






遇到问题
我们在写文档或者代码时,会遇到需要书写重复或者类似内容的情况。快捷的做法是:先复制粘贴此相似内容,再修改差异。那么开发人员在设计界面的时候,也会遇到同类型的界面有重复的特性,比如报销类型的单据,都会有报销人员,所在部门,报销时间,报销说明等特性,我们是否也可以“复制粘贴”再去修改差异呢?
当我们“复制粘贴”并修改完差异后,发现有些重复内容需要修改,我们是否能只改一处,其它相似处就能全部自动修改呢?
如何解决问题
基于此问题,我们从设计界面的角度去思考。我们可以创建一个数据库表,存放这些共有的特性,又能保证此数据库表可以被复制,增加和修改字段。以此数据库表作为实体创建界面,界面也可以被复制,增加,修改字段,即在一个公用的模板基础上扩展出特有的界面。
inBuilder考虑到这一情况,推出了按场景定制界面功能,把共用的特性创建在数据库表中,比如报销类单据,公有特性有:报销人员,人员所在单位,报销金额等,作为公有实体,以此实体创建公有界面;不同报销类型的单据,又存在差异,比如交通费报销单,会有交通工具,交通费用产生日等,通讯费会有报销月份,按场景对扩展出来的表单进行定制开发。
举例说明
