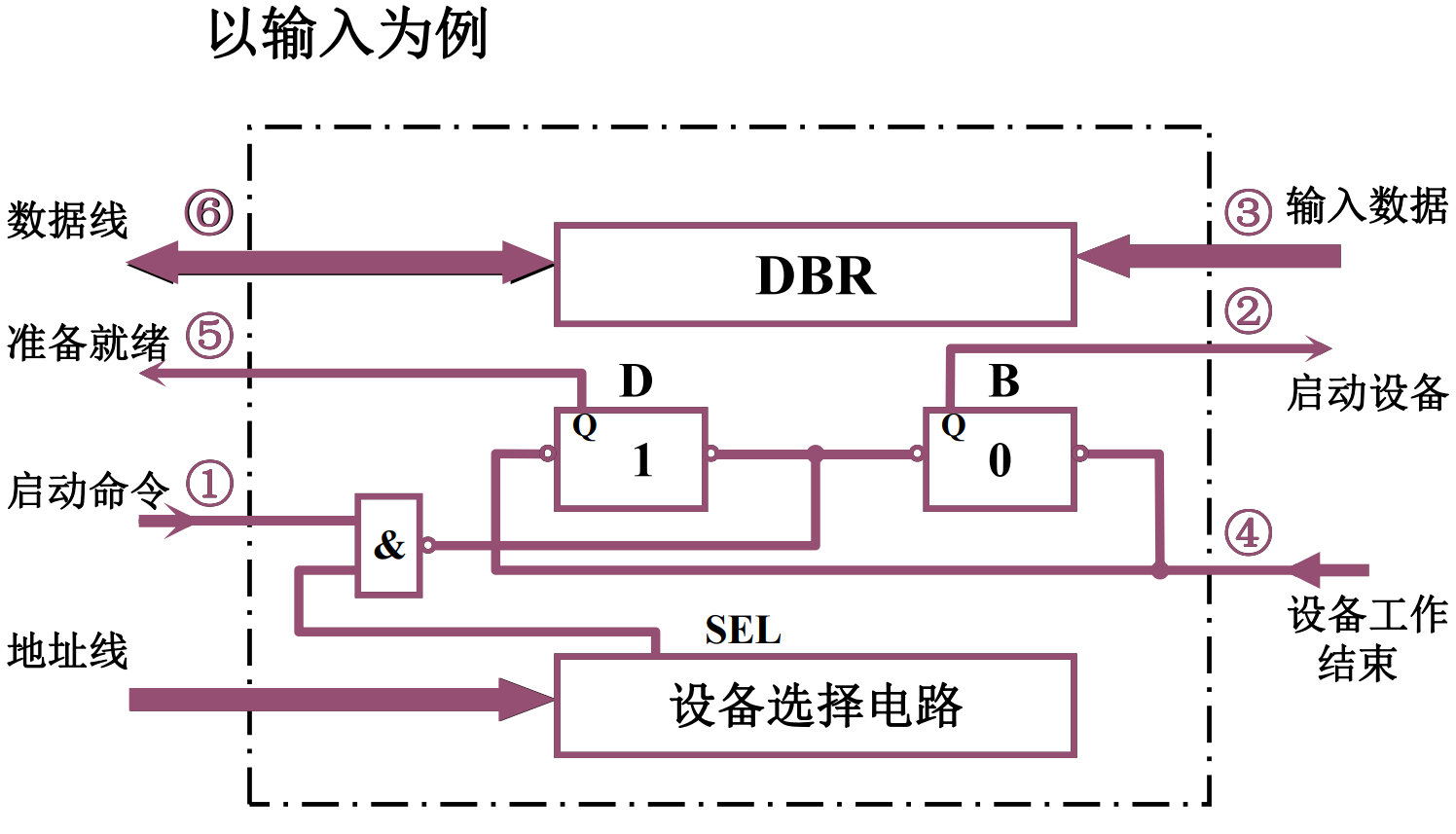
- 当CPU通过I/O指令启动输入设备时,指令的设备码字段通过地址线送至设备选择电路。
- 若该接口的设备码与地址线上的代码吻合,其输出SEL有效。
- I/O指令的启动命令经过“与非”门将工作触发器B置“1”,将完成触发器D置“0”。
- 由B触发器启动设备工作。
- 输入设备将数据送至数据缓冲寄存器。
