






目录
前言
什么叫做神经网络:包含输入层,隐藏层,输出层形成的类似蜘蛛网的网状结构(隐藏层包含多层)下图是包含一层的神经网络结构。
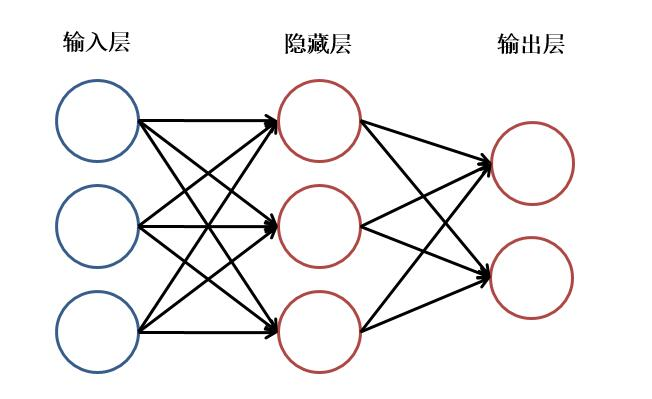
什么叫做模型:通过神经网络计算输出并且把权重记录到一个库中叫做模型,数学角度理解就算权重值,函数Y=KX+B,权重K,偏值B,这是一个关于Y(X)函数最简单的模型。
原理分析:假我们有一张图片要让AI来判断是什么类别,首先我们要将一张图片划分成一个一个像素点的,每一个像素点对应一个值。通过神经网络模型找出图中特有的特征比如(眼睛,鼻子等等)得到相应的值,记录在一个库里面成为模型。
下面跟着我详细来搭建一个简单图像分类模型:
环境准备
基于conda的python3.9环境
keras==2.9.0
tensorflow==2.9.1
numpy==1.23.1
scikit-learn==1.1.2环境搭建会吧(官网下载condaConda | Anaconda.org)(记得用管理员运行)
基本conda语法(创建自己环境安装环境)
1. 列出所有环境 conda env list
2. 查看当前激活的环境 conda info
3. 查看特定环境的详细信息 condo env export --name <environment_name>
4. 激活和停用环境 conda activate <environment_name> 停用当前环境conda deactivate
5. 创建新的环境 conda create --name <environment_name> [package_names] conda create --name python9 python=3.9
6. 删除环境 conda remove --name <environment_name> --all
7. 更新环境 conda update --all --name <environment_name>
8. 查看环境中的包 conda list --name <environment_name>
9.创建环境 conda create --name my_python39_env python=3.9
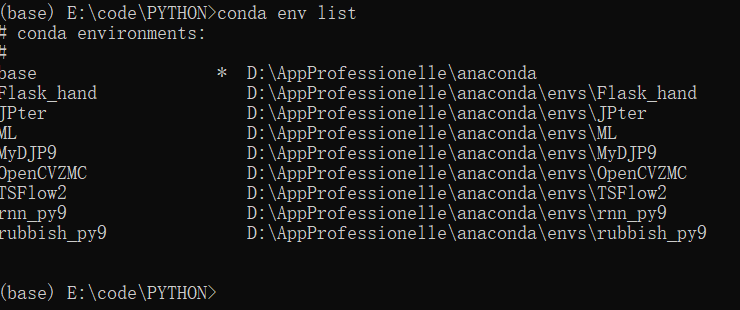
此知环境搭建就完成了
数据处理
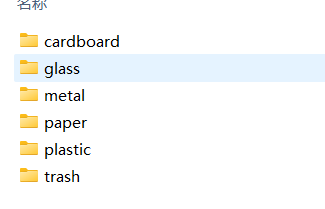
我一垃圾分类数据集为例子来进行分类
数据集下载
:评论区私信发压缩包😯
包含6个类别


数据增强处理
将下载好的数据大小规定相同,并且进行运用数据增强技术
def get_data_generators(batch_size):
""" 获取数据生成器 """
train_datagen = ImageDataGenerator(
rotation_range=10, # 随机旋转度数
width_shift_range=0.1, # 随机水平平移
height_shift_range=0.1, # 随机竖直平移
rescale=1 / 255, # 数据归一化
shear_range=0.1, # 随机裁剪
zoom_range=0.1, # 随机放大
horizontal_flip=True, # 水平翻转
fill_mode='nearest', # 填充方式
brightness_range=[0.5, 1.5] # 亮度变化 在数据生成器中增加了亮度变化,以增加数据多样性。
)
test_datagen = ImageDataGenerator(rescale=1 / 255) # 测试数据生成器,仅进行数据归一化
train_generator = train_datagen.flow_from_directory(
'../data/GarbageClassification', # 训练数据目录
target_size=(512, 384), # 图像目标尺寸
batch_size=batch_size, # 批次大小
class_mode='categorical' # 类别模式
)
test_generator = test_datagen.flow_from_directory(
'../data/test', # 测试数据目录
target_size=(512, 384), # 图像目标尺寸
batch_size=batch_size, # 批次大小
class_mode='categorical' # 类别模式
)
return train_generator, test_generator测试一张图片是否成功
def augment_and_show(image_path, batch_size=1, num_images=3, target_size=(150, 150)):
"""
加载图片,应用数据增强,并显示增强后的图片。
参数:
- image_path: 图片文件的路径。
- batch_size: 生成器每次返回的图片数量,默认为1。
- num_images: 要生成并显示的增强图片的数量,默认为5。
- target_size: 图片的目标尺寸,默认为 (150, 150)。
"""
# 创建数据生成器
datagen = ImageDataGenerator(
rotation_range=10, # 随机旋转度数
width_shift_range=0.1, # 随机水平平移
height_shift_range=0.1, # 随机竖直平移
rescale=1/255, # 数据归一化
shear_range=0.1, # 随机裁剪
zoom_range=0.1, # 随机放大
horizontal_flip=True, # 水平翻转
fill_mode='nearest', # 填充方式
brightness_range=[0.5, 1.5] # 亮度变化
)
# 加载图片
img = load_img(image_path, target_size=target_size)
img_array = img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
# 创建生成器实例
generator = datagen.flow(img_array, batch_size=batch_size)
# 从生成器获取增强后的图片
augmented_images = [next(generator)[0] for _ in range(num_images)]
# 绘制增强后的图片
fig, axes = plt.subplots(1, num_images, figsize=(15, 3))
for i, ax in enumerate(axes):
ax.imshow(augmented_images[i])
ax.axis('off')
plt.show()
image_path = 'picture/aftertaste/塑料瓶.jpg' # 替换为你的图片路径augment_and_show(image_path)
参数可调节角度,水平移动,垂直移动,随机裁剪,随机裁剪,以及亮度变换自行更改调节

模型搭建
辅助训练函数
函数create_directories()用于保存模型路径记录日志路径。函数write_log_start()写入训练日志以及日志标题。函数write_model_save_info()用于保存模型以及训练的多少轮。
def create_directories(model_dir, log_dir):
""" 创建模型保存目录和日志目录 """
