






本地知识库问答系统demo,OpenAI,智谱清言,Lang

本地知识库问答系统,OpenAI,智谱清言,LangChain技术pdf出错是因为课表里没有第几节课的概念,而是节次
直达API 接openaigpt4-o+langchain
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import os
os.environ['http_proxy']=''
os.environ['https_proxy']=''#
llm = ChatOpenAI(api_key="")
# llm = ChatOpenAI(api_key="")
# a=llm.invoke("how can langsmith help with testing?")
# print(a)
# from langchain_core.prompts import ChatPromptTemplate
# prompt = ChatPromptTemplate.from_messages([
# ("system", "You are a world class technical documentation writer."),
# ("user", "{input}")
# ])
# chain = prompt | llm
# b=chain.invoke({"input": "帮我写一个学生成绩管理系统用C++"})
# print(b)
# from langchain_core.output_parsers import StrOutputParser
#
# output_parser = StrOutputParser()
# chain = prompt | llm | output_parser
# c=chain.invoke({"input": "帮我生成一首古诗"})
# print(c)
# #11111111
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("")
docs = loader.load()
# #11111111
from langchain_openai import OpenAIEmbeddings
# 使用 OpenAIEmbeddings 类创建一个嵌入模型实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
#loader = WebBaseLoader("")
# 使用 WebBaseLoader 加载文档
loader = WebBaseLoader("")
docs = loader.load()
# 创建一个文本分割器
text_splitter = RecursiveCharacterTextSplitter()
# 使用文本分割器将文档拆分为段落
documents = text_splitter.split_documents(docs)
# 根据选择的嵌入模型,创建一个嵌入实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 使用嵌入模型将文档嵌入到向量中
vector = FAISS.from_documents(documents, embeddings)
# 至此,文档已经被成功嵌入并索引到了向量存储中
# # #11111111
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
from langchain_core.documents import Document
# document_chain.invoke({
# "input": "how can langsmith help with testing?",
# "context": [Document(page_content="langsmith can let you visualize test results")]
# })
# document_chain.invoke({
# "input": "",
# "context": [Document(page_content="langsmith can let you visualize test results")]
# })
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({"input": ""})
#response = retrieval_chain.invoke({"input": ""})
print(response["answer"])
# LangSmith offers several features that can help with testing:...
# # #11111111清华gpt接prompt提示词 glm-4
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import os
os.environ['http_proxy']=''
os.environ['https_proxy']=''#
llm = ChatOpenAI(api_key="")
# llm = ChatOpenAI(api_key="")
# a=llm.invoke("how can langsmith help with testing?")
# print(a)
# from langchain_core.prompts import ChatPromptTemplate
# prompt = ChatPromptTemplate.from_messages([
# ("system", "You are a world class technical documentation writer."),
# ("user", "{input}")
# ])
# chain = prompt | llm
# b=chain.invoke({"input": "帮我写一个学生成绩管理系统用C++"})
# print(b)
# from langchain_core.output_parsers import StrOutputParser
#
# output_parser = StrOutputParser()
# chain = prompt | llm | output_parser
# c=chain.invoke({"input": "帮我生成一首古诗"})
# print(c)
# #11111111
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("")
docs = loader.load()
# #11111111
from langchain_openai import OpenAIEmbeddings
# 使用 OpenAIEmbeddings 类创建一个嵌入模型实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
#loader = WebBaseLoader("")
# 使用 WebBaseLoader 加载文档
loader = WebBaseLoader("")
docs = loader.load()
# 创建一个文本分割器
text_splitter = RecursiveCharacterTextSplitter()
# 使用文本分割器将文档拆分为段落
documents = text_splitter.split_documents(docs)
# 根据选择的嵌入模型,创建一个嵌入实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 使用嵌入模型将文档嵌入到向量中
vector = FAISS.from_documents(documents, embeddings)
# 至此,文档已经被成功嵌入并索引到了向量存储中
# # #11111111
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
from langchain_core.documents import Document
# document_chain.invoke({
# "input": "how can langsmith help with testing?",
# "context": [Document(page_content="langsmith can let you visualize test results")]
# })
# document_chain.invoke({
# "input": "",
# "context": [Document(page_content="langsmith can let you visualize test results")]
# })
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({"input": ""})
#response = retrieval_chain.invoke({"input": ""})
print(response["answer"])
