







 本文介绍了几种图像生成方法,包括VAE、基于流的模型和扩散模型(DDPM)。重点讲述了DDPM的加噪过程和稳定扩散模型在DALL-E和Imagen等应用中的工作原理,其中涉及到文本编码器和噪声预测模块。在训练过程中,通过逐步加噪和反向预测来生成图像,而在推理时则通过减少噪声来恢复图像。
本文介绍了几种图像生成方法,包括VAE、基于流的模型和扩散模型(DDPM)。重点讲述了DDPM的加噪过程和稳定扩散模型在DALL-E和Imagen等应用中的工作原理,其中涉及到文本编码器和噪声预测模块。在训练过程中,通过逐步加噪和反向预测来生成图像,而在推理时则通过减少噪声来恢复图像。
一、几个图像生成方法:
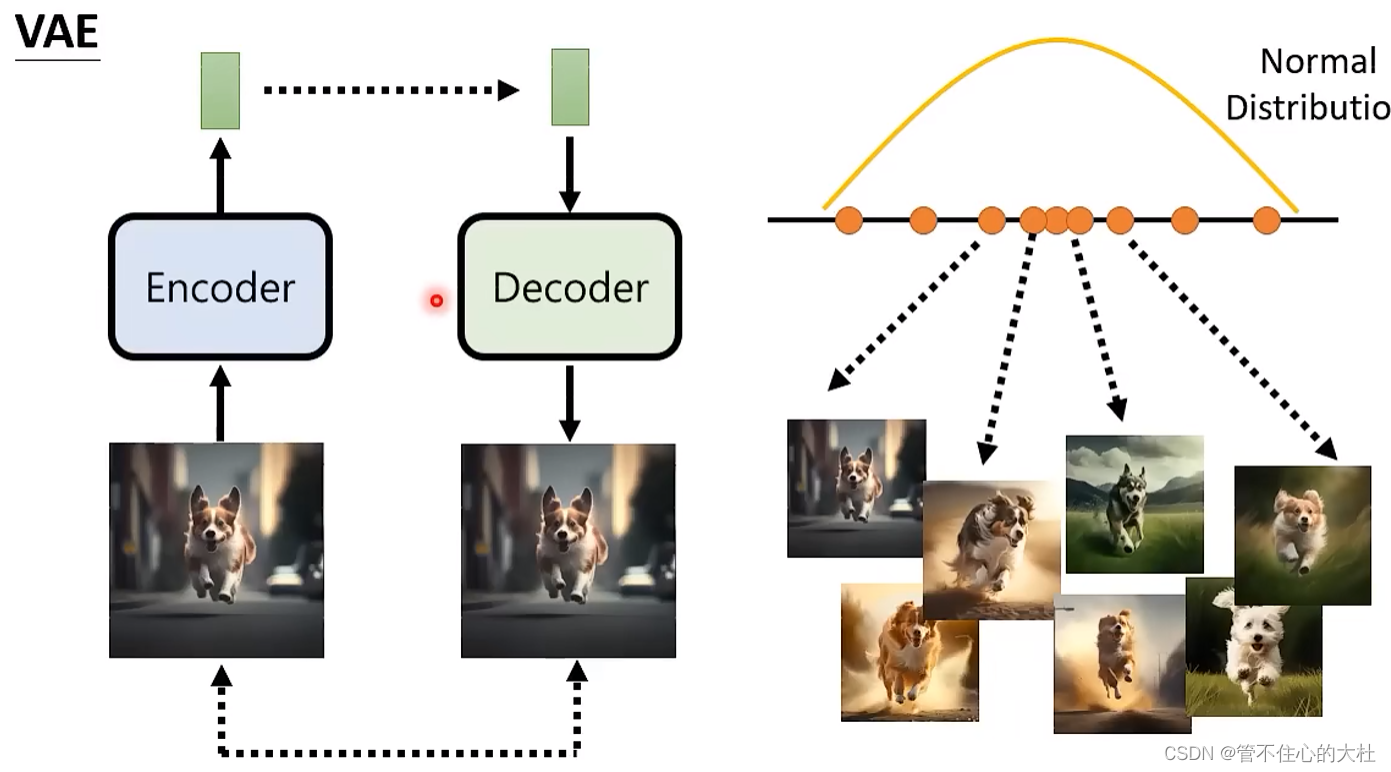
VAE:
类似于seq2seq
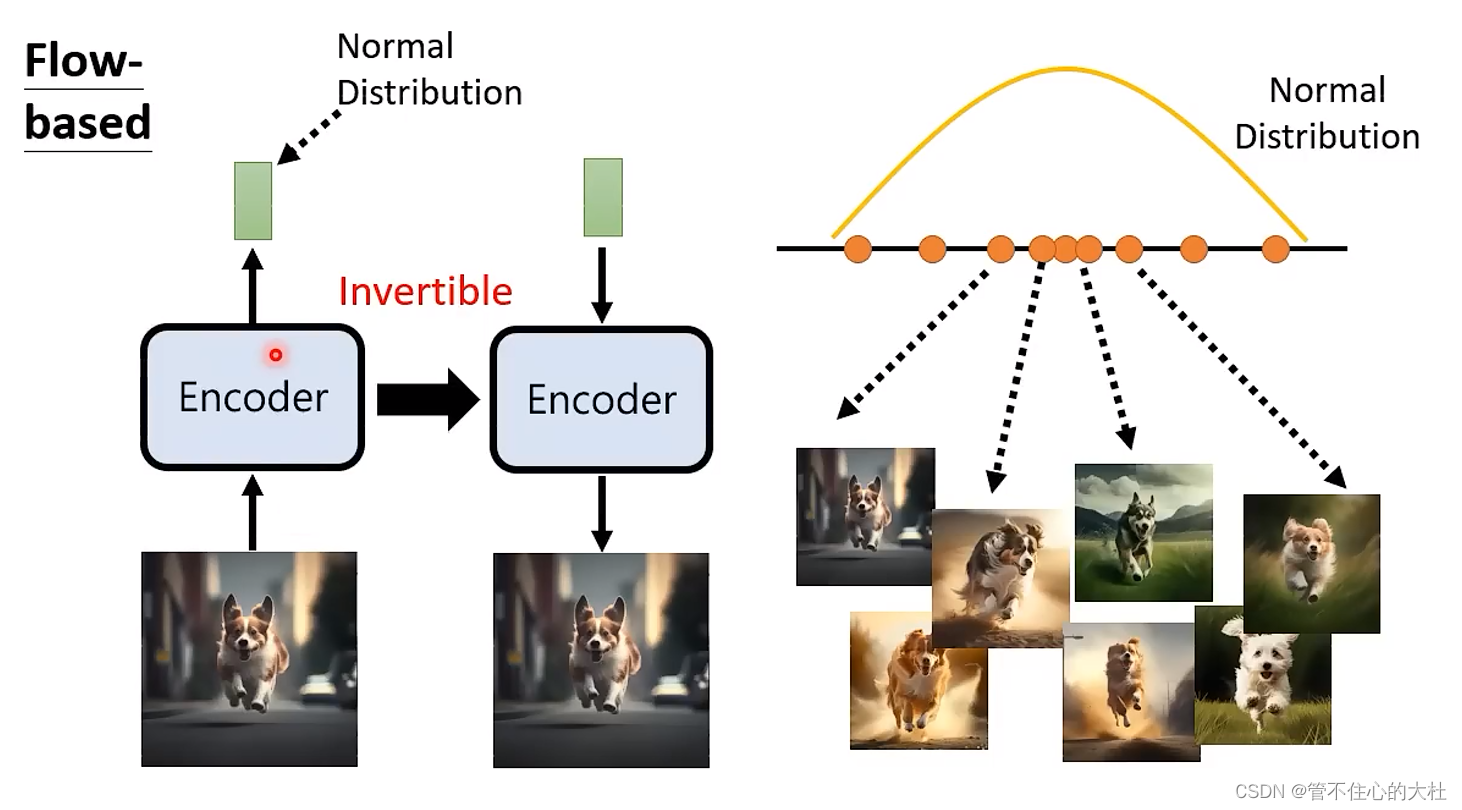
flow-based:
训练和推理方向相反。
为保证Encoder Invertible,Encoder输出的维度与输入图片维度相同,并且需要刻意限制架构。
 diffusion:
