










〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
简介
olmOCR,这是一个高性能工具包,旨在将 PDF 和文档图像转换为干净、结构化的纯文本。
olmOCR的主要特点包括:
高精度文本提取:经过大量多样化PDF内容的训练,采用独特的提示技术,显著提高文本识别的准确性,减少误识别和幻觉现象。
复杂文档处理能力:不仅支持普通文本,还能准确识别和处理表格、公式、手写内容等复杂元素。
高效大规模处理:利用SGLang优化推理管道,可在本地GPU上运行,或通过AWS S3实现多节点并行处理,每百万页文档的处理成本仅190美元左右,适合处理海量文档。
开源与可扩展性:采用Apache 2.0许可,所有组件,包括模型权重、数据和训练代码,均已开源,方便用户二次开发与定制。
代码地址:https://github.com/allenai/olmocr
演示地址:https://olmocr.allenai.org/
引言
PDF文档有潜力提供数以万亿计的新颖、高质量标记用于训练语言模型。然而,PDF文档种类繁多,格式和视觉布局各异,这对内容提取和表示提出了挑战。
PDF文档缺乏基本的结构化信息,如自然的阅读顺序;现有的OCR工具和模型在处理复杂布局和低质量扫描的文档时表现不佳;大规模处理PDF文档的成本高昂。
早期的OCR研究和第一个商业OCR工具的出现可以追溯到20世纪50年代。Tesseract的发布标志着高质量开源OCR工具的诞生。现有的PDF提取工具可以分为:基于管道的系统(如Grobid、VILA、PaperMage)和端到端模型(如Nougat、GOT Theory 2.0)。
方法概述:
olmOCR,一种用于将PDF文档转换为干净、线性化的纯文本的开源Python工具包。
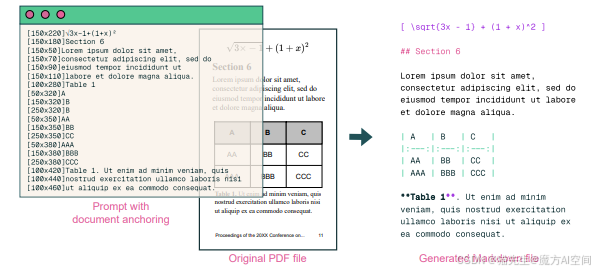
- DOCUMENT-ANCHORING技术:该技术从原生数字PDF文档中提取文本和布局信息。具体步骤包括使用PyPDF库提取PDF页面的结构和文本块,包括位置信息。然后,从最相关的文本块和图像中采样并添加到VLM的提示中,直到达到定义的最大字符限制。
- 模型微调:选择Qwen2-VL-7B-Instruct模型进行微调,以适应线性化任务。微调过程中,使用Hugging Face的transformers库进行实现,设置有效批大小为4,学习率为1e-6,AdamW优化器和余弦退火调度器进行10,000步训练。
- 数据集:使用olmOCR-mix-0225数据集进行训练,该数据集包含近260,000个PDF页面,涵盖了学术、宣传册、法律、表格、图表等多种文档类型。数据集通过从公共网站爬取的2.4亿个PDF文档中随机抽样生成。
实验设计
- 数据收集:从公共网站爬取的2.4亿个PDF文档中随机抽样生成100,000个PDF文档,并使用Lingua包过滤非英文文档和格式不正确的文档。还从互联网档案馆的公共领域书籍中抽样5,601个PDF文档。
- 实验设计:使用Qwen2-VL-7B-Instruct模型进行微调,训练过程中使用简化后的提示和结构化的JSON输出。训练数据集被截断为8,192个令牌,损失计算仅涉及最终响应令牌。
- 样本选择:从olmOCR-mix-0225数据集中随机选择20到50个文档,使用两种不同的方法进行处理,并将结果并排显示,以便进行手动对比评估。

- 参数配置:微调过程中,使用有效批大小为4,学习率为1e-6,AdamW优化器和余弦退火调度器进行10,000步训练。使用单个节点和8个NVIDIA H100 GPU进行训练。
结果与分析
- 与教师模型的对齐:olmOCR-7B-0225-preview与其教师模型GPT-4o的平均对齐得分为0.875,优于GPT-4o mini的0.833。
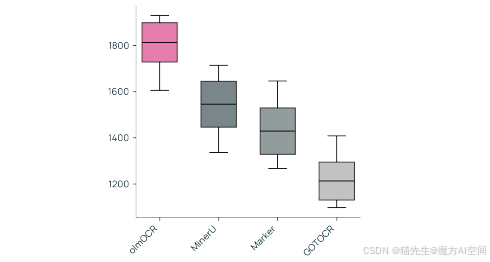
- 内部人类评估:通过2,017个新PDF文档的成对比较,olmMOCR的ELO评分超过1800,显著优于其他OCR工具。
