




 BCNet是一种解决实例分割中遮挡问题的深度学习方法,通过解耦遮挡者和被遮挡者的mask预测,提高分割准确性。网络结构包含双层解码器,分别处理遮挡和被遮挡目标。实验表明,BCNet在边缘清晰度和整体性能上优于其他实例分割方法。
BCNet是一种解决实例分割中遮挡问题的深度学习方法,通过解耦遮挡者和被遮挡者的mask预测,提高分割准确性。网络结构包含双层解码器,分别处理遮挡和被遮挡目标。实验表明,BCNet在边缘清晰度和整体性能上优于其他实例分割方法。
参考代码:BCNet
1. 概述
导读:在这篇文章关注的是实例分割中mask的分割,在正常的场景下是可能存在2个或是多个物体存在重叠遮挡的,往往就会在物体像素相接的地方存在分割边界模糊以及分割不准确的问题。对于这样的现象文章将其归纳为如下原因:
1)原生的Mask RCNN只是在RoI区域进行前景mask分割,并不关心RoI区域中的其它目标的mask(统统为背景),也就是没有对这些mask也进行显式建模;
2)在后处理阶段一般采用非极大值抑制的策略对存在重叠的mask进行处理,这也必然会导致一些奇异现象的出现;
对此,文章将RoI中的mask进行解耦,也就是将当前RoI区域正常需要预测的mask和存在交叠的mask进行区分,也就是对应文章中提到的occluder和occludee,从而构造了一个2层解码的mask预测网络BCNet(Bilayer Convolutional Network)。在这两层的结构中分别去预测occluder和occludee从而实现两者显式建模和解耦。
对于存在遮挡的的mask预测的例子(见下图),使用文章的方法会将occluder和occludee分别使用两个mask预测层进行编码,之后再将两个层的结果融合起来得到最后的结果。

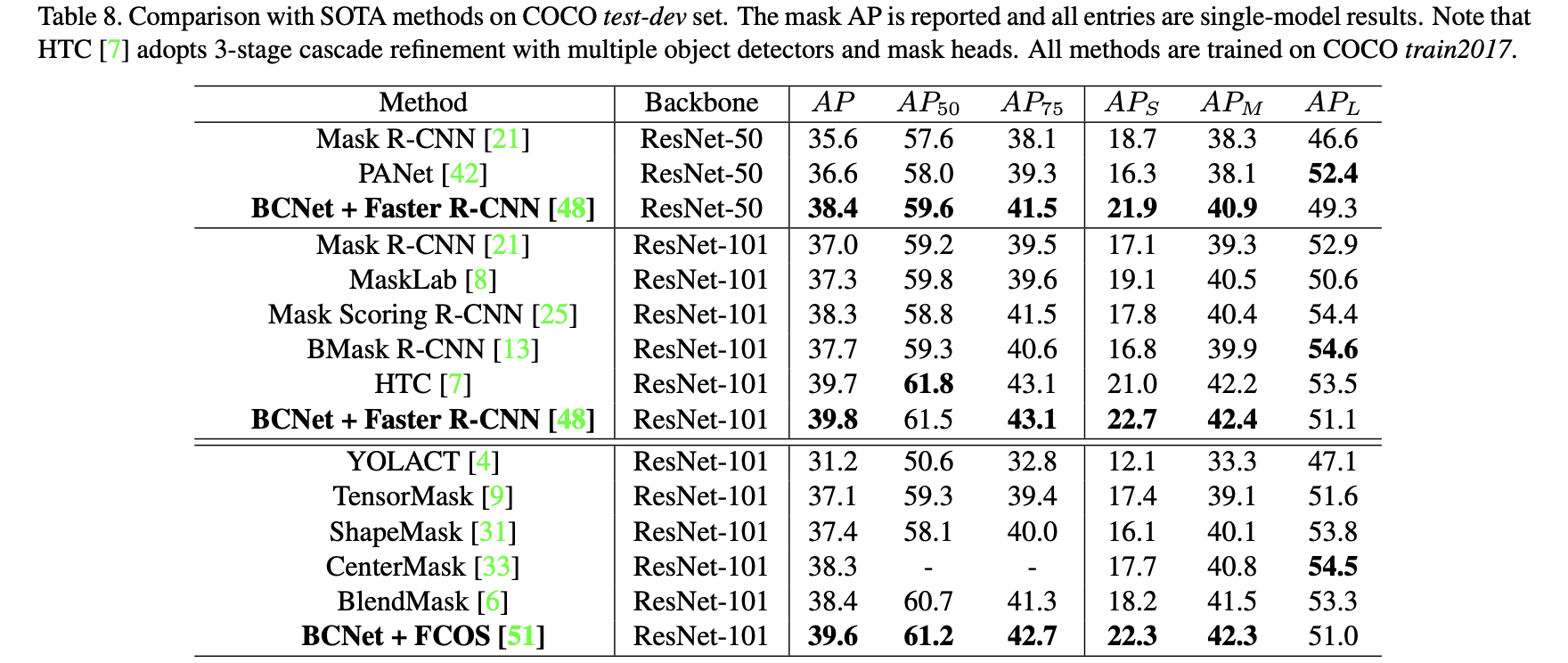
经过对于前后目标图层进行分开建模和预测之后,实例分割的结果在边缘上得到很好地改善,将文章的方法与其它一些实例分割方法进行比较:

