







嵌入式计算与现代电子系统
1.1.1 嵌入式计算基础知识
1.1.2 嵌入式计算体系结构
1.1.3 现代电子系统发展可编程片上系统概述
1.2.1 微控制器(MCU)基础
1.2.2 可编程片上系统概述
1.2.3 PSoC Creator IDE和外设
1.1.1 嵌入式计算 基础知识
基本概念: ****
定义:嵌入式系统是完全内嵌于受控装置,针对特定应用的专用计算系统;与个人计算机(PC)等数据处理单元不同,嵌入式系统通常执行特定要求的预定义任务。
系统构成:
以微控制器(MCU)等数据处理单元为核心,感测外部环境,并干预外部环境

应用:
1.以算力(CP)实现感知(Perception)和认知(Cognition): 当前热门的智能硬件的重要组成部分;
- 物联网(IoT)发展的技术驱动力:嵌入式计算(EC);无线链接(WC);换能器(Transducer): 传感器(Sensor)和执行器
(Actuator)
- 应用场景:消费电子(CE);物联网(IoT); 工业控制; 汽车电子,应用案例:
** WC1750深井相机:** 美国ARIES工业公司:细杆双目(端面和侧壁)相机:实现矿井或水井的内部检测- 使用可编程片上系统(PSoC)†为信息处理核心;矿井或水井的内部诊断检查系统;
大直径1.75inch(44.45mm),长度22inch(558.8mm),重量6lbs(2.724Kg)- 不锈钢防水外壳,密封填充15PSI氮
气; 高工作温度180华氏度(82.22摄氏度),彩色480电视线水平分辨率;行间转移(ILT)CCD:1/4inch,
768(H)*494(V)- 镜头焦距fM2.3mm, 大视场FoV=86°, 低光照1lux@F1.2
1.1.2 嵌入式计算 体系结构
1.1.2.1嵌入式处理器概述: ****
体系结构:哈佛结构 (Harvard Architecture)冯诺曼结构 (Von Neuamnn Architecture) 指令集架构(ISA):
基本指令集架构:
精简指令集计算(RISC) 复杂指令集计算(CISC) 商业指令集架构:
- 先进RISC机器(ARM);arm
- 86/88兼容处理器(x86):Intel;AMD ★ Xtensa处理器:Tensilica (Cadence) 开源指令集架构:
- RISC-V;第5代精简指令集计算机;RISC-V基金会;源于斯坦福大学;
- MIPS:无内部互锁流水级的微处理器;MIPS公司;源于斯坦福大学 功能(Function):
微处理器单元(MPU);微控制器单元(MCU); 图形处理单元(GPU);视觉处理单元(VPU); 数字信号:
数字信号处理器(DSP); 数字信号控制器(DSC):可编程器件:
现场可编程门列阵(FPGA); 复杂可编程逻辑器件(CPLD); 专用器件:
专用标准产品(ASSP); 专用集成电路(ASIC); 片上集成:
片上系统(SoC);可编程片上系统(PSoC)
1.1.2.2ARM处理器概述: ****
硅知识产权(Si-IP)
提供ip: 安谋(arm)科技提供处理器以及其他知识产权(IP) 提供设计: 微控制器(MCU)供应商(IDM/Fabless)设计;
生产:由半导体厂商(IDM)或代工厂(Foundry)制造
ARM处理器的生态系统(Ecosystem) :
由行业领先的嵌入式生态系统支持; 以更少时间,更低成本提供更多特性,连通性,代码复用,标准安全性, 高能效。
ARM处理器的演化:
处理器位数:
32位:ARMv6;ARMv7; 64位:ARMv8;ARMv9; 现代ARM处理器:ARMv7;ARMv8;ARMv9;
□ Cortex-X:应用处理器(超大核);
□ Cortex-A:应用处理器;面向性能密集型系统的应用处理器核
□ Cortex-R:实时处理器;面向实时应用的处理器核
□ Cortex-M:微控制器;面向各类嵌入式应用的处理器核
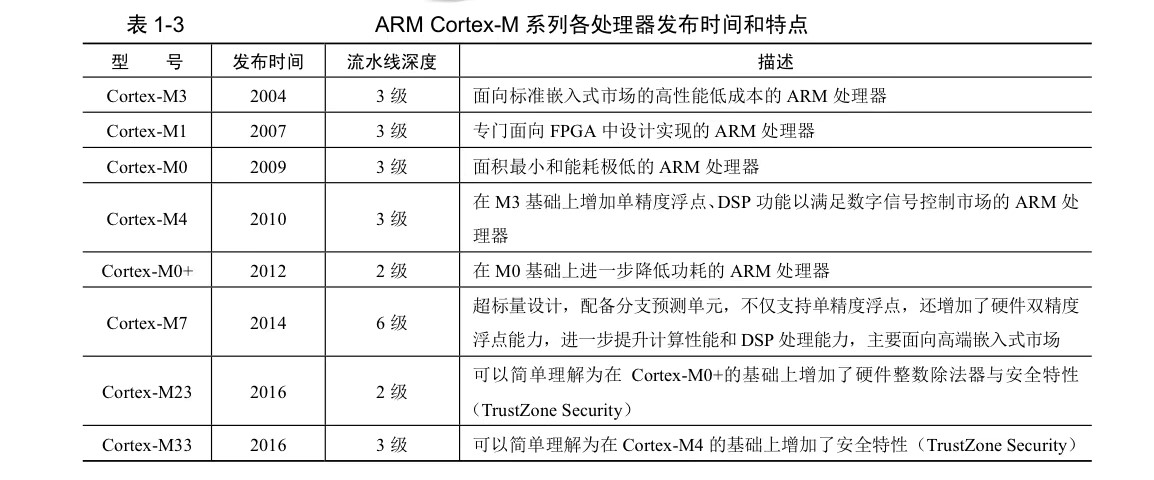
1.1.2.3 ARM Cortex-M内核 : ****
分类:
32位:
ARMv6-M:Cortex-M1/M0/0+;
ARMv7-M:Cortex-M3/M4/M7
