







集群延迟和前向着色
Clustered Deferred and Forward Shading
Ola Olsson, Markus Billeter 和 Ulf Assarsson
查尔姆斯理工大学
翻译:欧石楠

图 1: 集群着色(Clustered Shading) 将样本从视图(左图)分组为集群(在顶部中心图像中以蓝色显示)。对于着色, 即为每个集群分配影响集群的灯光。与屏幕空间分块(在底部中心图像中以红色显示) 创建的集群体积相比,集群着色的集群较小,而与分块着色( TiledShading)相比,集群着色中的每个像素会保持较低照明计算次数(右上图像)。颜色表示每个像素的照明计算次数,范围从蓝色像素的小于 50,到白色像素的超过 300。该场景大约包含 2400 个光源, 并且会通过我们的方法渲染 17ms(2.3ms 用于聚类, 1.5ms 用于光分配,5.6ms 用于着色; 剩余的帧像周期主要是渲染到 G 缓冲区,并且在这里使用 glutSolidSphere()方法可视化光源,而分块着色实现需 26ms(光分配为 1.0ms,着色为 17.7ms)。
摘要:
本文介绍和研究了延迟和前向渲染的集群着色。在集群着色中,具有相似属性(例如, 3D 位置和/或法线)的视图样本被分组为集群。这与分块着色相当,其中视图样本仅基于 2D 位置分组为分块。我们展示了集群着色, 创建了比分块着色更好的光源到视图样本的映射,从而显著地减少了着色期间的光照计算。此外, 集群着色可以使用常规信息执行每个集群的背面剔除灯光,同样可以减少照明计算的数量。我们还展示了集群着色不仅在许多场景中优于分块着色, 而且在棘手的条件下也表现出更好的最坏情况行为(例如,当观察具有大的深度不连续性的高频几何时)。此外, 集群着色可实现比以前可行的光源高出两到三个数量级的实时场景(最多约一百万个光源)。
1. 介绍
近年来,各种形式的分块着色 [OA11]在游戏开发界越来越受到关注。 分块延迟着色是最受欢迎的一种形式,它也已经在 SonyPlayStation 3 和 Microsoft XBox 360 控制台以及个人计算机 [BE08, And09, Swo09,Lau10, Cof11]上实现了。近期, 分块前向着色也引起了人们的关注[McK12]。
分块延迟着色消除了延迟着色的带宽瓶颈,但却使技术计算受到了限制。于是,我们可以有效地使用具有高计算带宽比的设备,例如现代控制台和多个 GPU。现代高端游戏正在使用分块延迟着色来容纳数千盏灯,而这些灯光需要突破视觉保真度[FC11]。大量的灯光可以产生影响动态和静态几何形状的 GI 效果。
分块着色将矩形屏幕空间分块中的样本分组,使用每个分块内的最小和最大深度来定义子平截头体。因此,包含深度值相近
的分块(例如, 从单一表面),将代表小的边界量。 然而,对于出现一个或多个深度不连续的分块, 分块的深度边界必须包含样本组之间的所有空白空间(如图 1 所示)。因而这减少了光线剔除效率,最坏的情况下,会退化为纯 2D 测试。该结果使得视图和性能之间存在强烈依赖性,任何时候都难以保证一致的渲染性能,而这在实时应用中是非常不希望看到的。
我们介绍了集群着色,在其中我们会探索更高维度的分块,我们统称为集群。每个集群都有一个固定的最大 3D 范围,这意味着根据视图,不存在退化的情况。每一个样本在最坏的情况下,都被固定的体积所代表,而空的空间被忽略。
我们展示了如何在 GPU 上有效地实现集群着色,同时支持延迟和前向着色实现。我们的实现显示出更少依赖于视图的性能,并且对于某些对分块着色具有挑战性的情况,该实现要快得多。我们还扩展到 3D 集群之外,并使用普通信息。这用于在每个集群的基础上实现光背面剔除,从而丢弃不影响样本的灯光。为了可靠地支持大量灯光,我们还实施了分层灯光分配的方法,该方法可实现高达 1M 盏灯光的实时性能。
2. 先前工作
延迟着色最初是在 1988 年的硬件设计中引入的[DWS*88],随后在 1990 年[ST90]引入了使用全屏几何缓冲区(G-Buffers)的更通用的方法。延迟着色使几何和光处理分离,使得管理大量光源变得相对简单。因为硬件变得越来越强大,提高视觉保真度的标准需要越来越多的灯光,所以它已经成为近年来的主流方法。
