







本代码首先将语料文件alice_in_wonderland.txt以句子为单位进行拆分,然后进行序列化(语料下载地址)。
对每个句子提取出3个连续单词的tuple=(left,center,right),cbow(假设词窗大小为3)的目标是从left、right预测出center。
因此对于每个tuple=(left,center,right)的数据,将left、center、right分别放入三个列表 w_lefts, w_centers, w_rights中。
输入的数据集[ x=(left+right)/2 , y=center ]
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer, one_hot
from sklearn.metrics.pairwise import cosine_distances
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt
import nltk
import numpy as np
import operator
np.random.seed(2018)
BATCH_SIZE = 128
NUM_EPOCHS = 20
lines = []
fin = open("./data/alice_in_wonderland.txt", "r")
for line in fin:
line = line.strip()
if len(line) == 0:
continue
lines.append(line)
fin.close()
sents = nltk.sent_tokenize(" ".join(lines)) # 以句子为单位进行划分
tokenizer = Tokenizer(5000) # use top 5000 words only
tokenizer.fit_on_texts(sents)
vocab_size = len(tokenizer.word_counts) + 1
sequences = tokenizer.texts_to_sequences(sents)'''
对每个句子提取出3个连续单词的tuple=(left,center,right),cbow(假设词窗大小为3)的
目标是从left、right预测出center。
因此对于每个tuple=(left,center,right)的数据,将left、center、right分别放入三个列表 w_lefts, w_centers, w_rights中
'''
w_lefts, w_centers, w_rights = [], [], []
for sequence in sequences:
triples = list(nltk.trigrams(sequence))
w_lefts.extend([x[0] for x in triples])
w_centers.extend([x[1] for x in triples])
w_rights.extend([x[2] for x in triples])# 将上面已经得到xs,ys转化为 one-hot矩阵
'''
例如词典大小为 5,有两个待转化为One-hot编码的left和right的数字[[2],[4]],则one-hot编码返回一个矩阵为
[
[0,0,1,0,0],
[0,0,0,0,1]
]
放入模型的X是 (left+right)/2,Y是center
'''
ohe = OneHotEncoder(n_values=vocab_size)
Xleft = ohe.fit_transform(np.array(w_lefts).reshape(-1, 1)).todense()
Xright = ohe.fit_transform(np.array(w_rights).reshape(-1, 1)).todense()
X = (Xleft + Xright) / 2.0
Y = ohe.fit_transform(np.array(w_centers).reshape(-1, 1)).todense()
# 划分出30%作为测试集,70%作为训练集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3,random_state=42)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape)
model = Sequential()
model.add(Dense(300, input_shape=(Xtrain.shape[1],)))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(Ytrain.shape[1]))
model.add(Activation("softmax"))
model.compile(optimizer="Nadam", loss="categorical_crossentropy",
metrics=["accuracy"])
history = model.fit(Xtrain, Ytrain, batch_size=BATCH_SIZE,
epochs=15, verbose=1,
validation_data=(Xtest, Ytest))'''
(17243, 2642) (7391, 2642) (17243, 2642) (7391, 2642)
Train on 17243 samples, validate on 7391 samples
Epoch 1/15
17243/17243 [==============================] - 11s 632us/step - loss: 6.3892 - acc: 0.0600 - val_loss: 5.9648 - val_acc: 0.0633
Epoch 2/15
17243/17243 [==============================] - 10s 592us/step - loss: 5.7475 - acc: 0.0723 - val_loss: 5.8266 - val_acc: 0.0835
Epoch 3/15
17243/17243 [==============================] - 10s 583us/step - loss: 5.4657 - acc: 0.1152 - val_loss: 5.6572 - val_acc: 0.1387
Epoch 4/15
17243/17243 [==============================] - 10s 592us/step - loss: 5.1743 - acc: 0.1565 - val_loss: 5.5046 - val_acc: 0.1582
Epoch 5/15
17243/17243 [==============================] - 10s 581us/step - loss: 4.8930 - acc: 0.1915 - val_loss: 5.3970 - val_acc: 0.1720
Epoch 6/15
17243/17243 [==============================] - 10s 591us/step - loss: 4.6346 - acc: 0.2153 - val_loss: 5.3193 - val_acc: 0.1783
Epoch 7/15