64位:
ARMv8-M:Cortex-M23/M33/M35P/M55/M85
特征:
针对确定性实时嵌入式处理和微控制器(MCU)应用优化; 可裁剪,高能效和易使用的处理器,满足智能产品的需求。
Cortex-M3处理器 :
硅芯(Die)面积,性能和功耗 优,系统接口丰富,集成调试与跟踪元件; 广泛应用验证的全特征ARMv7-M指令集。 专门设计的高性能低成本开发平台;用于可穿戴系统,物联网,智能家居/工业现场等。
应用处理级操作系统 :
| 微软(Microsoft): Windows IoT:物联网; Windows LTSC(长期服务 频道):金融,医疗或工控 等用途 |
Linux基金会:GNU Linux;发行版:Debian (Ubuntu);Fedora (Redhat);SUSE (SLES); 嵌入式版本: DietPi;RaspberryPi OS |
谷歌(Google); | /手环: : |
||
|---|---|---|---|---|---|
| AOSP/GMS; | 安卓手表 | ||||
| 手机/平板: (Android); wearOS;电视:Android TV |
|||||
| 苹果(Apple):手机:iOS;- 12 平板:iPadOS;手表:watchOS: | 华为(Huawei):AOSP/HMS;终端/电视:鸿蒙(HarmonyOS);物联网版鸿蒙LiteOS | 浏览器操作系统 教育电脑/平板:Chrome OS |
工业与物联网级操作系统:
实时系统:
★VxWorks:英特尔(Intel/Wind River);★ QNX:QNX软件系统有限公司(QSSL);★ RTX:安谋(arm/Keil);★
Azure IOT:微软物联网(IOT)系统:
- mbed OS:安谋(arm)科技;
- RT-Thread:睿赛德电子:国产优秀开源系统
1.1.3 现代电子系统发展
嵌入式系统平台技术
平台架构:
由硬件和软件集成,更好更快构建复杂功能系统。
硬件平台:[通信接口] + [数据处理单元] + [输入输出(I/O)] 可重配置处理架构:
更多采用复杂可编程逻辑(CPL)实现 :□ 更快更可靠的输入输出(I/O)响应;□ 故障预测和提高安全性的机器监测;□ 输入输出(IO)预处理降低数据传输量□ 音频和图像处理;无线和网络通信;□ 与智能传感器和其它系统间的数字通信;□ 模拟/数字信号滤波提供更准确结果
移动计算(Mobile Computing)
- 利用 新设备(器件)和云计算实现现代嵌入式系统:□ 智能手机(SP)从消费电子产品演变为功能完善易用的移动电脑。△ 移动应用软件(app)组成的工程生态系统更多扩展并提高SP的通用功能。
云计算(Cloud Computing)
- 数据聚合:各子系统相距甚远,需考虑云存储。
- 获取数据:某些情况下,设计中系统难以直接获取数据。
- 降低运算量:云计算提供接近无限资源,单终端从庞大运算中解放出来 系统安全(System Security)与跨系统支持(MultiOS Support)
- 嵌入式系统远程控制必会引入额外风险。 □ 严重的是系统安全: △ 系统安全与时间和成本成正比,损失一定的简便性
- 不断涌现的新技术对跨(多)平台支持成为合理选择。 □ 每个跨平台应用中,都会有常见的缺点, △ 也会有需要折衷(tradeoff)考虑的方面。
嵌入式系统平台形态
| 嵌入所有电路,以通用标准设备提供 | ||
|---|---|---|
| 平台形态 | 模块计算机(COM) | 特殊SOM,整个嵌入式系统集成到独立装置中 |
| 单板计算机(SBC) | 同一电路板整合所有(微处理器、存储装置和内存等)组件的计算机 |
树莓派(RPi)单板机(SBC):
主流系列:使用博通arm应用处理器(AP)
RPi [n] B型:RPi 1B,1B+,2B,3B,3B+,4B,5B;尺寸85mmB56mm;
RPi [n] A型:RPi 1A,1A+,2B,3A+; 尺寸67mmB56mm;
计算模块(CM)[n]:CM1和CM3:尺寸67.6B31mm; CM4:尺寸55B40mm 个人计算机套件(PCK):集成树莓派4B+到键盘中