分块着色是一种相对较新的,基于延迟着色的发展趋势。其主要用于解决延迟着色中的内存带宽瓶颈问题,并已在许多现代计算机游戏中实现。由于游戏控制台是高带宽限制设备,因此分块延迟着色很快成为高端游戏的重要算法[BE08,And09, Swo09, Lau10, Cof11,McK12]。在消费型 GPU 中也存在计算能力增长快于存储器带宽的趋势。已经证明,分块着色可以在连续多代 GPU 上很好地扩展[OA11]。
2.1. 集群确定
为了能更高效地实现集群处理,我们需要一些方法来确定给定帧中存在哪些集群。在延迟着色的设置中,需要分析整个帧缓冲区,且必须在 GPU 上有效地完成,以最小化数据传输和同步。在 GPU 渲染算法中,确定超出简单的 2D 分块的样本分组是一个相当普遍的问题。
分辨率匹配阴影图(RMSM)必须确定视图样本使用的阴影页[LSO07]。该方法首先利用屏幕空间的一致性来减少来自屏幕空间中相邻像素的重复请求。然后通过对剩余请求进行排序和压缩来确定全局唯一请求。
Garanzha 等。 [GL10]提出了一种类似的技术,称为压缩-分类-解压缩(CSD)。他们的目标是在帧缓冲区中找到 3D(或 5D) 集群,其中这些集群用于形成射线包。与其他方法的主要区别在于 Garanzha 等人,将帧缓冲区视为 1D 序列,并在排序之前使用行程长度编码(RLE)来减少重复。他们在排序后再扩大结果。
在 2D 和 1D 中, RMSM 和 CSD 中的方法依赖于相邻输入元件之间的相干性。在许多情况下,这是一个合理的假设。但是,诸如具有 alpha-to-coverage 方法的多采样抗锯齿( MSAA)或随机透明[ESSL10]等技术,让该假设失去了有效性。相干性仍存在于帧缓冲区中,但不存在于相邻样本之间。对于相邻样本之间具有弱相干性的场景,这两种方法都退化成对整个帧缓冲区进行排序。
虚拟纹理技术面临与 RMSM 非常相似的问题,即:必须确定虚拟纹理中使用的页面。 Mayer [May10]调查了几种解决这个问题的技术,所有这些都与上述方法非常相似。Hollemeersch 等。 [HPLdW10]描述了一种不同的解决方案,它直接在虚拟页面表中设置一个标志,用以指示该页面是否需要。接下来压缩页面表,生成所需的唯一页面。
标记和压缩页表不需要使用邻接关系来降低工作量。 无论在帧缓冲区中的位置如何,都可以,无论是否可以清除重复的请求,所有需要相同页面的样本都将设置相同的标志。因此,对于非相干帧缓冲器,该方法应该更加鲁棒。但是,由于使用了直接索引,因此必须使得可能的索引相对较少(在本例中为页面)。
Liktor 和 Dashsbacher [LD12]使用相关技术确定并分配独特的着色样本。但是,由于大量独特的着色样本标识符,直接映射的方法是不可行的。此外,由于他们需要在过程中为样本分配空间,因此他们使用了更为紧凑的哈希表来跟踪存在的样本。为样本分配的空间以连续数组形式存在,从而进一步复杂化了该过程。
3.集群延迟着色算法
我们的算法包括以下基本步骤,每个步骤将在以下部分中更为详细地描述。
1.将场景渲染为 G-Buffers。
2.集群分配。
3.找到独特的集群。
4.将灯光分配给集群。
5.阴影样本。
第一步,与传统的延迟着色或分块延迟着色没有区别,即:通过渲染模型来填充 GBuffers。第二步根据其位置为每个像素计算所属的集群(和可能正常的)。在第三步中,我们将其缩减为唯一集群列表。第四步,将灯光分配给集群,包括有效地查找哪些灯光影响哪个独特集群,并为每个集群生成灯光列表。最后,对于每个样本,访问这些灯光列表来计算样本的阴影。
3.1 集群分配
集群分配的目标是根据 G-Buffers 中可用的信息计算给定视图样本的整数集群键。 我们利用这个位置,也可以选择正常的位置。对视图样本进行分组的方法比较有限。从根本上,我们希望将彼此接近的样本组合在一起,因为它们很可能受到同一组灯光的影响。其中有许多可用的动态聚类算法,例如, k-means 聚类,但这些都不能对数百万个样本表现得足够好。因此,我们采用样本位置的常规细分或量化,既快又能提供可预测集群的大小。我们选择量化位置的方式在某些方面很重要。我们希望集群很小,以使影响每个集群的灯光尽可能少,但相反,它们应该包含尽可能多的样本,从而保持光分配和阴影的效率。我们还希望集群键编码所需的比特数较小并且可预测。