diffusion:
diffusion夹杂讯过程没有参数。

这些后面都可以增添一个GAN。
二、denoising diffusion probablistic model(DDPM)
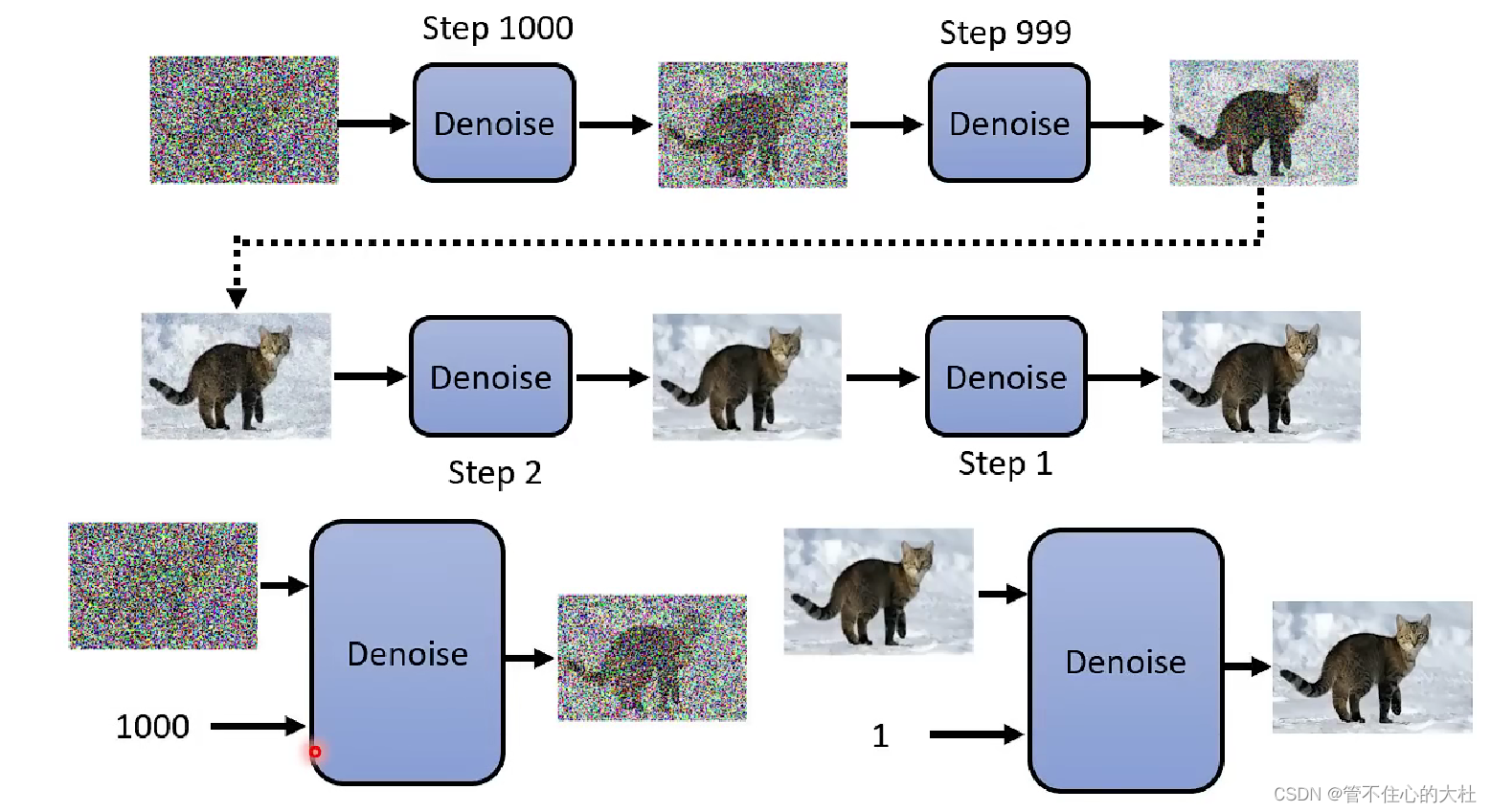
step在一开始就已经定好了,并且是将同一个module重复使用多次,但不同的是在不同的是需要输入当前step,代表现在noise的程度。
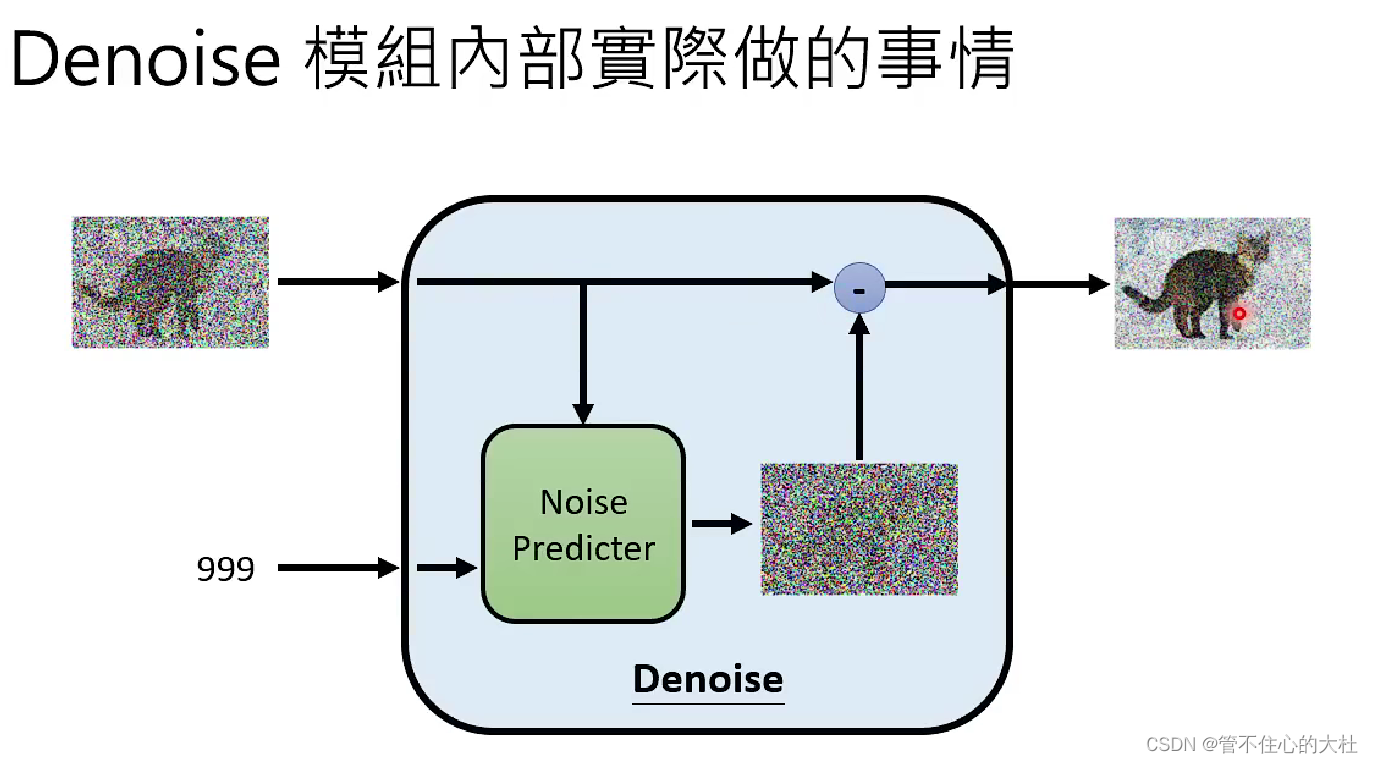
