






概要
YOLOv4是一种用于目标检测的深度学习模型,它能够快速准确地检测图像或视频中的目标物体。本文将概述使用YOLOv4模型训练自己的数据集的过程。
首先,为了训练YOLOv4模型,我们需要一个包含目标物体的数据集。这个数据集应该包括标注了目标物体位置的图像,以及每个目标物体的类别标签。可以使用标注工具,如LabelImg或RectLabel,手动标注图像中目标物体的位置和类别。
接下来,我们需要将数据集划分为训练集和验证集,用于模型的训练和评估。通常,训练集占整个数据集的大部分,而验证集只占一小部分。这样可以确保模型在训练过程中不仅能够学习目标物体的特征,还能够泛化到未见过的数据。
在准备数据集之后,我们需要进行一些数据增强操作,以增加训练数据的多样性。常见的数据增强操作包括随机缩放、随机裁剪、随机旋转和图像翻转等。这些操作可以帮助模型更好地适应不同尺寸和角度的目标物体。
接下来,我们需要根据YOLOv4模型的要求对数据集进行预处理。首先,我们需要将图像转换为模型输入所需的尺寸。通常,YOLOv4模型要求输入图像为416x416或者608x608大小。其次,我们需要将图像转换为模型能够处理的张量格式,如RGB图像或灰度图像。
然后,我们可以使用YOLOv4的训练脚本进行模型的训练。在训练过程中,模型将根据损失函数来调整权重和偏置,以最小化目标检测的误差。训练过程可能需要较长的时间,具体取决于数据集的大小和计算资源的限制。
在完成模型训练后,我们可以使用验证集对模型进行评估,计算其在目标检测任务上的性能指标,如精度、召回率和F1分数等。根据评估结果,我们可以对模型进行调优或者选择最佳的模型进行应用。
总结而言,使用YOLOv4模型训练自己的数据集需要完成以下步骤:准备数据集,划分训练集和验证集,进行数据增强操作,对数据集进行预处理,使用训练脚本进行模型训练,评估模型性能,根据评估结果调优模型。这些步骤将帮助我们构建一个能够快速准确检测目标物体的YOLOv4模型。
整体架构流程
训练自己的数据集使用YOLOv4的整体架构流程如下:
-
数据准备:
- 收集和标注图像数据集,确保每个对象都添加正确的边界框和类别标签。
- 将标注数据转换为YOLOv4所需的格式,通常为.txt文件,每个文件包含一行的标注信息,包括类别标签和边界框的坐标。
-
模型配置:
- 下载YOLOv4的权重文件,可以从官方GitHub仓库或其他可信源获取。
- 配置YOLOv4的参数,包括类别数量、输入图像的大小、训练批次大小、学习率、训练迭代次数等。
-
模型训练:
- 在训练之前,将数据集分为训练集和验证集,通常采用80%的数据作为训练集,20%的数据作为验证集。
- 利用划分的数据集,进行实际的模型训练。可以使用预训练的权重文件作为初始模型,在训练过程中进行微调。训练过程中,通过计算损失函数来优化模型的参数。
-
模型评估:
- 使用训练好的模型对验证集数据进行预测,并计算预测结果与真实标签的匹配度,通常使用精确度、召回率、F1值等指标进行评估。
-
模型测试:
- 使用训练好的模型对新的图像数据进行预测,得到检测到的目标类别和位置信息。
-
模型优化:
- 根据评估和测试结果,对模型进行调整和优化,可能需要调整超参数、数据增强策略、网络结构等进行进一步训练。
-
使用模型:
- 训练完毕后,可以将模型部署到实际应用中,用于目标检测任务的实时预测。
技术名词解释
YOLOv4是一种目标检测算法,是YOLO(You Only Look Once)系列的第四个版本。它使用深度学习技术,特别是卷积神经网络(CNN),来实现实时物体检测。
以下是一些与YOLOv4训练自己的数据集相关的技术名词的解释:
-
目标检测(Object Detection):是计算机视觉领域的一个任务,旨在识别图像或视频中的物体并确定其位置。
-
数据集(Dataset):是用于训练和评估机器学习模型的数据的集合。自己的数据集指的是用户自己收集和准备的数据集。