RPi Zero系列:Zero,Zero W;Zero 2,Zero 2W;尺寸65mmB30mm
RPi Pico
BeagleBone单板机(SBC):使用德州仪器(TI)AM系列应用处理器(AP) :
主流系列: □ BB标准板: △ 阻焊层颜色区分,黑,蓝,绿,尺寸86B53mm; □ Pocketbegale: △ 尺寸
55B35mm;GPIO插座数量也少
其他系列: □ BB AI板: △ Beaglebone AI;尺寸86B53mm; △ Beaglebone AI-64;尺寸102B79mm □ 其他: Beagle RV:BeagleV Fire;BeagleV Ahead;Beagle Play:Beagle Connect
Arduino和Energia平台 :
- Arduino:微机器学习(TinyML)的部署平台
□ 硬件:AVR MCU,拓展Cortex-M3/4,ESP32等众多高性能MCU
□ 集成开发环境(IDE):Processing;编程语言:Wire,类Java和C;
□ Arduino Pro IDE:
更多的高级开发特征;Arduino CLI:命令行
- Energia:Arduino的克隆(CCS的入门开发替代)
□ 硬件:TI MSP430 Lauchpad □ 集成开发环境(IDE):Processing;编程语言:Wire,类Java和C
边缘计算与人工智能
云计算,雾计算和边缘计算 :
云计算:数据中心,数以千计; ★ 雾计算:数据节点,数以百万计 ★ 边缘计算:(数据)装置,数以十亿计 处理器:
英特尔(Intel)视觉处理器(VPU): ★ Myriad-X;算力4TOPS 谷歌边缘张量处理器(Edge TPU): Coral Edge TPU:算力4TOPS 英伟达(Nvidia) Jetson Nano 微机器学习(TinyML)
1.(嵌入式机器学习的应用,算法,硬件和软件的交叉领域) :
探索和优化机器学习算法,使其可在小型低功耗器件如微控制器上运行。 使能边缘器件低延迟,低功耗和低带宽模型推理
- 通用图形处理单元(GPU)训练神经网络消耗(65T85)W的功耗:如ARM Cortex-M3和Cortex-M4的微控制器仅消耗低千倍的功耗
- 优点:低延迟;低功耗;低带宽;低成本
Tensorflow Lite for Microcontroller(TFLM)开放框架
谷歌(Google)主导的设备(Device)端推断的开源深度学习(DL)框架 应用领域和技术
工业预测维护:健康保护;民用基础设施,物流和智能家居计算机视觉:语音-声音;振动-传感器融合
1.2.1 微控制器(MCU)基础
定义 : 1.内置多种外设(Peripheral)的微处理器(MPU)
用来实现响应输入输出(I/O)引脚,定时器,通信等的输入;对信息操作和控制,输出合适信号
2.集成多种电子开关的器件
二进制(Binary)运行,简化复杂操作为逻辑运算和算术运算;确定使用某种电子开关
** 核心部件 : 中央处理器(CPU);微处理器(MPU) ; 高速缓存(Cache); 随机访问存储器(RAM); □非易失存储器(NVM):快闪(Flash)等 中央处理器(CPU) **常见架构: 哈佛(Harvard)架构;冯诺曼(Von Neumann)架构;
作用: 微控制器(MCU)的核心,与其它部件连接实现: ★ 与存储器交换信息;逻辑指令; ★ 基本操作(加/减,或/ 与/异或,移位/移动/复制); ★ 复杂操作(基本操作组合)
组成: 由多个子系统构成 :如 程序计数器(PC);指令译码器(CD);算术逻辑单元(ALU) 存储器(Memory)
| 高速缓存(Cache) | 从位置和访问速度,Cache最接近CPU; 在同一硅芯(Die)或封装 (Package)集成Cache和CPU |
|
|---|---|---|
| 存储器 | 随机访问存储器 (RAM |
从CPU访问速度讲,访问随机访问存储器(RAM)比高速缓存(Cache)要慢 |
| 非易失性存储器 (NVM) |
保存程序,非易失性存储介质构成; □ 只读存储器(ROM):快闪(Flash) |
类型 :半导体存储;光存; 磁存储;
