







模型的选择
LangChain支持许多知名LLM,例如百度的文心一言,OpenAl等..... (相关调用方法具体百度)
本项目采用了智谱清言的Chat-GLM4模型,读者可切换其他模型进行尝试!
将大模型接入LangChain
Langchain官网文档中,并没有详细讲解如何将本地或者其他未接入Langchain的模型的方法.
具体方法主要通过 继承Langchain的LLM类,并重载 _call , _stream等方法实现.(值得一提的是截止到文章发布时间,智谱清言官方已经发布了如何接入Langchain SDK的方法)
这里详细解释下我个人理解: 接入Langchain 最基本需要继承LLM类并且重载 _llm_type , _call 方法 三者缺一不可. _llm_type 具体定义了模型的名称. _call方法主要需要写出模型怎么调用得到输出的过程.
基于以上理解,写出下列代码.
示例代码:
from langchain_core.outputs import ChatGenerationChunk
from zhipuai import ZhipuAI
import json
import time
from langchain.llms.base import LLM
from typing import Optional, List, Any, Mapping, Iterator
from langchain.schema.output import GenerationChunk # 用于流式传输
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.chat_models import openai
from langchain_core.callbacks.manager import CallbackManager
from langchain_core.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_core.messages.ai import AIMessageChunk
from typing import Dict
class chat_glm4(LLM):
# 模型的各个参数
max_token: int = 8192
do_sample: bool = True
temperature: float = 0.0 # 0.5
top_p = 0.7
tokenizer: object = None
model: object = None
history: List = []
tool_names: List = []
has_search: bool = False
client: object = None # 额外实现这个
@property
def _llm_type(self) -> str:
return "ChatGLM4"
# 初始化时需要指定模型的API key
def __init__(self, zhipuai_api_key):
super().__init__()
self.client = ZhipuAI(api_key=zhipuai_api_key)
# 重载call函数
def _call(self, prompt: str,
history: List = [],
stop: Optional[List[str]] =None
):
if history is None:
history = []
# 常规调用
response = self.client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
temperature=0.95,
top_p=0.7,
stop = stop # 停止词
)
# 得到模型输出的结果返回结果
result = response.choices[0].message.content
return result
# 异步调用
def sse_invoke(self, prompt: str, history=[]):
if history is None:
history = []
history.append({"role": "user", "content": prompt})
response = self.client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=history,
stream=True,
)
return response
# 流式调用
def _stream( # type: ignore[override]
self,
prompt: List[Dict[str, str]],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
"""Stream the chat response in chunks."""
response = self.sse_invoke(prompt)
for chunk in response:
if chunk.choices[0].delta:
delta = chunk.choices[0].delta.content
chunk = ChatGenerationChunk(message=AIMessageChunk(content=delta))
if run_manager:
run_manager.on_llm_new_token(delta, chunk=chunk)
yield chunk
附上智谱清言对于各个参数的解释: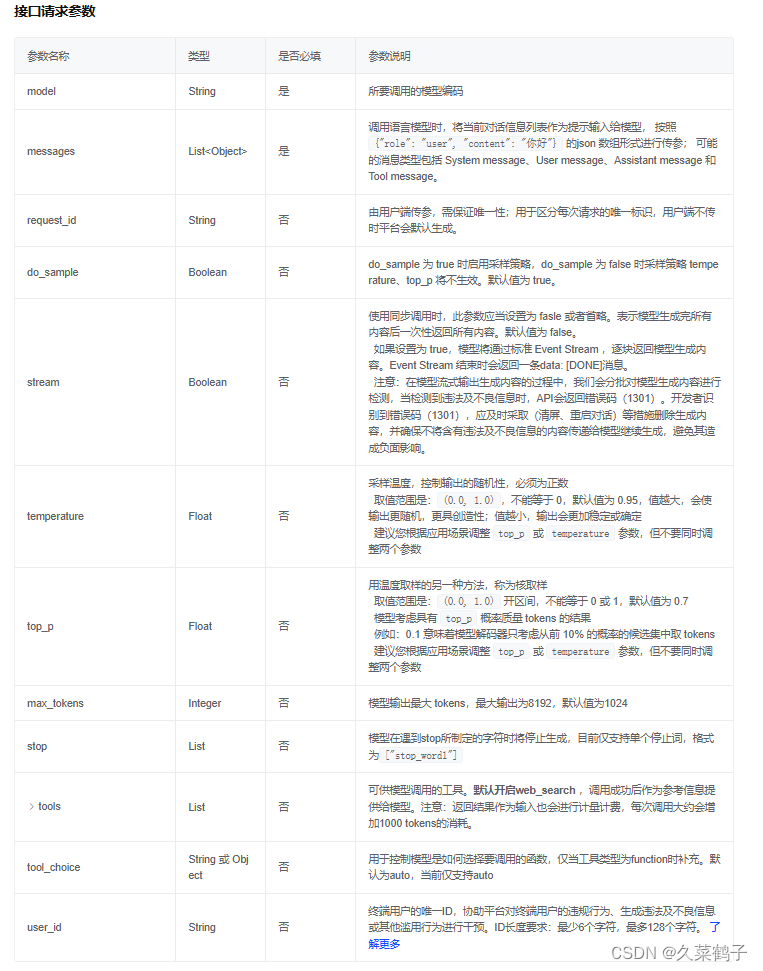
读者可根据自己需要自行调节参数.
到此为止,我们已经成功的将ChatGLM4模型接入了LangChain.我们可以写一个代码测试一下:
from Chat_GLM4 import chat_glm4
llm = chat_glm4(zhipuai_api_key="替换为你的api key")
print(llm.invoke("你好!"))
