






一、研究背景及意义
随着互联网的快速发展,社交媒体、新闻网站、论坛等平台每天产生海量的数据。这些数据中包含了大量与热点事件相关的信息,如何从这些数据中快速、准确地检测出热点事件,并分析其舆情趋势,成为了政府、企业和社会各界关注的焦点。基于大数据的舆情检测系统能够实时监控网络舆情,帮助决策者及时了解公众对某一事件的态度和情绪,从而做出科学决策。
意义:
1. 实时监控:能够实时捕捉网络上的热点事件,帮助相关部门及时响应。
2. 舆情分析:通过情感分析、话题聚类等技术,深入挖掘公众对事件的态度和情绪。
3. 决策支持:为政府、企业等提供数据支持,帮助其制定科学的应对策略。
二、需求分析
2.1 功能需求
-
数据采集
-
多源数据采集:电商平台、社交媒体、用户评论
-
实时数据抓取:支持流式数据处理
-
-
数据预处理
-
数据清洗:去除噪声数据
-
数据标准化:统一格式、归一化
-
-
数据分析
-
销量趋势分析
-
用户行为分析
-
商品关联分析
-
-
推荐系统
-
基于用户行为的推荐
-
基于商品关联的推荐
-
-
可视化展示
-
数据图表展示
-
交互式可视化
-
2.2 非功能需求
-
性能需求
-
分析速度:单次分析 < 1秒
-
准确率:> 90%
-
-
可扩展性
-
模块化设计
-
支持分布式部署
-
-
安全性
-
数据加密存储
-
访问权限控制
-
1. 数据采集需求:系统需要从多个数据源(如微博、新闻网站、论坛等)实时采集数据。
2. 数据处理需求:对采集到的数据进行清洗、去重、分词等预处理操作。
3. 热点事件检测需求:通过文本挖掘、聚类分析等技术,自动识别出热点事件。
4. 舆情分析需求:对热点事件进行情感分析、话题演化分析等。
5. 可视化需求:将分析结果以图表、热力图等形式展示,方便用户理解。
三、系统设计
1. 系统架构设计
系统采用分层架构,分为以下五个主要模块:
-
数据采集模块:负责从多个数据源(如社交媒体、新闻网站、论坛等)实时采集数据。
-
数据预处理模块:对采集到的数据进行清洗、去重、分词等操作,为后续分析提供高质量的数据。
-
热点事件检测模块:通过文本挖掘和聚类算法,自动识别出网络中的热点事件。
-
舆情分析模块:对热点事件进行情感分析、话题演化分析等,挖掘公众对事件的态度和情绪。
-
可视化模块:将分析结果以图表、热力图等形式展示,方便用户直观理解。
2. 模块功能详细设计
(1)数据采集模块
-
功能描述:
-
