










Stable Diffusion(SD) 是由CompVis、Stability AI 和 LAION 的研究人员于 2022 年发布的一款文本到图像生成的潜在扩散模型,基础版SD1.5(512*512),SD2.1(768*768),后又开源了SDXL(1024*1024)、SDXL-turbo,一般用于图像生成、图像处理等任务,其技术原理:
一种基于变分自编码器(VAE)的潜在扩散模型,它通过在低维度的潜在空间中操作来减少计算成本和提高生成图像的速度。它不仅可以专门用于文本到图像的任务,还可以用于图像到图像、人物刻画、超分辨率或着色任务。
其工作原理分为以下几个关键步骤:
提示词(Prompt)输入,文本信息转换成语义向量传输给文本编码器(Text Encode);潜在空间压缩:使用变分自编码器(VAE)将高维度的图像数据压缩到一个低维度的潜在空间。在Stable Diffusion中,这个潜在空间的维度远小于原始图像空间,从而大大减少了需要处理的数据量。正向扩散:在潜在空间中,模型通过逐步添加噪声来“扩散”图像,最终将图像转化为完全随机的噪声分布。这个过程模拟了物理中的扩散现象,使得图像的特征逐渐消失。噪声预测器:在训练阶段,模型学习如何预测在潜在空间中添加的噪声。这是一个U-Net结构的神经网络,它通过学习如何从噪声图像中恢复出原始图像来训练。反向扩散:在生成阶段,模型使用噪声预测器来估计潜在空间中图像的噪声,并逐步去除这些噪声,从而从噪声中恢复出清晰的图像。条件生成:Stable Diffusion通过提示词来引导图像的生成。提示词首先被分词并转换为嵌入向量,然后这些向量被输入到噪声预测器中,以指导生成过程,确保生成的图像与提示词相匹配。VAE解码:最后,潜在空间中的图像通过VAE的解码器转换回原始的像素空间,生成最终的图像。
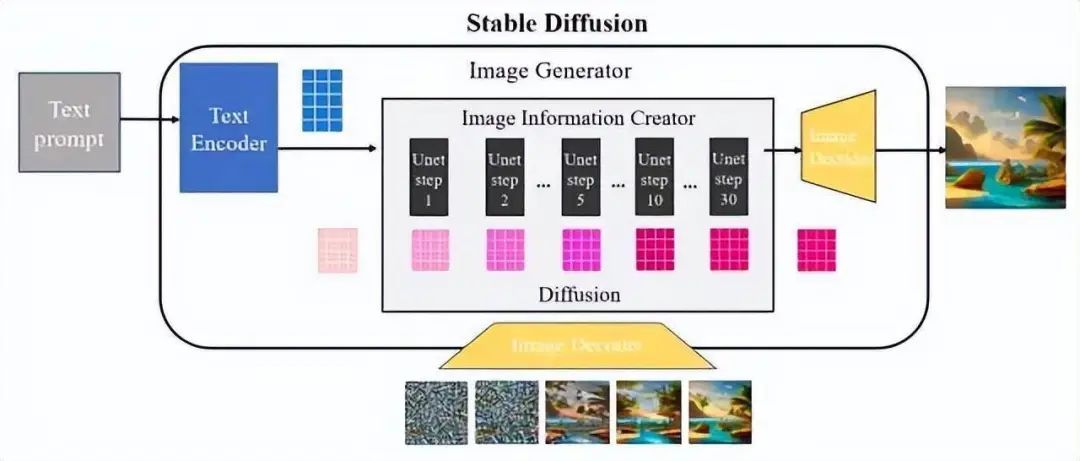
如下图:扩散过程发生在图像信息生成器中,将初始纯噪声潜变量输入到Unet网络中并与语义控制向量结合,该过程重复30-50次以不断从纯噪声潜变量中去除噪声变量并不断地将语义信息注入到潜在向量中,可以获得具有丰富语义信息的潜在空间向量(图右下深粉色方块)。采样器负责协调整个去噪过程,并根据设计模式在去噪的不同阶段动态调整Unet去噪强度。为了更好地理解这一点,图内显示了通过将初始纯噪声向量和最终去噪潜在向量输入到图像解码器中输出图像的差异。从图中可以看出,纯噪声向量的解码图像由于缺乏任何有用信息也是纯噪声,而去噪潜向量经过50次迭代后的解码图像是有效的并且包含语义信息。
通常理解就是:Stable Diffusion 是一种智能的图像生成工具,它能够根据你提供的描述文字(比如“一只蓝色的猫”)来创造出相应的图片。它是怎么工作的呢?
首先,它有一个特殊的大脑(图像模型+变分自编码器),这个大脑可以把复杂的图像压缩成一个简单的、低维度的表示(就像把一张大照片压缩成一个小图标)。这样处理起来就快多了。然后,它开始在脑海中想象这张图片,但是一开始是一团乱糟糟的噪声,就像是一张全是像素点的图片。接下来,它开始一步步地清理这些噪声,就像擦去墨水一样,让图片逐渐清晰起来。在这个过程中,它会根据你提供的描述来指导这个过程。比如你告诉它“蓝色的猫”,它就会在清理噪声的时候特别注意,确保最后生成的图片中有一只蓝色的猫。最后,这个工具会把这些脑海中的想象转换成真实的图片,就像把想象中的画面打印出来一样。这样,你就能得到一张根据你的描述生成的图片了。

为了降低理解成本,我会尽量减少有关数学的知识点,并尽量用类比的方式,帮助你理解一些概念。所以有可能出现不够严谨的情况,如果你有更好的解释,欢迎留言。或加入我们的社群,与我联系。
!开源免费
软件本身无任何使用成本,一键即可打开使用。
源生应用需要安装环境,传送门:https://github.com/AUTOMATIC1111/stable-diffusion-webui
Windows:秋叶大佬一键启动包,传送门:https://pan.baidu.com/s/1go-IS2l0IKfYUfiXCqVNUw?pwd=07hb
Mac:一键启动包,传送门:https://pan.baidu.com/s/1wwH4iVDPJBGja_2zeGVGBA?pwd=gban
!本地部署
生成的图片和图像模型都在本地计算机上,数据安全性非常高,使用无需联网。支持Windows、MAC、Linux系统。适用于个人或团队使用。
!云端部署
同样,能部署在本地,也能部署在云端,这样就免去了配置高端电脑的条件了。适用于企业级团队或炼丹使用。推荐的云端:https://www.lanrui-ai.com/
!高度可扩展
多种多样的开源插件,适合很多定制化需求场景,有能力的话还能自己开发插件。可以根据行业属性或者企业IP风格定制属于自己的大模型。
!无内容限制
可以生成任何内容图像。
使用门槛
本地部署电脑的硬件配置需满足:
-
Widows系统:内存8G以上,Nvidia(英伟达)显卡,显卡内存4G以上,硬盘空间500G以上。
-
- 4G显存:勉强可以跑SD,出图时间20秒至50秒左右一张;
- 6G显存:同上,XL模型跑不动;
- 8G显存:20秒左右出一张图,基本功能都能使用;
- 16G显存:5-10秒出一张图,所有功能都能用;
- 24G显存:无敌,炼丹亦可。
-
MAC :M1-M2以上型号,用CPU跑的,据说跑的非常慢。
上网条件(下载插件和大模型)。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2045
2045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