module内部根据当前step和输入图像预测杂讯,再用输入图像将其减去得到输出。这样折腾的原因是生成一张杂讯难度要比生成一张带杂讯的原图的难度小得多,如果一个module可以生成带杂讯的原图,那么其实它几乎也可以生成一张原图了。--------李宏毅
关于Predicter的训练我们需要前向的加噪过程,找到对应的步骤作为Ground Truth。
前向过程称为Forward Process,或者DIffusion Process。

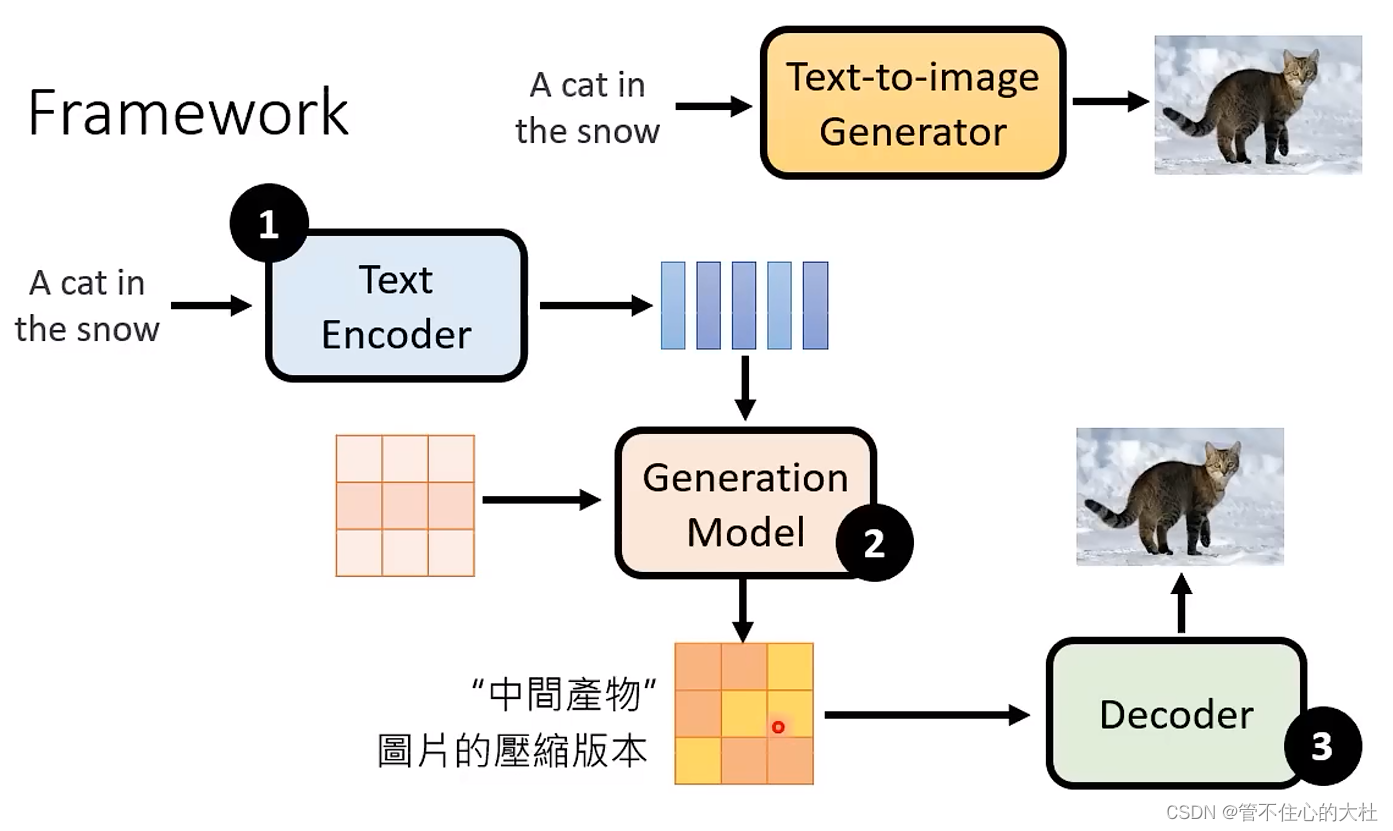