2. 方法设计
2.1 网络结构
文章提出的网络结构见下图所示:

这篇文章是在FCOS的基础上进行改进得到的,主要的改进点是在mask_head部分,也就是按照上文提到的思想,将occluder和occludee进行分别建模,之后使用两者的信息组合得到最后的结果。
这里可以将文章的实例分割头与现有的一些实例分割头进行对比,其具体的差别相见下图:

2.2 实现细节
"GCN"模块:
在RoI区域中需要正常分割的前景目标可能会被其它目标遮挡,因为遮挡而断成为两截的极端情况也是存在的,对此文章提到需要一种可以有全局感知的模块求信息进行提取和建模,这就想到了GCN的模块。其实这里GCN的模块是使用attention的方式来实现的,其结构借鉴的是non-local,也就是网络结构图上左上角的图。那么其对应的代码实现可以参考:
# detectron2/modeling/roi_heads/mask_head.py#L325
# 定义GCN模块
self.query_transform_bound_bo = Conv2d(input_channels, input_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.key_transform_bound_bo = Conv2d(input_channels, input_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.value_transform_bound_bo = Conv2d(input_channels, input_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.output_transform_bound_bo = Conv2d(input_channels, input_channels, kernel_size=1, stride=1, padding=0, bias=False)
# detectron2/modeling/roi_heads/mask_head.py#L411
# 产生key query val进行attention运算
# x: B,C,H,W
# x_query: B,C,HW
x_query_bound = self.query_transform_bound(x).view(B, C, -1)
# x_query: B,HW,C
x_query_bound = torch.transpose(x_query_bound, 1, 2)
# x_key: B,C,HW
x_key_bound = self.key_transform_bound(x).view(B, C, -1)
# x_value: B,C,HW
x_value_bound = self.value_transform_bound(x).view(B, C, -1)
# x_value: B,HW,C
x_value_bound = torch.transpose(x_value_bound, 1, 2)
# W = Q^T K: B,HW,HW
x_w_bound = torch.matmul(x_query_bound, x_key_bound) * self.scale
x_w_bound = F.softmax(x_w_bound, dim=-1)
# x_relation = WV: B,HW,C
x_relation_bound = torch.matmul(x_w_bound, x_value_bound)