if not os.path.exists(model_dir): # 检查模型保存目录是否存在
os.makedirs(model_dir) # 如果不存在则创建目录
if not os.path.exists(log_dir): # 检查日志目录是否存在
os.makedirs(log_dir) # 如果不存在则创建目录
def write_log_start(log_file):
""" 写入日志文件开头信息 """
with open(log_file, 'w') as f: # 打开日志文件,以写模式
f.write("Training Log\n") # 写入日志标题
f.write("Start Time: {}\n".format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))) # 写入训练开始时间
def write_class_indices(log_file, class_indices):
""" 写入训练数据的类别索引 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("Training Data Class Indices: {}\n".format(class_indices)) # 写入类别索引
def write_training_history(log_file, history):
""" 写入训练历史 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("\nTraining History:\n") # 写入训练历史标题
for key, value in history.history.items(): # 遍历训练历史
f.write("{}: {}\n".format(key, value)) # 写入每个指标的历史记录
def write_model_save_info(log_file, start_time, end_time):
""" 写入模型保存和训练结束信息 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("模型保存成功!\n") # 写入模型保存成功的消息
f.write("本次训练一共运行了:%s秒 ---- 约等于 %s分钟\n" % ((end_time - start_time), (end_time - start_time) / 60)) # 写入训练总时间
VGG19模型搭建
def define_model(num_classes):
""" 定义优化后的AlexNet模型 """
model = Sequential() # 创建Sequential模型
model.add( # 输出特征 卷积核高度宽度 # 步长 4*4 变化成7*7 是否填充不填充
Conv2D(filters=96, kernel_size=(3, 3), input_shape=(512, 384, 3), strides=(3, 3), padding='valid',
activation='relu')) # 第一层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu')) # 第二层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第三层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第四层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第五层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Flatten()) # 展平层
model.add(Dense(4096, activation='relu')) # 全连接层
model.add(Dropout(0.5)) # Dropout层,防止过拟合
model.add(Dense(4096, activation='relu')) # 全连接层
model.add(Dropout(0.5)) # Dropout层,防止过拟合
model.add(Dense(num_classes, activation='softmax')) # 输出层,num_classes个类别
return model输入层采用96个特征值(可以自行调节i9cpu建议128filter)输入图像形状512*384的彩色图,步长为3(可调节越小特征越准确吃cpu)。
model.add( # 输出特征 卷积核高度宽度 # 步长 4*4 变化成7*7 是否填充不填充
Conv2D(filters=96, kernel_size=(3, 3), input_shape=(512, 384, 3), strides=(3, 3), padding='valid',
activation='relu')) # 第一层卷积层核心隐藏层采用五层卷积层加上最大池化才层,展平层两个全连接层输出num个类别(softmax激活函数)下面通过三个辅助函数观察,卷积特征图,池化特征图,全连接特征图
卷积特征图,池化特征图,全连接特征图
首先图像归一化处理
def load_and_preprocess_image(image_path, target_size=(224, 224)):
# 加载图像
image = Image.open(image_path).convert('RGB')
# 调整图像大小
image = image.resize(target_size)
# 转换为NumPy数组
image_array = np.array(image) / 255.0 # 归一化到[0, 1]
# 增加一个批次维度
image_batch = np.expand_dims(image_array, axis=0)
return image_batch卷积特征:(这里采用8个特征图,卷积核2,步长1)
def visualize_conv_features(image_batch, filters=8, kernel_size=2, strides=1, padding='same'):
# 定义一个简单的卷积层
conv_layer = layers.Conv2D(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding,
activation='relu') # softmax relu sigmoid Tanh
# 将图像通过卷积层
feature_map = conv_layer(image_batch)
# 可视化卷积后的特征图
def plot_feature_maps(feature_map):
num_features = feature_map.shape[-1]
fig, axes = plt.subplots(1, num_features, figsize=(20, 5))
for i in range(num_features):
# 提取第i个特征图
feature = feature_map[0, :, :, i]
# 将特征图转换为NumPy数组
feature_np = feature.numpy()
# 归一化特征图以便可视化
feature_normalized = (feature_np - feature_np.min()) / (feature_np.max() - feature_np.min())