| 机器语言 (Machine Language) |
表现为二进制码; 运行效率最高; | |
|---|---|---|
| 指令构成 操作符,操作数 |
操作码:告诉CPU需要执行的操作; 操作数:执行操作针对的对象(立即数,寄存器和存储器等); 通过访问操作数获得需要操作的对象。 | |
| 汇编语言 | 汇编语言 (Assembly Language) |
使用助记符(Mnemonic Symbol)帮助程序员理解和设计指令控制CPU。助记符指令由汇编器翻译成机器语言指令。助记符描述CPU操作,比机器语言更易理解和记忆,其基础是机器语言,执行效率基本与机器语言一样, 但编程效率很低。 |
| 指令格式 | [标号:] 助记符 [操作数][;注释] | |
| 高级语言(High- Level Language): |
C/C++和(Micro/Circuit) Python等高级语言对嵌入式硬件编程; □ 无法直接运行,由编译器或解释器翻译或解释成机器语言运行。 | |
| 高级语言代码运行效率不可能比汇编语言高,使高级语言和汇编语言执行效率一样高,需优化高级语言代码,混合编程,满足代码长度和运行时间的要求 |
1.2.2 可编程片上系统(psoc)概述
** 概述:**
是英飞凌(原赛普拉斯)提供的可编程单片微控制器(MCU)方案
- 高性能可编程模拟模块; ★ 可编程数字模块:可编程逻辑器件(PLD) ★ 可编程互联和布线; ★ 电容触摸感应
(CapSense) 特性
- 快速原型:
□ 使用PSoC Creator软件能够在数分钟而不是数小时创建定制芯片。
△ 在芯片上创建需要的外设组合,选择期望引脚(Pin),即可实现。
- 无蓝线:
□ 使用PSoC组件重新配置PSoC可编程硬件模块,
△ 适应 终功能变化,消除硬件错误和印刷电路板(PCB)生产延迟
- 传感器接口:
□ 使用PSoC组件和可编程模拟模块设计自定义模拟前端(AFE)
△ 产品增加新功能不增加印刷电路板(PCB)尺寸和物料单(BOM)成本。
分类:
8位内核: PSoC3 (8051);PSoC1 (M8C)
32位内核:PSoC4 (CM0/CM0+);PSoC5LP (CM3);PSoC6 (CM0+|CM4)
64位内核:PSoC Edge (CM55|CM33)
| PSoC4系 列 |
解决嵌入式设计的复杂问题,更容易将产品推向市场;集成并优化模拟传感器集成,电容式触摸和无线链接等功能 | 32位处理器内核:Cortex-M0/M0+低能耗蓝牙(BLE)产品:PSoC4BLE;模拟协处理器: PSoC Analog Coprocessor |
|---|---|---|
| PSoC6系 列 |
弥补昂贵耗电的应用处理器(AP)与低性能微 控制器(MCU)的差距;超低功耗(ULP)架构 提供物联网设备的处理性能,对功耗和性能折中 |
双核处理器架构,同一芯片两个内核;高性能 (HP):Cortex-M4低功耗(LP):Cortex-M0+ 内置安全功能,保护物联网系统 |
| PSoC4系 列 |
解决嵌入式设计的复杂问题,更容易将产品推向市场;集成并优化模拟传感器集成,电容式触摸和无线链接等功能 | 32位处理器内核:Cortex-M0/M0+低能耗蓝牙(BLE)产品:PSoC4BLE;模拟协处理器: PSoC Analog Coprocessor |
| PSoC5LP 系列 |
见文章 后 |
架构:
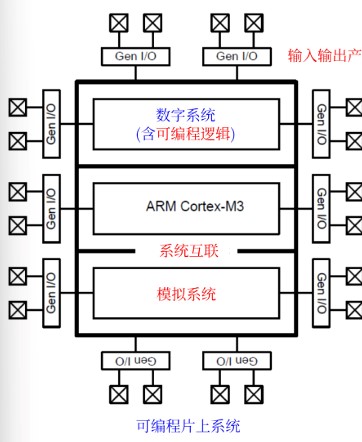
可配置的模拟和数字模块:
集成可配置的模拟和数字电路是PSoC平台的基础: 使用预设库函数或自创建函数配置这些模块。数字模块,创建
16,24,甚至32位逻辑资源;模拟模块实现复杂模拟信号流:
开关电容运算放大器,模拟比较器,模数转换器(ADC),数模转换器(DAC)和数字滤波器区块(DFB)的聚集
可编程的布线与互联:
自由重布线至用户选择管脚,没有固定功能外设(FFP)控制器的限制
全局总线允许信号复用和逻辑运算,消除复杂的数字逻辑门设计的需求。
CPU子系统: 集成多类存储器:SRAM,电可擦除编程只读存储器(EEPROM) 快闪存储器(Flash)
