






CNN FPGA加速器实现(小型)CNN FPGA加速器实现(小型)
通过本工程可以学习深度学习cnn算法从软件到硬件fpga的部署。
网络软件部分基于tf2实现,通过python导出权值,硬件部分verilog实现,纯手写代码,可读性高,高度参数化配置,可以针对速度或面积要求设置不同加速效果。
参数量化后存储在片上ram,基于vivado开发。
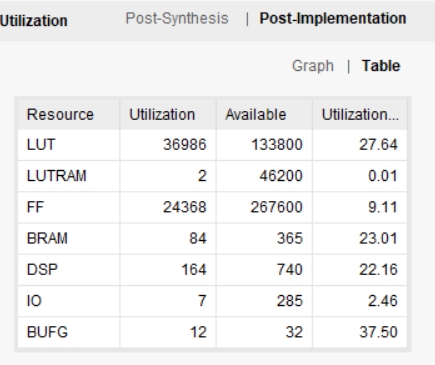
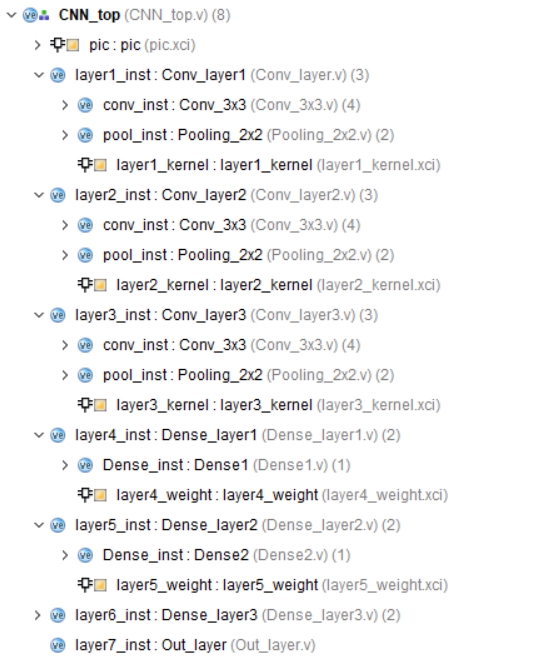
图一为工程结构图,提供基础的testbench,加速器输入存在ram上,图二为在artix7 fpga xc7a200t所占资源(资源和速度互相折中,可以用更多的资源换速度,也可以降速度减少资源消耗)。
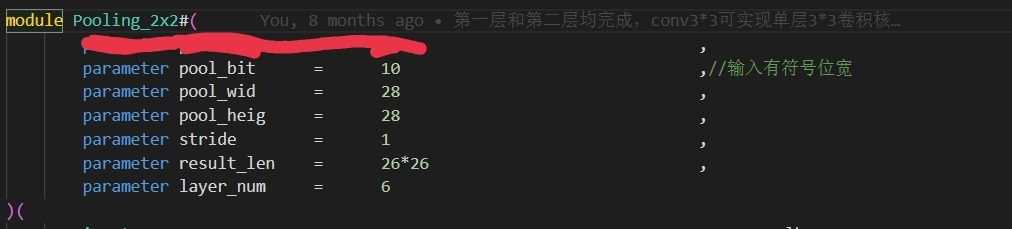
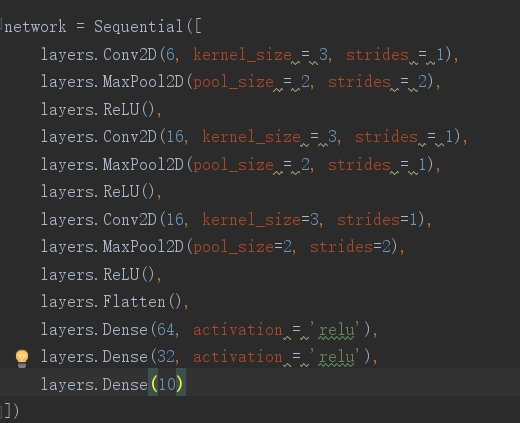
图三为网络结构图,demo所实现输入为28*28*1,图四五为卷积层和池化层可配置部分。
单张图片推理时间50us左右
提供本项目实现中所用的所有软件( python)和硬件代码( verilog)。
ID:52300624043661539
云赐记

标题:小型CNN FPGA加速器的实现
摘要:本文介绍了一种小型CNN FPGA加速器的实现方法,通过软件到硬件的部署,可以加速深度学习算法。该加速器使用纯手写的Verilog代码,具有高可读性和高度参数化配置,可以根据速度或面积要求进行不同的加速效果设置。本文还提供了工程结构图、基础测试用例和网络结构图等相关内容。
关键词:CNN、FPGA、加速器、硬件部署、Verilog代码、参数化配置
-
引言
深度学习算法在计算机视觉、语音识别等领域取得了显著的成果,但其复杂的计算任务对计算资源的要求也越来越高。为了提高深度学习算法的执行效率,本文提出了一种基于FPGA的小型CNN加速器的实现方法。 -
系统结构
本文设计的小型CNN FPGA加速器采用了软硬件协同设计的方式,在软件部分使用TensorFlow 2实现深度学习算法,并通过Python将权值导出。硬件部分则采用纯手写的Verilog代码实现,具有高可读性和高度参数化配置的特点。该加速器的硬件部分基于Vivado进行开发。 -
工程结构图
根据图一所示的工程结构图,本文提供了基础的testbench,加速器的输入存储在片上RAM中。图二展示了在Artix 7 FPGA XC7A200T上的资源占用情况,可以根据实际需求对资源和速度进行折中的配置。 -
网络结构
本文所实现的小型CNN加速器的网络结构如图三所示,输入尺寸为28x28x1。图四和图五展示了卷积层和池化层可配置的部分,可以根据具体的应用需求进行参数设置。 -
性能评估
通过实验测量,本文提供了在该小型CNN加速器上的单张图片推理时间约为50us。这一性能指标可以为用户提供参考,根据实际应用需求进行性能优化。 -
代码资源
为了帮助读者更好地理解和实现该小型CNN FPGA加速器,本文提供了所使用的软件(Python)和硬件代码(Verilog)。 -
总结
本文介绍了一种小型CNN FPGA加速器的实现方法,通过软件到硬件的部署,可以加速深度学习算法。该加速器采用纯手写的Verilog代码实现,具有高可读性和高度参数化配置的特点。通过实验测量,本文还展示了该加速器在单张图片推理时间方面的表现。希望本文的介绍能够对读者在深度学习算法加速方面提供帮助和启示。
参考资料
- 无
注意:本文所提供的软件代码和硬件代码仅供学习和参考使用,请勿用于商业用途。
相关代码 程序地址:http://nodep.cn/624043661539.html















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