# 绘制特征图
axes[i].imshow(feature_normalized, cmap='viridis')
axes[i].axis('off')
axes[i].set_title(f'Feature Map {i + 1}')
plt.show()
# 指定图像路径
image_path = 'picture/aftertaste/电池.jpg'
# 加载并预处理图像
image_batch = load_and_preprocess_image(image_path)
# 调用函数可视化卷积特征图
visualize_conv_features(image_batch)
池化特征:(这里采用最大池化)
def max_pool_and_visualize(image_path, pool_size=8, stride=2, padding='VALID'):
"""
对一张图像进行最大池化操作,并可视化池化后的图像。
参数:
- image_path: 图像文件的路径
- pool_size: 池化窗口的大小 (默认为 2)
- stride: 池化窗口的步长 (默认为 None,表示等于池化窗口大小)
- padding: 填充方式 (默认为 'VALID',表示不填充)
"""
# 读取图像并转换为张量
image = Image.open(image_path)
image_array = np.array(image)
image_tensor = tf.convert_to_tensor(image_array, dtype=tf.float32)
image_tensor = tf.expand_dims(image_tensor, axis=0) # 增加批次维度
# 设置池化参数
if stride is None:
stride = pool_size
# 进行最大池化操作
# 定义最大池化层
max_pool_layer = tf.keras.layers.MaxPooling2D(pool_size=(pool_size, pool_size),
strides=(stride, stride),
padding=padding,
data_format='channels_last')
# 第一次最大池化操作
print(image_tensor.shape)
pooled_image_1 = max_pool_layer(image_tensor)
pooled_image_1_np = pooled_image_1.numpy().squeeze(0)
print(pooled_image_1.shape)
# 第二次最大池化操作
pooled_image_2 = max_pool_layer(pooled_image_1)
pooled_image_2_np = pooled_image_2.numpy().squeeze(0)
print(pooled_image_2.shape)
# 可视化原始图像和池化后的图像
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 原始图像
axes[0].imshow(image_array.astype(np.uint8))
axes[0].set_title('Original Image')
axes[0].axis('off')
# 第一次池化后的图像
axes[1].imshow(pooled_image_1_np.astype(np.uint8))
axes[1].set_title(f'First Max Pooled Image (Pool Size: {pool_size}, Stride: {stride})')
axes[1].axis('off')
# 第二次池化后的图像
axes[2].imshow(pooled_image_2_np.astype(np.uint8))
axes[2].set_title(f'Second Max Pooled Image (Pool Size: {pool_size}, Stride: {stride})')
axes[2].axis('off')
plt.show()
# 示例用法
# image_path = 'picture/aftertaste/塑料.jpg' # 可视化池化层
# max_pool_and_visualize(image_path)

 对应三个图的大小
对应三个图的大小
全连接特征:(可视化一次卷积,一次池化,一次全连接)
def visualize_layers(image_path, conv_filters, pool_size, fc_units):
"""
读取图像,进行一次卷积、一次池化和一次全连接操作,并可视化每个步骤的结果。
参数:
- image_path: 图像文件的路径
- conv_filters: 卷积层的滤波器数量
- pool_size: 池化层的池化窗口大小
- fc_units: 全连接层的输出单元数
"""
# 读取图像并转换为张量
image = Image.open(image_path)
image_array = np.array(image)
image_tensor = tf.convert_to_tensor(image_array, dtype=tf.float32)
image_tensor = tf.expand_dims(image_tensor, axis=0) # 增加批次维度
# 卷积层
conv_layer = tf.keras.layers.Conv2D(filters=conv_filters, kernel_size=3, padding='same', activation='relu')
conv_output = conv_layer(image_tensor)
print(conv_output.shape)
# 池化层
pool_layer = tf.keras.layers.MaxPooling2D(pool_size=pool_size, strides=2, padding='same')
pool_output = pool_layer(conv_output)
print(pool_output.shape)
# 展平输入张量
flat_input = tf.reshape(pool_output, [pool_output.shape[0], -1])
print(flat_input.shape)
# 全连接层
fc_layer = tf.keras.layers.Dense(units=fc_units, activation='softmax') # softmax relu
fc_output = fc_layer(flat_input)
print(fc_output.shape)
# 可视化输入图像、卷积层输出、池化层输出和全连接层输出
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 原始图像
axes[0, 0].imshow(image)
axes[0, 0].set_title('Original Image')
axes[0, 0].axis('off')
# 卷积层输出
conv_output_image = conv_output[0, :, :, 0] # 取第一个滤波器的输出
axes[0, 1].imshow(conv_output_image, cmap='viridis')
axes[0, 1].set_title('Convolution Layer Output')
axes[0, 1].axis('off')