# LangSmith offers several features that can help with testing:...
# # #11111111
清华gpt接langchain
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
# 初始化 GLM-4 模型
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="",
openai_api_base=""
)
# 加载网页内容
loader = WebBaseLoader("")
docs = loader.load()
# 创建文本分割器
text_splitter = RecursiveCharacterTextSplitter()
# 使用文本分割器将文档拆分为段落
paragraphs = text_splitter.split_documents(docs)
# 将段落信息转换为字符串列表,并传入prompt的placeholder中
document_content = [doc.page_content for doc in paragraphs]
# 构建prompt提示词
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
""
),
MessagesPlaceholder(variable_name="document_content"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# 运行LLMChain
conversation = prompt | llm
# 提出问题并获取回答
question = ""
#question = "把网址的内容全部展示出来"
answer = conversation.invoke({"document_content": document_content, "question": question})
print(answer)
中转API未接langchain gpt-3.5-turbo
import os
# 设置 OPENAI_API_KEY 环境变量
os.environ["OPENAI_API_KEY"] = ""
# 设置 OPENAI_BASE_URL 环境变量
os.environ["OPENAI_BASE_URL"] = ""
from openai import OpenAI
import httpx
client = OpenAI(
base_url="",
api_key="",
http_client=httpx.Client(
base_url="",
follow_redirects=True,
),
)
'''
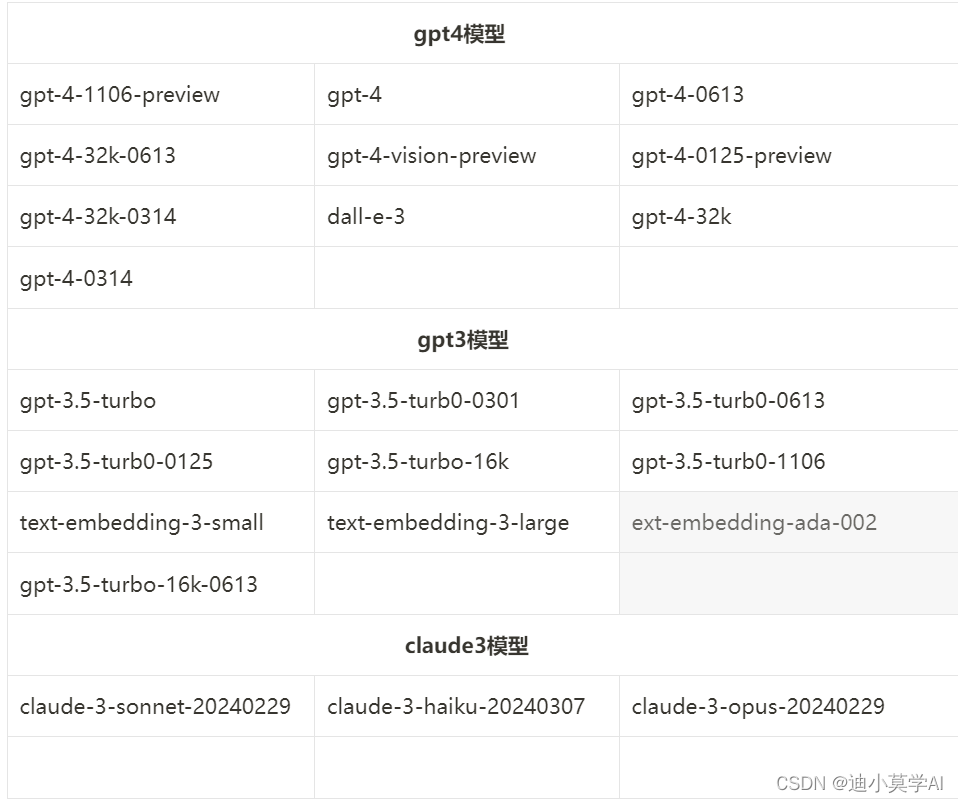
gpt-3.5-turbo gpt-3.5-turb0-0301 gpt-3.5-turb0-0613
gpt-3.5-turb0-0125 gpt-3.5-turbo-16k gpt-3.5-turb0-1106
text-embedding-3-small text-embedding-3-large ext-embedding-ada-002
gpt-3.5-turbo-16k-0613
'''
completion = client.chat.completions.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "帮我写一个学生成绩管理系统用C++"}
#{"role": "user", "content": "今天的天气怎么样?"}
]
)
print(completion)#中转api接3.5接langchain text-embedding-ada-002
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import OpenAI # 使用langchain_openai中的OpenAI
import httpx
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.documents import Document
from langchain.chains import create_retrieval_chain
import requests
from requests.adapters import HTTPAdapter
# 设置环境变量
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_BASE_URL"] = ""
# 初始化OpenAI客户端
llm = OpenAI(
base_url="",
api_key=os.environ["OPENAI_API_KEY"],
http_client=httpx.Client(
base_url="",
follow_redirects=True,
),
)
# 创建自定义会话以忽略SSL验证
session = requests.Session()
adapter = HTTPAdapter(max_retries=3)
session.mount('http://', adapter)
session.mount('https://', adapter)
# 加载文档时忽略SSL验证
loader = WebBaseLoader("")
loader.session = session
loader.requests_kwargs = {'verify': False}
docs = loader.load()
# 将文档拆分成段落
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# 使用支持嵌入操作的模型