- 由设备发设备工作结束信号,将D置“1”,B 置“0”,表示外设准备就绪。
- D触发器以“准备就绪”状态通知 CPU,表示“数据缓冲满”。
- CPU执行输入指令,将数据缓冲寄存器中的数据送至CPU的通用寄存器,再存入主存相关单元。
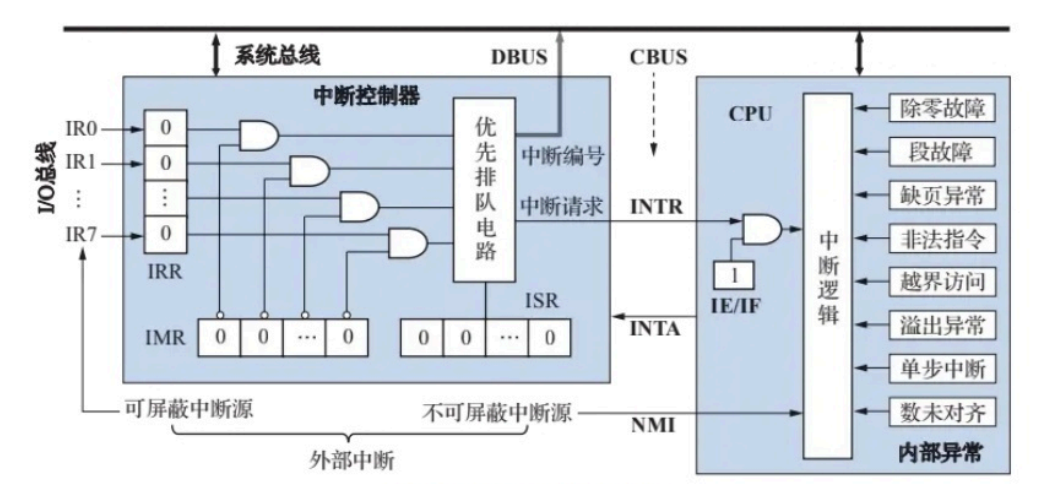
- 中断请求的硬件支持
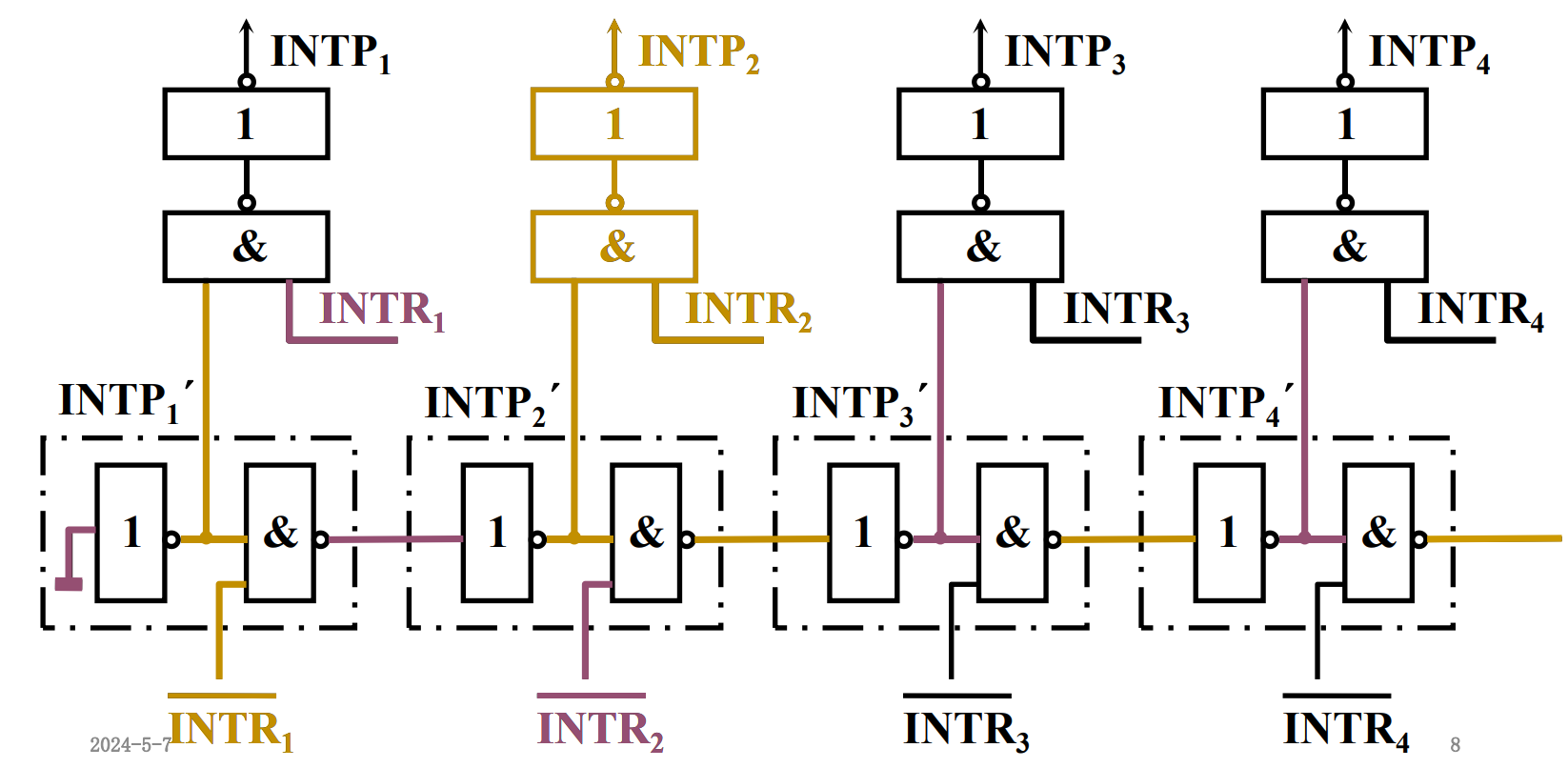
