






 本文介绍了常用的距离计算方法如欧氏距离、曼哈顿距离和切比雪夫距离,以及基于闵可夫斯基距离的参数化表示。重点讲解了特征预处理中的数据归一化和标准化,并以KNN算法为例展示了如何在鸢尾花数据集上进行分类,包括数据展示、处理和预测过程。
本文介绍了常用的距离计算方法如欧氏距离、曼哈顿距离和切比雪夫距离,以及基于闵可夫斯基距离的参数化表示。重点讲解了特征预处理中的数据归一化和标准化,并以KNN算法为例展示了如何在鸢尾花数据集上进行分类,包括数据展示、处理和预测过程。
距离度量
常用距离计算方法
欧氏距离
两个点在空间中的距离一般都是指欧氏距离
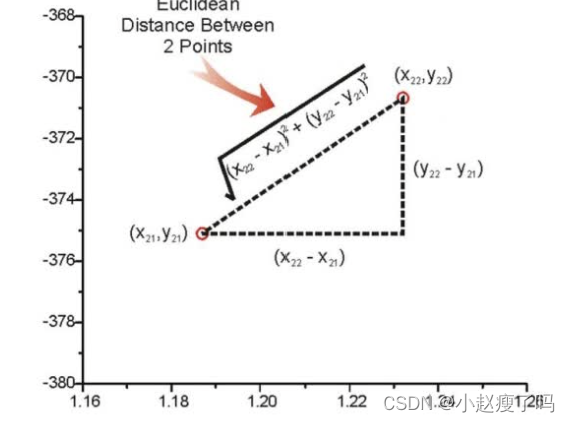
距离公式:

曼哈顿距离
特点:横平竖直
距离公式:

切比雪夫距离
距离公式:

闵可夫斯基距离(闵氏距离)
不是一种新的距离的度量方式
是对多个距离度量公式的概括性的表述
距离公式:

其中p是一个变参数:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞ 时,就是切比雪夫距离;
根据p的不同,闵氏距离可表示某一类种的距离
特征预处理
数据归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
from sklearn.preprocessing import MinMaxScaler
# 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
print(f'原始的data-->\n{data}')
# 实例化对象
transformer = MinMaxScaler()
# 数据归一化
data = transformer.fit_transform(data)
# 打印结果
print(f'归一化的data-->\n{data}')数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
from sklearn.preprocessing import StandardScaler
# 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
print(f'原始的data-->\n{data}')
# 实例化对象
transformer = StandardScaler()
# 数据归一化
data = transformer.fit_transform(data)
# 打印结果
print(f'标准化的data-->\n{data}')
print(f'均值-->\n{transformer.mean_}')
print(f'标准差-->\n{transformer.var_}')利用KNN算法对鸢尾花分类
实现流程:加载数据集—> 数据展示—>特征处理—>实例化—>训练—>评估—>预测
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
#显示鸢尾花数据
def dm02_showiris():
# 1载入鸢尾花数据集并显示特征名称
mydataset = load_iris()
print(mydataset.feature_names)
# 2数据转换,设置data,columns属性,目标值名称
iris_d = pd.DataFrame(mydataset['data'], columns=mydataset.feature_names)
iris_d['Species'] = mydataset.target
print('\niris_d-->\n', iris_d)
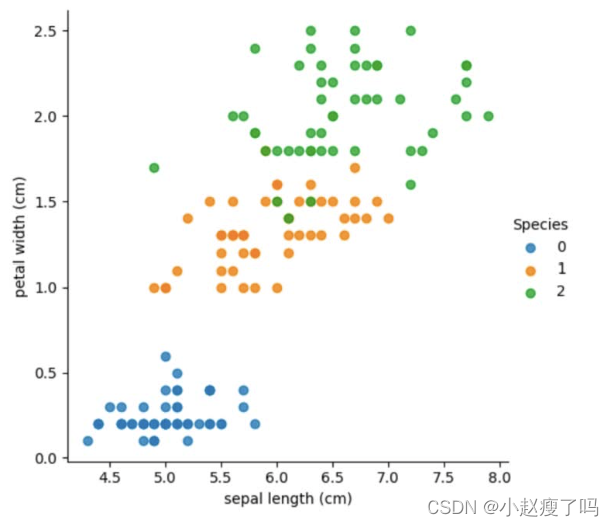
col1 = 'sepal length (cm)'
col2 = 'petal width (cm)'
# 3 sns.lmplot()展示
sns.lmplot()
sns.lmplot(x=col1, y=col2, data=iris_d, hue='Species', fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('iris')
plt.show()利用KNN算法加载鸢尾花数据集
利用KNN算法对鸢尾花分类流程代码
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# from sklearn.metrics import accuracy_score
# todo 1.加载数据集
iris_data = load_iris()
# print(f'数据集-->\n{iris_data.feature_names}\n{iris_data.data[:10]}')
# print(f'\n目标值-->\n{iris_data.target_names}\n{iris_data.target}')
# todo 2.数据展示
def dm02_irisdata_show():
iris_df = pd.DataFrame(iris_data['data'], columns=iris_data.feature_names)
print(iris_df)
iris_df['target'] = iris_data.target
print(iris_df)
feature_names = list(iris_data.feature_names)
print(feature_names)
for i in range(len(feature_names)):
for j in range(i + 1, len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
sns.lmplot(x=col1, y=col2, hue='target', data=iris_df,fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f'{col1} vs {col2}')
plt.show()
# todo 3.数据基本处理
# 数据计划分
x_train,x_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,test_size=0.3,random_state=32)
# print(x_train)
# print(f'数据总数量-->{len(iris_data.data)}')
# print(f'训练集数量-->{len(x_train)}')
# print(f'测试集数量-->{len(x_test)}')
# todo 4.特征处理
# 数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# print(f'标准化后的x_train-->{x_train}')
# todo 5.实例化
model = KNeighborsClassifier(n_neighbors=5)
# todo 6.训练
model.fit(x_train,y_train)
# todo 7.评估
# y_pre = model.predict(x_test)
# score = accuracy_score(y_test,y_pre)
# print(f'score-->{score}')
# score2 = model.score(x_test,y_test)
# print(f'score2-->{score2}')
# todo 8.预测
mydata = [[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata = transfer.fit_transform(mydata)
predata = model.predict(mydata)
print(f'predata-->{predata}')以上为我的分享~















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