系统资源: 内部主振荡器(IMO)和低速振荡器(ILO);可编程时钟同步的外部晶体振荡器(ECO); 睡眠(Sleep)和看门狗(Watchdog)定时器;多种时钟源的集成锁相环(PLL) 通信接口:
- 串行通信: 集成电路间总线(I2C),全速通用串行总线(USB),控制器现场网络(CAN);
- 调试与跟踪接口:片上调试;联合测试行动组(JTAG)接口;串线调试(SWD) 注:JTAGH和SWD的对比可能会考。
后:
数据手册:PSoC5LP系列
概述:
32位Cortex-M3处理器(CPU)
□ 直接存储访问控制器(DMAC):外设到外设
□ 数字滤波器模块(DFB):硬件协处理器;
□ 数字结构;复杂可编程逻辑器件(CPLD)
□ 可编程模拟模块; 强劲的并行处理
□ 24位硬件协处理器:数字滤波器模块(DFB);
△ 处理传感器信号
□ 24个通用数字模块(UDB):基于复杂可编程逻辑器件(CPLD)
△ 分担传统CPU任务
□ 24通道DMAC提高系统性能集成的高精度模拟信号
□ 集成定制20位模拟前端(AFE)与可编程模拟模块在一起。
□ 利用电容触摸(CapSense)实现复杂的用户接口(UI)传感方案
特征
32位Cortex-M3处理器(CPU): 高80MHz时钟
□ 24通道直接存储访问控制器(DMAC);
□ 闪存(FLASH)(G256KB),静态随机访问存储器(SRAM)(64KB)
★ 24位64抽头(Tap)数字滤波器区块(DFB);专有外设接口:
□ 液晶显示(LCD)段码(Segment)驱动;
□ 电容感应(CapSens):自动调谐(Autotuning);电容增量累加(CSD)控制器; 多62个I/O 可编程模拟模块
□ 1个(8T20)位增量累加模数转换器(ADC);
□ 2个12位逐次逼近(SAR)模数转换器(ADC)
□ 4个8位数模转换器(DAC);
□ 1.024V±0.1%电压参考源;
□ 4个模拟比较器;
□ 4个运算放大器;
□ 4个可编程开关电容连续时间(SC/CT)模拟模块 可编程数字模块
□ 4个定时计数脉宽调制(TCPWM)模块;
□ 24个通用数字区块(UDB);
□ 数字串行通信(SCB):
△ 集成电路间总线(I2C)
△ 串行外设接口(SPI)
△ 通用异步收发器(UART)
△ 现场控制器网络(CAN);
★ 供电电压:范围:(1.2T5.5)V 合计4个供电轨
处理器 ****
ARM指令系统 ****
ARM指令集
ARM指令集的演化
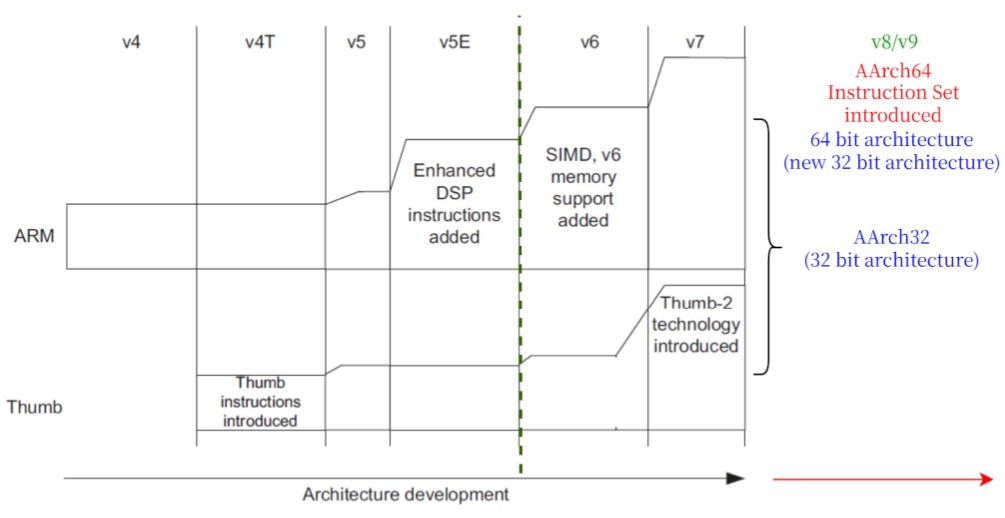
Thumb指令集与arm指令集
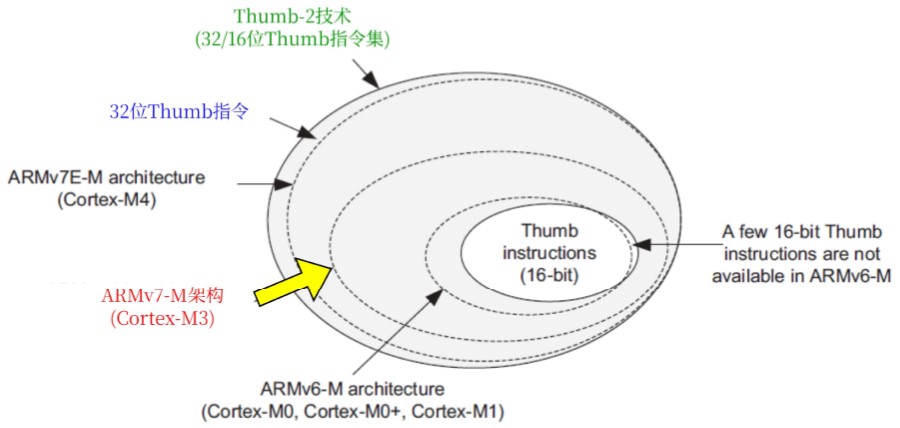
Cortex-M3使用ARMv7-M架构,它是Thumb-2指令集的子集,Thumb指令集的超集。
指令系统
指令系统反映处理器(CPU)的结构。可由指令系统确定处理器(CPU)内核结构。
指令构成:操作码和操作数;
操作码的 终操作对象是操作数;
操作数可在处理器(CPU)内部寄存器,或片内(外)存储器;也可是常数。
指令寻址模式
处理器(CPU)按预定规则寻找操作对象。操作对象:与寻址模式相关。立即数;直接位地址;程序地址;直接数地址;间接地址;特殊汇编器符号。
寻址:处理器(CPU)寻找操作对象位置的过程;寻址模式即寻址方法。
Cortex-M3指令系统
Cortex-M3寻址模式 **** 立即寻址;相对寻址;寄存器寻址;寄存器移位寻址;寄存器间接寻址;多寄存器寻址;基址寻址;堆栈寻址;块复制寻址。
通用微控制器软件接口标准(CMSIS)
CMSIS是应用程序接口(API),软件组件,工具,以及工作流程的集合。优点:
简化软件重用:降低开发者学习曲线;加速项目构建和调试;缩短新产品上市时间。它起初作为Cortex-M处理器的硬件抽
象层,后拓展支持入门级
Cortex-A
处理器。
简化访问,定义通用工具接口,为处理器和外设提供简单软件接口使能一致的器件支持。通过广泛的开发工具和微控制器
使能一致的软件层和器件支持。
不是巨大的软件层,不引入额外开销,也不定义标准外设。
有助于行业标准化,半导体行业以此通用标准支持
Cortex
处理器的各种变型。