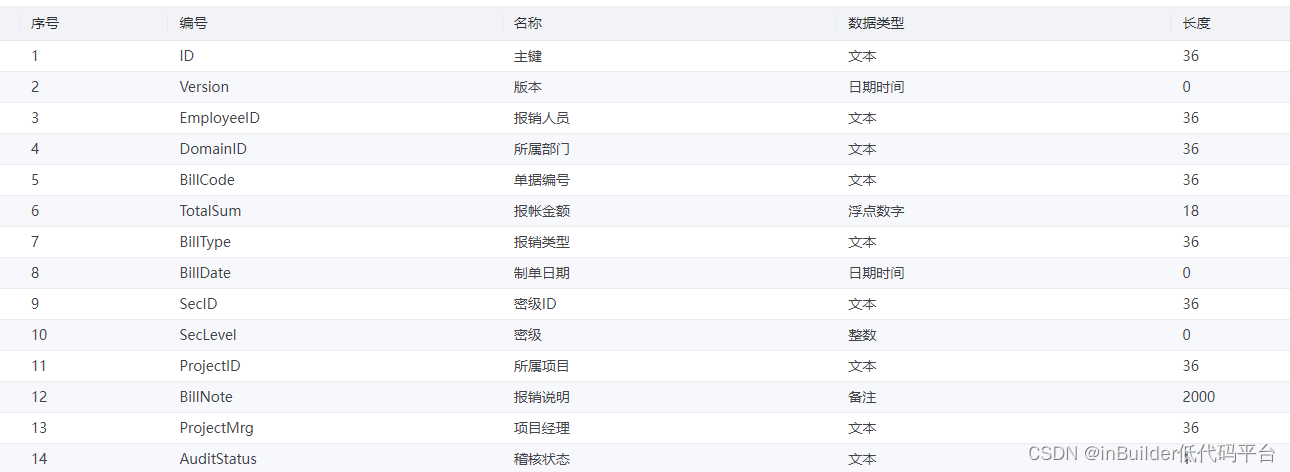
以网上报销费用为例,大概的介绍一下我们的功能,提取报销类型单据的共有部分,设计其报销费用的数据库表,即为实体,部分实体数据如图1,以此实体创建一个基础公有界面。
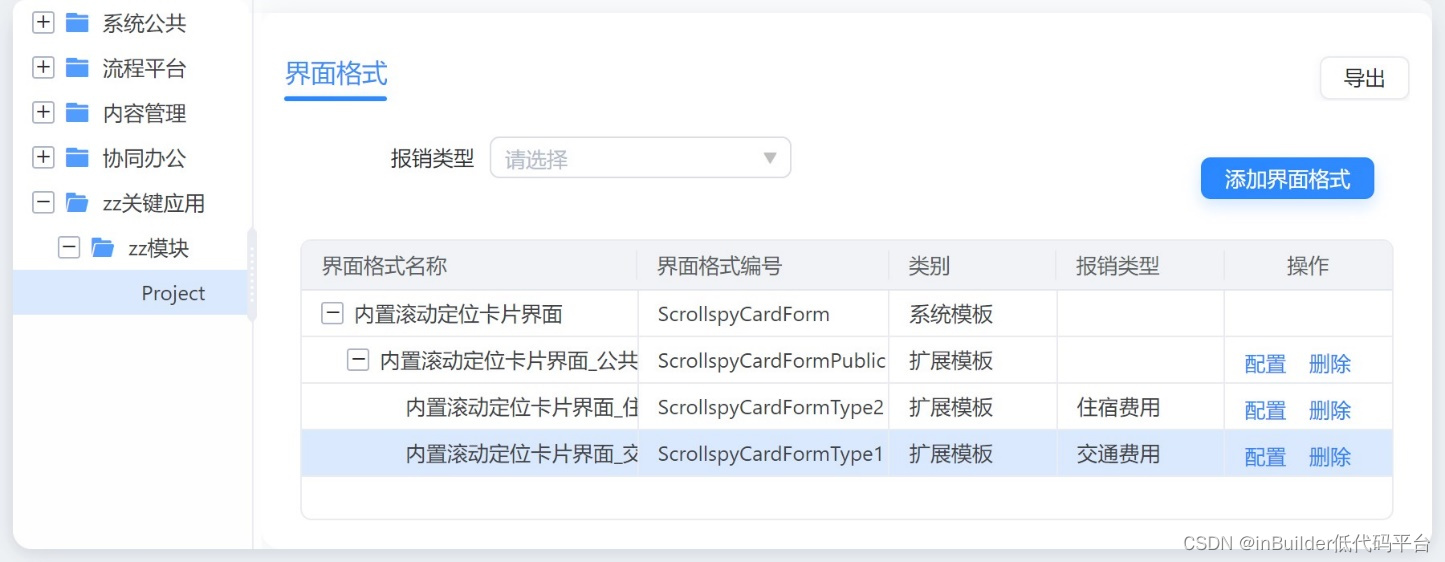
开启界面和实体的允许扩展按钮后,在业务配置中心按照报销类型进行定制化配置,如图2,按报销类型不同,生成两个扩展模板。
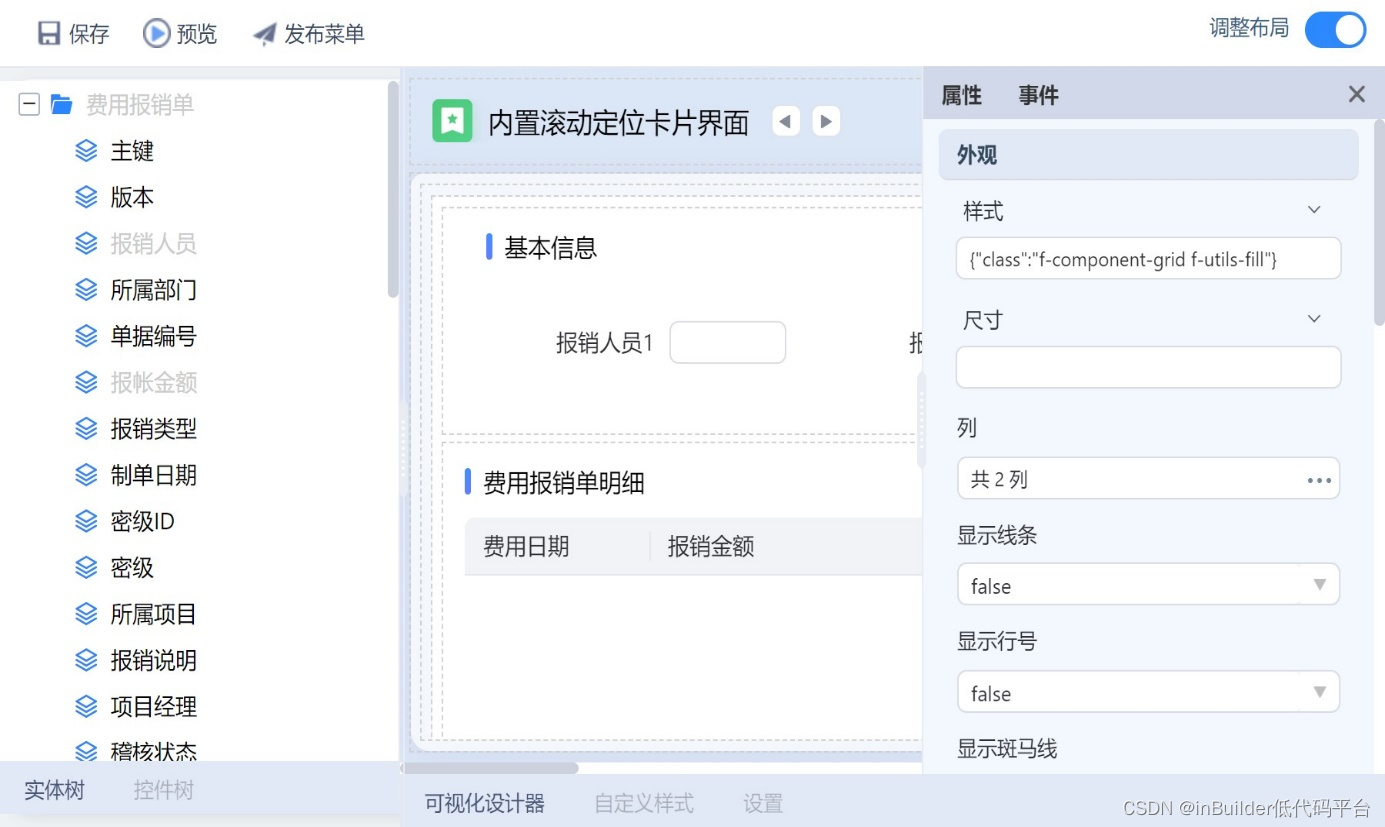
之后打开不同报销类型的扩展表单分别进行配置,配置界面如图3,可以在此界面进行布局修改,是否显示公有表单原有的字段,增加修改字段等操作,按场景定制界面。
总结
按场景定制界面这一功能的推出,能够为用户提供便捷,高效的设计体验。这个功能的加入,不仅能降低用户处理冗余工作,又能帮助用户系统结构化应对复杂业务挑战。
写在最后,欢迎大家下载我们的inBuidler低代码平台开源社区版,可免费下载使用,加入我们,开启开发之旅!

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