- 下游评估:在OLMo-2-1124-7B模型的中期训练中,使用olmOCR提取的文本进行预训练,相比使用peS2o提取的文本,在多个核心基准任务上平均提高了1.3个百分点,特别是在ARC挑战赛和DROP任务上表现优异。
项目部署
1. 硬件要求
- NVIDIA GPU(在 RTX 4090、L40S、A100、H100 上测试),至少具有 20 GB 的 GPU RAM
- 30GB 可用磁盘空间
2. 安装依赖项 (Ubuntu/Debian)
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools3. conda 环境并安装 olmocr
conda create -n olmocr python=3.11
conda activate olmocr
git clone https://github.com/allenai/olmocr.git
cd olmocr
pip install -e .4. 如果要在 GPU 上运行推理,请安装带有flashinfer 的 sglang。
pip install sgl-kernel==0.0.3.post1 --force-reinstall --no-deps
pip install "sglang[all]==0.4.2" --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/5. 本地使用示例
# 转换单个 PDF:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
# 转换多个 PDF:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/*.pdf6. 多节点/集群使用
如果您想使用并行运行的多个节点转换数百万个 PDF,则 olmOCR 支持从 AWS S3 读取 PDF,并使用 AWS S3 输出存储桶协调工作。
例如,可以在您的第一个 Worker 节点上启动此命令,它将在您的 AWS 存储桶中设置一个简单的工作队列并开始转换 PDF。
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace --pdfs s3://my_s3_bucket/jakep/gnarly_pdfs/*.pdf现在,在任何后续节点上,只需运行此命令,它们就会开始从同一工作区队列中获取项目。
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace如果您使用的是 Ai2 并希望使用beaker有效地线性化数百万个 PDF,只需添加 --beaker。这将在本地计算机上准备工作区,然后在集群中启动 N 个 GPU 工作线程以启动 转换 PDF。
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace --pdfs s3://my_s3_bucket/jakep/gnarly_pdfs/*.pdf --beaker --beaker_gpus 4总结
olmOCR,一种用于将PDF文档转换为干净、线性化的纯文本的开源工具包。通过结合DOCUMENT-ANCHORING技术和微调的7B参数视觉语言模型,OLMOCR在成本效益上显著优于现有的商业解决方案。OLMOCR的高效推理管道和强大的鲁棒性使其能够处理数百万文档,解锁新的训练数据来源,特别是来自高质量PDF文档的数据。
推荐阅读
► AGI新时代的探索之旅:2025 AIGCmagic社区全新启航
► 技术专栏: 多模态大模型最新技术解读专栏|AI视频最新技术解读专栏|大模型基础入门系列专栏|视频内容理解技术专栏|从零走向AGI系列
► 技术资讯: 魔方AI新视界
► 技术综述:一文掌握视频扩散模型|YOLO系列的十年全面综述|人体视频生成技术:挑战、方法和见解|一文读懂多模态大模型(MLLM)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