三、Stable Diffusion, DALL-E, Imagen共用套路
Text Encoder将文字变成向量
Generator吃杂讯和Encoder的产物得到一个图片的压缩版本,这个压缩版本可能能看懂可能看不懂
最后通过一个Decoder将图片由压缩版本还原。
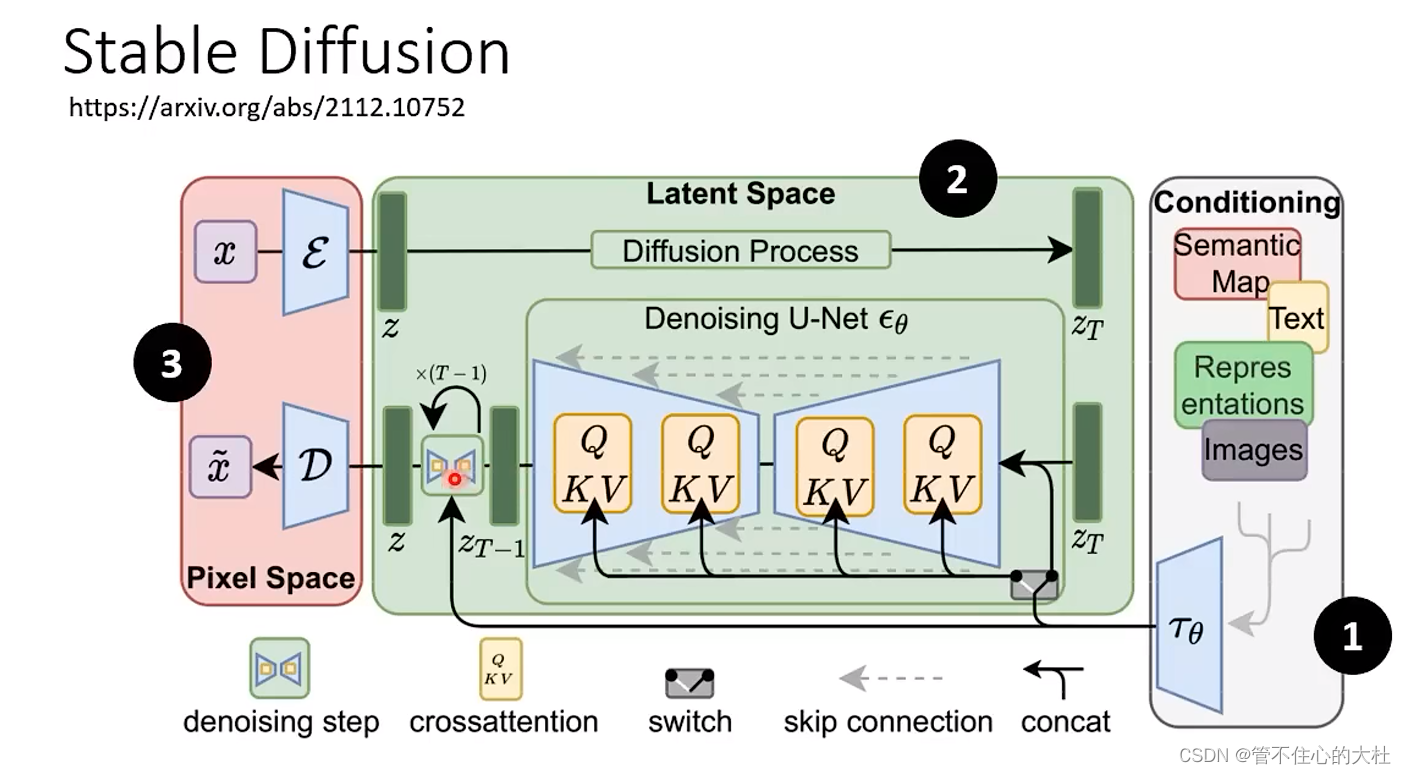
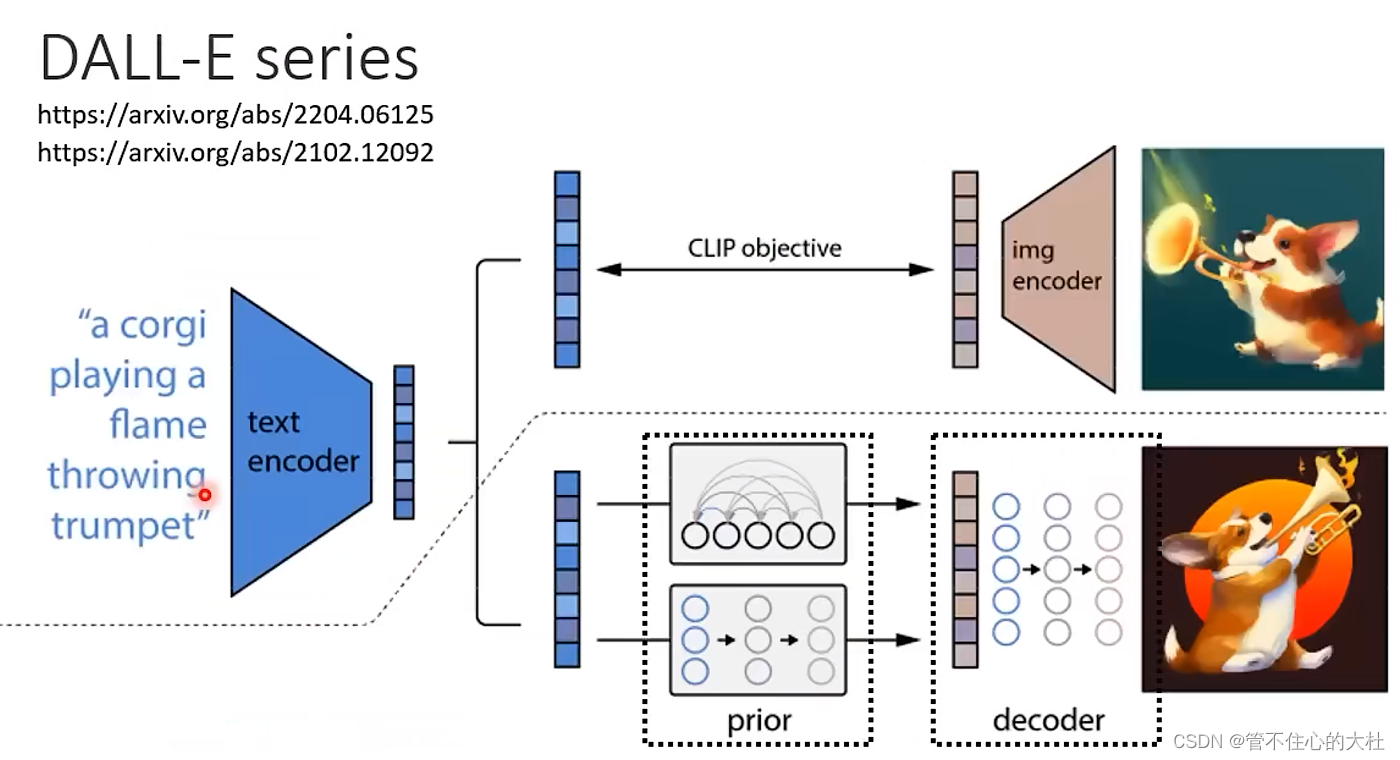
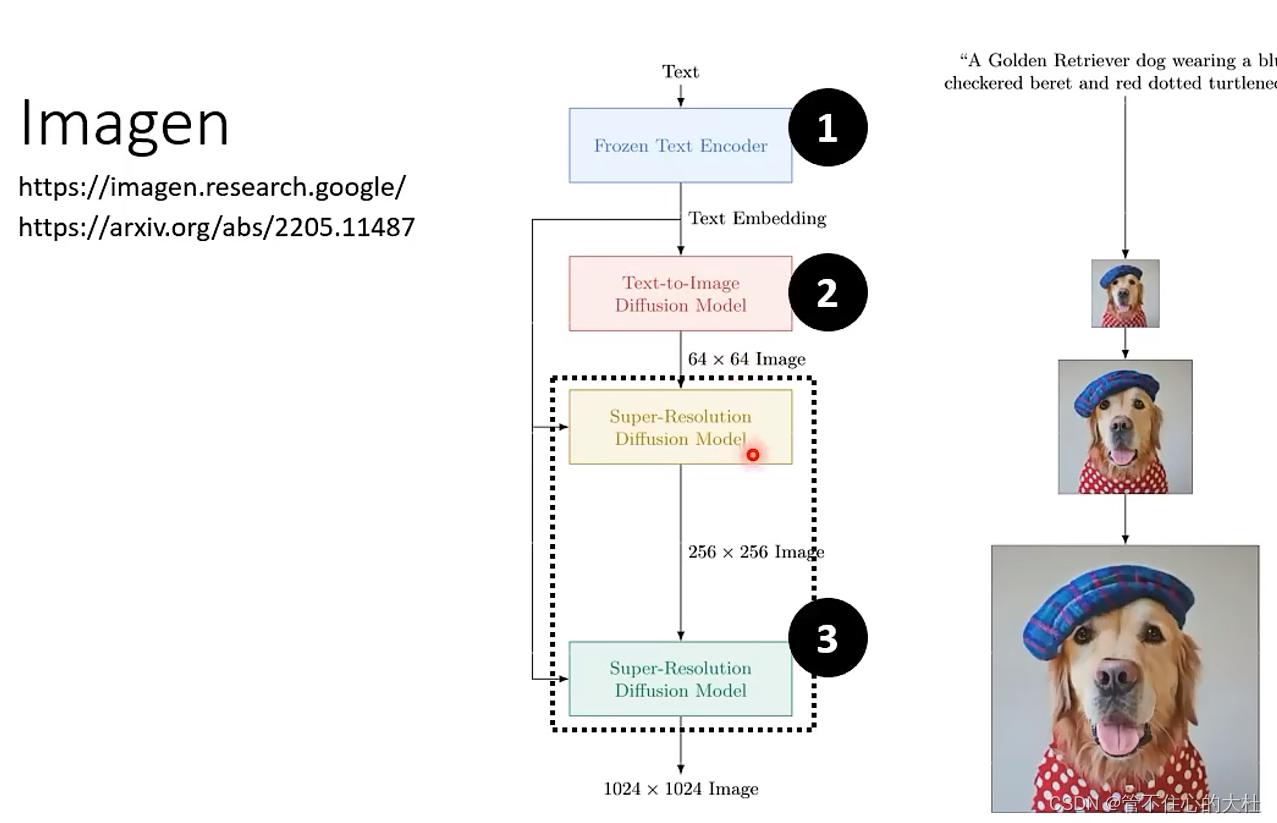