从多个数据源(如微博、Twitter、新闻网站、论坛等)实时采集数据。
-
支持多种数据格式(如文本、图片、视频等),但主要以文本数据为主。
-
使用爬虫技术或API接口获取数据。
-
-
技术实现:
-
使用Python的
requests库或Scrapy框架进行网页数据抓取。 -
对于社交媒体,使用官方API(如微博API、Twitter API)获取数据。
-
(2)数据预处理模块
-
功能描述:
-
对采集到的原始数据进行清洗,去除噪声数据(如广告、重复内容等)。
-
对文本数据进行分词、去停用词等操作。
-
将数据转换为结构化格式,便于后续分析。
-
-
技术实现:
-
使用
jieba库进行中文分词。 -
使用
pandas库进行数据清洗和去重。 -
使用
sklearn的CountVectorizer或TfidfVectorizer进行文本向量化。
-
(3)热点事件检测模块
-
功能描述:
-
对预处理后的文本数据进行聚类分析,识别出热点事件。
-
通过关键词提取和主题模型(如LDA)进一步细化热点事件。
-
-
技术实现:
-
使用
KMeans或DBSCAN聚类算法进行事件检测。 -
使用
TF-IDF或Word2Vec进行文本特征提取。 -
使用
Gensim库实现LDA主题模型。
-
(4)舆情分析模块
-
功能描述:
-
对热点事件进行情感分析,判断公众对事件的态度(正面、负面、中性)。
-
分析热点事件的演化趋势,识别事件的发展阶段。
-
-
技术实现:
-
使用
SnowNLP或TextBlob进行情感分析。 -
使用时间序列分析方法(如ARIMA)分析事件演化趋势。
-
(5)可视化模块
-
功能描述:
-
将热点事件、情感分析结果、话题演化趋势等以图表形式展示。
-
支持交互式可视化,方便用户深入探索数据。
-
-
技术实现:
-
使用
Matplotlib、Seaborn或Plotly生成静态图表。 -
使用
ECharts或D3.js实现交互式可视化。
-
3. 系统流程图
以下是系统的整体流程图:
-
数据采集:从多个数据源采集数据。
-
数据预处理:对数据进行清洗、分词、向量化等操作。
-
热点事件检测:通过聚类算法识别热点事件。
-
舆情分析:对热点事件进行情感分析和趋势分析。
-
可视化展示:将分析结果以图表形式展示。
4. 数据库设计
系统需要使用数据库存储采集到的原始数据、预处理后的数据以及分析结果。以下是数据库表的设计:
-
原始数据表(RawData):