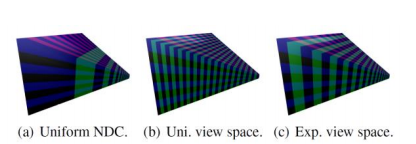
图 2: 深度细分方案: (a), 标准化设备坐标的统一细分; (b), 在视野中均匀细分; (c), 视图空间中的指数间距。
一种常见的方法是简单地使用世界空间(虚拟)均匀网格[GL10]。此方法提供快速的集群键计算方法,并且保证所有集群的大小相同。但是,选择合适的网格单元大小需要对每个场景进行手动调整,同时根据场景大小,可能需要大量的位来表示键。此外,当在投影下观察网格时,远处的集群会在屏幕上变小。因此,在大型场景中,可能会遇到许多集群是像素大小的视图,因而使得性能变得非常差。
因此,我们探讨了一种替代方法,基于观察我们只对视锥体内的点感兴趣。从分块延迟着色中使用的统一屏幕空间分块开始,我们通过沿着视图空间(或标准化设备坐标)中的 z 轴细分,以类似于[HM08]的方式对其进行扩展。在世界空间中观察,这会产生分隔视锥体的小亚视锥,见图 2。

图 3: 视图空间中的指数间距。对于给定的分区 k,显示了近平面和远平面,以及单元高度和深度。
执行 z轴细分的最简单方法是将标准化设备坐标中的深度范围划分为一组均匀段。然而,由于标准化设备坐标的非线性特性,这种量化会导致集群尺寸非常不均匀。靠近近平面的集群变得非常薄,而朝向远平面的集群变得非常长(图 2(a))。视图空间中的均匀细分产生相反的伪影,其中视点附近的集群是长而窄的, 而远处的集群是宽而扁平的(图 2(b))。
因此,我们选择在视图空间中执行细分,通过以指数方式间隔分割以实现自相似细分[LTYM06],使得集群变为尽可能立方体(图 2(c)和 3)。

图 4: 单位立方体上法线方向的量化,每个面上使用 3×3 细分,一个细分使用重建的法线锥。
在图 3 中,我们示出了平截头体的细分.Y 方向(Sy)的细分数量在屏幕空间中给出(例如,以形成 32× 32 像素的区块)。 k,neark 的近平面可以从中计算出来
neark = neark−1 + hk−1
对于第一个细分, near0 = near,即近视平面。对于 2q 的给定视野,我们发现:
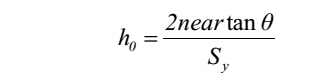
由此可以使用以下表达式计算 neark:
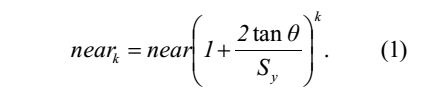
求解 k 的等式 1,我们发现:
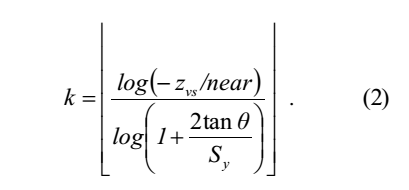
使用等式 2,我们现在可以从屏幕空间坐标(xss; yss)和视图空间深度 zvs 计算集群键元组(i; j; k)。坐标(i; j)是屏幕空间分块索引,即分块大小为(tx; ty),(i; j) =(⌊xss/tx,yss/ty⌋ )。
使用我们更加动态的集群定义,可以使用除位置之外的属性来定义集群键。我们使用编码量化法线方向的多个位扩展集群键(图 6)。我们通过立方体面和每个面上的离散 2D 网格来量化法线,如图 4 所示。法线上的聚类方法可以改善光的剔除(参见第 3.3 节)。

图 5: 对键缓冲区进行排序和压缩以查找唯一的集群。 对键缓冲区中的集群键进行排序,然后进行压缩,以查找唯一集群列表。 例如,排序基于视图样本的深度和法线方向。
3.2 寻找独特的集群
我们将在此提供两种不同的选项,用于标识唯一的集群:使用排序和页面表。
简单地对集群键进行排序是并行查找独特集群的最显著的方法,排序之后执行压缩操作,用于删除具有相同邻居的所有集群键(见表格 5)。排序和压缩都是相对有效且易于获得的 GPU 构建块。尽管取得了一些稳步的进展,但排序仍是一项昂贵的操作,因此需要我们探索性能更好的替代方案。如第 2 节所述,依赖相邻屏幕空间一致性的方法并不稳健,特别是对于随机帧缓冲区。因此我们可以把注意力放在不存在这种(a) 参考视图 (b) 仅基于 3D 位置的聚类 (c) 使用 3D 位置和样本法线

