







参考资料:R语言实战【第2版】
在划分聚类分析中,观测值被分为K组并根据给定的规则改组成最具有粘性的类。其中最常见就是K均值聚类分析。
K均值聚类算法如下;
(1)选择K个中心点(随机选择K个观测/数据行)
(2)把每个数据点分配到距它最近的中心点
(3)重新计算每类中的点到该类中心点的平均值(也就是说,得到长度为p的均值向量,这里的p为变量的个数)
(4)分配每个数据到它最近的中心点
(5)重复步骤(3)和步骤(4)直到所有的观测值不再被分配或是达到最大迭代次数(R把10次作为默认的迭代次数)。
这种方法的实施细节可以变化。R软件使用Hartigan & Wong提出的有效算法,这种算法是把观测值分成k组并使得观测值到其指定的聚类中心的平方的总和为最小。也就是说,在步骤(2)和步骤(4)中,每个观测值被分配到使下式得到最小值的那一类中:
xij表示第i个观测值中第j个变量的值。表示第k个类中第j个变量的均值,其中p为变量的个数。
K均值聚类能处理比层次聚类更大的数据集。另外,观测值不会永远被分到一类中。当我们提高整体解决方案时,聚类方案也会变动。但均值的使用意味着所有的变量必须是连续的,并且这个方法很有可能被异常值影响。它在非凸聚类(例如U型)情况下也会变得很差。
在R中K均值的函数格式是kmean(x,centers),这里x表示数值数据集(矩阵或数据框),centers是要提取的聚类数目。函数返回类的成员、类中心、平方和(类内平方和、类间平方和、总平方和)和类大小。
由于K均值聚类在开始要随机选择k个中心点,在每次调用函数时可能获得不同的方案。使用set.seed()函数可以保证结果可以复现。此外,聚类方法对初始中心值的选择也很敏感。kmeans()函数有一个nstart选项尝试多种初始配置并输出最好的一个。例如,加上nstart=25会生成25个初始配置。通常推荐使用这种方法。
不像层次聚类方法,K均值聚类要求我们事先确定要提取的聚类个数。同样,NbClust包也可以用来作为参考。另外,在K均值聚类中,类中总的平方值对聚类数量的曲线可能是有帮助的。可根据图中的弯曲选择适当的类的数量。图像生成的代码如下:
wssplot<-function(data,nc=15,seed=1234){
wss<-(nrow(data)-1)*sum(apply(data,2,var))