# 池化层输出
pool_output_image = pool_output[0, :, :, 0] # 取第一个滤波器的输出
axes[1, 0].imshow(pool_output_image, cmap='viridis')
axes[1, 0].set_title('Pooling Layer Output')
axes[1, 0].axis('off')
# 全连接层输出
axes[1, 1].bar(range(fc_output.shape[1]), fc_output.numpy()[0])
axes[1, 1].set_title('Fully Connected Layer Output')
axes[1, 1].set_xlabel('Neuron Index')
axes[1, 1].set_ylabel('Activation Value')
plt.show()
image_path = 'picture/aftertaste/塑料.jpg' # 可视化全连接
visualize_layers(image_path, conv_filters=32, pool_size=2, fc_units=10)
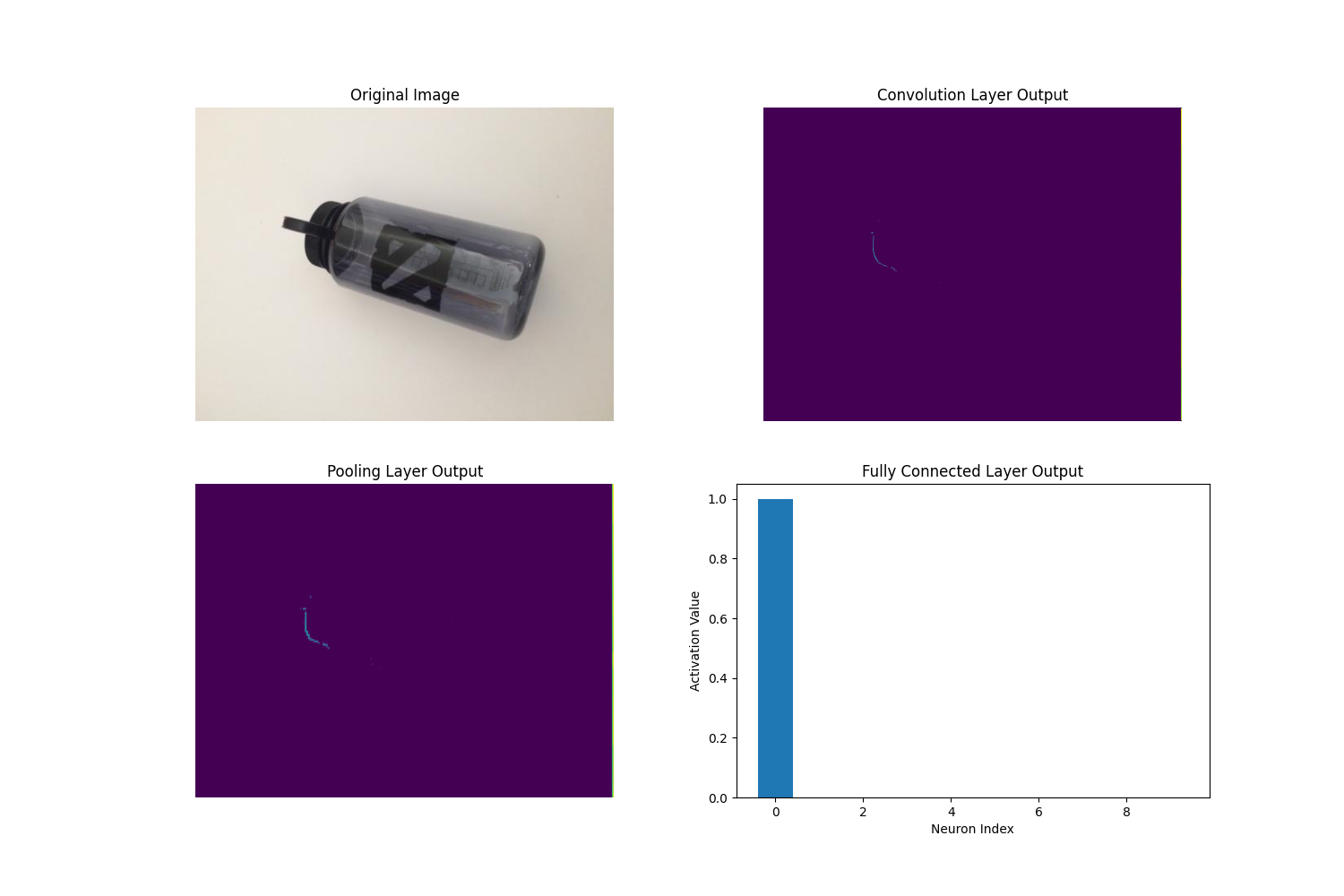
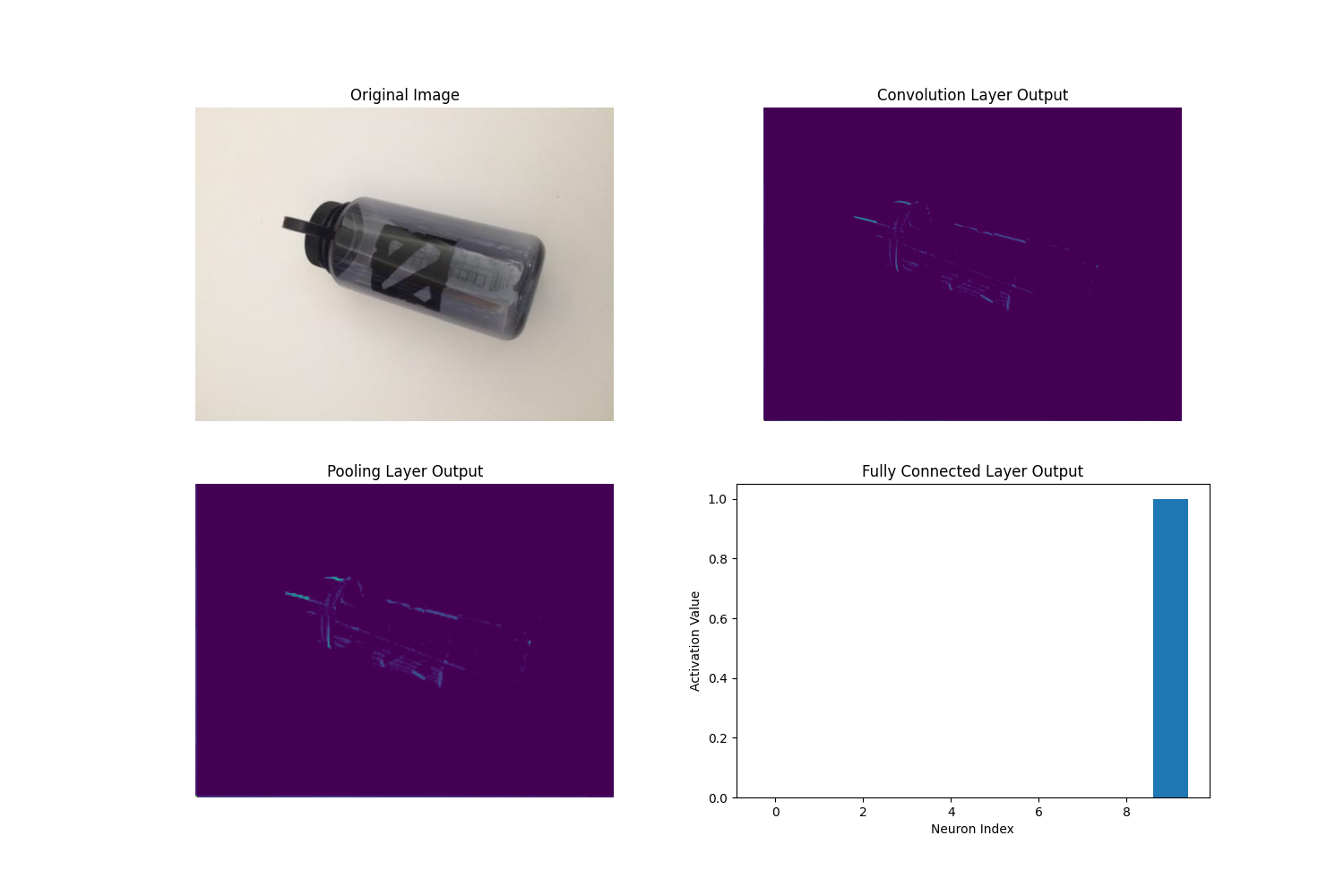
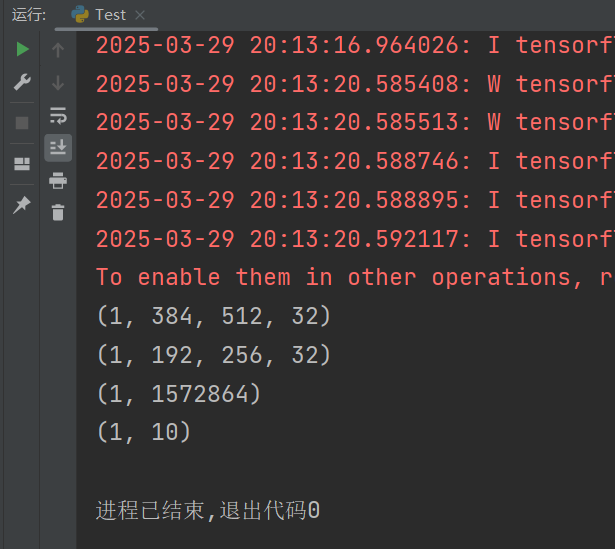
从上图可以看出每个特征图以及被分类的概率。
模型训练
回调函数
创建回调函数,以及可可视化训练函数。
def create_callbacks(log_file, filepath):
""" 创建回调函数列表 """
class TimeCallback(keras.callbacks.Callback):
def __init__(self, log_file):
super().__init__()
self.log_file = log_file # 初始化日志文件路径
def on_train_begin(self, logs={}):
self.start_time = time.time() # 记录训练开始时间
self.epoch_times = [] # 存储每轮的时间
def on_epoch_end(self, epoch, logs={}):
end_time = time.time() # 记录每轮结束时间
elapsed_time = end_time - self.start_time # 计算每轮耗时
self.epoch_times.append(elapsed_time) # 存储每轮耗时
avg_time_per_epoch = np.mean(self.epoch_times) # 计算平均每轮耗时
remaining_epochs = self.params['epochs'] - (epoch + 1) # 计算剩余轮数
estimated_remaining_time = remaining_epochs * avg_time_per_epoch # 估计剩余时间
log_message = "Epoch {}/{} - Loss: {:.4f}, Accuracy: {:.4f}, Val_Loss: {:.4f}, Val_Accuracy: {:.4f} - " \
"Estimated Remaining Time: {:.2f} seconds\n".format(
epoch + 1, self.params['epochs'], logs['loss'], logs['accuracy'], logs['val_loss'],
logs['val_accuracy'],
estimated_remaining_time) # 构建日志消息
with open(self.log_file, 'a') as f: # 打开日志文件,以追加模式
f.write(log_message) # 写入日志消息
print(log_message) # 打印日志消息
return [
ModelCheckpoint(filepath, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max',
save_freq='epoch'), # 模型检查点回调 参数讲解monitor被监控的数据 verbose 1表示epoch输出的信息
# filepath模型保存路径 save_best_only 如果为True,那么只保存在验证集上性能最好的模型。
TimeCallback(log_file)] # 自定义时间回调
# 可视化训练过程
def plot_training_history(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
main函数编写
def main():
start = time.time() # 记录开始时间
model_dir = 'model' # 确保模型保存目录存在
log_dir = 'log_record' # 日志记录
create_directories(model_dir, log_dir) # 创建必要的目录
# 日志文件路径
log_file = os.path.join(log_dir, 'test_iog.txt')
write_log_start(log_file) # 写入日志文件开头信息
num_classes = 6 # 假设有6个类别
model = define_model(num_classes) # 定义模型
batch_size = 16 # 批次大小
train_generator, test_generator = get_data_generators(batch_size) # 获取数据生成器
# 打印训练数据的类别索引
print(train_generator.class_indices)
write_class_indices(log_file, train_generator.class_indices) # 写入类别索引到日志文件
# 设置模型保存路径
filepath = os.path.join(model_dir, 'multi_classification_train_test.h5')
# 创建回调函数列表
callbacks_list = create_callbacks(log_file, filepath) # 创建回调函数列表
# 编译模型
model.compile(optimizer=Adam(learning_rate=1e-6), loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型
# 将学习率从 1e-4 降低到 1e-6,以进一步减少学习率,避免模型跳过最优解。
# 训练模型
history = model.fit(
train_generator, # 训练数据生成器
epochs=10, # 训练轮数
validation_data=test_generator, # 验证数据生成器
callbacks=callbacks_list # 回调函数列表
)
# 记录训练历史
write_training_history(log_file, history) # 写入训练历史到日志文件
# 保存模型
write_model_save_info(log_file, start, time.time()) # 写入模型保存和训练结束信息到日志文件
print("模型保存成功!")
