







循环神经网络(RNN)基础篇学习笔记
一.权重共享
在CNN全连接层权重占比较多,在图像任务中,由于整个图像共享卷积核,所以实际参数量远远小于全连接层。

在实际任务中,由于全连接层参数过多,我们需要使用RNN解决带有序列模式的数据,同时利用权重共享的思想解决参数过多的问题。
二.RNN
1.序列模式的数据
比如预测天气时,今天的天气要依赖于上一天的天气数据,多用于天气、股票、自然语言处理等。

2.RNN Cell
h0:先验知识(可以初始化为全0与h1同维度的矩阵)
h1:hidden,与RNN Cell一同计算h2

RNN Cell本质就是一个线性层(Linear),hidden就是隐层,区别就是RNN Cell是共享的,反复参与运算。
RNN Cell详细运算如下:

伪代码实现:

直接使用RNN的话就不用自己实现循环:

Out为循环h1…hn,Hidden为最后一个隐层hn。

numlayer为几层的RNN(以下为numlayer详细图解):
其中numlayer=3

直接使用RNN伪代码:

其他参数说明:

batch_first=True:数据的序列长度和样本数量进行交换,即batch_size与seq_len参数顺序交换。

4.嵌入层
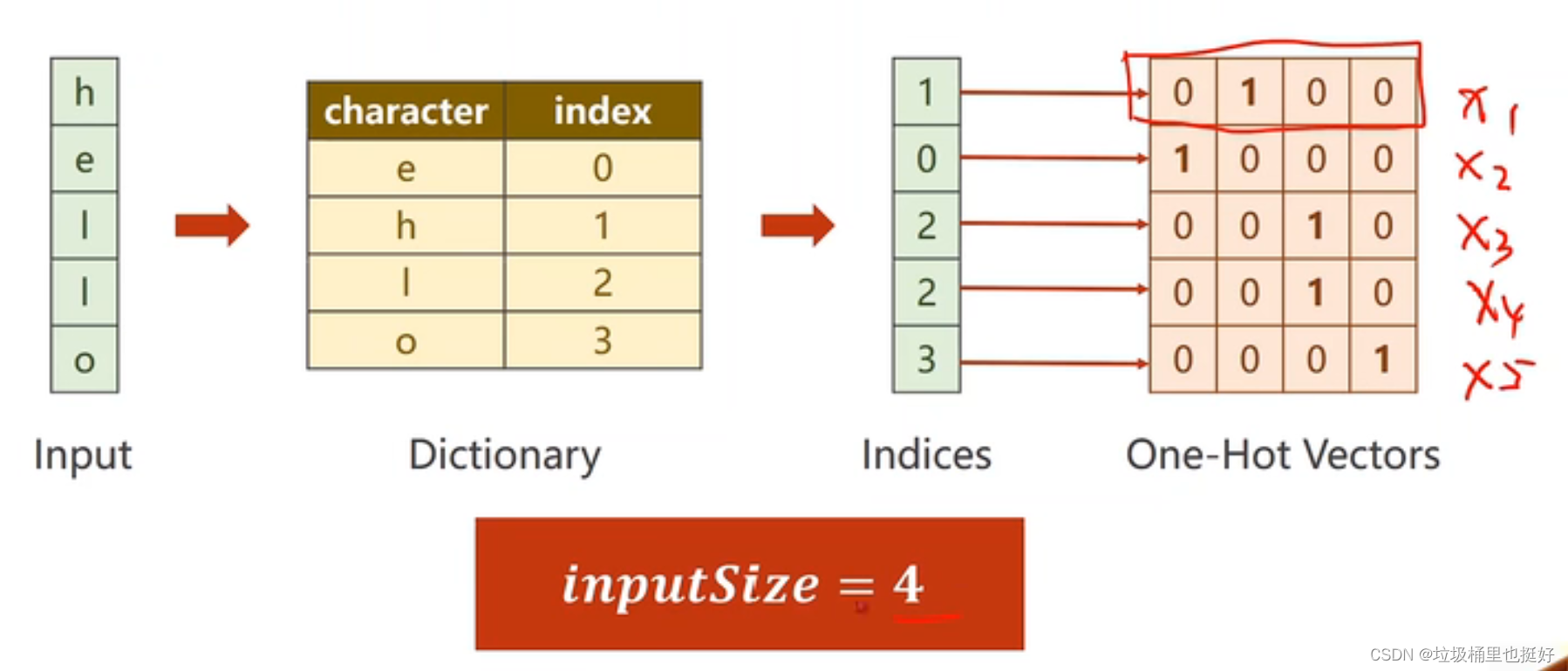
独热编码缺点:
(1)维度过高(每个词映射后维度变成几万维,维度诅咒)
(2)稀疏
(3)硬编码

