







问题描述:
使用Pandas库,DataFrame.apply()方法设置列数据格式,在回调函数中将int类型转为str类型。Pandas发出警告。这个警告不影响结果,类型转换成功了,就是看着不爽
测试代码:
import pandas as pd
import numpy as np
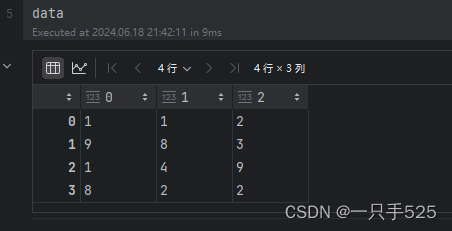
data = pd.DataFrame(np.random.randint(1, 10, size=(4, 3)))
def convert(df):
df[1] = (df[1]+10).astype(str)
df[2] = float(df[2] + 100)
return df
data = data.apply(lambda df: convert(df), axis=1)
data[1].infodata结构:
运行结果
只是发出警告,并不影响运行结果。
FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '11' has dtype incompatible with int32, please explicitly cast to a compatible dtype first.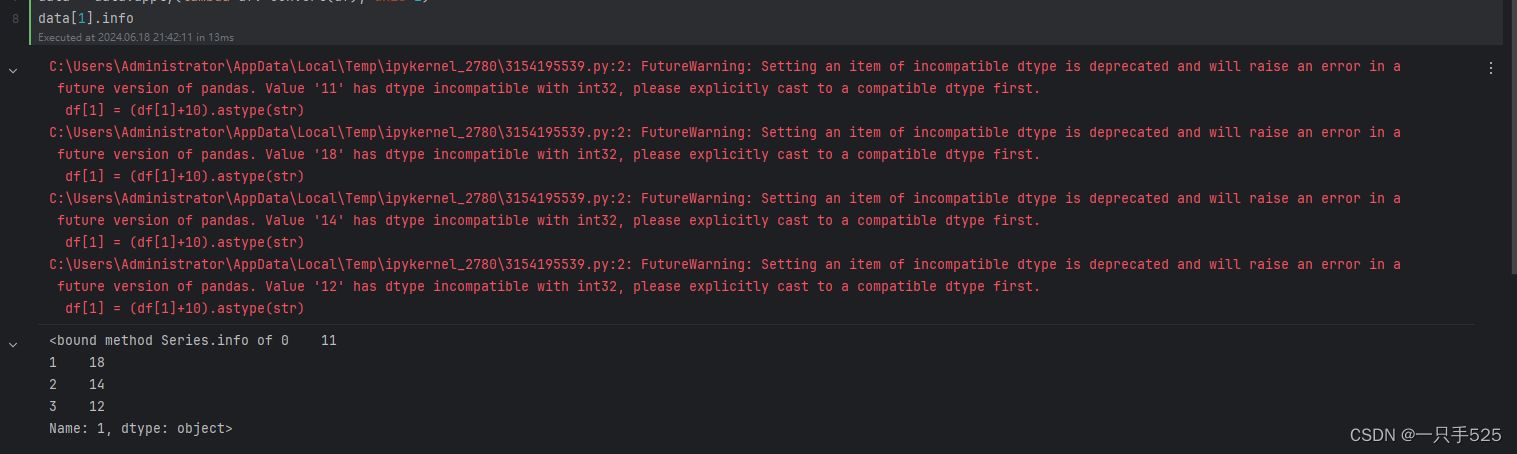
解决方法
不在convert()中转换,在apply()执行完后进行转换
完整代码
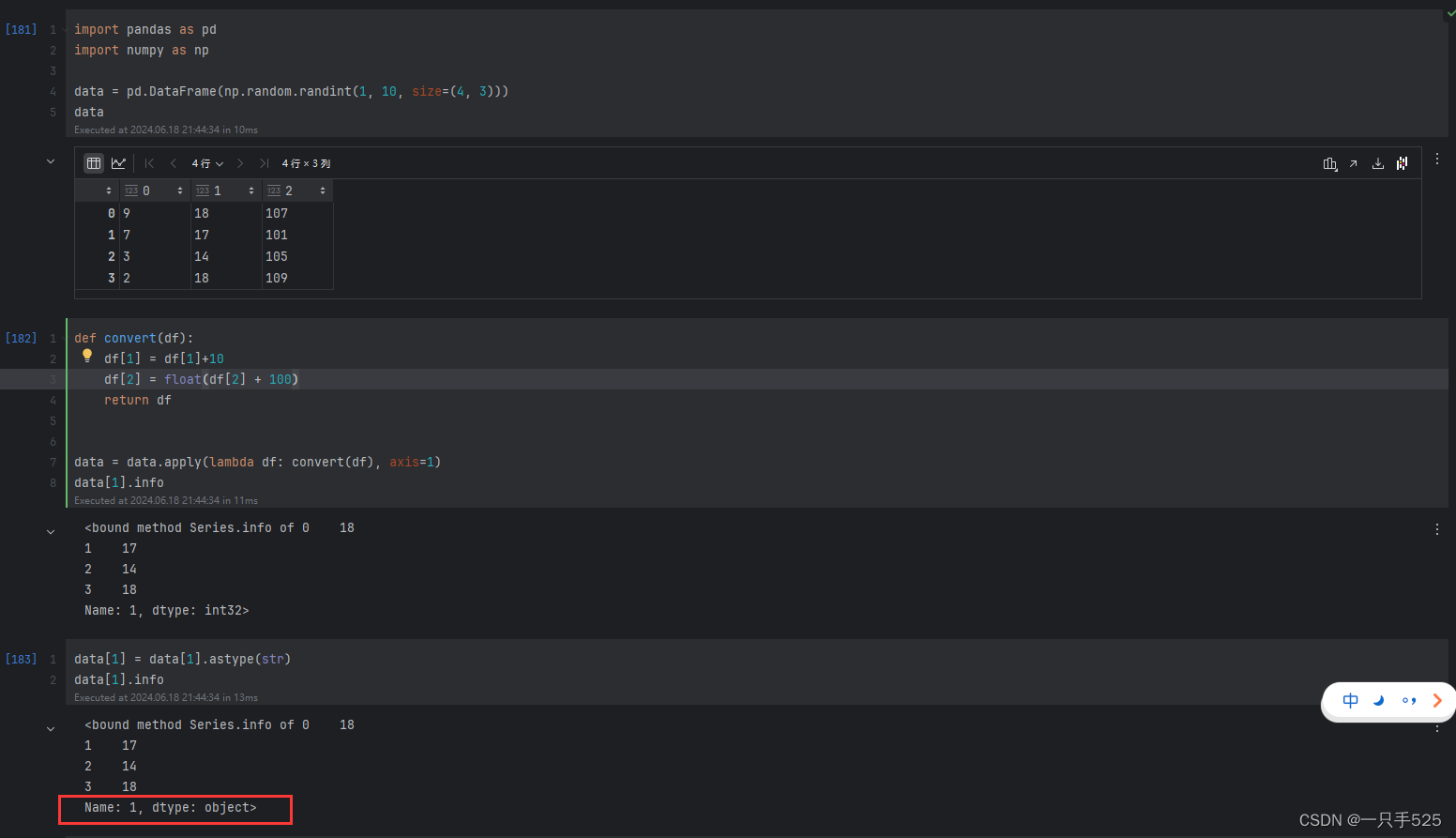
import pandas as pd
import numpy as np
data = pd.DataFrame(np.random.randint(1, 10, size=(4, 3)))
def convert(df):
df[1] = df[1]+10
df[2] = float(df[2] + 100)
return df
data = data.apply(lambda df: convert(df), axis=1)
data[1] = data[1].astype(str)运行结果

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