组件:
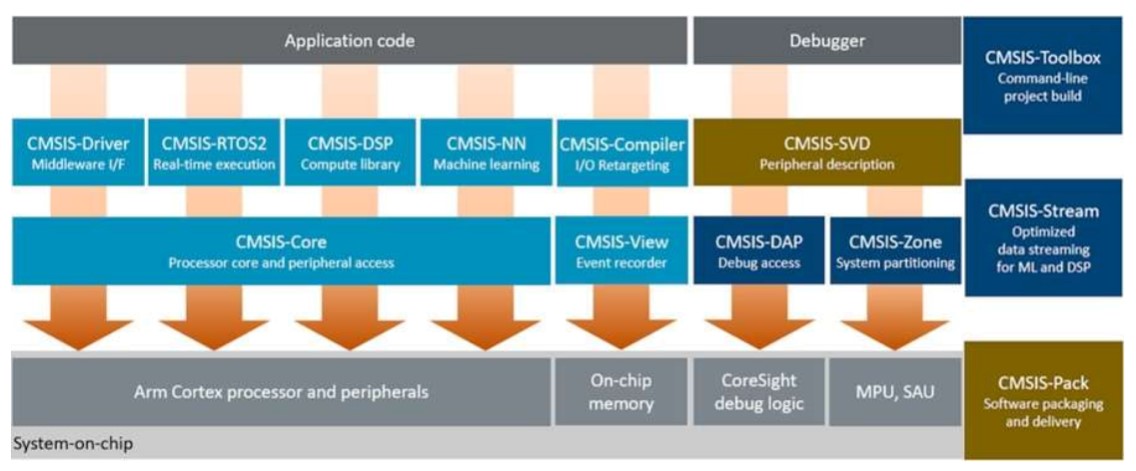
基础软件组件:为设备的基本功能提供软件抽象
CMSIS-Core (内核);处理器内核与外设访问CMSIS-Driver (驱动程序)
;中间件接口CMSIS-RTOS2 (实时操作系统):实时执行扩展软件组件:实现针对在arm处理器执行而优化的特定功能。
CMSIS-DSP (数字信号处理);计算库
CMSIS-NN (神经网络);机器学习
CMSIS-View (视图);事件记录器
CMSIS-Compiler (编译器):输入输出重定向工具:使用CMSIS的组件为软件开发工作流程提供有用实用程序。
CMSIS-Toolbox (工具箱);命令行项目构建
CMSIS-Stream (数据流);为机器学习和数字信号处理优化的数据流
CMSIS-DAP (调试访问端口);调试访问
CMSIS-Zone (区域):系统分区规格:定义嵌入式软件开发的方法和工作流程。
CMSIS-Pack (软件包);软件打包与交付
CMSIS-SVD (系统视图描述):外设描述
Cortex-M3指令
存储器访问指令:ADR指令;LDR和STR立即偏移指令;LDR和STR寄存器偏移指令;LDR和STR非特权指令;LDR和PC相对指令;LDM和STM指令;PUSH和POP指令;LDREX和STREX指令;CLREX指令。
通用数据处理指令:ADD,ADC,SUB,SBC和RSB指令;AND,ORR,EOR,BIC和ORN指令;ASR,LSL,LSR,ROR和 RRX指令;CLZ指令;CMP和CMN指令;MOV和MVN指令;MOVT指令;REV,REV16,REVSH和RBIT指令;TST和TEQ指令。乘除法指令:MUL,MLA和MLS指令;UMULL,UMLAL,SMULL和SMLAL指令;SDIV和UDIV指令。
位(Bit)操作指令:BFC和BFI指令;SBFX和UBFX指令;SXT和UXT指令。
分支与控制指令:B,BL,BX和BLX指令;CBZ和CBNZ指令;IT指令,TBB和TBH指令
其它指令:BKPT指令和CPS指令;DMB指令和DSB指令;ISB指令和MRS指令;MSR指令和NOP指令;SEV指令和SVC指令;WFE指令和WFI指令
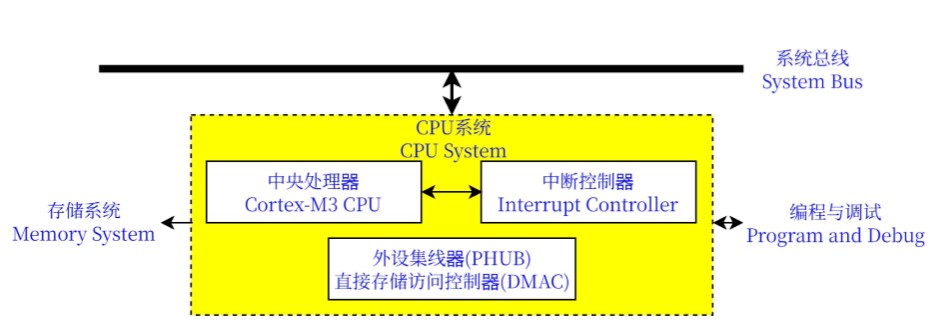
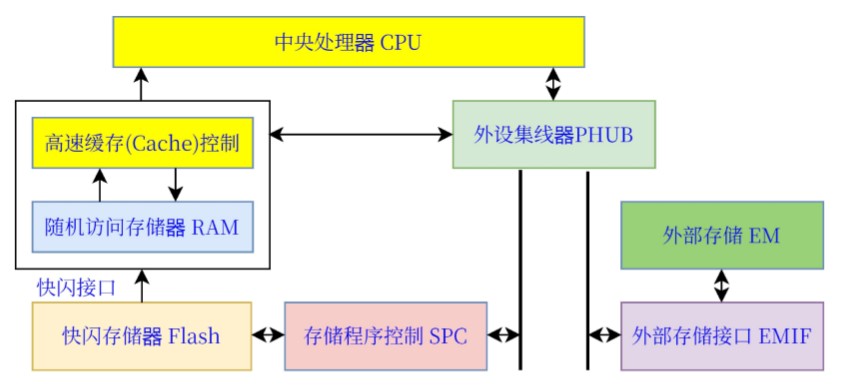
处理器内核和高速缓存控制器 ****
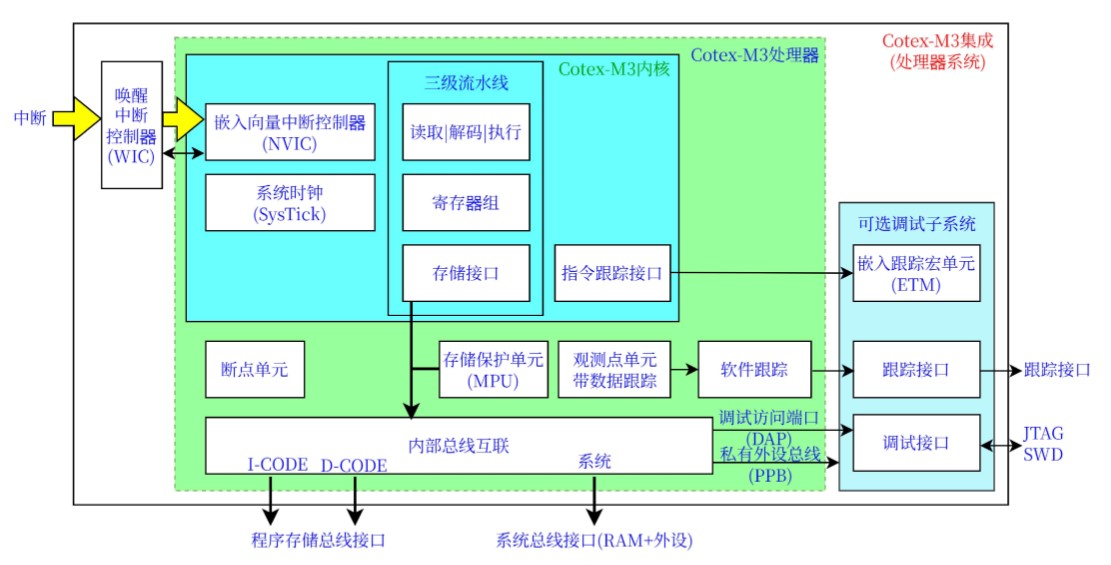
架构:
Cortex-M3
内核:低功耗32位三级流水线哈佛架构;整数计算性能:1.25DMIPS/MHz
。内核:Cortex-M3内核:嵌套向量中断控制器(NVIC)(可编程);调试与跟踪模块高速缓存(Cache)控制器。存储器:闪存(Flash)存储器:多256KB
;电可擦除可编程只读存储器(EEPROM):2KB;静态随机存储访问存储器(SRAM):64KB外设集线器(PHUB)和直接存储访问控制(DMAC)外部存储接口(EMIF)
特性
支持:
4GB地址:32位处理器代码,数据和外设的预定义地址;同时访问指令,数据和外设的多条总线
不支持
Thumb-2指令集:以Thumb代码密度实现ARM性能(16/32位指令) 高级指令:位域控制;硬件乘法和除法;饱和;if-then;事件和中断等待;独占访问和阻塞等
静态随机访问存储器(SRAM)地址的ARM指令。 SRAM区的位(Bit)段:原子位(Atom Bit)读写操作;
非对齐的数据存储和访问:不同字节长度数据的连续存储。
特权级(Privilege Level):特权(Priviledged);用户(User) 运行模式(Operation Mode):线程(Thread);句柄(Handle) 堆栈指针:主堆栈指针(MSP);进程堆栈指针(PSP)。
支持扩展:中断(Interrupt);异常(Exception)。
在特权级或用户级运行,也可在线程或句柄程序模式运行;句柄模式仅在特权级使用。
用户级禁用特定指令,特殊寄存器,配置寄存器和调试组件,尝试访问会导致故障;特权级允许访问所有指令和寄存器。