图 6: 不同聚类方法的结果。 (a) 渲染和点亮的参考视图显示在右侧。 (b) 中心图像仅显示聚类在位置上的结果。(为每个集群分配一种随机颜色。) (c) 基于的聚类位置和法线显示在右侧。 在这两种情况下,平坦区域产生类似于屏幕空间分块的聚类。
缺陷的技术上。
3.2.0.1. 局部排序
在我们的第一种技术中,我们在局部对每个屏幕空间分块中的样本进行排序。这使得我们能在芯片共享存储器中执行排序操作,并且使用局部(因而更小)索引链接回到源像素上。我们使用并行压缩从每个分块中提取唯一的集群。由此,我们获得了唯一的全局集群列表。在压缩过程中,我们还计算并存储了从每个样本到其关联集群的链接。
3.2.0.2. 页表
第二种技术类似于虚拟纹理使用的页表方法(第 2 节)。但是,由于可能的集群键的范围非常大,所以我们无法在集群数据的集群键和物理存储位置之间使用直接映射;它通常不适用于 GPU 内存。取而代之,我们使用虚拟映射,并根据键需要的存储空间来分配物理页面。 Lefohn 等人提供了虚拟地址转换的 GPU 软件实现的详细信息。我们利用所有物理页面分配范围紧凑的事实, 压缩该范围以找到唯一的集群。无论是使用排序还是页表, 集群键定义隐式 3D 边界,也可以定义隐式法线锥。但是,由于实际视图样本位置和法线通常具有更紧密的边界,我们还会评估显式 3D 上界和法线锥。 我们通过对每个集群中的样本进行缩减操作来计算显式上界(例如,我们执行最小-最大减少以找到包围每个集群的 AABB)。减少的结果分别存储在存储器中。使用页表时,难以有效地实现缩减。由于视图样本到集群数据的多对一映射,我们需要利用原子操作来获得高碰撞率。我们认为这是一种不切实际的昂贵方法。因此,我们仅基于排序实现第一种技术的显式上界(在局部排序之后,很容易知道哪些样本是属于给定集群的)。
3.3. 灯光分配
灯光分配阶段的目标是计算影响每个群的灯光列表。 分块延迟着色实现的先前设计利用蛮力方法,基本上能找到灯光和分块之间的交叉点。也就是说,对于每个分块, 通过迭代场景中的所有灯光并测试包围盒,从而找到光和集群的重叠部分。 这对于相当少数量的灯光和集群是可以接受的。
为了能支持大量的灯光和动态变化的集群数,我们使用基于灯光的空间树完全分层方法。对于每个帧,首先,我们通过每个光的离散中心位置以及 Z 方向顺序(莫顿码)对灯光进行排序,来构建包围盒层次结构(BVH)。我们围绕所有灯光,动态计算出包围盒,从而推导出离散化。
我们直接从排序数据中获取搜索树的叶子。接下来,将 32 个连续叶子分组到包围盒(AABB)中,以形成叶子上方的第一级。接下来,通过再次组合 32 个连续元素来构建下一层。在单个根元素不存在的情况下,我们继续该过程。
对于每个集群,我们使用深度优先遍历来遍历此 BVH。在每个层,我们将针对子节点的包围盒测试集群的边界框(从集群的内容显式计算或隐式地从集群的键派生)。对于叶节点,使用界定光源的球体;其他节点存储封闭该节点的 AABB。 32 的分支因子允许在 GPU 上进行有效的 SIMD遍历并使得搜索树层数相对较浅显(最多 5层),这用于避免昂贵的递归(分支因子应该是根据所使用的 GPU 调整,在当前的NVIDIA GPU 上,因子 32 很方便)。
如果集群可以使用法线锥, 我们使用此锥体进一步摒弃的光线,将不会影响集群中任何样本。如果来自集群 AABB(di)的中心的入射光方向 w 与法线锥轴(a)之间的角度大于 p = 2 + a + d,则会发生以上的情况。 角度 α 是法线锥半角, d是锥体与包围集群 AABB 的光的半角(见图 7)。
3.4. 底纹
着色与分块着色的区别仅在于我们如何查找有问题的视图样本集群。对于分块着色,基于屏幕空间坐标的简单 2D 查找,足
以能检索灯光列表偏移和计数值。但是,对于集群方法,集群键和唯一集群列表的索引之间不再存在直接映射。

图 7: 针对集群灯光的背面剔除。 具有开口角度 α的法线锥(蓝色)从集群导出或用集群存储。此集群中包含的样本的法线都在此锥体内。起源于光源并包围集群的锥体(灰色虚线-几何上等于红色锥体)给出角度 d。如果入射光与法线锥(w)的轴之间的角度大于 p = 2 + a + d,光线会面向集群中所有样本的背面,因此可以被忽略。