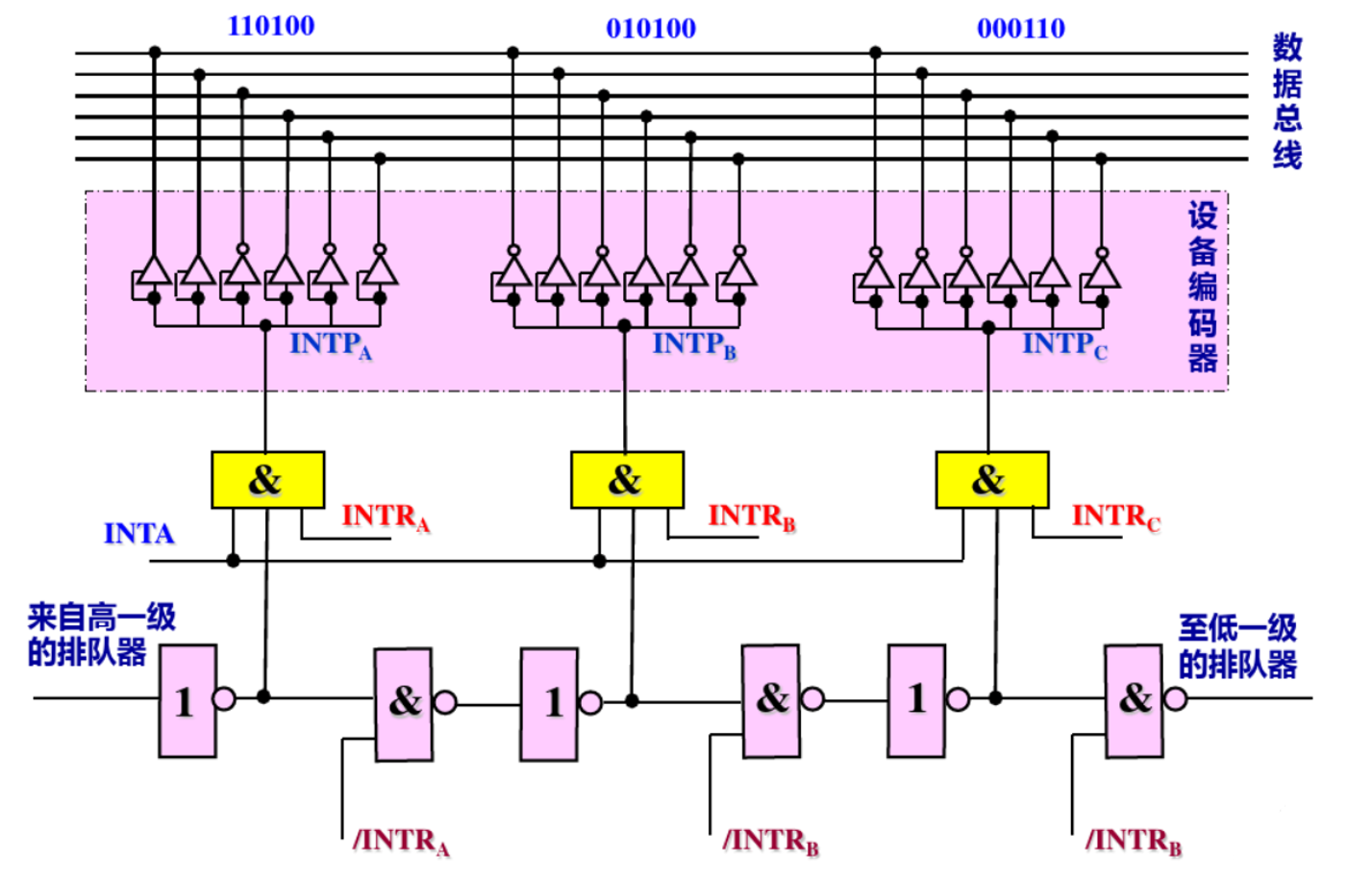
- 中断排队器
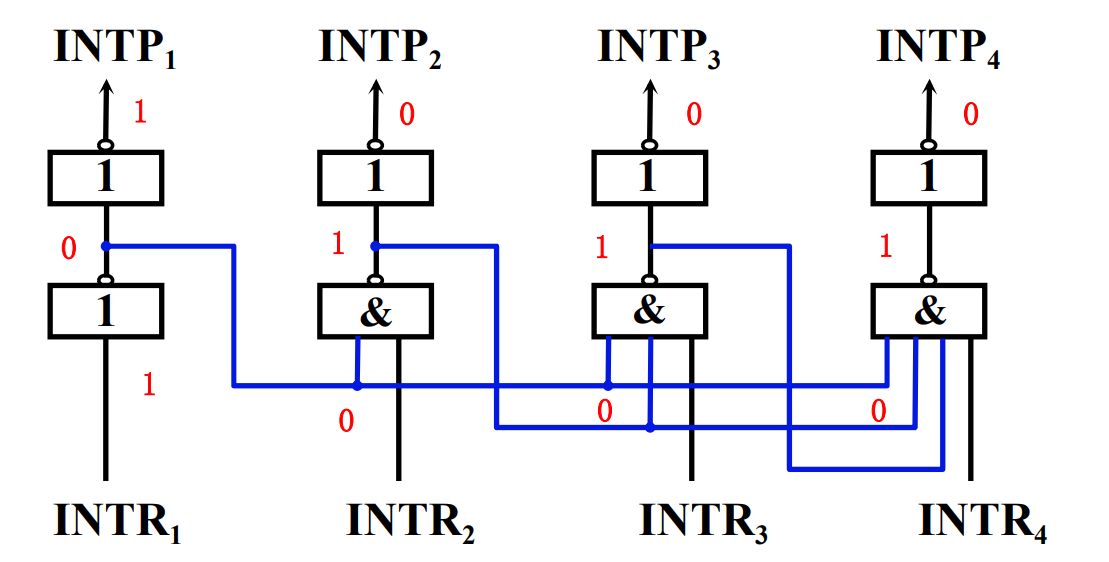
链式排队器
- 硬件关中断
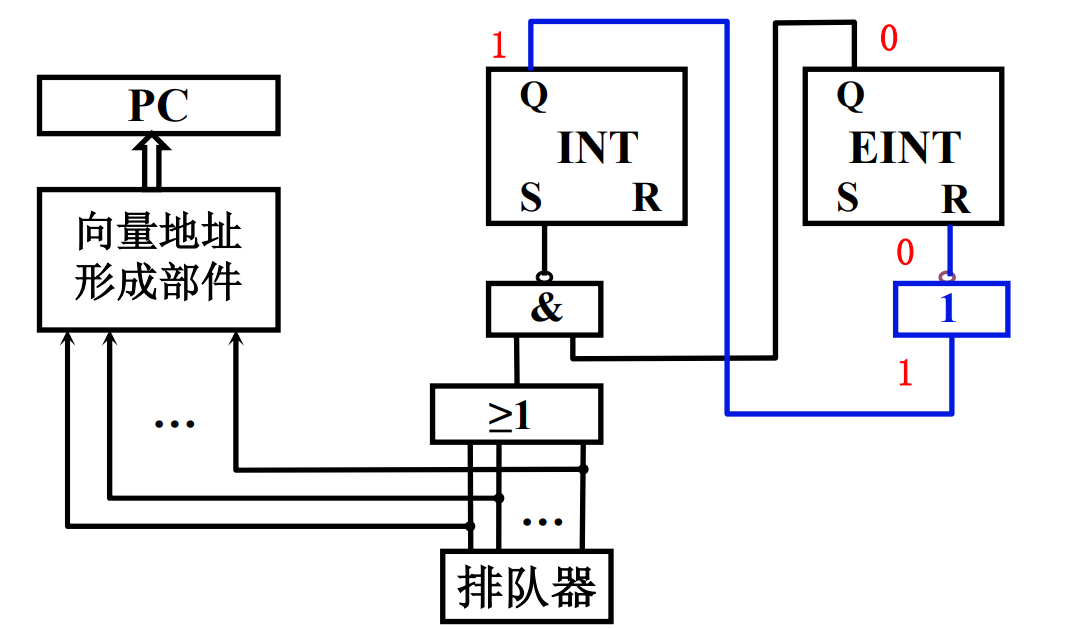
一条指令执行周期结束后,CPU发出中断查询信号,此时EINT为1表示允许中断,各中断源经过IMP(中断屏蔽)送至排队器,排队器选择响应优先级最高的信号输出到向量地址形成部件。