







卷积神经网络(CNN)是一种在计算机视觉和图像处理中广泛应用的深度学习模型。然而,由于CNN的复杂性和参数量的增加,过拟合问题经常出现,导致模型在训练集上表现良好但在测试集上泛化能力较差。本文将介绍过拟合问题的原因,并提供一些常见的解决方法,以帮助提高CNN模型的泛化能力和减少过拟合现象。如何解决CNN模型中的过拟合问题?
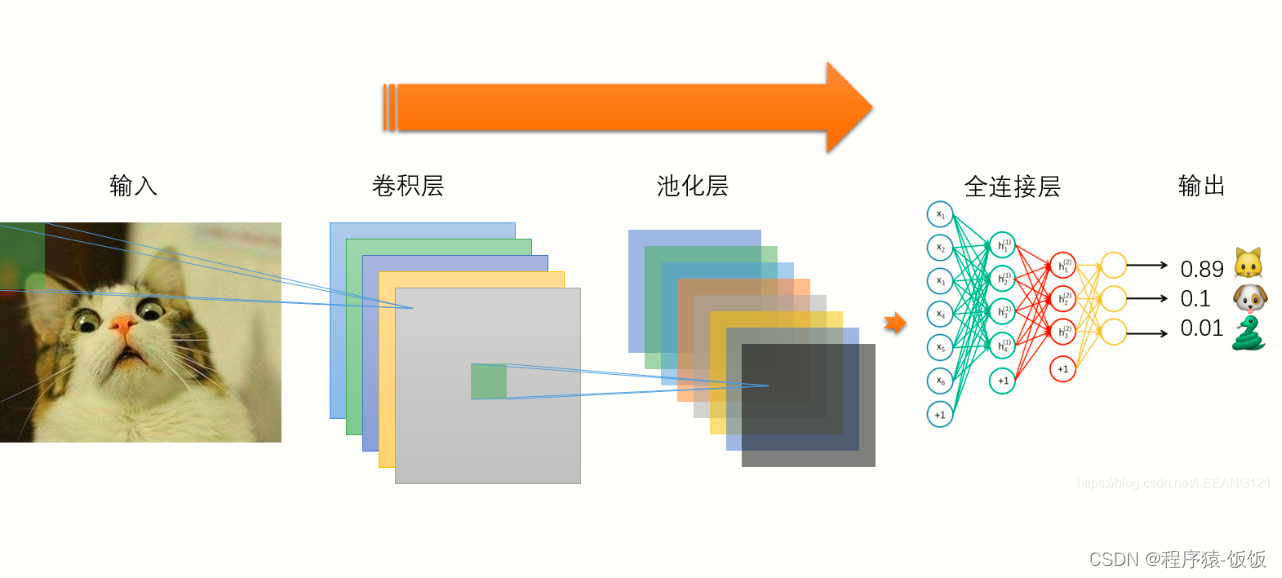
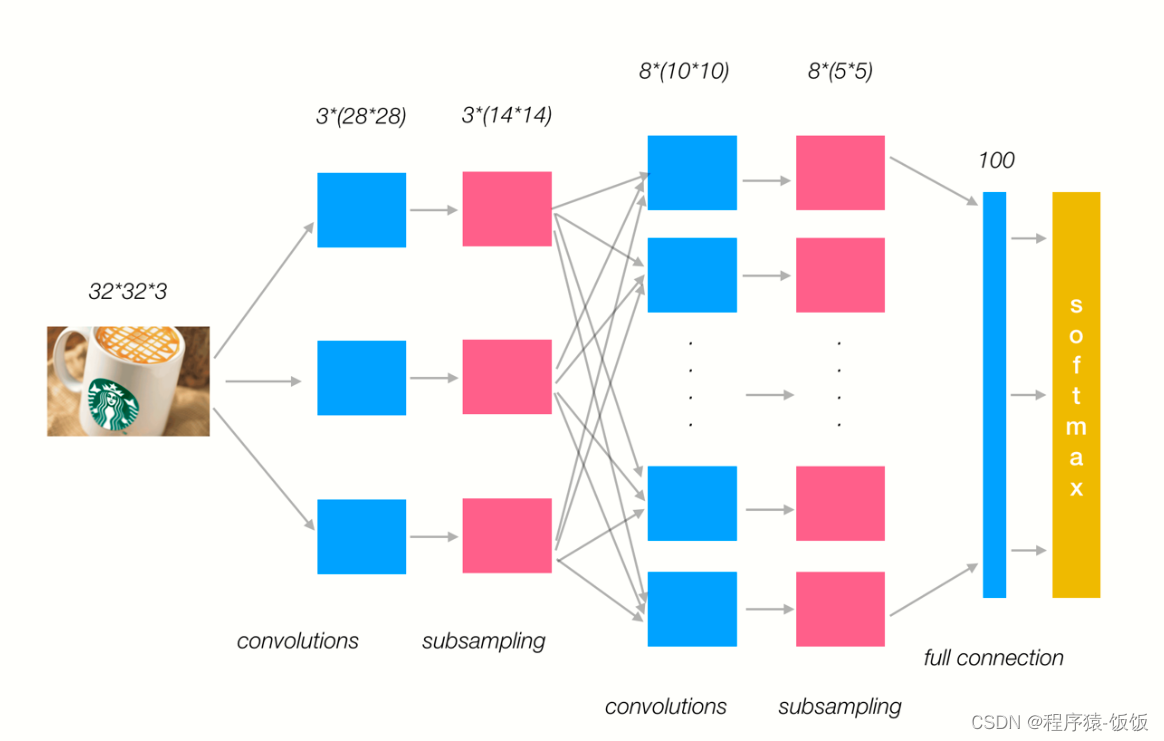
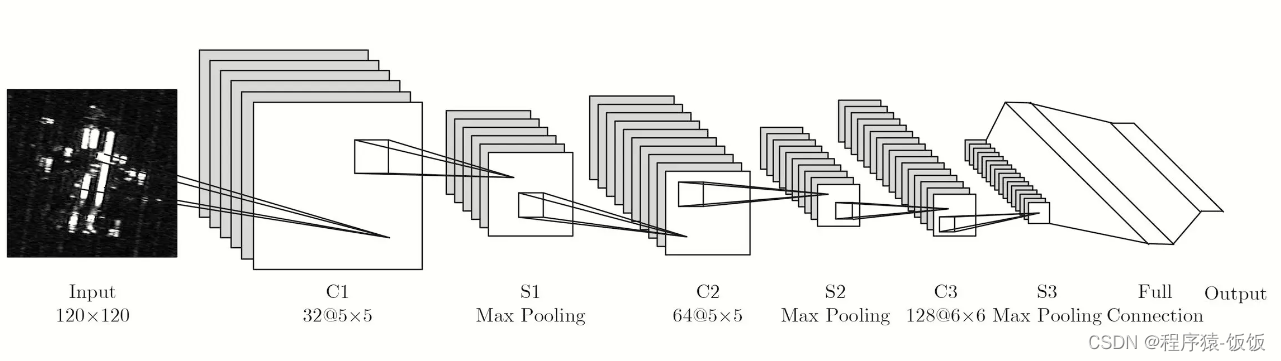
-
数据增强(Data Augmentation):
- 数据增强是通过对训练数据进行一系列的随机变换来扩充数据集,以增加样本的多样性。常见的数据增强方法包括图像平移、旋转、缩放、翻转等操作,可以有效减少过拟合问题。
-
正则化(Regularization):
- 正则化是通过对模型的复杂性进行约束来减少过拟合。常见的正则化方法包括L1正则化、L2正则化和Dropout。L1和L2正则化通过添加正则化项到损失函数中,惩罚模型中的大权重值,以减少模型的复杂性。Dropout通过在训练过程中随机关闭一部分神经元,强制模型学习更鲁棒的特征表示。