# x_relation = B,C,HW
x_relation_bound = torch.transpose(x_relation_bound, 1, 2)
# x_relation = B,C,H,W
x_relation_bound = x_relation_bound.view(B,C,H,W)
x_relation_bound = self.output_transform_bound(x_relation_bound)
x_relation_bound = self.blocker_bound(x_relation_bound)
x = x + x_relation_bound # 还引入了残差连接
其实将上述的GCN网络换成为FCN网络在现有的网络架构下也是带来性能上的提升的(attention大法好啊),参考下面的实验结果:
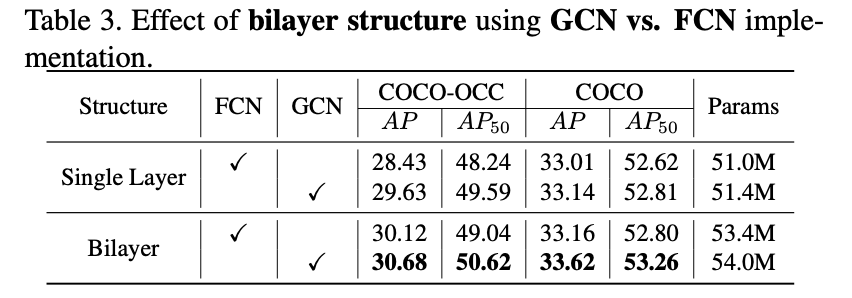
Mask预测头:
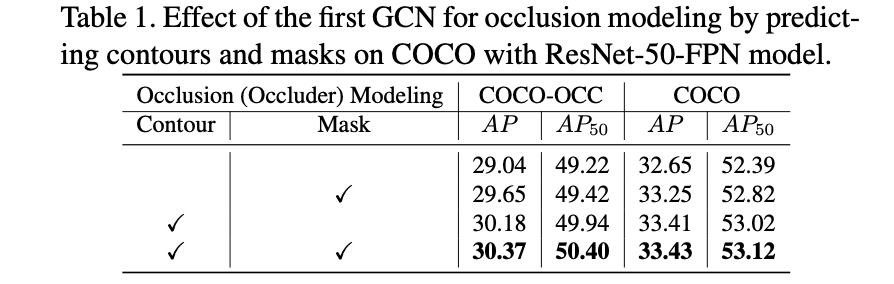
文章提出的mask头是会预测两个分量的:boundary和mask,需要预测额外的boundary文章给出的解释是可以带来额额外的guidance。那么这个guidance带来的收益是怎么样的呢?见下表:
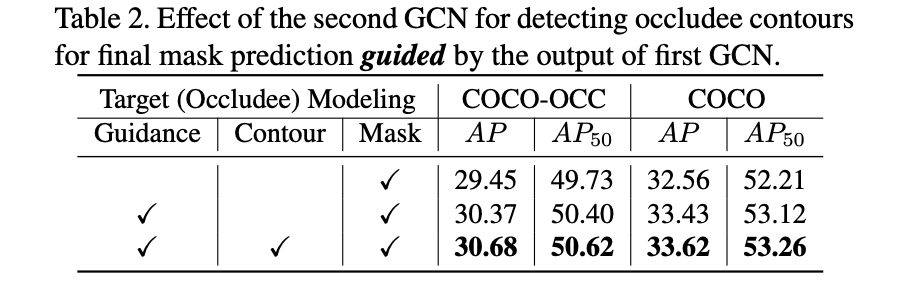
而且文章的算法可以算作是级联优化的形式,在第一层级完成对occluder的预测之后,在其基础上进行第二级优化。那么这个第二级优化带来的收益见下表:
2.3 损失函数:
这里的损失函数与传统的实例分割损失函数并没有太大的区别,也是属于检测损失加上分割损失的形式,其总体损失描述为:
L
=
λ
1
L
d
e
t
e
c
t
+
L
O
c
c
l
u
d
e
r
+
L
O
c
c
l
u
d
e
e
L=\lambda_1L_{detect}+L_{Occluder}+L_{Occludee}
L=λ1Ldetect+LOccluder+LOccludee
对于其中的FCOS检测部分其损失函数为:
L
D
e
t
e
c
t
=
L
R
e
g
r
e
s
s
i
o
n
+
L
C
e
n
t
e
r
n
e
s
s
+
L
C
l
a
s
s
L_{Detect}=L_{Regression}+L_{Centerness}+L{Class}
LDetect=LRegression+LCenterness+LClass
对于mask头部分包含两种类型的损失:boundary和mask的损失,既为:
L
O
c
c
l
u
d
e
r
=
λ
2
L
O
c
c
−
B
′
+
λ
3
L
O
c
c
−
S
′
L_{Occluder}=\lambda_2L_{Occ-B}^{'}+\lambda_3L_{Occ-S}^{'}
LOccluder=λ2LOcc−B′+λ3LOcc−S′
L
O
c
c
l
u
d
e
e
=
λ
4
L
O
c
c
−
B
+
λ
5
L
O
c
c
−
S
L_{Occludee}=\lambda_4L_{Occ-B}+\lambda_5L_{Occ-S}
LOccludee=λ4LOcc−B+λ5LOcc−S
3. 实验结果


















 2277
2277







 到【灌水乐园】发言
到【灌水乐园】发言