17243/17243 [==============================] - 10s 587us/step - loss: 4.3870 - acc: 0.2402 - val_loss: 5.2587 - val_acc: 0.1863
Epoch 8/15
17243/17243 [==============================] - 10s 580us/step - loss: 4.1494 - acc: 0.2683 - val_loss: 5.2239 - val_acc: 0.1925
Epoch 9/15
17243/17243 [==============================] - 10s 597us/step - loss: 3.9166 - acc: 0.2929 - val_loss: 5.1895 - val_acc: 0.2009
Epoch 10/15
17243/17243 [==============================] - 10s 586us/step - loss: 3.6900 - acc: 0.3183 - val_loss: 5.1650 - val_acc: 0.2055
Epoch 11/15
17243/17243 [==============================] - 10s 592us/step - loss: 3.4696 - acc: 0.3399 - val_loss: 5.1647 - val_acc: 0.2107
Epoch 12/15
17243/17243 [==============================] - 10s 594us/step - loss: 3.2650 - acc: 0.3564 - val_loss: 5.1683 - val_acc: 0.2143
Epoch 13/15
17243/17243 [==============================] - 10s 584us/step - loss: 3.0550 - acc: 0.3796 - val_loss: 5.1813 - val_acc: 0.2153
Epoch 14/15
17243/17243 [==============================] - 10s 592us/step - loss: 2.8832 - acc: 0.3981 - val_loss: 5.2149 - val_acc: 0.2161
Epoch 15/15
17243/17243 [==============================] - 10s 586us/step - loss: 2.7104 - acc: 0.4179 - val_loss: 5.2461 - val_acc: 0.2223
'''# plot loss function
plt.subplot(211)
plt.title("accuracy")
plt.plot(history.history["acc"], color="r", label="train")
plt.plot(history.history["val_acc"], color="b", label="validation")
plt.legend(loc="best")
plt.subplot(212)
plt.title("loss")
plt.plot(history.history["loss"], color="r", label="train")
plt.plot(history.history["val_loss"], color="b", label="validation")
plt.legend(loc="best")
plt.tight_layout()
plt.show()
# evaluate model
score = model.evaluate(Xtest, Ytest, verbose=1)
print("Test score: {:.3f}, accuracy: {:.3f}".format(score[0], score[1]))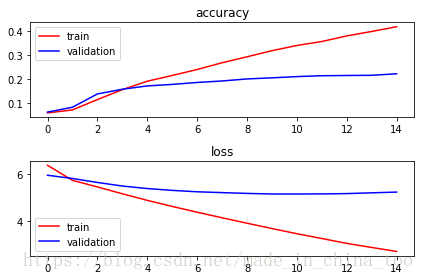
'''
7391/7391 [==============================] - 1s 167us/step
Test score: 5.246, accuracy: 0.222
In [17]:
'''# using the word2vec model
word2idx = tokenizer.word_index
idx2word = {v:k for k, v in word2idx.items()}
# retrieve the weights from the first dense layer. This will convert
# the input vector from a one-hot sum of two words to a dense 300
# dimensional representation
W, b = model.layers[0].get_weights()
# 计算词典所有单词的词向量
idx2emb = {}
for word in word2idx.keys():
wid = word2idx[word]
vec_in = ohe.fit_transform(np.array(wid)).todense()
vec_emb = np.dot(vec_in, W)
idx2emb[wid] = vec_emb
# 找出与word的词向量余弦相似度最高的10个单词,并输出这些单词
for word in ["stupid", "wonderful", "succeeded"]:
wid = word2idx[word]
source_emb = idx2emb[wid]
distances = []
for i in range(1, vocab_size):
if i == wid:
continue
target_emb = idx2emb[i]
distances.append(
(
(wid, i),
cosine_distances(source_emb, target_emb)
)
)
sorted_distances = sorted(distances, key=operator.itemgetter(1))[0:10]
predictions = [idx2word[x[0][1]] for x in sorted_distances]
print("{:s} => {:s}".format(word, ", ".join(predictions)))'''
stupid => happening, northumbria, eaten, uglification, tremulous, cakes, twinkled, reduced, memory, sixteenth
wonderful => riper, coaxing, promise, vegetable, simpleton, holiday, secret, pun, consultation, thunderstorm
succeeded => fainting, chains, coils, bed, currants, existence, contradicted, despair, drowned, couples
'''













 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