-
提前停止(Early Stopping):
- 提前停止是指在训练过程中根据验证集的性能来确定停止训练的时机。当验证集上的性能不再提升或开始下降时,停止训练以避免过拟合。
-
参数调整(Hyperparameter Tuning):
- 模型的超参数对模型性能有很大的影响。通过对超参数进行调整,可以优化模型的泛化能力。常见的超参数包括学习率、批量大小、网络层数等。
-
感谢大家对文章的喜欢,欢迎关注威
❤公众号【AI技术星球】回复(123)
白嫖配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
总结: 过拟合是CNN模型常见的问题之一,可以通过数据增强、正则化、提前停止和参数调整等方法来减少过拟合现象。在实际应用中,根据具体情况选择合适的方法或组合多种方法来解决过拟合问题,以提高CNN模型的泛化能力和性能。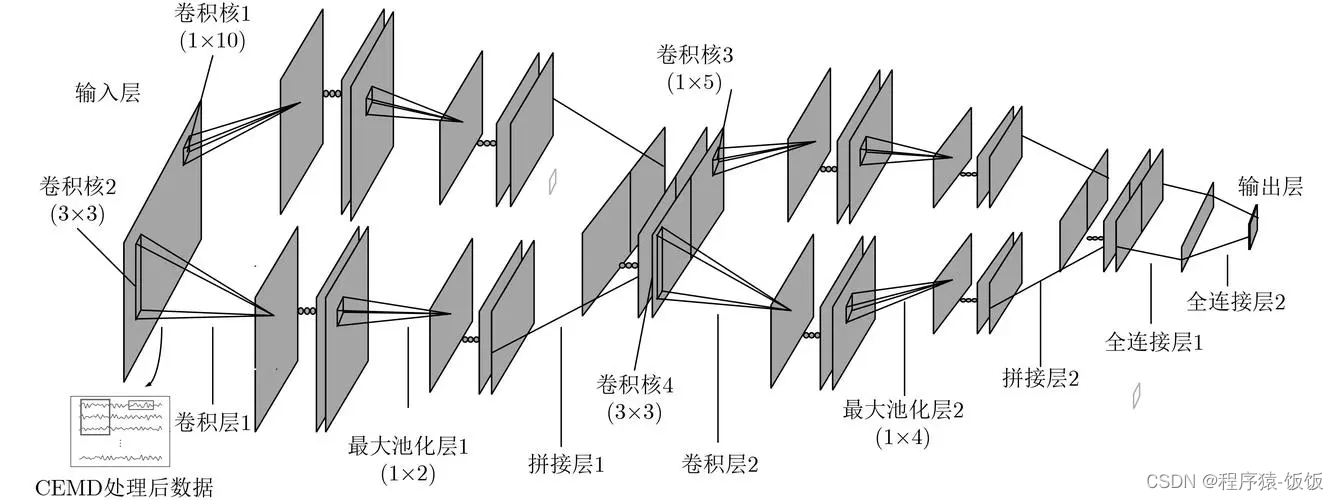















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