print("本次训练一共运行了:%s秒 ---- 约等于 %s分钟" % ((time.time() - start), (time.time() - start) / 60)) # 打印训练总时间
# 调用可视化函数
plot_training_history(history)
if __name__ == "__main__":
main() # 运行主函数这里提示一下路径默认都要修改用自己文件的路径。

我这里训练一轮大概8分钟左右(之前训练的)
Training Log
Start Time: 2024-11-16 11:18:51
Training Data Class Indices: {'cardboard': 0, 'glass': 1, 'metal': 2, 'paper': 3, 'plastic': 4, 'trash': 5}
Epoch 1/30 - Loss: 3.3409, Accuracy: 0.2389, Val_Loss: 1.7816, Val_Accuracy: 0.2278 - Estimated Remaining Time: 8088.18 seconds
Epoch 2/30 - Loss: 2.8679, Accuracy: 0.2926, Val_Loss: 1.6783, Val_Accuracy: 0.3207 - Estimated Remaining Time: 11781.15 seconds
Epoch 3/30 - Loss: 2.5332, Accuracy: 0.3297, Val_Loss: 1.5626, Val_Accuracy: 0.4135 - Estimated Remaining Time: 15258.90 seconds
Epoch 4/30 - Loss: 2.3592, Accuracy: 0.3515, Val_Loss: 1.7205, Val_Accuracy: 0.4346 - Estimated Remaining Time: 18423.09 seconds
Epoch 5/30 - Loss: 2.3355, Accuracy: 0.3707, Val_Loss: 1.5964, Val_Accuracy: 0.4641 - Estimated Remaining Time: 21285.85 seconds
Epoch 6/30 - Loss: 2.1042, Accuracy: 0.3856, Val_Loss: 1.5763, Val_Accuracy: 0.4726 - Estimated Remaining Time: 23898.86 seconds
Epoch 7/30 - Loss: 1.9563, Accuracy: 0.4148, Val_Loss: 1.6505, Val_Accuracy: 0.4515 - Estimated Remaining Time: 26225.47 seconds
Epoch 8/30 - Loss: 1.9630, Accuracy: 0.3996, Val_Loss: 1.5487, Val_Accuracy: 0.4641 - Estimated Remaining Time: 28286.63 seconds
Epoch 9/30 - Loss: 1.9506, Accuracy: 0.4044, Val_Loss: 1.5171, Val_Accuracy: 0.4768 - Estimated Remaining Time: 30051.62 seconds
Epoch 10/30 - Loss: 1.8093, Accuracy: 0.4288, Val_Loss: 1.4816, Val_Accuracy: 0.4810 - Estimated Remaining Time: 31520.79 seconds
Epoch 11/30 - Loss: 1.7443, Accuracy: 0.4507, Val_Loss: 1.4163, Val_Accuracy: 0.4810 - Estimated Remaining Time: 32698.38 seconds
Epoch 12/30 - Loss: 1.6926, Accuracy: 0.4367, Val_Loss: 1.4594, Val_Accuracy: 0.4726 - Estimated Remaining Time: 33577.84 seconds
Epoch 13/30 - Loss: 1.6569, Accuracy: 0.4550, Val_Loss: 1.4255, Val_Accuracy: 0.4599 - Estimated Remaining Time: 34170.23 seconds
Epoch 14/30 - Loss: 1.5934, Accuracy: 0.4742, Val_Loss: 1.3334, Val_Accuracy: 0.4937 - Estimated Remaining Time: 34472.66 seconds
Epoch 15/30 - Loss: 1.5648, Accuracy: 0.4629, Val_Loss: 1.3989, Val_Accuracy: 0.4979 - Estimated Remaining Time: 34483.10 seconds
Epoch 16/30 - Loss: 1.5899, Accuracy: 0.4672, Val_Loss: 1.3749, Val_Accuracy: 0.4810 - Estimated Remaining Time: 34198.59 seconds
Epoch 17/30 - Loss: 1.5504, Accuracy: 0.4755, Val_Loss: 1.3415, Val_Accuracy: 0.4895 - Estimated Remaining Time: 33623.97 seconds
Epoch 18/30 - Loss: 1.4599, Accuracy: 0.4917, Val_Loss: 1.3510, Val_Accuracy: 0.4852 - Estimated Remaining Time: 32758.27 seconds
Epoch 19/30 - Loss: 1.4629, Accuracy: 0.4847, Val_Loss: 1.3467, Val_Accuracy: 0.4979 - Estimated Remaining Time: 31605.78 seconds
Epoch 20/30 - Loss: 1.4437, Accuracy: 0.4852, Val_Loss: 1.3831, Val_Accuracy: 0.4937 - Estimated Remaining Time: 30164.27 seconds
Epoch 21/30 - Loss: 1.4091, Accuracy: 0.4961, Val_Loss: 1.3562, Val_Accuracy: 0.5105 - Estimated Remaining Time: 28433.92 seconds
Epoch 22/30 - Loss: 1.3640, Accuracy: 0.5332, Val_Loss: 1.3532, Val_Accuracy: 0.4895 - Estimated Remaining Time: 26416.81 seconds
Epoch 23/30 - Loss: 1.3715, Accuracy: 0.5100, Val_Loss: 1.3134, Val_Accuracy: 0.4768 - Estimated Remaining Time: 24114.36 seconds
Epoch 24/30 - Loss: 1.2986, Accuracy: 0.5170, Val_Loss: 1.3370, Val_Accuracy: 0.5021 - Estimated Remaining Time: 21526.02 seconds
Epoch 25/30 - Loss: 1.3436, Accuracy: 0.5127, Val_Loss: 1.2849, Val_Accuracy: 0.5232 - Estimated Remaining Time: 18652.69 seconds
Epoch 26/30 - Loss: 1.2937, Accuracy: 0.5288, Val_Loss: 1.2902, Val_Accuracy: 0.5105 - Estimated Remaining Time: 15493.43 seconds
Epoch 27/30 - Loss: 1.3017, Accuracy: 0.5166, Val_Loss: 1.3041, Val_Accuracy: 0.5401 - Estimated Remaining Time: 12048.52 seconds
Epoch 28/30 - Loss: 1.2527, Accuracy: 0.5410, Val_Loss: 1.2805, Val_Accuracy: 0.5232 - Estimated Remaining Time: 8317.70 seconds
Epoch 29/30 - Loss: 1.2753, Accuracy: 0.5397, Val_Loss: 1.2841, Val_Accuracy: 0.5148 - Estimated Remaining Time: 4301.43 seconds
Epoch 30/30 - Loss: 1.2245, Accuracy: 0.5616, Val_Loss: 1.2890, Val_Accuracy: 0.5232 - Estimated Remaining Time: 0.00 seconds
Training History:
loss: [3.340884208679199, 2.867870569229126, 2.5332372188568115, 2.359208106994629, 2.3354685306549072, 2.1041789054870605, 1.9562690258026123, 1.9629878997802734, 1.9506416320800781, 1.8093208074569702, 1.7442997694015503, 1.6926182508468628, 1.656939148902893, 1.5934324264526367, 1.564758539199829, 1.5898915529251099, 1.5504276752471924, 1.4598692655563354, 1.4628880023956299, 1.4437172412872314, 1.4090903997421265, 1.3639603853225708, 1.3714642524719238, 1.2986280918121338, 1.343636393547058, 1.2936680316925049, 1.3016674518585205, 1.2527035474777222, 1.2752952575683594, 1.2245419025421143]
accuracy: [0.23886463046073914, 0.2925764322280884, 0.32969433069229126, 0.3515283763408661, 0.3707423508167267, 0.38558951020240784, 0.41484716534614563, 0.3995633125305176, 0.4043668210506439, 0.42882096767425537, 0.4506550133228302, 0.43668121099472046, 0.45502182841300964, 0.47423580288887024, 0.4628821015357971, 0.46724891662597656, 0.47554585337638855, 0.491703063249588, 0.48471614718437195, 0.48515284061431885, 0.49606987833976746, 0.533187747001648, 0.5100436806678772, 0.5170305967330933, 0.5126637816429138, 0.5288209319114685, 0.516593873500824, 0.5410480499267578, 0.5397379994392395, 0.5615720748901367]
val_loss: [1.7816048860549927, 1.678263545036316, 1.5625799894332886, 1.7204755544662476, 1.596358299255371, 1.576268196105957, 1.6505039930343628, 1.548664927482605, 1.5170931816101074, 1.4815529584884644, 1.4163448810577393, 1.4593719244003296, 1.425512433052063, 1.3333649635314941, 1.398883581161499, 1.3748672008514404, 1.3414623737335205, 1.3510297536849976, 1.3467077016830444, 1.3831374645233154, 1.3561547994613647, 1.3532150983810425, 1.3134098052978516, 1.3370168209075928, 1.2848548889160156, 1.2901666164398193, 1.3041305541992188, 1.280457854270935, 1.2840877771377563, 1.2889574766159058]
val_accuracy: [0.2278480976819992, 0.3206751048564911, 0.4135020971298218, 0.4345991611480713, 0.4641350209712982, 0.472573846578598, 0.4514767825603485, 0.4641350209712982, 0.4767932593822479, 0.4810126721858978, 0.4810126721858978, 0.472573846578598, 0.4599156081676483, 0.49367088079452515, 0.49789029359817505, 0.4810126721858978, 0.48945146799087524, 0.48523205518722534, 0.49789029359817505, 0.49367088079452515, 0.5105485320091248, 0.48945146799087524, 0.4767932593822479, 0.502109706401825, 0.5232067704200745, 0.5105485320091248, 0.5400843620300293, 0.5232067704200745, 0.5147679448127747, 0.5232067704200745]
模型保存成功!
