






一、起因
Office 2016未有平滑过渡功能,但是不想下载wps,实验软件资源中有Office 2021安装包,故打算彻底卸载Office 2016,安装Office 2021。
二、卸载2016
1. 网上看了一下,在“控制面板\程序\程序和功能”的“卸载或更改程序”中,没找到Office,故选择Microsoft的手动卸载Office的文章。
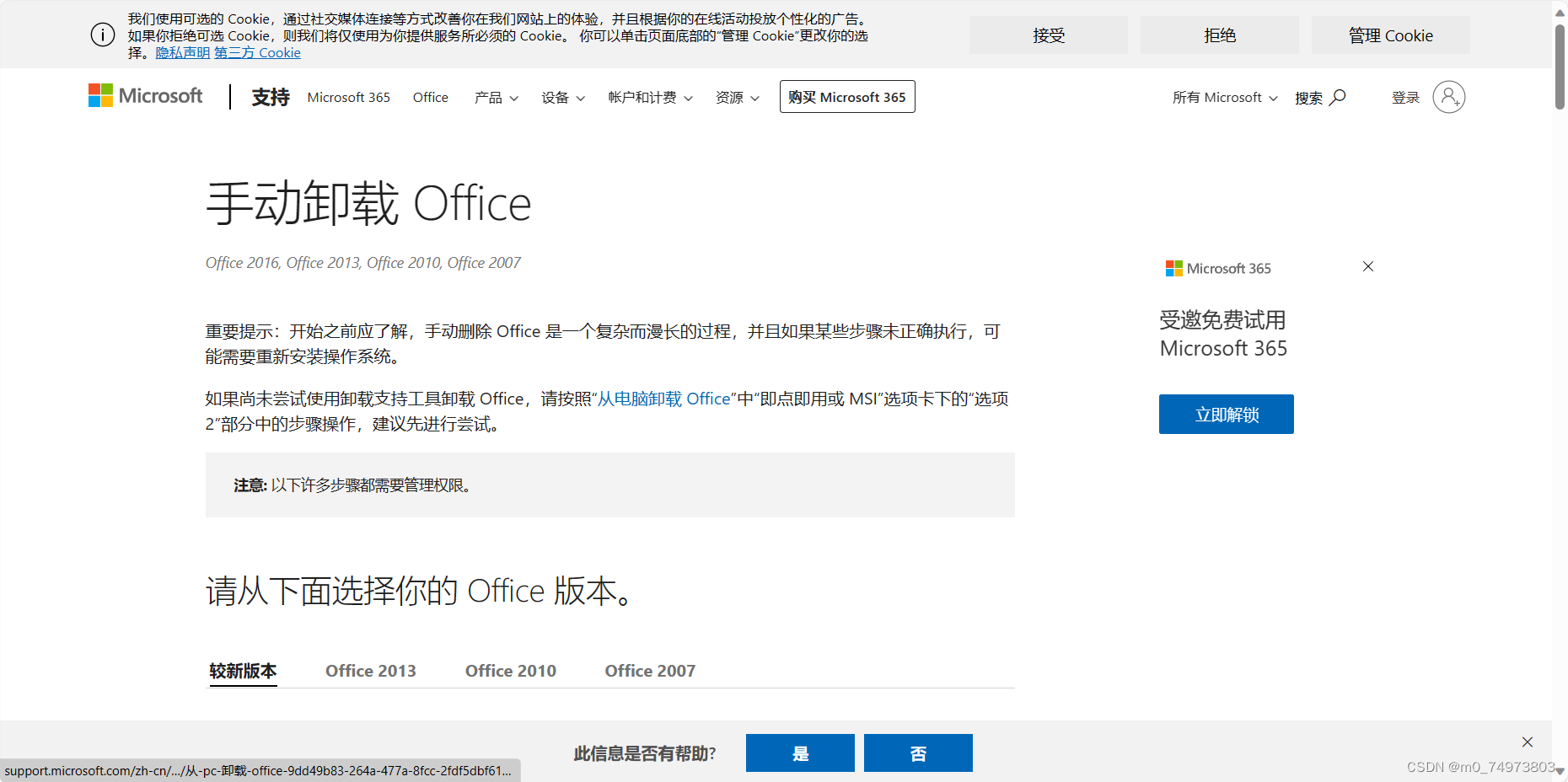
2. 一步步跟下来即可。以下是遇到的一些问题:
2.1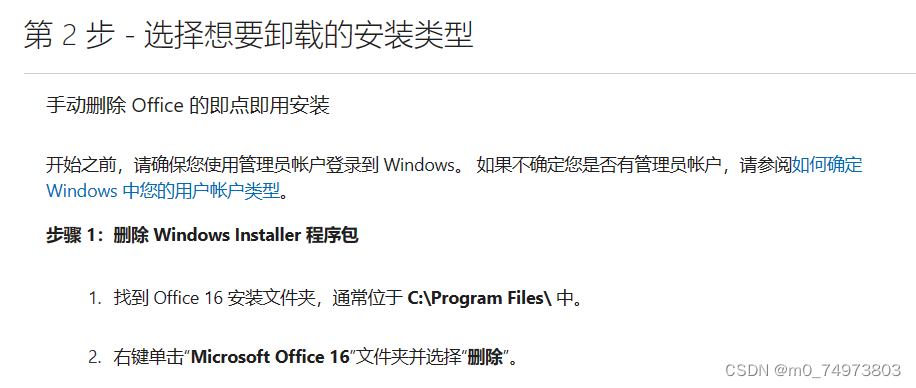
C:\Program Files\中没有“Microsoft Office 16”文件夹,有①“Microsoft Office”文件夹、②“Microsoft Office 2015”文件夹和③“Microsoft OfficePLUS”文件夹。我从PowerPoint快捷方式中找到安装目录应该是“Microsoft Office”文件夹,故删除。删除过程中多次出现删不干净情况,多重启电脑几次即可(重启后尽量不干别的,先删文件【】)。
2.2
“ClickToRun”文件夹删不掉,解决方法仍是重启电脑(此处Microsoft亦有讲解)。
2.3
注册表删除中,首先要做好备份工作(重要)。问题:步骤三中“HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall”目录下,没有“Microsoft Office <版本> - en-us”,且无法删除“HKEY_CURRENT_USER\Software\Microsoft\Office”目录,因为其中一项删不掉。