同时进行一步硬件关中断的操作,EINT的RS触发器Q端1和排队器传递来的有中断请求1传到INT为RS触发器S端置Q为1(INT的R端应该为始终为1)代表进入中断周期,INT的Q端传到EINT的R端至EINT的Q为0。
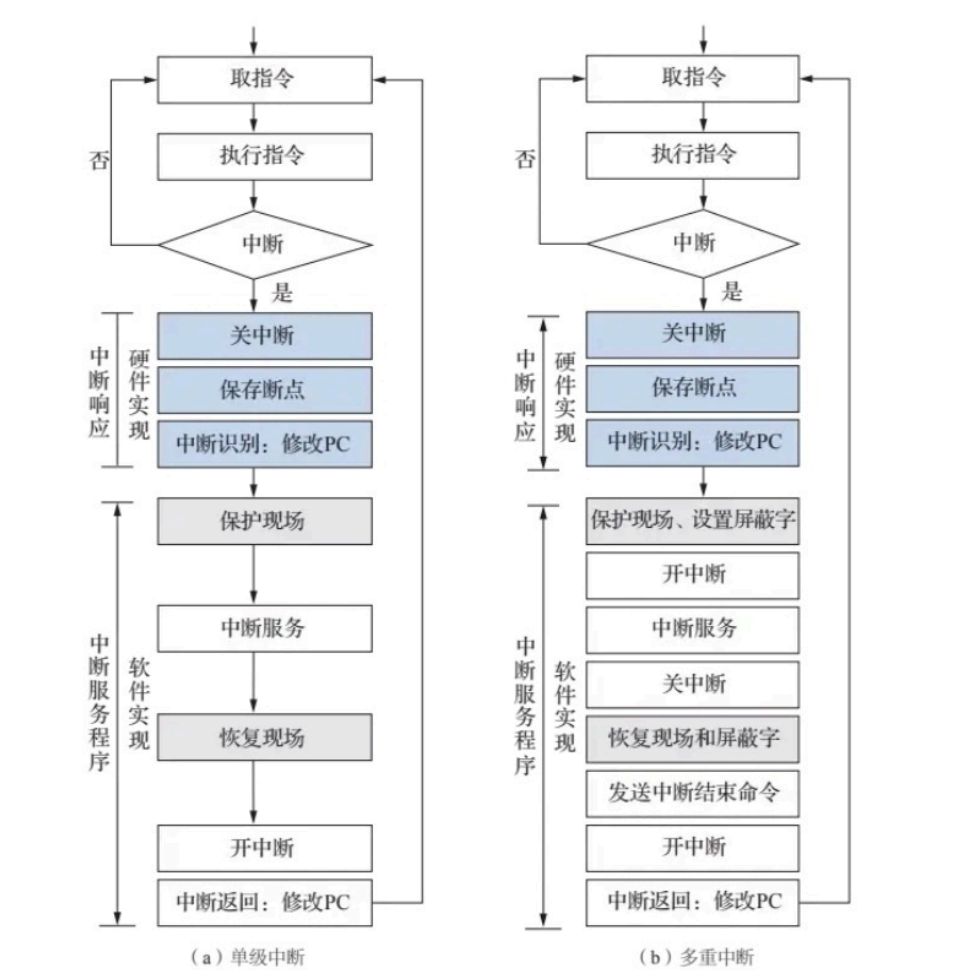
- 程序中断方式的接口
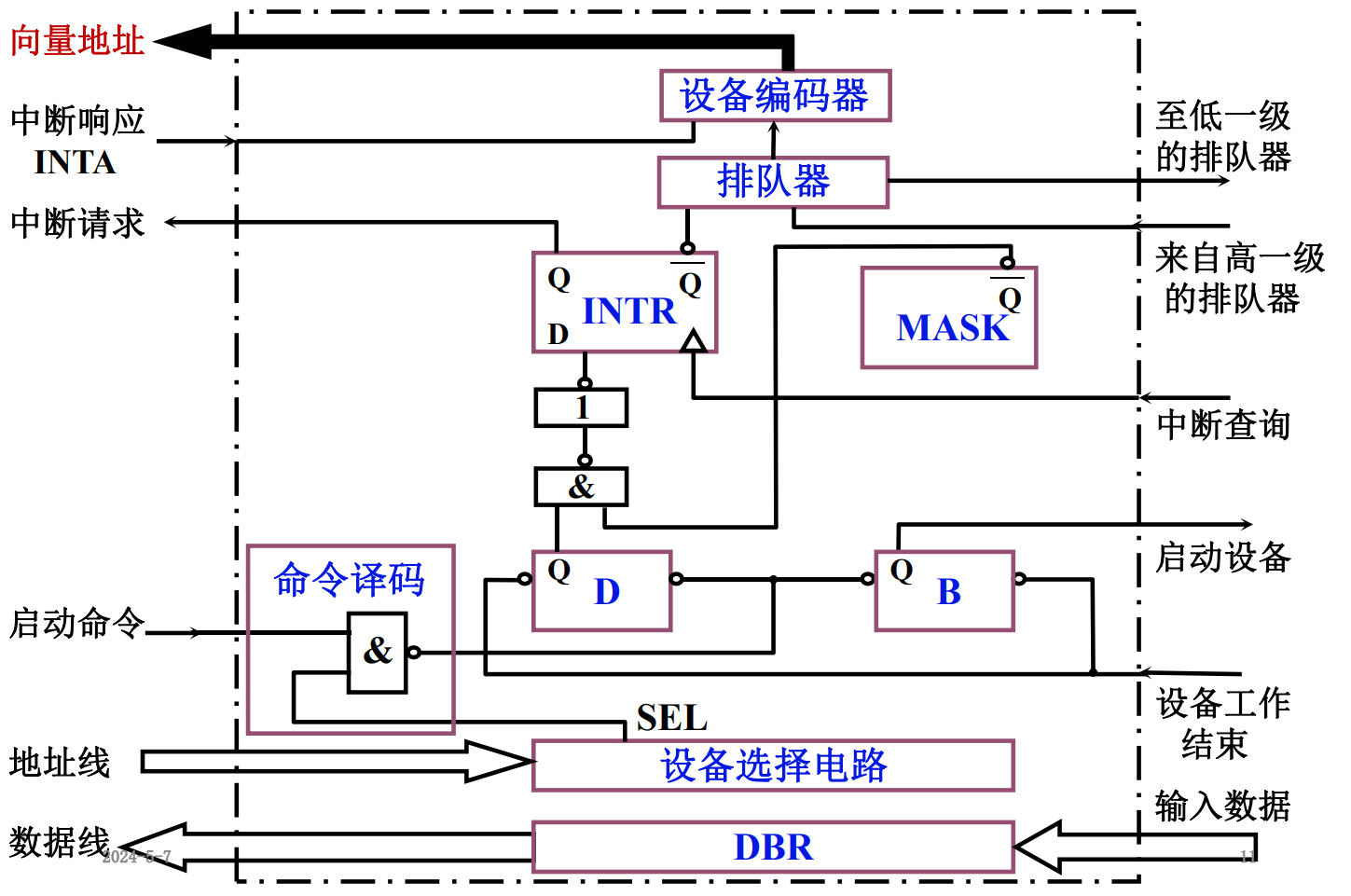