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# 将文档嵌入到向量中
vector = FAISS.from_documents(documents, embeddings)
# 创建带有提示的文档链
prompt = ChatPromptTemplate.from_template("""
Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}
""")
document_chain = create_stuff_documents_chain(llm, prompt)
# 创建检索链
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 使用查询调用检索链
response = retrieval_chain.invoke({"input": "5月13号有什么消息?"})
# 打印响应
print(response["answer"])
#openaigpt处理文档内容
import fitz # PyMuPDF
from langchain_core.documents import Document
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import WebBaseLoader
from langchain.chains import create_retrieval_chain
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
import os
os.environ['http_proxy']=''
os.environ['https_proxy']=''
# 1. 从 PDF 文档中提取文本信息
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
return text
# 2. 创建 LangSmith 实例
llm = ChatOpenAI(api_key="")
# 3. 创建文档加载器并加载 PDF 文档
pdf_path = r"" # 替换为你的 PDF 文件路径
pdf_text = extract_text_from_pdf(pdf_path)
# 4. 创建 LangSmith 链
prompt = ChatPromptTemplate.from_template("""根据提供的上下文回答以下问题:
<context>
{context}
</context>
问题:{input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# 5. 创建文档嵌入实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 6. 创建文档向量存储
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents([Document(page_content=pdf_text)])
vector = FAISS.from_documents(documents, embeddings)
# 7. 创建检索链
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 8. 提出问题并获取回答
question = "周一节次为3,4是什么课?在哪个教室上课?"
response = retrieval_chain.invoke({"input": question})
print(response["answer"])
#gml4处理文档内容
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
import pdfplumber
# 初始化 GLM-4 模型
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="",
openai_api_base=""
)
# 加载 PDF 文档内容
with pdfplumber.open(r"C:\Users\18499\Desktop\Langchaintest\test.pdf") as pdf:
pdf_text = pdf.pages[0].extract_text() # 假设只提取第一页的内容
# 创建一个列表,包含课表的每一行
document_content = pdf_text.split('\n')
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"请根据文档信息回答问题。"
),
MessagesPlaceholder(variable_name="document_content", memory_key="document_content"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# 运行LLMChain
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=ConversationBufferMemory(memory_key="chat_history", return_messages=True)
)
# 提出问题并获取回答
question = "我周二第一节课是什么课?"
input_data = {"document_content": document_content, "question": question}
answer = conversation.invoke(input_data)
print(answer)















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









