






 本文介绍了如何使用KNN算法对鸢尾花进行分类,包括数据加载、数据展示、基本处理、特征处理以及模型训练与评估。同时,详细讲解了交叉验证和网格搜索在超参数优化中的应用,以提高KNN模型的性能,并展示了如何在手写数字识别中使用这些技术。
本文介绍了如何使用KNN算法对鸢尾花进行分类,包括数据加载、数据展示、基本处理、特征处理以及模型训练与评估。同时,详细讲解了交叉验证和网格搜索在超参数优化中的应用,以提高KNN模型的性能,并展示了如何在手写数字识别中使用这些技术。
一、利用KNN算法对鸢尾花分类
简单代码示例
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# from sklearn.metrics import accuracy_score
# todo 1.加载数据集
iris_data = load_iris()
# print(f'数据集-->\n{iris_data.feature_names}\n{iris_data.data[:10]}')
# print(f'\n目标值-->\n{iris_data.target_names}\n{iris_data.target}')
# todo 2.数据展示
def dm02_irisdata_show():
iris_df = pd.DataFrame(iris_data['data'], columns=iris_data.feature_names)
print(iris_df)
iris_df['target'] = iris_data.target
print(iris_df)
feature_names = list(iris_data.feature_names)
print(feature_names)
for i in range(len(feature_names)):
for j in range(i + 1, len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
sns.lmplot(x=col1, y=col2, hue='target', data=iris_df,fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f'{col1} vs {col2}')
plt.show()
# todo 3.数据基本处理
# 数据计划分
x_train,x_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,test_size=0.3,random_state=32)
# print(x_train)
# print(f'数据总数量-->{len(iris_data.data)}')
# print(f'训练集数量-->{len(x_train)}')
# print(f'测试集数量-->{len(x_test)}')
# todo 4.特征处理
# 数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# print(f'标准化后的x_train-->{x_train}')
# todo 5.实例化
model = KNeighborsClassifier(n_neighbors=5)
# todo 6.训练
model.fit(x_train,y_train)
# todo 7.评估
# y_pre = model.predict(x_test)
# score = accuracy_score(y_test,y_pre)
# print(f'score-->{score}')
# score2 = model.score(x_test,y_test)
# print(f'score2-->{score2}')
# todo 8.预测
mydata = [[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata = transfer.fit_transform(mydata)
predata = model.predict(mydata)
print(f'predata-->{predata}')预测结果
![]()
二、超参数的选择方法
1.交叉验证:是一种数据集的分割方法,将训练集划分为 n 份,拿一份做验证集(测试集)、其他n-1份做训练集
• 交叉验证法原理:将数据集划分为 cv=4 份
1. 第一次:把第一份数据做验证集,其他数据做训练
2. 第二次:把第二份数据做验证集,其他数据做训练
3. ... 以此类推,总共训练4次,评估4次。
4. 使用训练集+验证集多次评估模型,取平均值做交叉验证为模型得分
5. 若k=5模型得分最好,再使用全部训练集(训练集+验证集) 对k=5模型再训练一边,再使用测试集对k=5模型做评估
2.网格搜索
为什么需要网格搜索?
• 模型有很多超参数,其能力也存在很大的差异。需要手动产生很多超参数组合,来训练模型
• 每组超参数都采用交叉验证评估,最后选出最优参数组合建立模型
• 网格搜索是模型调参的有力工具。寻找最优超参数的工具!