本次训练一共运行了:8575.937643527985秒 ---- 约等于 142.93229405879976分钟
效果还是有明显变化(准确率在不断上升,损失值不断下降)
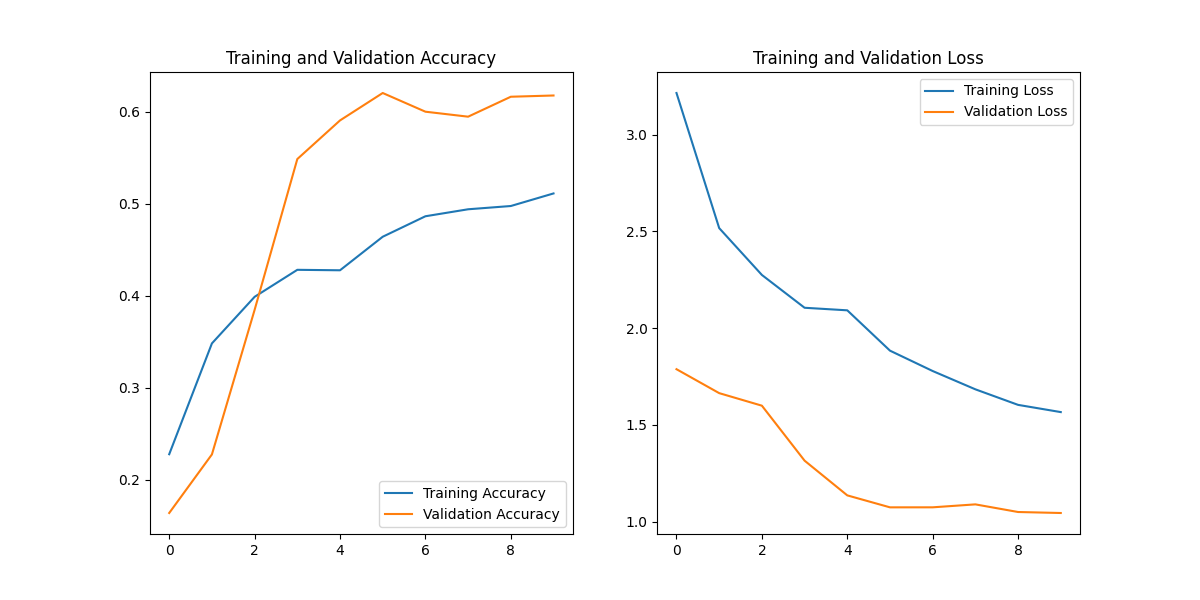
模型会以h5格式保存
模型测试
单张图片测试
import os
import numpy as np
from keras.models import load_model
from keras.utils import load_img, img_to_array
import time
# 记录开始时间
start = time.time()
# 加载模型
model_path = 'model/Accuracy69.h5'
if not os.path.exists(model_path):
raise FileNotFoundError(f"The model file '{model_path}' does not exist.")
model = load_model(model_path)
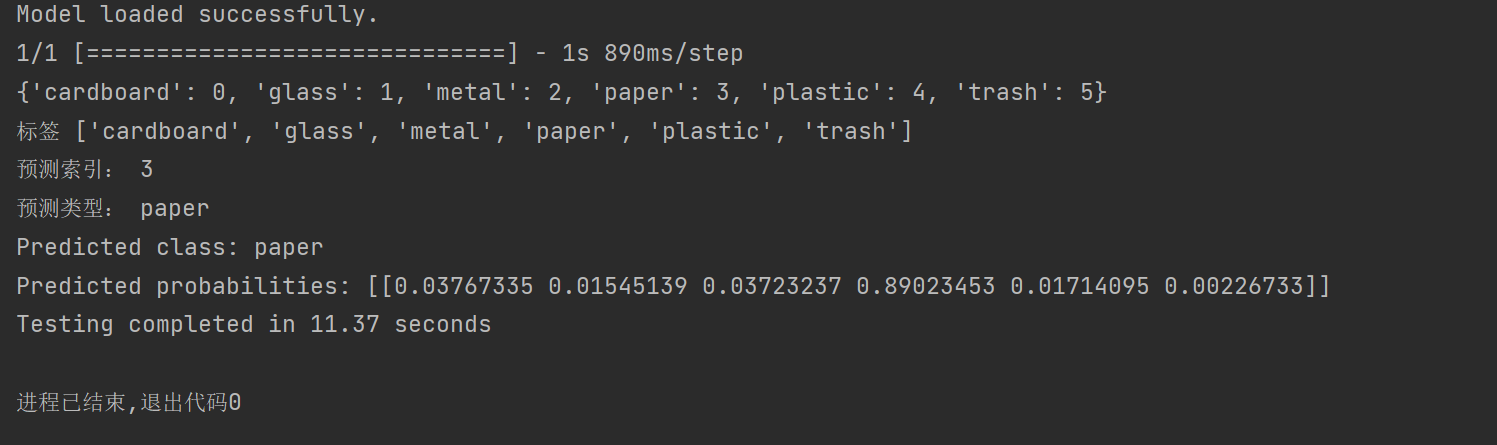
print("Model loaded successfully.")