-
标注(Annotation):在目标检测任务中,标注是将训练图像中的目标对象位置标记出来,以便算法可以学习识别这些目标。常用的标注方式有边界框标注和像素级标注。
-
标签(Label):在目标检测中,标签是指给定图像中目标对象的类别信息。每个目标都有一个类别标签。
-
VOC数据集(Common Objects in Context):是一个广泛使用的目标检测和图像分割数据集,包含80个常见的物体类别。
-
迁移学习(Transfer Learning):是一种训练模型的技术,它使用在一个任务上训练好的模型来初始化另一个相关的任务的模型。在YOLOv4的训练中,可以使用预训练的权重来加速模型的收敛。
-
数据增强(Data Augmentation):是通过对原始数据进行变换和扩充来增加数据集的多样性和数量。常用的数据增强方法包括随机裁剪、旋转、翻转、缩放等。
-
GPU(Graphics Processing Unit):是一种专门用于图形渲染和加速复杂计算的硬件设备。在深度学习中,使用GPU可以加快模型的训练速度。
-
迭代次数(Epoch):是指训练过程中整个数据集被完整地使用一次的次数。每个迭代周期中会对数据进行一次前向传播和反向传播。
-
损失函数(Loss Function):是用于衡量模型预测结果与真实标签之间差异的函数。在YOLOv4中,常用的损失函数是目标检测任务中常用的交叉熵损失和均方差损失。
这些技术名词解释可以帮助理解YOLOv4训练自己的数据集过程中涉及的相关概念和步骤。
技术细节
训练YOLOv4模型来处理自己的数据集涉及以下几个技术细节:
-
数据准备:首先,需要准备训练数据集,包括图像和对应的标注信息。标注信息可以使用常见的标注工具如labelImg来创建,通常以XML或JSON格式保存。标注信息应包含目标类别和边界框坐标。
-
数据扩增:数据扩增是提高模型性能的常见手段之一。可以使用数据增强工具,如OpenCV,对图像进行旋转、翻转、缩放、色彩调整等操作,以扩充数据集。
-
数据划分:将整个数据集划分为训练集和验证集。通常将数据集的80%用于训练,20%用于验证模型的性能。
-
配置文件:YOLOv4模型使用的是Darknet框架,需要创建一个配置文件来定义模型的架构和训练的超参数。配置文件通常包含网络结构、训练参数和数据集路径等信息。
-
权重初始化:可以使用预训练的Darknet权重来初始化YOLOv4模型,以加快训练过程。预训练权重可以从https://github.com/AlexeyAB/darknet/releases下载。
-
模型训练:使用配置文件和训练数据集开始训练模型。训练过程通常包括多轮迭代,每轮迭代中会进行前向传播、损失计算、反向传播和参数更新等步骤。
-
模型评估:在每个训练步骤结束后,可以使用验证集评估模型的性能。评估指标通常包括精度、召回率、平均精度均值(mAP)等。
-
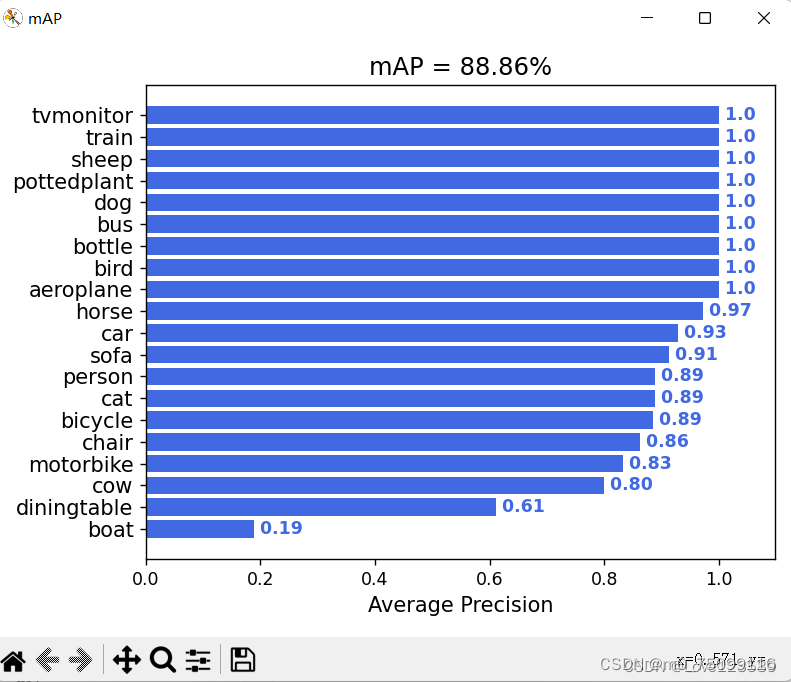
-
参数调优:根据模型的性能表现,可以调整训练超参数,如学习率、批量大小、迭代次数等,以进一步优化模型的性能。
-
模型测试:在模型训练完成后,可以使用测试集对模型进行最终评估。可以使用训练好的模型进行目标检测,并计算评估指标。
-

以上是训练YOLOv4模型使用自己数据集的一般技术细节。具体的步骤可能会根据数据集的不同而有所调整。
小结
训练自己的数据集需要准备好数据、转换数据格式、修改配置文件、进行模型训练、模型评估和模型调优等步骤。通过不断的训练和优化,可以得到一个适应自己数据集的YOLOv4模型,从而实现目标检测的功能。















 5512
5512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