我们希望得到低维,稠密,学习到的编码。

由此引出嵌入层,实质上就是对数据进行降维。

此时网络结构(Embed嵌入层)变成:
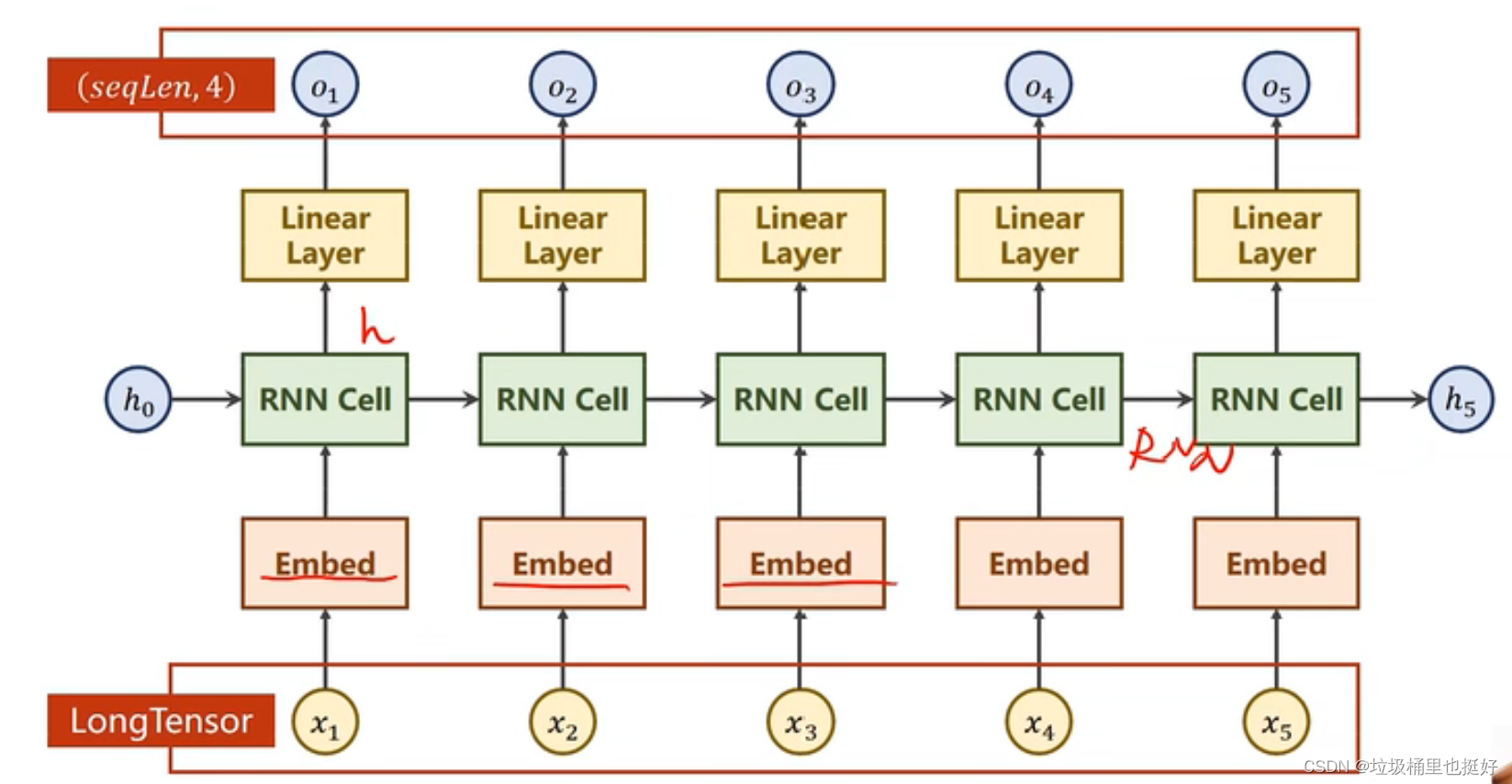
伪代码:

5.练习
(1)RNN(RnnCell练习)
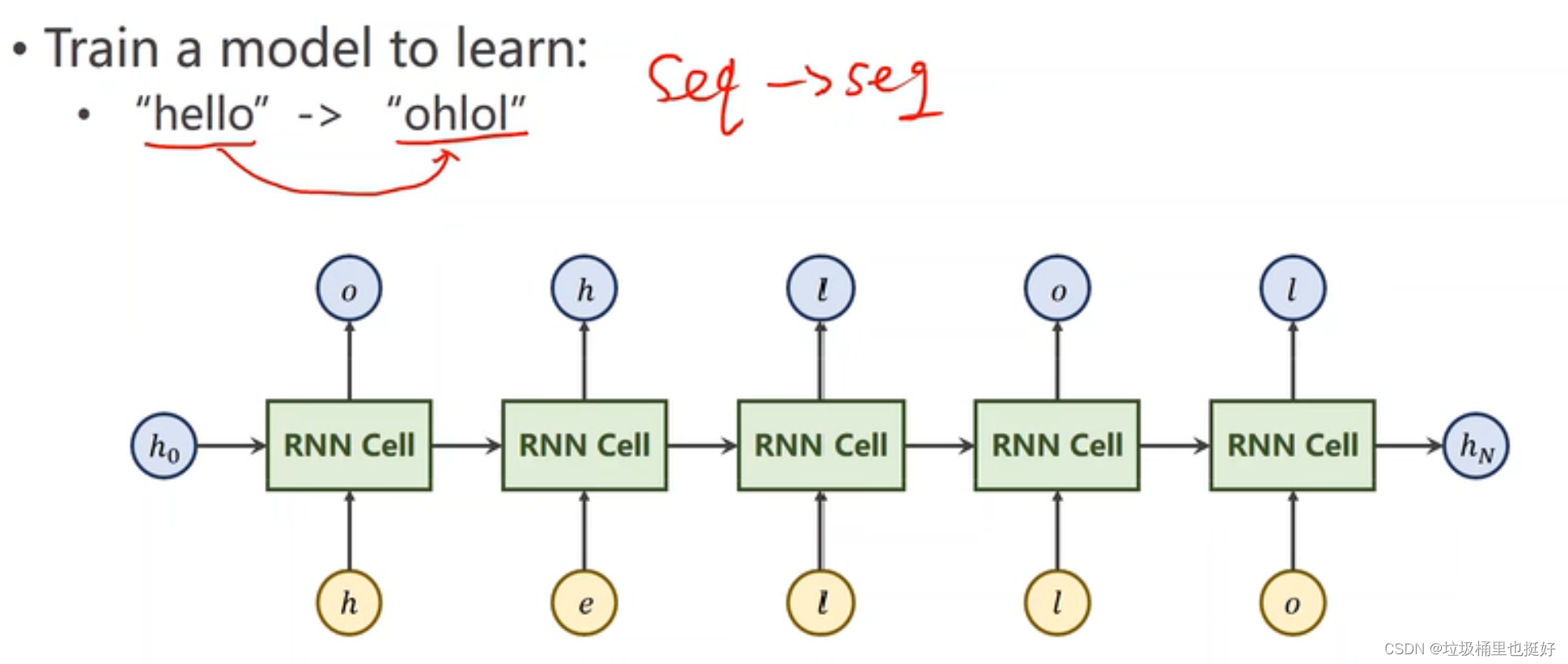
第一步:数据处理:使用独热编码
第二步:任务分析:输出为四维向量,通过交叉熵变为分布,实际上是分类问题。

代码如下:
import torch
import sklearn.preprocessing as sp
# 1. 数据准备
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e','h','l','o']
x_data = [[1],[0],[2],[2],[3]]
y_data = [[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