# 设置图片路径
image_path = '../data/many_test/paper561.jpg' # 替换为你的图片路径
# 加载图片并预处理
img = load_img(image_path, target_size=(512, 384)) # 调整图片大小
img_array = img_to_array(img) # 转换为数组
img_array = np.expand_dims(img_array, axis=0) # 添加批次维度
img_array /= 255.0 # 归一化
# 进行预测
predictions = model.predict(img_array)
# 获取类别索引
class_indices = {'cardboard': 0, 'glass': 1, 'metal': 2, 'paper': 3, 'plastic': 4, 'trash': 5} # 根据你的训练数据生成器的类别索引调整
class_labels = list(class_indices.keys())
print(class_indices)
print("标签", class_labels)
# 获取预测类别
predicted_class_index = np.argmax(predictions, axis=1)[0]
predicted_class_label = class_labels[predicted_class_index]
print("预测索引:", predicted_class_index) # 打印预测索引
print("预测类型:", predicted_class_label)
# 打印预测结果
print(f"Predicted class: {predicted_class_label}")
print(f"Predicted probabilities: {predictions}")
# 记录结束时间
end = time.time()
print(f"Testing completed in {(end - start):.2f} seconds")我上传的图为paper(落在paper概率为0.89023453)
预测实物
# -*- coding: utf-8 -*-
import cv2
import sys
import numpy as np
from keras.models import load_model
from keras_preprocessing.image import img_to_array
# 加载训练好的模型
model_path = 'model/Accuracy69.h5'
try:
model = load_model(model_path)
print(f"模型加载成功:{model_path}")
except Exception as e:
print(f"无法加载模型:{e}")
sys.exit(1)
# 类别标签映射
class_indices = {'cardboard': 0, 'glass': 1, 'metal': 2, 'paper': 3, 'plastic': 4, 'trash': 5}
class_labels = {v: k for k, v in class_indices.items()} # 反转字典,方便后续使用
# 设置摄像头
cap = cv2.VideoCapture(0) # 0 表示默认摄像头
if not cap.isOpened():
print("无法打开摄像头")
sys.exit(1)
# 设置图像预处理参数
input_shape = (384, 512, 3) # 假设你的模型输入大小为 512x384
target_size = (input_shape[0], input_shape[1])
# 创建一个窗口用于显示结果
cv2.namedWindow('Garbage Classification', cv2.WINDOW_NORMAL)
while True:
# 读取摄像头帧
ret, frame = cap.read()
if not ret:
print("无法获取摄像头帧")
break
# 显示原始帧
cv2.imshow('Garbage Classification', frame)
# 预处理图像
try:
img = cv2.resize(frame, target_size) # 调整图像大小
img = img_to_array(img) # 将图像转换为数组
img = np.expand_dims(img, axis=0) # 添加批次维度
img = img / 255.0 # 归一化
# 进行预测
predictions = model.predict(img)
predicted_class = np.argmax(predictions, axis=1)[0]
predicted_label = class_labels[predicted_class]
confidence = predictions[0][predicted_class]
# 在图像上显示预测结果
label_text = f"Class: {predicted_label}, Confidence: {confidence:.2f}"
cv2.putText(frame, label_text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2, cv2.LINE_AA)
# 显示带有预测结果的图像
cv2.imshow('Garbage Classification', frame)
except Exception as e:
print(f"图像预处理或预测时出错:{e}")
# 按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头资源并关闭窗口
cap.release()
cv2.destroyAllWindows()

预测分类
准备了150张glass(预测打印每一张图以及准确率)
1/1 [==============================] - 0s 106ms/step
Image: glass98.jpg
Predicted class: glass
True class: glass
Prediction is correct: True
Predicted probabilities: [0.06439121 0.7634102 0.09975921 0.00926053 0.06004699 0.00313186]
----------------------------------------
1/1 [==============================] - 0s 121ms/step
Image: glass99.jpg
Predicted class: glass
True class: glass
Prediction is correct: True
Predicted probabilities: [0.11105543 0.54373616 0.25552285 0.02794291 0.05041091 0.0113318 ]
----------------------------------------
glasss类预测(代码如下)
import os
import numpy as np
from keras.models import load_model
from keras.utils import load_img, img_to_array
import time
# 记录开始时间
start = time.time()
# 加载模型
model_path = 'model/Accuracy69.h5'
if not os.path.exists(model_path):
raise FileNotFoundError(f"The model file '{model_path}' does not exist.")
model = load_model(model_path)
print("Model loaded successfully.")
# 设置图片路径
image_folder = '../data/test/glass/' # 替换为你的图片文件夹路径
# 获取类别索引
class_indices = {'cardboard': 0, 'glass': 1, 'metal': 2, 'paper': 3, 'plastic': 4, 'trash': 5}
class_labels = list(class_indices.keys()) # 将类别索引转换为类别标签列表
# 初始化计数器
correct_predictions = 0
total_images = 0
# 遍历文件夹中的所有图片
for filename in os.listdir(image_folder):
if filename.endswith(('.jpg', '.png', '.jpeg')): # 检查文件扩展名是否为图片格式
image_path = os.path.join(image_folder, filename) # 构建完整的图片路径
# 加载图片并预处理
img = load_img(image_path, target_size=(512, 384)) # 调整图片大小
img_array = img_to_array(img) # 转换为数组
img_array = np.expand_dims(img_array, axis=0) # 添加批次维度
img_array /= 255.0 # 归一化
# 进行预测
predictions = model.predict(img_array) # 使用模型进行预测
# 获取预测类别
predicted_class_index = np.argmax(predictions, axis=1)[0] # 获取预测类别的索引
predicted_class_label = class_labels[predicted_class_index] # 将索引转换为类别标签
# 假设这是这张图片的真实标签
true_label = 'glass' # 因为我们正在测试 glass 类别
# 计算预测是否正确
is_correct = true_label == predicted_class_label # 比较预测标签和真实标签
if is_correct:
correct_predictions += 1 # 如果预测正确,增加正确预测计数
# 打印单张图片的预测结果
print(f"Image: {filename}")
print(f"Predicted class: {predicted_class_label}")
print(f"True class: {true_label}")
print(f"Prediction is correct: {is_correct}")
print(f"Predicted probabilities: {predictions[0]}") # 打印预测的概率分布
print("-" * 40) # 分割线,便于阅读
total_images += 1 # 增加总图片计数
# 计算准确率
accuracy = (correct_predictions / total_images) * 100 # 计算准确率(百分比)
# 打印最终结果
print(f"Total images: {total_images}")
print(f"Correct predictions: {correct_predictions}")
print(f"Accuracy for glass class: {accuracy:.2f}%")
# 记录结束时间
end = time.time()
print(f"Testing completed in {(end - start):.2f} seconds")完整代码:
import os
import time
import keras
import numpy as np
from keras.optimizers import Adam # 使用Adam优化器
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Flatten, BatchNormalization, Dropout, Dense, Activation, Conv2D, MaxPooling2D
from keras.models import Sequential
from keras.callbacks import ModelCheckpoint
from matplotlib import pyplot as plt
def create_directories(model_dir, log_dir):
""" 创建模型保存目录和日志目录 """
if not os.path.exists(model_dir): # 检查模型保存目录是否存在
os.makedirs(model_dir) # 如果不存在则创建目录
if not os.path.exists(log_dir): # 检查日志目录是否存在
os.makedirs(log_dir) # 如果不存在则创建目录
def write_log_start(log_file):