处理异常时,处理器以句柄模式运行(特权级);而不能以线程模式运行。
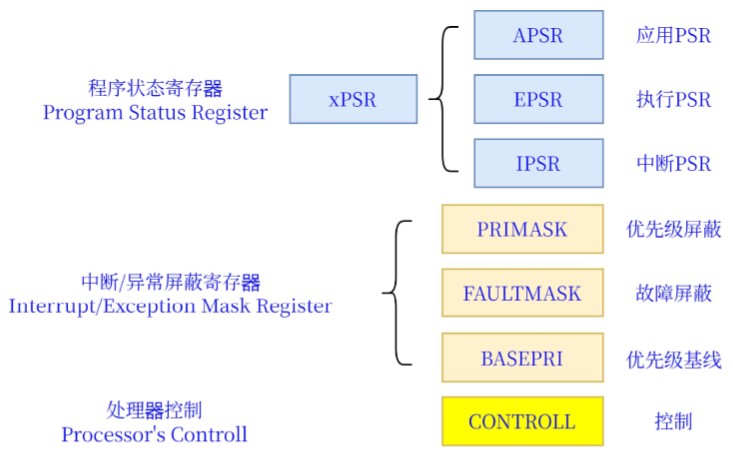
寄存器 **** 通用寄存器(General Purpose Registers):
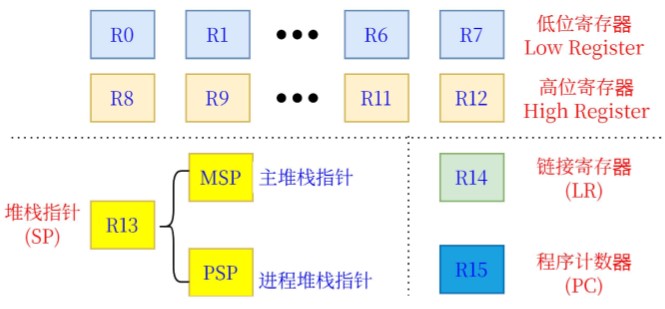
特殊寄存器:
高速缓存控制器
Cache仅为指令缓存和中央处理器(CPU)获取指令,Cache快速访问和存储内部缓冲闪存(Flash)存储器的代码。
特征:指令缓存;直接映射;4路关联1KB Cache存储器集(Set);测量缓存击中/丢失率(Hit/Loss Rate)的寄存器;支持纠错码(ECC);错误日志和中断产生;自动设置Flash睡眠的节电设计。
细节:缓存接口;代码保护与安全;Cache击中与丢失测量;Cache诱导Flash低功耗模式(睡眠模式行为);Cache 的使能与禁止(Cache线无效:Cache限制) 详见《PSoC5LP技术参考手册(TRM)》
外设集线器和直接存储访问控制器 ****
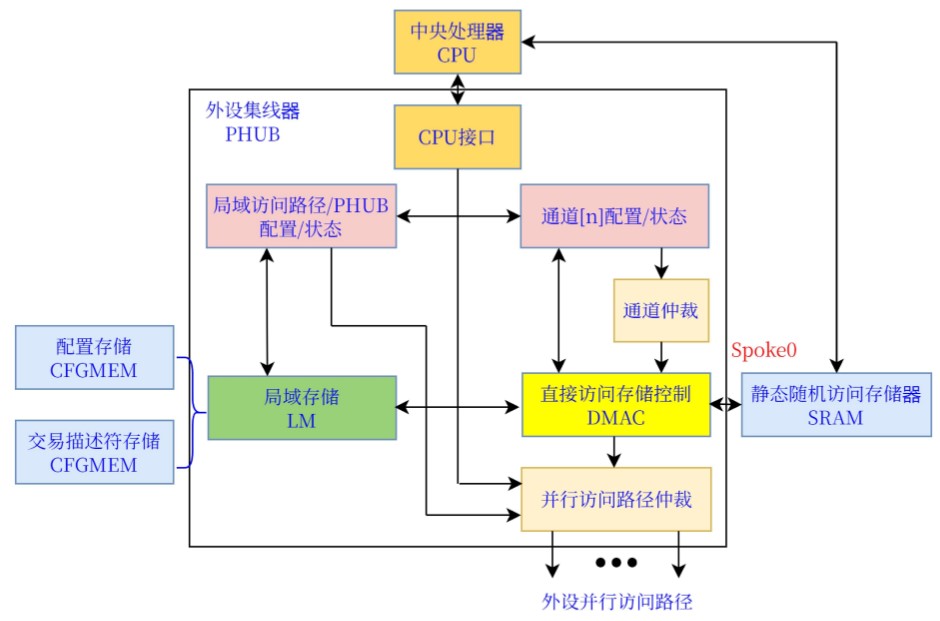
先进微处理器总线架构
-
高性能总线
(AMBA-HB):实现外设访问和批量(bulk)
数据传输;
外设集线器
(PHUB):AMBA-HB及其关联的中心控制器:中心总线基干(Baseline)
可编程可配置,紧密连接不同的片上系统单元。由多个并行访问路径(Spoke)组成,每个可连接数个外设模块;
直接存储访问控制器(DMAC):PHUB内置。用以数据传输;支持多个DMA
通道。总线主模块:DMAC和CPU:可启动总线阻塞PHUB仲裁器负责仲裁CPU和DMAC的请求;接收到CPU或DMAC的请求,中继请求至合适的Spoke
外设集线器(PHUB)
特征
先进微控制器总线架构高性能总线简化版(AMBA-HB Lite)协议外设的并行访问路径(Spoke):8个
(8~32)位数据宽度;
不同地址宽度外设连接同一Spoke
24个通道直接存储访问控制器(DMAC):可编程,支持字节指令与数据宽度的匹配原理
连接中央处理器(CPU)至存储器和外设:存储器:静态随机访问存储器(SRAM),快闪(Flash)存储器,电可擦除可编程只读存储器(EEPROM) 外设:模拟系统,数字模块,数字滤波器区块(DFB),及其他外设使用8个Spoke连接外设,每个可连接多个外设。
连接每个Spoke的外设可能有比Spoke的数据宽度长
外设可扩展多个Spoke:外设连接每个Spoke的不同地址空间
Spoke的地址宽度,数据宽度和外设在器件内固定且不能更改。
Spoke的配置:地址宽度;数据宽度;外设数量仲裁器
外设集线器(PHUB)由处理器(CPU)或直接存储访问控制器(DMAC)接收数据:处理每个请求确定访问某个并行访问路径
(Spoke)和外设,随即管理数据访问。
DMAC和CPU同时启动PHUB数据交易时,由仲裁器确定请求优先:除Spoke0外,每个Spoke均可配置优先级;Spoke0仅由DMAC访问,因CPU有独立SRAM接口。
CPU和DMAC同时访问不同Spoke,所有访问相互独立,无需仲裁:除SRAM外,由CPU和PHUB直接访问,无需仲裁,降低SRAM的访问延迟。
直接存储访问控制器(DMAC)
功能:
存储器与外设传输数据;PHUB(内置24个通道DMA)传输数据。
128个交易描述符(TD)
任意布线信号,CPU,或其他DMA通道触发交易;可停止或取消交易;
每次交易数据量(1T 64)KB,交易结束配置产生中断较大交易分割为较小的突发交易,并行访问路径(Spoke)内突发数量限制16个;支持高位优先和低位优先格式转换的字节交换,处理数据宽度差别
局域存储器(LM):PHUB内置LM:保存配置数据(配置存储(CFGMEM);交易描述符存储(TDMEM))。PHUB内置
16字节(Byte)的先进先出(FIFO):数据传输器件处理数据;LM经外设集线器(PHUB)的局域Spoke访问。
原理:
DMAC是PHUB的总线主元件之一,实现数据传输:存储器至存储器;存储器至外设;外设至存储器;外设至外设。
