







Paper Title: olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
该论文发布于:CVPR2023
Github website: https://github.com/allenai/olmocr
Weights & Data: https://huggingface.co/collections/allenai/olmocr-67af8630b0062a25bf1b54a1
Demo website: olmOCR – Open-Source OCR for Accurate Document Conversion
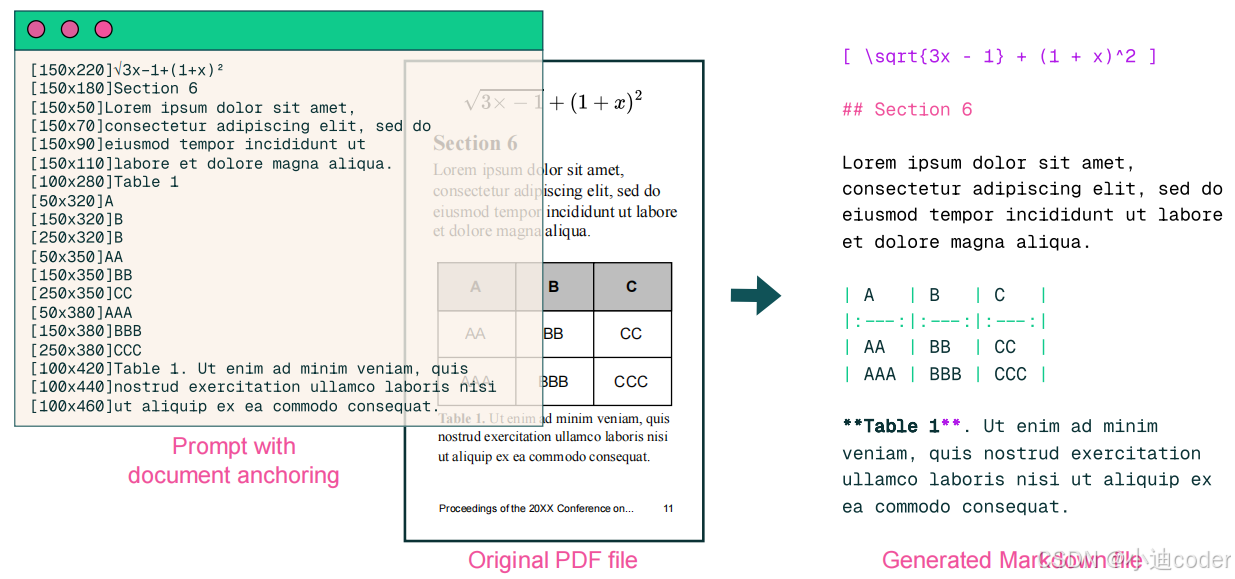
olmOCR是一个开源工具包,旨在高效地将PDF文档转换为干净的纯文本。该工具包结合了文档锚定(document-anchoring)技术
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