四、原理剖析
训练

1,6:一直重复,直到收敛
2:从数据集中选出一张照片作为x0
3:t代表step,T是总step数
4:产生一个正态分布ε ,ε大小和图像大小一样
5:
首先进行红色方框,就是加噪。加噪其实是是一个带权相加的过程,而不是每一个step加一点每一个step加一点的迭代。只需要在一开始给出所有step的权重â1,â2,...,âT,这些权重越来越小,既越往后的step原图X0的权重越小,噪音ε的权重越高。这里与第二节中的区别就是第二节中画的是一步一步逐渐加噪,这里是提前定好每一步加噪的权重,每一步都是单独的加噪。在下面这张图中叙述的很清晰。

其次进行噪音预测,就是εθ函数,如上所述红框的内容是加噪后的图片,那么将红框与step t喂给εθ这个Noise predictor就得到了预测的噪音。
然后计算真实噪音和预测噪音的MSELoss梯度下降。
推理
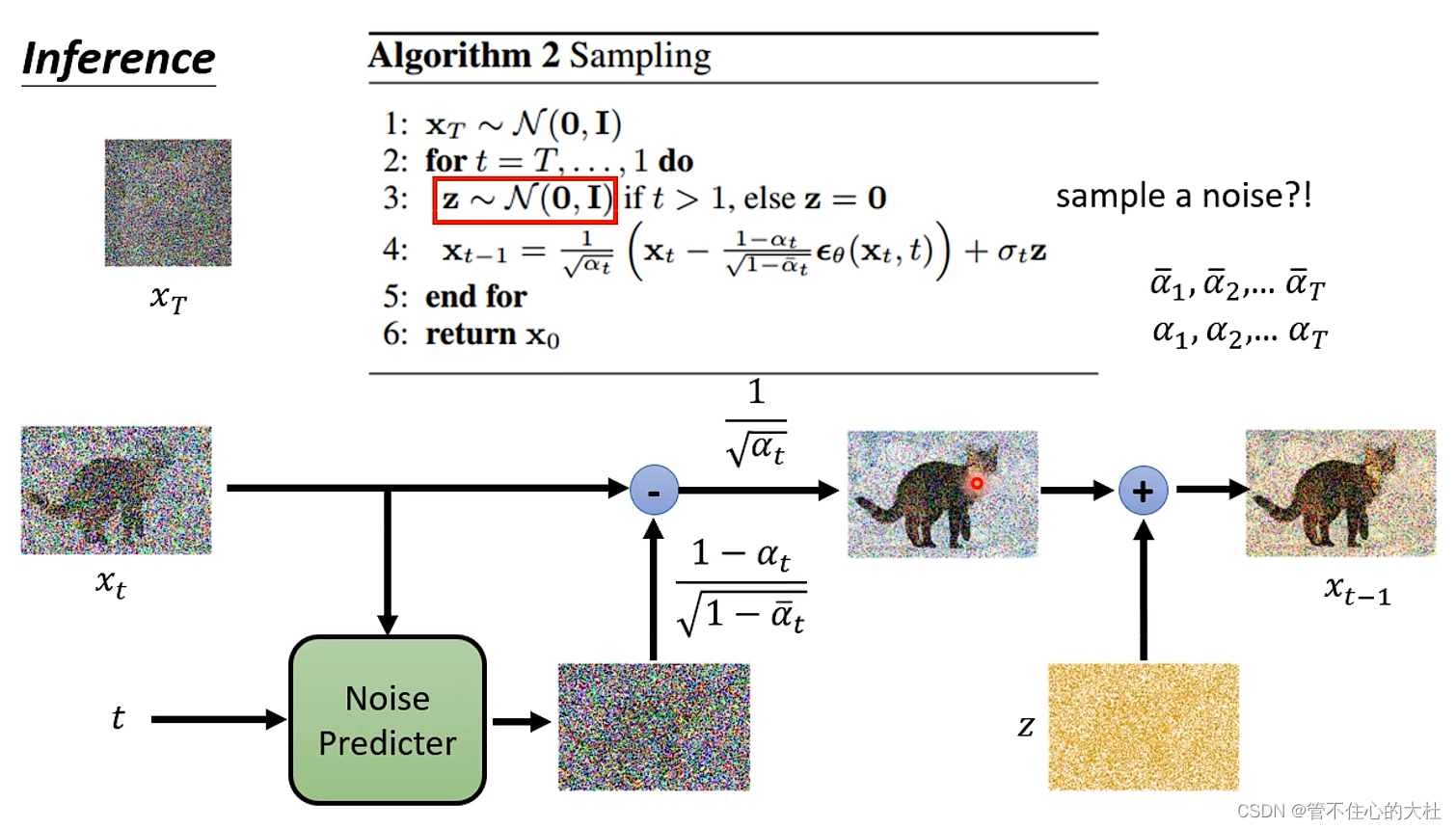
1:先生成一个服从正态分布的杂讯XT
2,5:for t in range(T,0,-1):
3:如果不是最后一步就再生成一个服从正态分布的杂讯z
4:Xt减去预测的杂讯得到杂讯更少的图片, 再加上Z。注意这里的α1,α2,...,αT也是提前给出的。
6:返回T次减少杂讯的图片X0。
关于为什么还要再加上一个杂讯z,李宏毅的解释是如果每一次都取最大概率,那么及其每一次输出都是重复的结果。
数学原理
目前看不懂。。。等我学会后再来补上。















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