只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。
网格搜索 + 交叉验证的强力组合 (模型选择和调优)
• 交叉验证解决模型的数据输入问题(数据集划分)得到更可靠的模型
• 网格搜索解决超参数的组合
• 两个组合再一起形成一个模型参数调优的解决
三、利用KNN算法对鸢尾花分类 – 交叉验证网格搜索
简单代码示例
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
def dm01_鸢尾花knn分类_交叉验证网格搜索():
# 1 获取数据集
mydataset = load_iris()
# 2 数据基本处理-划分数据集
x_train, x_test, y_train ,y_test = train_test_split(mydataset.data, mydataset.target,
test_size=0.2,random_state=22)
# 3 数据集预处理-数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 机器学习(模型训练)
estimator = KNeighborsClassifier()
print('estimator-->', estimator)
# 4-2 使用校验验证网格搜索
param_grid = {'n_neighbors':[1,3,5,7]}
# 输入一个estimator, 出来一个estimator(功能变的强大)
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=5)
estimator.fit(x_train, y_train) # 4个模型 每个模型进行网格搜素找到做好的模型
# 4-3 交叉验证网格搜索结果查看
# estimator.best_score_ .best_estimator_ .best_params_ .cv_results_
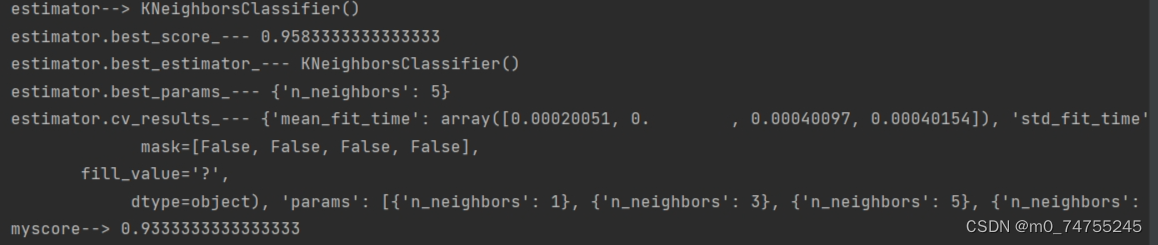
print('estimator.best_score_---', estimator.best_score_)
print('estimator.best_estimator_---', estimator.best_estimator_)
print('estimator.best_params_---', estimator.best_params_)
print('estimator.cv_results_---', estimator.cv_results_)
# 4-4 保存交叉验证结果
myret = pd.DataFrame(estimator.cv_results_)
myret.to_csv(path_or_buf='./mygridsearchcv.csv')
# 5 模型评估
myscore = estimator.score(x_test, y_test)
print('myscore-->', myscore)
dm01_鸢尾花knn分类_交叉验证网格搜索()运行结果
四、利用KNN算法实现手写数字识别
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import joblib
from collections import Counter
def show_digit(idx):
# 1 加载数据
data = pd.read_csv(r" ")#添加自己的数据集路径
if idx < 0 or idx > len(data) - 1:
return
# 2 打印数据基本信息
x = data.iloc[:, 1:]
y = data.iloc[:, 0]
print('数据基本信息:', x.shape)
print('类别数据比例:', Counter(y))
print('当前数字的标签为:',y[idx])
# 3 显示指定的图片 # data修改为ndarray 类型
data_ = x.iloc[idx].values
# 将数据形状修改为 28*28
data_ = data_.reshape(28, 28)
# 关闭坐标轴标签
plt.axis('off')
# 显示图像
plt.imshow(data_,cmap='gray')
plt.show()
def train_model():
# 1 加载手写数字数据集
data = pd.read_csv(r" ")#添加自己的数据集路径
# 2 数据预处理 归一化
x = data.iloc[:, 1:] / 255
y = data.iloc[:, 0]
# 3 分割数据集
split_data = train_test_split(x, y, test_size=0.2, stratify=y, random_state=0)
x_train, x_test, y_train, y_test = split_data
# 4 模型训练
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5 模型评估
acc = estimator.score(x_test, y_test)
print('测试集准确率: %.2f' % acc)
# 6 模型保存
joblib.dump(estimator, r' ')#保存模型的路经
def test_model():
# 1 读取图片数据
img = plt.imread(r" ")#测试图片的路径
plt.imshow(img)
# 2 加载模型
knn = joblib.load(r' ')#保存模型的路经
# 3 预测图片
y_pred = knn.predict(img.reshape(1, -1))
print('您绘制的数字是:', y_pred)
show_digit(2)
train_model()
test_model()














 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









