






关于lda主题模型这里不做详解,这里只谈谈怎么用mahout包中的lda。
准备工作:
1.数据准备,准备好相应文档数据,这里是采用的是中文的
2.已经配置好hadoop、mahout、jdk等。
步骤:
1、准备好数据文件,这里先做好分词,可采用jieba先分好词
打开一个文件,如下

2、在hdfs上新建一个文件,命令如下:
hdfs dfs mkdir -p cvb
hdfs dfs mkdir -p cvb/data
3、将文件上传到hdfs上:
hdfs dfs -put ~/Documents/Textfile/* cvb/data
用hdfs dfs -ls cvb/data 查看是否上传成功
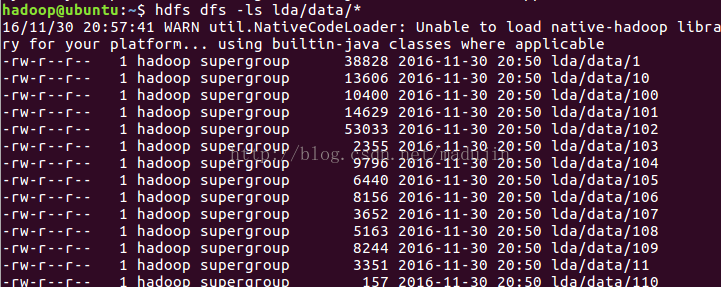
4、将数据文件转成序列化文件:
mahout seqdirectory -i cvb/data -o cvb/seq
将数据文件序列化并存在cvb/seq下,
hdfs dfs -ls cvb/seq,查看到:

5、将序列文件向量化:

这里-o是输出路径,
-wt是生成tfidf文件
--analyzerName 在这里需要指定这里包,因为默认不是中文,要对中文进行处理,才需要用到lucene的这个包。
查看结果:
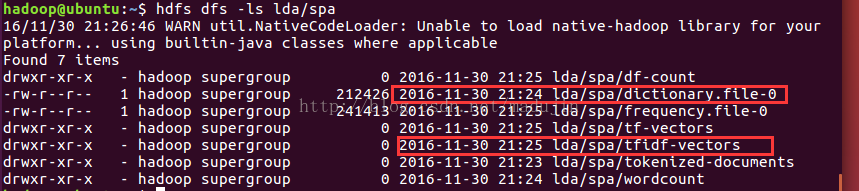
这里可查看这里的dictionary.file-0,看分词是否成功,

6、将向量文件,转成矩阵:

7、调用cvb:

-o输出文件位置
-k 生成主题个数
-x 设置迭代次数
-ow是否覆盖迭代结果
-dict 指定词典位置
-dt生成文档主题
-mt 生成主题模型
8、查看结果

查看topic,把生成的文档拷到本地















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