输入为例:启动命令→启动设备→输入数据→设备结束→中断查询→中断请求→中断响应→中断地址。
- 由CPU发启动I/O设备命令,将接口中的B置“1”,D置“0”;
- 接口启动输入设备开始工作;
- 输入设备将数据送入数据缓冲寄存器;
- 输入设备向接口发出“设备工作结束”信号,将D置“1”,B置“0”,标志设备准备就绪;
- 当设备准备就绪(D=1)。且本设备未被屏蔽(MASK=0)时,在指令执行阶段的结束时刻,由CPU发出中断查询信号;
- 设备中断请求触发器INTR 被置“1”,标志设备向CPU提出中断请求。与此同时,INTR送至排队器,进行中断判优;
- 若CPU允许中(EINT=1),设备又被排队选中,即进入中断响应阶段,由中断响应信号INTA 将队器输出送至编码器形成向量地址;
- 向量地址送至PC,作为下一条指令的地址;
- 由于向量地址中存放的是一条无条件转移指令,故这条指令执行结束后,即无条件转至该设备的服务程序入口地址,开始执行中断服务程序,进入中断服务阶段,通过输入指令将数据缓冲寄存器的输入数据送至 CPU的通用寄存器,再存入主存相关单元;
- 中断服务程序的最后一条指令是中断返回指令,当其执行结束时,即中断返回至原程序的断点处。至此,一个完整的程序中断处理过程即告结束。
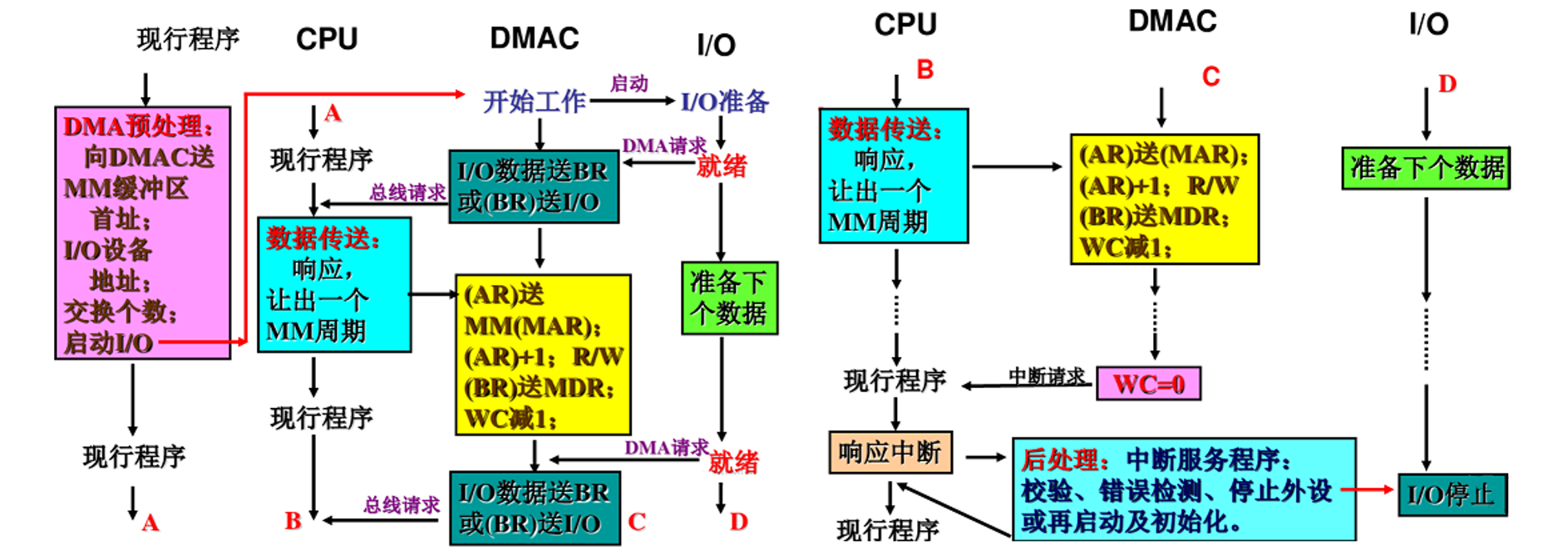
- DMA基本结构
