






1.1 方差过滤
1.1.1 VarianceThreshold
这是通过特征本身的方差来筛选特征的类。比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差 异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无 论接下来的特征工程要做什么,都要优先消除方差为
0
的特征
。
VarianceThreshold
有重要参数
threshold
,表示方 差的阈值,表示舍弃所有方差小threshold
的特征,不填默认为
0
,即删除所有的记录都相同的特征。
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵
#也可以直接写成 X = VairanceThreshold().fit_transform(X)
X_var0.shape1.1.2 方差过滤对模型的影响
从算法原理上来说,传统决策树需要遍历所有特征,计算不纯度后进行分枝,而随机森林却是随机选择特征进 行计算和分枝,因此随机森林的运算更快,过滤法对随机森林无用,对决策树却有用 在sklearn
中,决策树和随机森林都是随机选择特征进行分枝
,但决策树在建模过程中随机抽取的特征数目却远远超过随机森林当中每棵树随机抽取 的特征数目(比如说对于这个780
维的数据,随机森林每棵树只会抽取
10~20
个特征,而决策树可能会抽取 300~400个特征),因此,过滤法对随机森林无用,却对决策树有用 也因此,在sklearn
中,随机森林中的每棵树都比单独的一棵决策树简单得多,高维数据下的随机森林的计算比决策树快很多。
1.1.3 选取超参数threshold
我们怎样知道,方差过滤掉的到底时噪音还是有效特征呢?过滤后模型到底会变好还是会变坏呢?
答案是:每个数 据集不一样,只能自己去尝试。这里的方差阈值,其实相当于是一个超参数,要选定最优的超参数,我们可以画学 习曲线,找模型效果最好的点。但现实中,我们往往不会这样去做,因为这样会耗费大量的时间。我们只会使用阈 值为0
或者阈值很小的方差过滤,来为我们优先消除一些明显用不到的特征,然后我们会选择更优的特征选择方法 继续削减特征数量。
1.2 卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验feature_selection.chi2
计算每个非负 特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合feature_selection.SelectKBest 这个可以输入”
评分标准
“
来选出前
K
个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目 的无关的特征。
另外,如果卡方检验检测到某个特征中所有的值都相同,会提示我们使用方差先进行方差过滤。并且,刚才我们已 经验证过,当我们使用方差过滤筛选掉一半的特征后,模型的表现时提升的。因此在这里,我们使用threshold=中 位数时完成的方差过滤的数据来做卡方检验(如果方差过滤后模型的表现反而降低了,那我们就不会使用方差过滤 后的数据,而是使用原数据:
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#假设在这里我一直我需要300个特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(X_fsvar, y)
X_fschi.shape1.2.1 选取超参数K
那如何设置一个最佳的K
值呢?在现实数据中,数据量很大,模型很复杂的时候,我们也许不能先去跑一遍模型看 看效果,而是希望最开始就能够选择一个最优的超参数k
。
import matplotlib.pyplot as plt
score = []
for i in range(390,200,-10):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar, y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
score.append(once)
plt.plot(range(350,200,-10),score)
plt.show()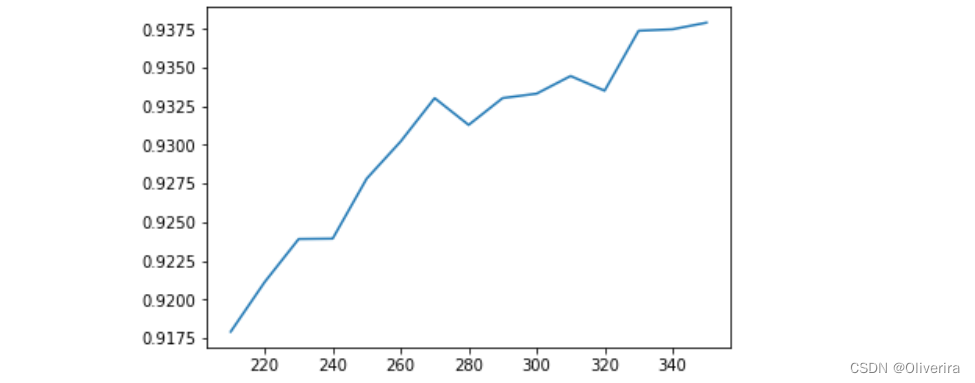
通过这条曲线,我们可以观察到,随着K
值的不断增加,模型的表现不断上升,这说明,
K
越大越好,数据中所有的特征都是与标签相关的。
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”
两组数据是相互独立的
”
。卡方检验返回卡方值和 P值两个统计量,其中卡方值很难界定有效的范围,而
p
值,我们一般使用
0.01
或
0.05
作为显著性水平,即
p值判断的边界。
从特征工程的角度,我们希望选取卡方值很大,p
值小于
0.05
的特征,即和标签是相关联的特征。而调用 SelectKBest之前,我们可以直接从
chi2
实例化后的模型中获得各个特征所对应的卡方值和
P
值。
chivalue, pvalues_chi = chi2(X_fsvar,y)
chivalue
pvalues_chi
#k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征:
k = chivalue.shape[0] - (pvalues_chi > 0.05).sum()
#X_fschi = SelectKBest(chi2, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()1.3 F检验
F检验,又称
ANOVA
,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也可以做分类,因此包含feature_selection.f_classif(F检验分类)
feature_selection.f_regression
(F检验回 归)两个类。其中F
检验分类用于标签是离散型变量的数据,而
F
检验回归用于标签是连续型变量的数据。 和卡方检验一样,这两个类需要和类SelectKBest
连用,并且我们也可以直接通过输出的统计量来判断我们到底要 设置一个什么样的K
。需要注意的是,
F
检验在数据服从正态分布时效果会非常稳定,因此如果使用
F
检验过滤,我
们会先将数据转换成服从正态分布的方式。
F检验的本质是寻找两组数据之间的线性关系,其原假设是
”
数据不存在显著的线性关系
“
。它返回
F
值和
p
值两个统 计量。和卡方过滤一样,我们希望选取
p
值小于
0.05
或
0.01
的特征,这些特征与标签时显著线性相关的
,而
p
值大于 0.05或
0.01
的特征则被我们认为是和标签没有显著线性关系的特征,应该被删除。以
F
检验的分类为例,我们继续 在数字数据集上来进行特征选择:
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,y)
F
pvalues_f
k = F.shape[0] - (pvalues_f > 0.05).sum()
#X_fsF = SelectKBest(f_classif, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fsF,y,cv=5).mean()1.4 互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F
检验相似,它既 可以做回归也可以做分类,并且包含两个feature_selection.mutual_info_classif
(互信息分类)和
feature_selection.mutual_info_regression
(互信息回归)。这两个类的用法和参数都和
F
检验一模一样,不过 互信息法比F
检验更加强大,
F
检验只能够找出线性关系,而互信息法可以找出任意关系。 互信息法不返回p
值或
F
值类似的统计量,它返回
“
每个特征与目标之间的互信息量的估计
”
,这个估计量在
[0,1]
之间 取值,为0
则表示两个变量独立,为
1
则表示两个变量完全相关。以互信息分类为例的代码如下:
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
k = result.shape[0] - sum(result <= 0)
#X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()1.5 过滤法总结
















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