""" 写入日志文件开头信息 """
with open(log_file, 'w') as f: # 打开日志文件,以写模式
f.write("Training Log\n") # 写入日志标题
f.write("Start Time: {}\n".format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))) # 写入训练开始时间
def write_class_indices(log_file, class_indices):
""" 写入训练数据的类别索引 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("Training Data Class Indices: {}\n".format(class_indices)) # 写入类别索引
def write_training_history(log_file, history):
""" 写入训练历史 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("\nTraining History:\n") # 写入训练历史标题
for key, value in history.history.items(): # 遍历训练历史
f.write("{}: {}\n".format(key, value)) # 写入每个指标的历史记录
def write_model_save_info(log_file, start_time, end_time):
""" 写入模型保存和训练结束信息 """
with open(log_file, 'a') as f: # 打开日志文件,以追加模式
f.write("模型保存成功!\n") # 写入模型保存成功的消息
f.write("本次训练一共运行了:%s秒 ---- 约等于 %s分钟\n" % ((end_time - start_time), (end_time - start_time) / 60)) # 写入训练总时间
def define_model(num_classes):
""" 定义优化后的AlexNet模型 """
model = Sequential() # 创建Sequential模型
model.add( # 输出特征 卷积核高度宽度 # 步长 4*4 变化成7*7 是否填充不填充
Conv2D(filters=96, kernel_size=(3, 3), input_shape=(512, 384, 3), strides=(3, 3), padding='valid',
activation='relu')) # 第一层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu')) # 第二层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第三层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第四层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) # 第五层卷积层
model.add(BatchNormalization()) # 添加批量归一化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # 最大池化层
model.add(Flatten()) # 展平层
model.add(Dense(4096, activation='relu')) # 全连接层
model.add(Dropout(0.5)) # Dropout层,防止过拟合
model.add(Dense(4096, activation='relu')) # 全连接层
model.add(Dropout(0.5)) # Dropout层,防止过拟合
model.add(Dense(num_classes, activation='softmax')) # 输出层,num_classes个类别
return model
def get_data_generators(batch_size):
""" 获取数据生成器 """
train_datagen = ImageDataGenerator(
rotation_range=10, # 随机旋转度数
width_shift_range=0.1, # 随机水平平移
height_shift_range=0.1, # 随机竖直平移
rescale=1 / 255, # 数据归一化
shear_range=0.1, # 随机裁剪
zoom_range=0.1, # 随机放大
horizontal_flip=True, # 水平翻转
fill_mode='nearest', # 填充方式
brightness_range=[0.5, 1.5] # 亮度变化 在数据生成器中增加了亮度变化,以增加数据多样性。
)
test_datagen = ImageDataGenerator(rescale=1 / 255) # 测试数据生成器,仅进行数据归一化
train_generator = train_datagen.flow_from_directory(
'../data/GarbageClassification', # 训练数据目录
target_size=(512, 384), # 图像目标尺寸
batch_size=batch_size, # 批次大小
class_mode='categorical' # 类别模式
)
test_generator = test_datagen.flow_from_directory(
'../data/test', # 测试数据目录
target_size=(512, 384), # 图像目标尺寸
batch_size=batch_size, # 批次大小
class_mode='categorical' # 类别模式
)
return train_generator, test_generator
def create_callbacks(log_file, filepath):
""" 创建回调函数列表 """
class TimeCallback(keras.callbacks.Callback):
def __init__(self, log_file):
super().__init__()
self.log_file = log_file # 初始化日志文件路径
def on_train_begin(self, logs={}):
self.start_time = time.time() # 记录训练开始时间
self.epoch_times = [] # 存储每轮的时间
def on_epoch_end(self, epoch, logs={}):
end_time = time.time() # 记录每轮结束时间
elapsed_time = end_time - self.start_time # 计算每轮耗时
self.epoch_times.append(elapsed_time) # 存储每轮耗时
avg_time_per_epoch = np.mean(self.epoch_times) # 计算平均每轮耗时
remaining_epochs = self.params['epochs'] - (epoch + 1) # 计算剩余轮数
estimated_remaining_time = remaining_epochs * avg_time_per_epoch # 估计剩余时间
log_message = "Epoch {}/{} - Loss: {:.4f}, Accuracy: {:.4f}, Val_Loss: {:.4f}, Val_Accuracy: {:.4f} - " \
"Estimated Remaining Time: {:.2f} seconds\n".format(
epoch + 1, self.params['epochs'], logs['loss'], logs['accuracy'], logs['val_loss'],
logs['val_accuracy'],
estimated_remaining_time) # 构建日志消息
with open(self.log_file, 'a') as f: # 打开日志文件,以追加模式
f.write(log_message) # 写入日志消息
print(log_message) # 打印日志消息
return [
ModelCheckpoint(filepath, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max',
save_freq='epoch'), # 模型检查点回调 参数讲解monitor被监控的数据 verbose 1表示epoch输出的信息
# filepath模型保存路径 save_best_only 如果为True,那么只保存在验证集上性能最好的模型。
TimeCallback(log_file)] # 自定义时间回调
# 可视化训练过程
def plot_training_history(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
def main():
start = time.time() # 记录开始时间
model_dir = 'model' # 确保模型保存目录存在
log_dir = 'log_record' # 日志记录
create_directories(model_dir, log_dir) # 创建必要的目录
# 日志文件路径
log_file = os.path.join(log_dir, 'test_iog.txt')
write_log_start(log_file) # 写入日志文件开头信息
num_classes = 6 # 假设有6个类别
model = define_model(num_classes) # 定义模型
batch_size = 16 # 批次大小
train_generator, test_generator = get_data_generators(batch_size) # 获取数据生成器
# 打印训练数据的类别索引
print(train_generator.class_indices)
write_class_indices(log_file, train_generator.class_indices) # 写入类别索引到日志文件
# 设置模型保存路径
filepath = os.path.join(model_dir, 'multi_classification_train_test.h5')
# 创建回调函数列表
callbacks_list = create_callbacks(log_file, filepath) # 创建回调函数列表
# 编译模型
model.compile(optimizer=Adam(learning_rate=1e-6), loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型
# 将学习率从 1e-4 降低到 1e-6,以进一步减少学习率,避免模型跳过最优解。
# 训练模型
history = model.fit(
train_generator, # 训练数据生成器
epochs=10, # 训练轮数
validation_data=test_generator, # 验证数据生成器
callbacks=callbacks_list # 回调函数列表
)
# 记录训练历史
write_training_history(log_file, history) # 写入训练历史到日志文件
# 保存模型
write_model_save_info(log_file, start, time.time()) # 写入模型保存和训练结束信息到日志文件
print("模型保存成功!")
print("本次训练一共运行了:%s秒 ---- 约等于 %s分钟" % ((time.time() - start), (time.time() - start) / 60)) # 打印训练总时间
# 调用可视化函数
plot_training_history(history)
if __name__ == "__main__":
main() # 运行主函数
总结:本文主要核心是神经网络的搭建以及模型训练的流程,并没有详细讲解卷积神经网络的原理。目前简单的vgg图片分类项目大概运用的知识tensor flow框架以及keras框架。
在搭建模型时候注意环境中各个包的版本兼容问题,在数据处理方面数据增强技术是有利于模型的泛化能力,cnn网络搭建注意输入图形状大小和实际大小一致,隐藏层合理利用池化层(最大最小),激活函数(relu,sofmax)全连接层展平层根据自己的分类情况进行选择(Sigmoid 二分类,softmax多分类)调节训练轮数注意分配内存空间,卷积核大小,步长,批次大小选择(按照需求选择)多轮进行修改确保模型的最优化。
如果对你在学习中有所帮助记得点赞收藏下次进行复习,如有问题欢迎评论区提出修改建议。

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