任意直接存储访问(DMA)通道数据传输经过:仲裁阶段;读取阶段;源引擎阶段;目的引擎阶段;写回阶段。
DMA传输需要的总时间依赖于各阶段消耗的时间:Spoke内/间传输;Spoke传输,相同Spoke内数据传输;利用内部FIFO DMA模式:简单DMA;自动重复DMA;乒乓DMA;环形DMA;索引DMA;分散聚集DMA;数据包队列DMA;嵌套DMA。
中断控制器 ****
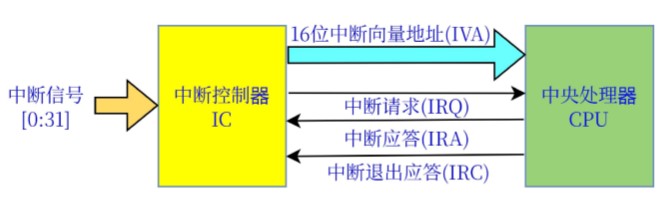
作用:提供更改程序地址到新位置的硬件资源的机制,独立于主程序代码的当前执行,中断服务程序(ISR)结束后,也处理即将执行的中断程序代码的继续。
特征:
支持32个中断线;
中断向量可编程:优先级可配置,动态更改优先级;每个中断的独立使能/禁止;中断嵌套;
各中断线有多个源:电平(Level)触发,脉冲(Pulse)触发;
支持:尾链(Tail Chaining),迟到(Late Arrivals),异常(Exceptions)
原理
中断源:32个中断信号源自:固定功能外设(FFP);直接存储访问(DMA);通用数字区块(UDB)。
中断请求:
利用中断布线,由复用器(Mux)选择中断请求:FFP中断请求(IRQ);UDB电平和边沿中断请求(IRQ);DMA中断请求(IRQ) 中断控制器(IC)单元优先和发送执行请求至CPU 中断使能(Enable):中断控制器(IC)使能和禁止(Disable)独立中断线
中断等待(Pending):中断控制器接收到中断信号时,设置等待(Pending)位。脉冲或电平中断,中断进入应答(IRA)接收到CPU应答立即清除等待位;等待位软件写入,硬件请求优先级高于软件请求优先级。
中断优先级:为每个中断赋予优先级的优先级处理,中断优先级(0~7),0高;优先级动态配置,运行时更改中断优先级而不影响相同中断的当前执行。
电平与脉冲中断:同时支持电平和脉冲中断,中断控制器内置脉冲检测逻辑,检测中断线的上升沿,若检测到上升沿,脉冲检测逻辑挂起中断位。
中断执行:中断进入应答(IRA),中断退出应答(IRC)。
PSoC5LP中断特征 **** 有效中断,中断嵌套,中断向量地址,尾链,迟到中断,异常,中断屏蔽,中断控制器与功耗模式存储器 静态随机访问存储器(SRAM) ****
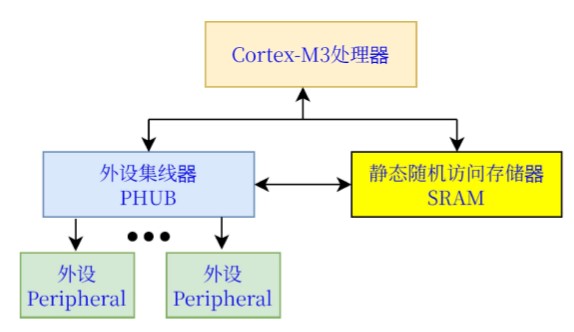
SRAM存储临时数据:程序代码地址空间内全速执行;地址0x20000000以上,执行速度稍慢。
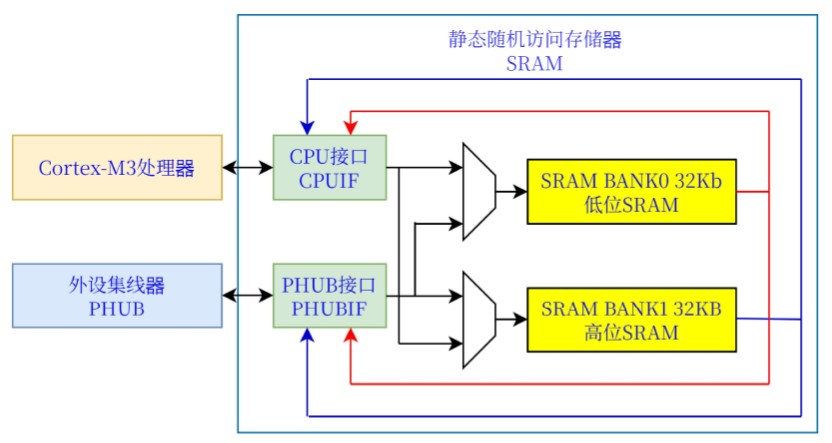
存储组(Bank):片上内置静态随机访问存储器(SRAM)多64KB:低位存储组:32Kb Bank0;高位存储组:32Kb
Bank1。CPU或DMAC(位于PHUB)均可访问所有SRAM,但不能同时访问SRAM中的同一组(Bank)存储:Bank0或
Bank1。
快闪程序存储器 ****
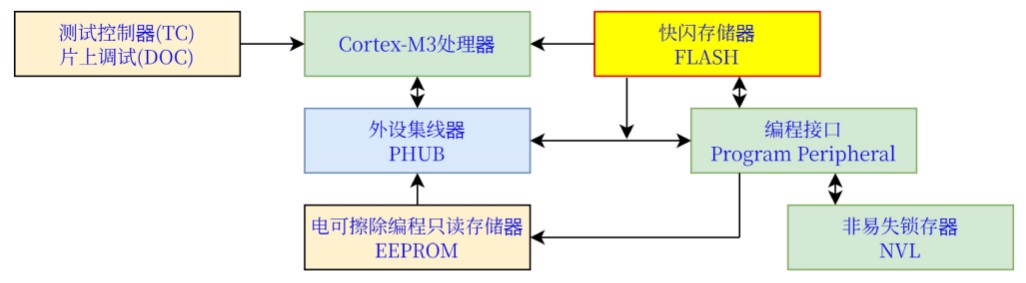
Flash提供非易失性存储(NVM),存储用户固件(FW)、配置数据、批量(bulk)数据、纠错码(ECC)。
空间:用户代码存储空间 多256KB,其中纠错码(ECC)多32KB;若未使用ECC,可存储配置和批量用户数据,用户代码不能在ECC地址外执行。
纠错码:纠错码(ECC)以固件存储的每8字节(Byte)为单位,纠正1位(Bit)错误和检测2位(Bit)错误,检测到错误,则产生中断;Flash输出9字节宽度:8字节数据,1字节ECC数据。
CPU或DMAC(位于PHUB)由Cache控制器读取Flash的用户代码和批量数据,以实现CPU的更高性能;使能ECC,
Cache控制器也执行错误检查和纠正。
编程:Flash编程由专用接口执行,期间不允许在Flash内执行代码。编程过程中,可在SRAM外执行代码。Flash编程接口会执行擦除、编程,并设置代码保护级。
系统内串行编程(ISSP)用于量产编程,也可用串线调试(SWD)和联合测试行动组(JTAG),ISSP常用于引导加载程序
(Bootloader)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