在排序方法中,我们为每个像素显式存储此索引。该过程是通过将引用追踪回原始像素来实现的,并且当建立唯一集群列表时,我们会将索引存储到全屏缓冲区中的正确像素上。使用页表时,在找到唯一的集群之后,我们将集群索引存储回用于先前存储集群键的物理内存位置(使用与之前相同的页表)。这意味着对集群键的虚拟查找将产生集群索引。因此,每个样本可以使用先前计算的(或重新计算的)集群键查找集群索引。
4. 实施和评估
我们使用 OpenGL 和 CUDA 实现了新算法的几种变体。变体如下(使用的后缀记录在表 1 中):
· ClusteredDeferred [Nk] [En] [Eb] [Pt] – 集群延迟着色。
· ClusteredForward - 聚集前向着色。
聚集的前向着色需要 pre-z 传递来填充深度缓冲区,该缓冲区用于聚类。目前仅通过页表来实现。此外,我们实施了以下方法进行比较,如[OA11]中所述:
· 延迟,传统的延迟着色,使用模板优化。这意味着使用模板测试[AA03],每个样品的灯光分配将是精确的。
· TiledDeferred,标准分块延迟着色。
· TiledDeferredEn, 分块延迟着色,每个分块计算显式法线锥。
· TiledForward,带有深度预传的标准分块前向着色,以实现最小-最大剔除光。

4.1. 集群键打包
为了在使用排序或页表时获得最佳性能,我们希望将集群键打包成尽可能少的位。我们为每个 i 和 j 组件分配 8 位,这些组件识别集群所属的屏幕空间区块。该操作允许最多 8192×8192 个大小的渲染目标(假设屏幕空间区块大小为 32×32 像素)。 深
度索引 k 的值由近平面和远平面的设置和等式 2 来确定。在我们的场景中,我们发现 10 位就足够了。因而为可选的正态集群
留下了多达 6 位。使用 6 位,例如我们可以接受每个立方体面上最多 3×3 细分的分辨率(3×3×6 = 54 和⌈ log254⌉ = 6) 的情
况。对于更受限制的环境,打包数据会更高效,从而能节省时间和空间。
4.2. 分块排序
对于集群键(10 到 16 位宽),我们附加了另外 10 位的元数据,这些元数据能识别样本相对于其分块的原始位置。 然后,我们执行集群键的和相关元数据的局部分块分类方法。其中 sort 方法只考虑集群键的最多 16 位;而元数据作为排序后返回原始样本的链接。在每个分块中,我们计算唯一集群键的数量。使用对每个分块的计数的前缀操作,我们找到唯一的集群键的总数,并为每个集群分配唯一的 ID,范围在[0 … numClusters]之间。 我们将唯一 ID 写回到集群成员的每个像素中。唯一 ID 还用来记录内存中集群数据存储位置的偏移量。
依据集群键,我们可以重建包围盒(AABB 和法线锥),在这种情况下,每个集群仅需要存储其集群键即可。对于显式包围盒,我们另外存储 AABB 和/或法线锥。我们使用缩减操作来计算显式包围盒:例如,可以使用样本位置上的最小和最大缩减操作找到 AABB。本地排序得到的集群键的元数据,为我们提供了哪些样本属于所给定集群的信息。

图 8: Crytek Sponza 场景的视图,随机放置 10k 盏灯。 树枝导致深度缓冲区中的不连续性,使得分块延迟着色更具挑战性。
4.3. 页表
我们使用两种孔型法实现了单级页表。首先,在表中标记所需的页面。然后,利用并行前缀和分配物理页面,从而将键最终
存储到物理页面中。我们在一次单程中即时执行物理页面分配的速度要慢 2 倍,但在具有更快原子操作的硬件上仍然可行。
4.4. 灯光分配
如 3.3 节所述,我们在每个帧的灯光上构造一个搜索树。该构造过程依赖于有效的分类功能; 在这里我们使用 Thrust [HB10]提供的排序功能。为了构造树的上层,我们为每个要构造的节点启动一个 CUDA warp(32 个线程)。 warp 对子节点的包围盒执行 in-warp 并行缩减。
对于遍历,我们再次利用搜索树的 32位宽扇出。对于每个集群,我们分配了一个以深度优先顺序遍历树的 warp。 warp 中的每个线程并行测试子节点的 32 个包围盒。