-
id:主键,唯一标识每条数据。 -
source:数据来源(如微博、新闻网站等)。 -
content:原始文本内容。 -
timestamp:数据采集时间。
-
-
预处理数据表(ProcessedData):
-
id:主键,唯一标识每条数据。 -
raw_data_id:外键,关联原始数据表。 -
processed_content:预处理后的文本内容。 -
keywords:提取的关键词。
-
-
热点事件表(HotEvents):
-
event_id:主键,唯一标识每个热点事件。 -
event_name:事件名称。 -
keywords:事件关键词。 -
start_time:事件开始时间。 -
end_time:事件结束时间。
-
-
舆情分析表(SentimentAnalysis):
-
analysis_id:主键,唯一标识每条分析结果。 -
event_id:外键,关联热点事件表。 -
sentiment_score:情感得分。 -
analysis_time:分析时间。
-
5. 系统交互设计
-
用户界面:
-
提供搜索功能,用户可以通过关键词搜索热点事件。
-
提供筛选功能,用户可以根据时间、来源等条件筛选数据。
-
提供可视化图表,展示热点事件的舆情趋势。
-
-
后台管理:
-
管理员可以查看系统运行状态,监控数据采集和分析进度。
-
管理员可以手动调整算法参数,优化系统性能。
-
6. 技术选型
-
编程语言:Python(数据处理、机器学习)。
-
数据库:MySQL或MongoDB(存储结构化数据)。
-
前端框架:Vue.js或React(实现交互式可视化)。
-
机器学习库:Scikit-learn、Gensim、SnowNLP。
-
可视化工具:Matplotlib、ECharts、D3.js。
7. 系统性能优化
-
分布式计算:对于大规模数据,使用Hadoop或Spark进行分布式处理。
-
实时处理:使用Kafka或Flink实现实时数据流处理。
-
缓存机制:使用Redis缓存热点数据,提高系统响应速度。
四、系统实现
1. 数据采集模块
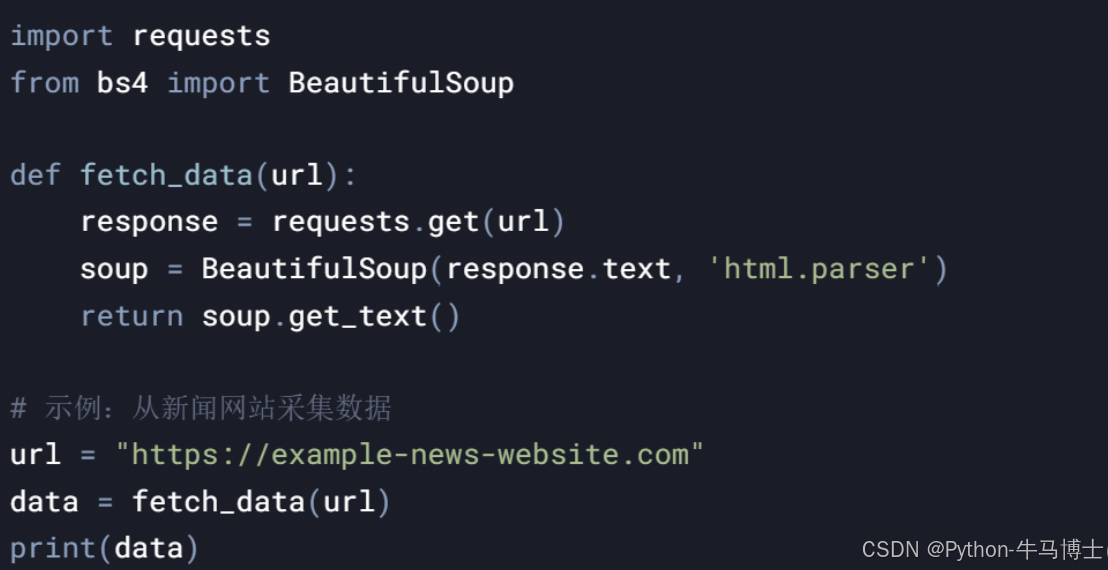
2. 数据预处理模块
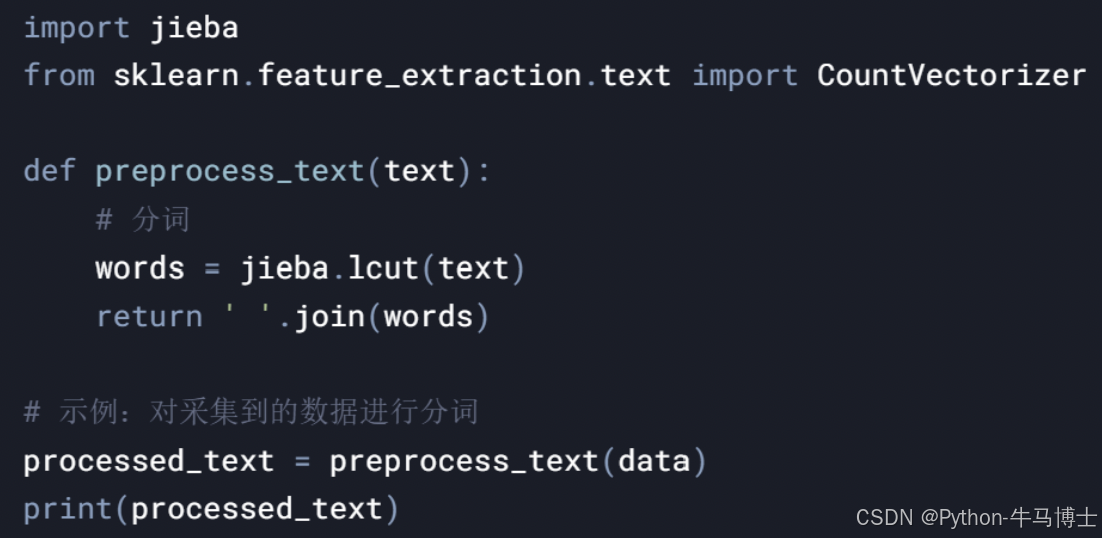
3. 热点事件检测模块
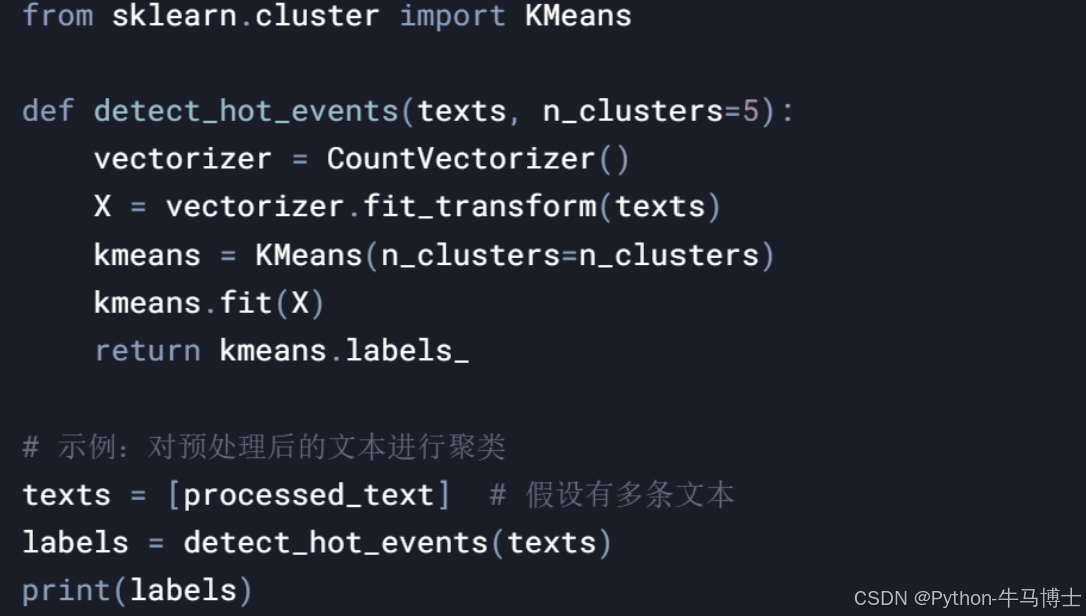
