






前言
上文讲解了强化学习模型ai训练玩马里奥游戏的环境,本文正式开始详细讲述训练过程。请在以下训练环境中运行本文的代码:
##环境##
#pip install gym==0.23
#pip install nes-py==8.1.8
#pip install gym-super-mario-bros==7.3.0
#pip install stable_baselines3==2.0.0
#pip install Optuna
一、库导入与游戏环境设置
1)import库
import gym_super_mario_bros
from nes_py.wrappers import JoypadSpace
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
其中SIMPLE_MOVEMENT用于加入简化的操作方法,可以方便我们的AI操作马里奥。我们print以下SIMPLE_MOVEMENT查看:
[['NOOP'], ['right'], ['right', 'A'], ['right', 'B'],
['right', 'A', 'B'], ['A'], ['left']]
是一个操作的列表。
2)设置游戏环境对象
environment = gym_super_mario_bros.make('SuperMarioBros-v0')
environment = JoypadSpace(environment, SIMPLE_MOVEMENT)
我们设置一个游戏环境的对象,其中使用的马里奥版本是标准版本(v0)
当然,你也可以使用别的版本,各个版本的差异请访问gymmario官网
第二行限定了ai的动作空间。即简单操作中包含的7个不同的按键组合。
我们这里涉及到了动作空间和观察空间,简单来说动作空间就是我们能干嘛,观察空间是我们的ai能看到啥,具体解释请看解释网址。
3)打开游戏窗口
done = True
for step in range(10000):
if done:
environment.reset()
state, reward, done, info = environment.step(environment.action_space.sample())
environment.render()
environment.close()
此段望文生义即可,其中action_sample是指动作空间中的随便一个样例;.render()方法将游戏显示在屏幕上。这段实现了打开游戏,随机做10000个动作,然后关闭窗口。
运行代码效果如下(完整代码在下方):
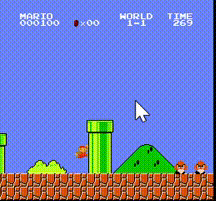
import gym_super_mario_bros
from nes_py.wrappers import JoypadSpace
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
environment = gym_super_mario_bros.make('SuperMarioBros-v0')
environment = JoypadSpace(environment, SIMPLE_MOVEMENT)
done = True
for step in range(10000):
if done:
environment.reset()
state, reward, done, info = environment.step(environment.action_space.sample())
environment.render()
environment.close()
二、预处理 Repreprocessing与环境矢量化
接下来,我们要进行预处理,开始正式识别、训练。
1)预处理的库
代码如下:
from gym.wrappers import FrameStack, GrayScaleObservation
from stable_baselines3.common.vec_env import VecFrameStack, DummyVecEnv
from matplotlib import pyplot as plt
Framestake 检测马里奥和敌人的移动轨迹 ,Gray 将彩色的游戏灰化,方便处理,matplotlib用于可视化。
注意,请在下载stable之前,下载pytorch,选择能支持GPU加速的版本~
2)初始化、矢量化
environment = gym_super_mario_bros.make('SuperMarioBros-v0')
environment = JoypadSpace(environment, SIMPLE_MOVEMENT)
environment = GrayScaleObservation(environment, keep_dim=True)
environment = DummyVecEnv([lambda : environment])
environment = VecFrameStack(environment , 4, channels_order='last')
一开始的取样维度为240 * 256 * 3。240 * 256是长宽、3是三种原色的表。
第三行灰化图降维减少训练量。240 * 256 * 3–>240 * 256 * 1
第四行完成环境的向量化,如果要用多个环境,可以直接state[0],state[1]这样调用,在后续训练时,向量化的多个环境便会在同一个线程或者进程中被使用,从而提高采样和训练的效率。
第四行运行完成 变为 1 * 240 * 256 * 1
第五行堆叠了最后一维的数量(图片的数量),使得可以一次处理更多图片(此处是4张,其中一张是有初始化的,我们可以切片state[0][:,:,3]查看到之前的灰度图)。channels_order=last表示堆在最后一维。
第五行运行完变为 1 * 240 * 256 * 4.
3)矢量化的效果展示
state = environment.reset()
state, reward, done, info = environment.step([environment.action_space.sample()])
plt.figure(figsize=(10,8))
for idx in range(state.shape[3]):
plt.subplot(1,4,idx+1)
plt.imshow(state[0][:,:,idx])
plt.show()
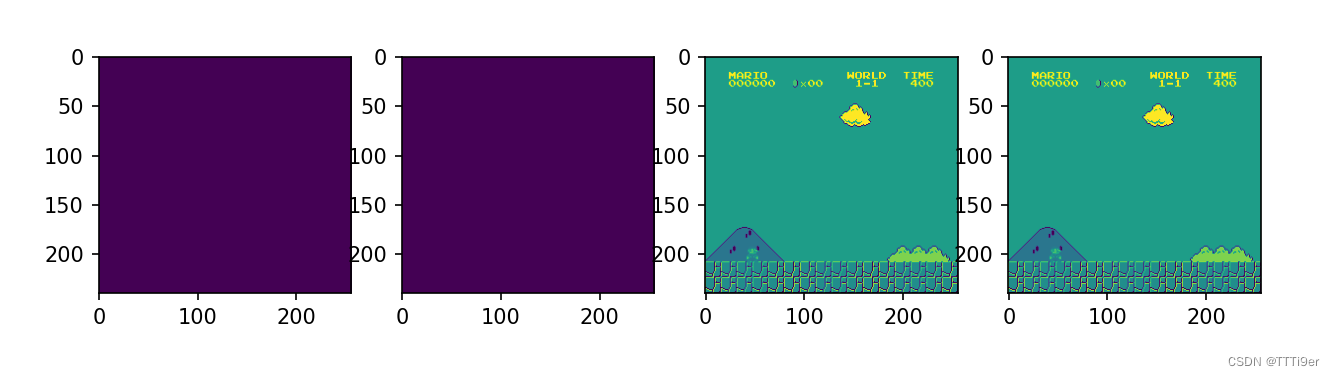
以上代码用plt可视化查看以下我们矢量化环境的state中保存的照片
(此段的完整代码附在后面)。
4)你可能遇到的问题
遇到需要shimmy问题:pip install shimmy
遇到ModuleNotFoundError: No module named ‘cv2’
执行pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple
本文最终代码如下:
import gym_super_mario_bros
from nes_py.wrappers import JoypadSpace
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
from gym.wrappers import FrameStack, GrayScaleObservation
from stable_baselines3.common.vec_env import VecFrameStack, DummyVecEnv
from matplotlib import pyplot as plt
environment = gym_super_mario_bros.make('SuperMarioBros-v0')
environment = JoypadSpace(environment, SIMPLE_MOVEMENT)
environment = GrayScaleObservation(environment, keep_dim=True)
environment = DummyVecEnv([lambda : environment])
environment = VecFrameStack(environment , 4, channels_order='last')
state = environment.reset()
state, reward, done, info = environment.step([environment.action_space.sample()])
plt.figure(figsize=(10,8))
for idx in range(state.shape[3]):
plt.subplot(1,4,idx+1)
plt.imshow(state[0][:,:,idx])
plt.show()















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