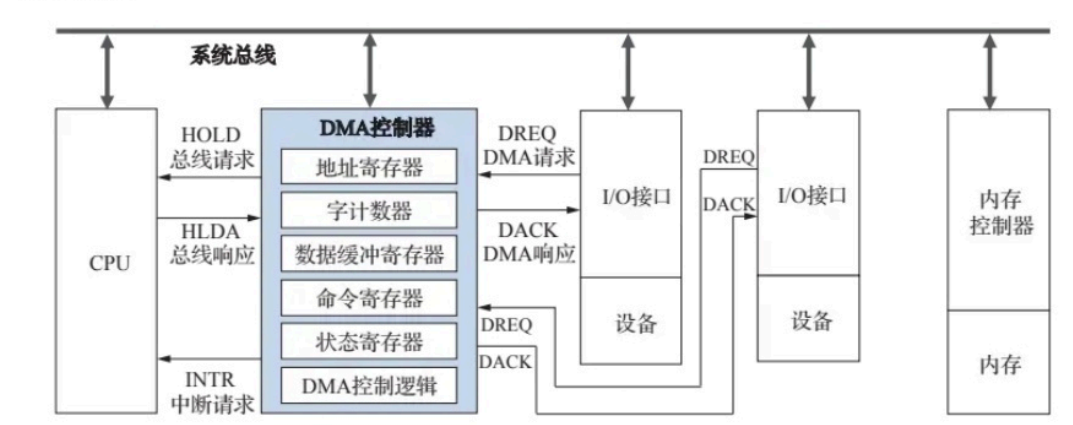
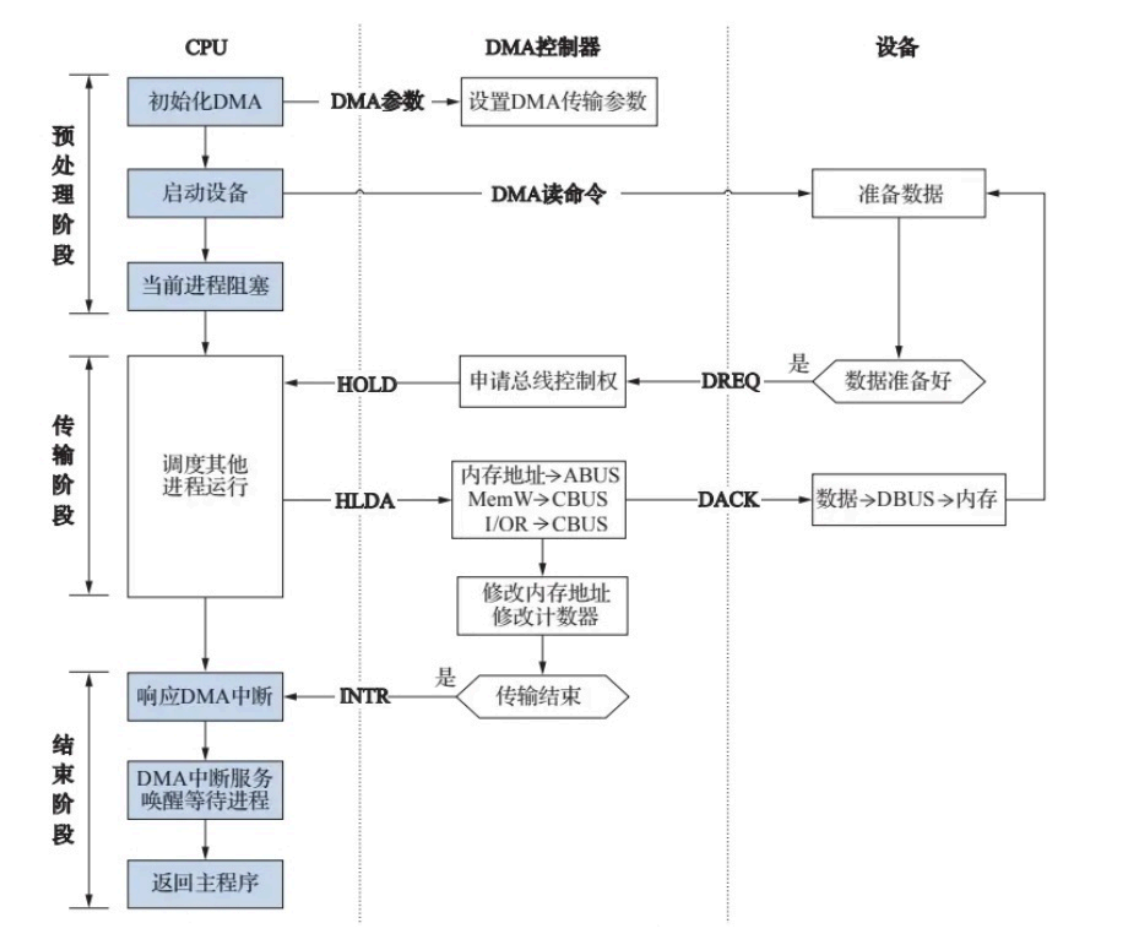
CPU暂停方式输送数据
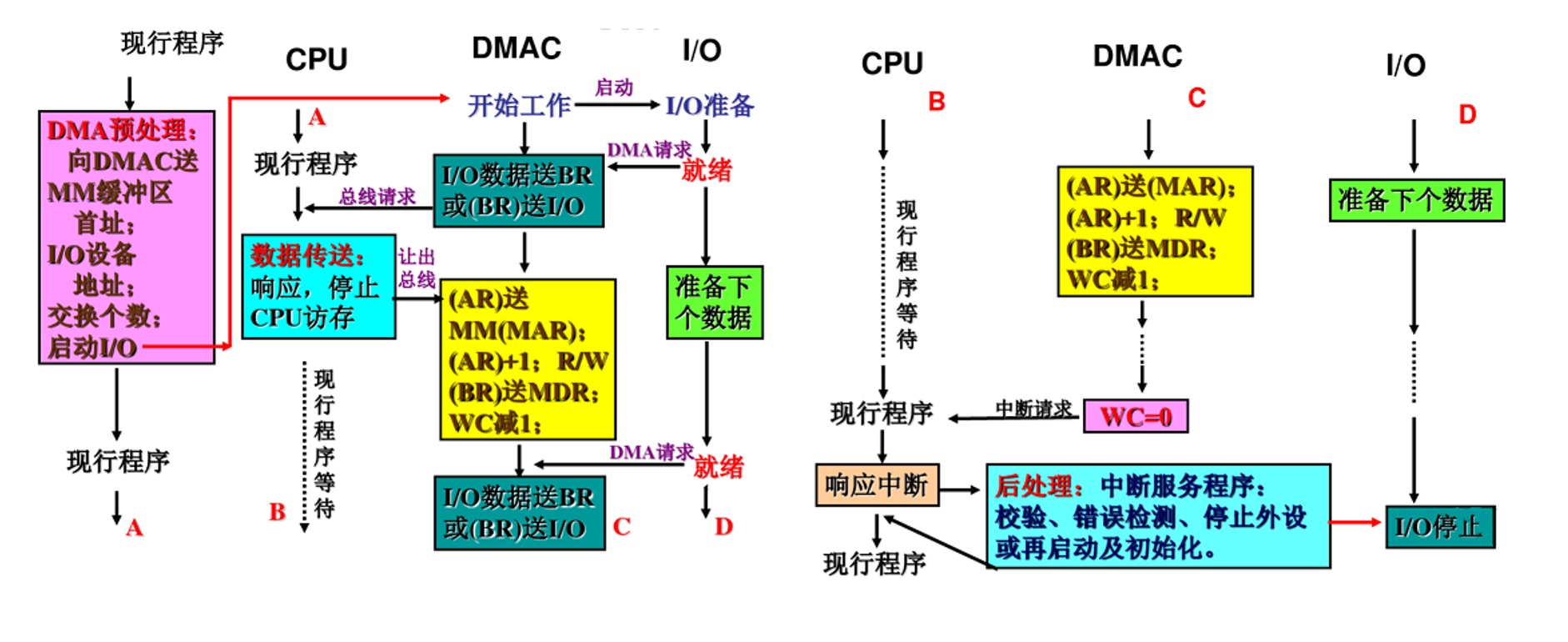
周期挪用方式传送数据


















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