通过实现展开深度为 5 的树,我们可以避免在 CUDA 中进行昂贵的递归。由于深度为 5,我们可以支持多达 3200 万盏灯,我认为这是足够的(扩展它是微不足道的)。
5. 结果和讨论
我们测量了上一节中描述的算法和变体的性能,并且测量是在 NVIDIA GTX 480GPU 上执行的,其他情况另有说明。我们使用下面列出的一组场景。

图 9: (左) 进行数百万次照明计算。(右)被标准化为延迟方法的相同的数据。
1.Necropolis。
虚幻开发工具包[Epi11]中的场景(图 1)。场景范围有限,其中包含653 盏灯。 这些灯大多数是聚光灯。但是我们将所有灯都视为点光源(这是我们实验中的约束条件)。场景包含大约 2M 个三角形并且是被法线贴图的。我们创建了一个覆盖地图长度的相机动画(参见补充视频)。为了进一步提高灯光数量,我们在场景中增加了几个炮塔,拍摄出彩色球体,在动画过程中将灯光总数提高到 2500 左右。
2.Sponza。
我们使用了 Crytek [Cry10]提供的版本的 sponza(图 8)。为了使场景更具挑战性, 具有更多的不连续性,我们注入了一组光秃秃的树。我们在场景 AABB 中生成了 10k 盏随机灯光。
5.1. 能效分析
集群着色优于分块着色的主要在于其减少了视图依赖性。通过避免空白空间,效率应类似于使用模板优化的延迟着色,并且
比分块着色所需的变量更少。这在图 9 和10(a)中示出,它们都采用了来自 [OA11]的照明计算度量。
由于聚类和光分配会引入开销,因此当光线较少或间断较少时,分块着色的效果预计会更好。 集群着色在帧时间内预计会具有较少的视图依赖性变化。图 11 证实了墓地场景的情况就是如此,它具有相对较少的不连续性和光照。即使是最复杂的集群算法(ClusteredNk3EbEn),也表现出了与分块延迟类似的最差情况。对于图 10(b)中所示的更具挑战性的场景,情况也是如此,即:具有许多不连续性和灯光,意味着集群着色的稳健性更强。我们还发现,在最坏的情况下,在墓地动画中表现最佳的集群变体(ClusteredDeferredPt)快了约 50%。
(a)数百万的照明计算的效率。
(b)重要阶段的毫秒数值用于衡量性能。

图 10: 针对图 8 中所示的 crytek sponza 场景的测试算法测量的性能。从(a)中排除了分块变体,因为它们使得比较困难。他们执行大约 9000 万次照明计算。出于同样的原因, Deferred 和 TiledForward 已被排除在(b)之外。延迟总共需要97.1 ms, TiledForward 需要 23.6 ms 才能渲染。

图 11: 一些算法变体运行时的性能,而非Necropolis 场景动画。
ClusteredForward 提供非常有竞争力的

(a) Sponza,没有树。 (b) Sponza, 有树 (c) Sponza,没有树木, 2 倍光半径。
图 12: 图 8 中 Sponza 视图的各种算法和灯数的交叉点。注意(a)和(c)使用相同的视图,但没有树,因此包含较少的不连续性。
表 现 , 类 似 于 墓 地 动 画 序 列 中 的TiledDeferred(图 11)。非常有趣的是,因为使用前向阴影,这个变体固有地支持 MSAA,自定义材质着色器,并回避 G-Buffer 存储的问题。这是非常了不起的,因为 TiledForward的表现比 TiledDeferred 差得多(这就是为什么 TiledForward 被排除在图 11 之外)。
运行时性能受许多因素的影响,包括灯的数量,光密度,不连续性水平,算法复杂度和各种实现细节。在图 12 中,我们将探讨前三个选项。虽然分块和集群实现之间的交叉点最多约为 2k 盏灯,但最重要的结论是即使是光线很少的情况,集群着色依旧表现出色。使用法线锥和显式上界可提高所有测试方法的效率和着色时间(图 9 和 10)。但是,随着其他阶段变慢,整体渲染并不能变得更快。 即使将法线锥结构添加到分块延迟TiledDeferredEn),其开销一般也太大,从而也无法提供任何净效益。这肯定了主要的性能增益来自于 2D 分块之外的移动。为了使这些更高级的集群具有吸引力,必须找到更快的光分配和聚类方法,或者必须增加着色成本。