上网查到以下解决方法:注册表编辑器删除时出错 (lw881.com)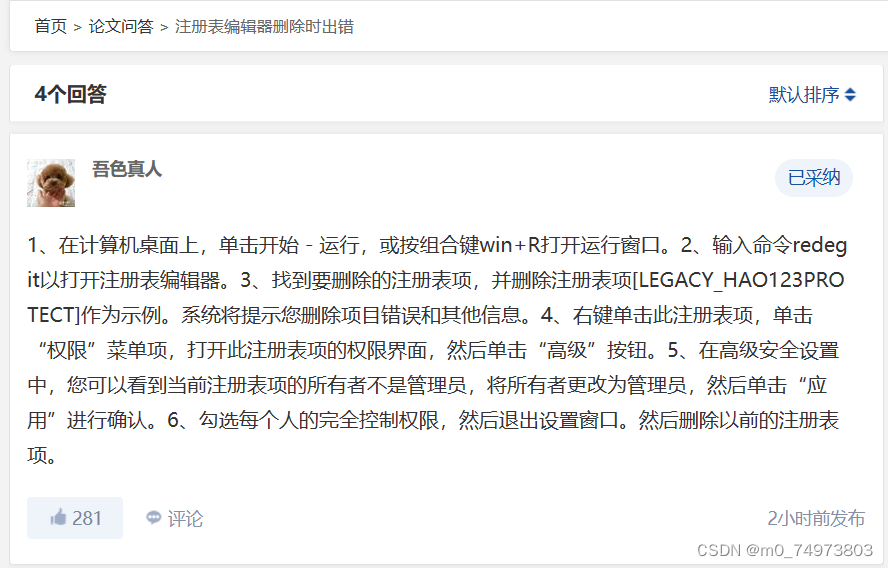
尝试解决,遇到如下问题:第6点不知道在哪勾选每个人的完全控制权限,最后在高级安全设置界面的提示下,找到是在双击“Everyone”后,勾选“完全控制”。
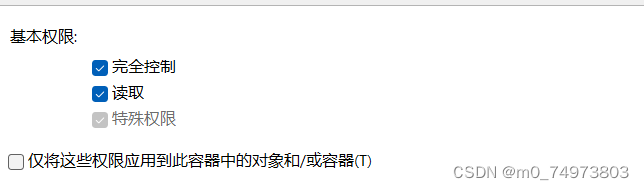
但是没用,双击“Everyone”后,将“Everyone”的类型改为允许。然后就可以删掉了。于是“Office”也删掉了。
剩下的也按照文章操作即可,至此,卸载完成。(虽然有点瑕疵)。
二、安装Office
按照说明,office完成新版Office的安装即可。其中的几个小问题:
1. iSlide好像不一定要装
2. 我选择的版本是2021,但安装过程中,突然有一刻某个提示框显示我即将安装的版本号是16.0.其他,我当时觉得不对,就点了取消,但好像并没有影响它的安装,它还在继续。
3.继续过程中,如果感觉Office安装的进度条长时间不动,其实可能是正常现象,一会儿之后就安装完成了,我差点因此将安装软件停止运行,幸好没有选择这样做,不然不知道又会发生啥。
三、结语
能跟着做下来我还挺厉害的。

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