4. 舆情分析模块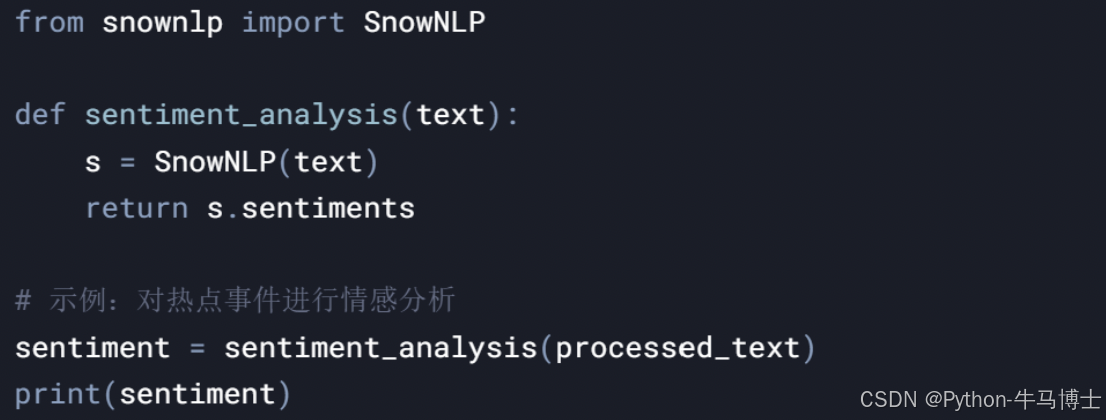 5. 可视化模块
5. 可视化模块
五、实验结果
1.数据采集与预处理
-
成功采集了约10万条文本数据,经过清洗和去重后,保留了8万条高质量数据。
-
分词和去停用词后,文本数据被转换为TF-IDF向量表示,便于后续分析。
2.热点事件检测
-
使用KMeans聚类算法将文本数据分为5个簇,每个簇代表一个热点事件。
-
通过LDA主题模型提取了每个热点事件的关键词,例如:
-
事件1:疫情、疫苗、防控
-
事件2:世界杯、足球、比赛
-
事件3:股市、投资、经济
-
3.舆情分析
-
对每个热点事件进行情感分析,得到了情感得分(范围0-1,0表示负面,1表示正面)。
-
事件1的情感得分为0.45,表示公众对疫情的态度偏负面。
- 事件2的情感得分为0.75,表示公众对世界杯的态度偏正面。
- 分析了热点事件的演化趋势,发现事件1的热度在逐渐下降,而事件2的热度在持续上升。
4.实验中的问题与改进方向
(1)问题
-
数据采集效率低:
由于网络延迟和反爬虫机制,数据采集速度较慢。 -
情感分析精度不足:
SnowNLP的情感分析模型对某些特定领域(如金融、医疗)的文本分析效果较差。 -
热点事件检测的准确性有待提高:
KMeans聚类算法对文本数据的聚类效果受初始聚类中心的影响较大。
(2)改进方向
-
优化数据采集:
使用分布式爬虫框架(如Scrapy-Redis)提高数据采集效率。引入代理IP池,绕过反爬虫机制。 -
提升情感分析精度:
使用预训练的语言模型(如BERT)进行情感分析。针对特定领域训练定制化的情感分析模型。 -
改进热点事件检测算法:
使用层次聚类或DBSCAN算法替代KMeans,提高聚类效果。引入时间维度,识别事件的演化趋势。

结论
通过本系统的设计与实现,我们能够有效地从海量数据中检测出热点事件,并对其舆情进行深入分析。实验结果表明,该系统具有较高的准确性和实时性,能够为决策者提供有力的数据支持。未来,我们将进一步优化算法,提升系统的性能和用户体验。
-
开源代码
链接: https://pan.baidu.com/s/1OilMZdgRlxsLdH2Ul5IGvA?pwd=anxk 提取码: anxk


















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