由于我们的集群着色实现使用光层次结构来进行光分配,因此随着灯光数量的增加,它会具有很好扩展性。表 2 表明了这一点, 即: 我们将层级光分配与分块实现所使用的暴力方法进行比较。对于少量的灯光,各种开销占据了分配时间,使得集群变体操作变得稍微昂贵。在 1M 盏灯光下,我们的集群着色实现以超过 35 fps 的速度运行,灯光均匀分布,最终, 影响到每个集群的灯光最多达 100 个(平均约 45 个)。
6. 结论和未来工作
在本文中,我们提出并评估了集群着色(Clustered Shading)。在集群着色中,我们根据它们的位置对相似的视图样本进行分组,并且可选地, 将其样本标准化为集群的形式。
然后我们确定哪些光源可能会影响哪些集群。与分块着色相比,集群通常较
小,因此将受到较少光源的影响。可选的每个集群标准化信息能让我们剔除背面光源, 以防止聚类的发生,从而进一步减少影响每个集群的光源数量。我们已经证明该方法效率确实优越,并且在观察条件改变的情况下表现地更加稳健。我们的实现表明,集群延迟和前向着色都可以提供实时性能,并且可以扩展到 1M 盏灯。此外,集群的开销很低,即使是很少的灯光下也很有说服力。
未来我们希望探索近似照明, 其中使用启发式方法来确定集群中的所有视图样本是否都受到特定光线的约相同程度的影响。 如果是,则对该光源的照明进行一次评估,并重新用于集群中的所有样本。在一些初步测试中,我们观察在计算成本非常低的情况下, 照明计算量大约减少了 20%。(但这产生了一些微妙的视觉差异,我们暂时无法解决这个问题。)
我们一致认为可以产生高质量的近似值。这些近似值可能额外需要每个集群的数据,例如镜面计算的平均光泽度。 还需要开发一种更好的启发式算法来确定何时可以进行近似处理。
研究集群着色如何与更复杂的着色相互作用,例如由于材料类型而导致的效果变换,也将是很有趣的。 由于集群着色具有比分块着色小得多的着色成本, 因此我们期望利用着色器复杂性进行更好的缩放。
参考文献
[AA03] ARVO J., AILA T.: Optimized shadow mapping using the stencil buffer. journal of graphics, gpu, and game tools 8, 3
(2003), 23–32. 6
[And09] ANDERSSON J.: Parallel graphicsin frostbite – current & future. SIGGRAPH Course: Beyond Programmable Shading,
2009. URL: http://s09.idav.ucdavis.edu/talks/04-JAndersson-ParallelFrostbite-Siggraph09.pdf. 2
[BE08] BALESTRA C., ENGSTAD P.-K.:The technologyof uncharted: Drake’s fortune. Game Developer Conference,2008. URL: http://www.naughtydog.com/docs/Naughty-Dog-GDC08-UNCHARTED-Tech.pdf. 2
[BOA09] BILLETER M., OLSSON O., ASSARSSON U.: Efficient stream compaction on wide simd many-core architectures. I
n HPG ’09: Proceedings of the Conferenceon High Performance Graphics 2009 (New York, NY, USA, 2009), ACM, pp. 159
–166. doi:http://doi.acm.org/10.1145/1572769.1572795. 4
[Cof11] COFFIN C.: Spu-based deferred shading in battlefield 3 for playstation 3. GDC 2011, 2011. URL:
http://www.slideshare.net/DICEStudio/spubased-deferred-shading-in-battlefield.-3-for-playstation-3. 2
[Cry10] Cryengine3 | crytek | sponza model, 2010. URL:http://www.crytek.com/cryengine/cryengine3/downloads. 7
[DWS_88] DEERING M., WINNER S., SCHEDIWY B., DUFFY C., HUNT N.: The triangle processor and normal vector sha
der: a vlsi system for high performance graphics. SIGGRAPH Comput.Graph. 22, 4(1988), 21–30. doi:http://doi.acm.org/10.1145/378456.378468. 2
[Epi11] EPIC GAMES: Unreal development kit, 2011. URL:http://www.udk.com/. 7
[ESSL10] ENDERTON E., SINTORN E.,SHIRLEY P., LUEBKED.: Stochastic transparency. In I3D ’10: Proceedingsof the 2010 ACM SIGGRAPH symposiumon Interactive3D Graphics and Games (New York, NY,USA, 2010), ACM,pp. 157–164.
doi:http://doi.acm.org.proxy.lib.chalmers.se/10.1145/1730804.1730830. 2
[FC11] FERRIER A., COFFIN C.: Deferred shading techniques sing frostbite in "battlefield 3" and "need for speed the run".In
ACM SIGGRAPH 2011 Talks (New York,NY, USA, 2011),SIGGRAPH ’11, ACM,pp. 33:1–33:1.
doi:10.1145/2037826.2037869. 2
[GL10] GARANZHA K., LOOP C.: Fast ray sorting and breadthfirst acket traversal for gpu ray tracing. Computer Graphics For
um 9, 2 (2010), 289–298. doi:10.1111/j.1467-8659.2009.01598.x. 2, 3
[HB10] HOBEROCK J., BELL N.: Thrust:A parallel template ibrary, 2010. Version1.3.0.
URL: http://www.meganewtons.com/. 4, 7
[HM08] HUNT W., MARK W. R.: Ray-specialized acceleration tructures for ray tracing. In IEEE/EG Symposium on Interactive
Ray Tracing 2008 (Aug 2008), IEEE/EG,pp. 3–10. 3
[HPLdW10] HOLLEMEERSCH C.-F., PIETERS B., LAMBERT P.,DE WALLE R.V.: Accelerating virtual texturing using cud
a. In GPU Pro, Engel W., (Ed.). A K Peters, 2010, pp. 623–642. 2















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