# 输出: 你好!欢迎您,请问有什么可以帮助您的吗?这里附上本地部署ChatGLM3-6B的示例代码(只重载了最基本的功能)
class Chat_GLM3(LLM):
# 基于本地 InternLM 自定义 LLM 类
# 声明分词器和模型
max_token: int = 8192
do_sample: bool = True
temperature: float = 0.0 # 0.5
top_p = 0.7
tokenizer: AutoTokenizer = None
model: AutoModel = None
def __init__(self, model_path="THUDM/chatglm3-6b"):
super().__init__()
print("正在加载模型")
# 加载分词器和模型
self.tokenizer = AutoTokenizer.from_pretrained(
model_path, trust_remote_code=True, local_files_only=True
)
# 注意 4bit量化仅供测试 服务器部署可以改成 fp16
self.model = (
AutoModel.from_pretrained(model_path, trust_remote_code=True, local_files_only=True)
.quantize(4)
.cuda()
)
self.model = self.model.eval()
print("完成模型的加载")
# 重载 _call 函数
def _call(
self,
prompt: str,
history: List = [],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any
):
if history is None:
history = []
# 重写调用函数
response, history = self.model.chat(self.tokenizer, prompt, history=[])
return response
@property
def _llm_type(self) -> str:
return "ChatGLM3-6B"
LangChain Expression Language
首先,引入一篇官方对LCEL(LangChain Expression Language)的介绍
-LCEL makes it easy to build complex chains from basic components, and supports out of the box functionality such as streaming, parallelism, and logging.
-LCEL 可以轻松地从基本组件构建复杂的链,并支持流、并行和日志等开箱即用的功能。
首先,介绍一下Chain(链)到底是神魔(个人理解).
LangChain中 核心也是最基本的组件有如下三种:
| Prompt | 提示词 |
| Model | 大模型 |
| OutPut Parser | 输出解释器 |
Prompt
Prompt 功能通常用于提供上下文信息,以便大模型能够更准确地理解和回应人类的语言输入。
相当于我们给模型加一个短期记忆,给了他所根据的材料.它非常强大(Prompt工程)
eg. 提供对话的上下文信息,机器翻译,限制模型的行为,更改模型回复的口气.....
废话少说,直接上代码:
from Chat_GLM4 import chat_glm4
from langchain_core.prompts import ChatPromptTemplate
# 因为ChatGLM属于对话模型,所以需要使用ChatPrompt
prompt = ChatPromptTemplate.from_template("你是一名{role},请你以{role}的语气回答用户{input}")
llm = chat_glm4(zhipuai_api_key="")
print(type(prompt))
# 形成链
chain = prompt | llm
print(chain.invoke({"role":"厨师","input":"三文鱼的烹饪手法"}))
# 输出
"""
<class 'langchain_core.prompts.chat.ChatPromptTemplate'>
作为一名厨师,我可以告诉你,三文鱼是一种非常受欢迎的海鲜,它可以用多种烹饪方法来制作。以下是一些常见的三文鱼烹饪手法:
1. 煎三文鱼:在平底锅中加入少量橄榄油,将三文鱼皮朝下放入,用中火煎至金黄色,然后翻转煎另一面,直至熟透。
...省略
"""由示例代码可知:Prompt的作用 它接收变量字典并生成 PromptValue。PromptValue 是对已完成的提示的封装,可以传递给 LLM(将字符串作为输入)或 ChatModel(将消息序列作为输入)。由于它定义了生成 BaseMessages 和生成字符串的逻辑,因此可以与任何一种语言模型类型配合使用。
在项目后续的代码中 Prompt会经常用到.
OutPut Parser
输出解析器负责获取 LLM 的输出,并将其转换为更合适的格式。这在使用 LLM 生成任何形式的结构化数据时都非常有用。
除了拥有大量不同类型的输出解析器之外,LangChain 输出解析器还有一个显著的优点,那就是其中很多都支持流式处理。
输出解释器(OutPut Parser)就比较好理解了.它控制模型的输出,使得模型的输出符合我们期望的格式.
示例代码:
from Chat_GLM4 import chat_glm4
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 因为ChatGLM属于对话模型,所以需要使用ChatPrompt
prompt = ChatPromptTemplate.from_template("你是一名{role},请你以{role}的语气回答用户{input}")
llm = chat_glm4(zhipuai_api_key="")
print(type(prompt))
# 输出解释器
output_parser = StrOutputParser()
print(output_parser)
# 形成链
chain = prompt | llm | output_parser
message = chain.invoke({"role":"厨师","input":"三文鱼的烹饪手法"})
print(type(message))
print(message)
# 输出
"""
class 'langchain_core.prompts.chat.ChatPromptTemplate'>
<class 'str'>
当然,很高兴能以厨师的身份为您提供三文鱼的烹饪建议。
三文鱼是一种非常受欢迎的鱼类,它不仅营养价值高,而且口感鲜美。以下是几种常见的三文鱼烹饪方法:
"""在了解完这两个组件和相关示例之后,我们再来理解 Chain的含义:Chain指的是工具的一系列调用顺序--无论是调用 LLM、工具还是数据预处理步骤。主要的支持方式是使用 LCEL(LangChain Expression Language)。
在本章我们学习了如何将大模型接入LangChain,并且初步认识了 LangChain中的核心组件-Chain
非常感谢您阅读本篇博客!如果您觉得这篇文章对您有所帮助,或者您对Neo4j和Langchain框架感兴趣,请不要吝啬您的点赞和收藏。您的支持是我继续努力创作的动力!同时,也欢迎您在评论区留言,分享您的想法和经验,让我们一起交流学习,共同进步。再次感谢您的阅读,希望我们下次再见!















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