for(i in 2:nc){
set.seed(seed)
wss[i]<-sum(kmeans(data,centers=i)$withinss)}
plot(1:nc,wss,typ="b",
xlab="Number of Clusters",
ylab="Within groups sum of squares")
}上面的函数中,data参数是用来分析的数据数据,nc是要考虑的最大聚类个数,而seed是一个随机数种子。
让我们用K均值聚类来处理包含178种意大利葡萄酒中13种化学成分的数据集。该数据最初来自于UCI机器学习库。我们可以通过rattle包获得。在这个数据集里,观测值代表三种葡萄酒的品种,由第一个变量(类型)表示。我们可以放弃这一变量,进行聚类分析,看看是否可以恢复已知的结构。
# 加载wine数据集
data(wine,package="rattle")
# 查看数据集
head(wine)
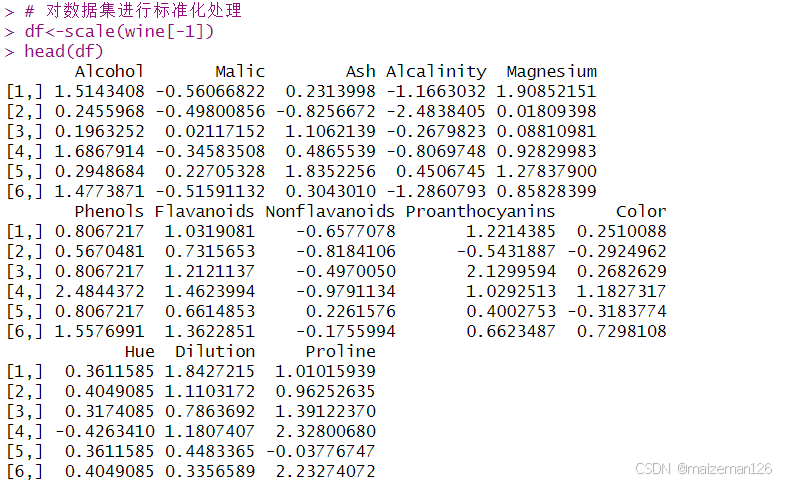
# 对数据集进行标准化处理
df<-scale(wine[-1])
head(df)
# 绘制曲线,查看适宜聚类个数
wssplot(df)
# 加载NbClust包
library(NbClust)
nc<-NbClust(df,min.nc=2,max.nc=15,method="kmeans")
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),
xlab="Number of Clusters",
ylab="Number of Criteria",
main="Number of Clusters Chosen by 26 criteria")
set.seed(1234)
# K均值聚类
fit.km<-kmeans(df,3,nstart=25)
fit.km$size
fit.km$centers
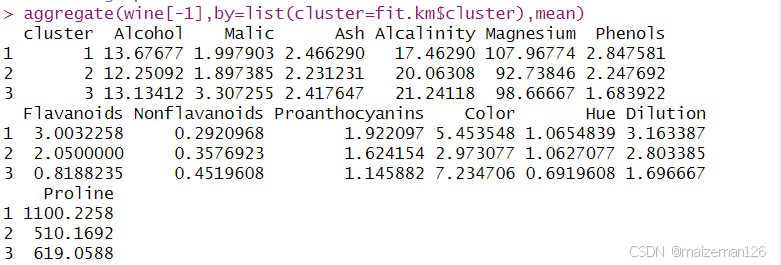
aggregate(wine[-1],by=list(cluster=fit.km$cluster),mean)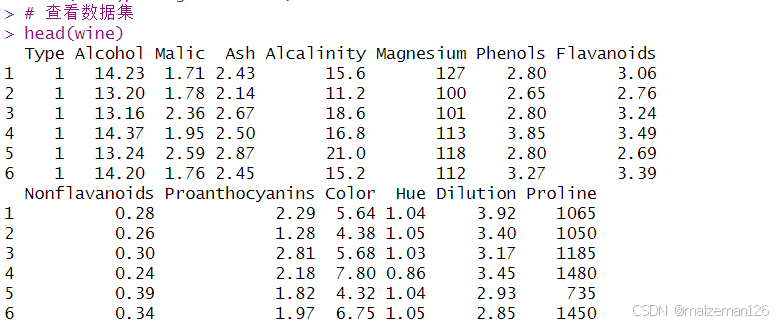
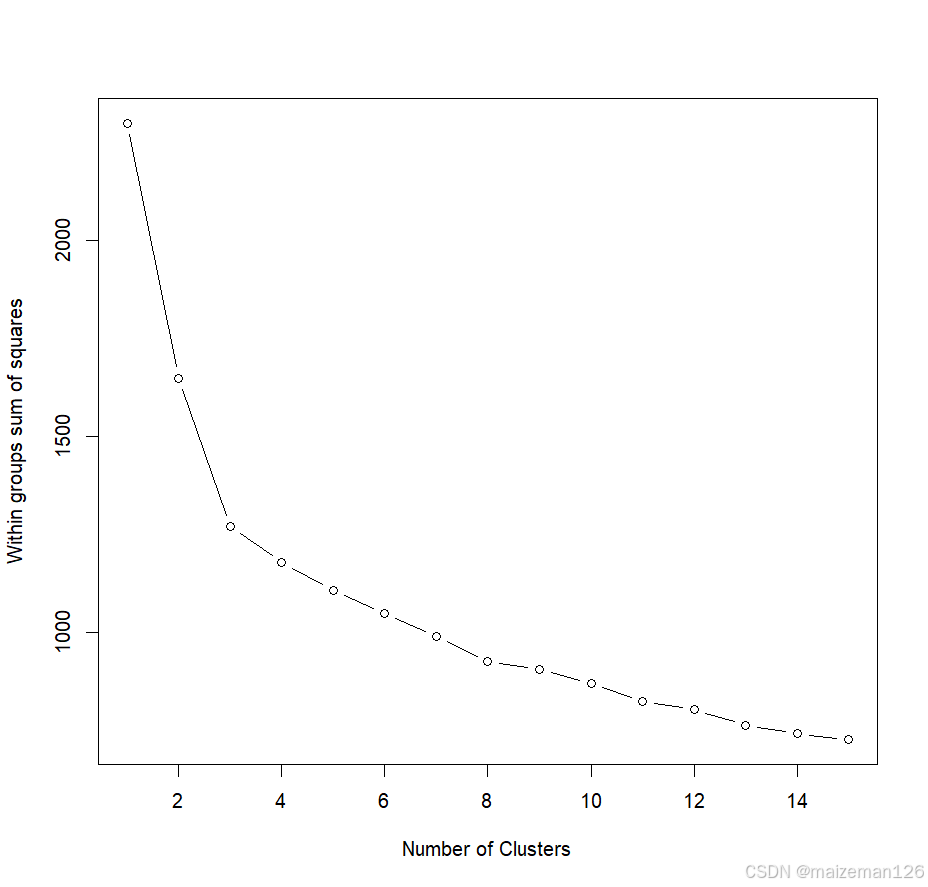
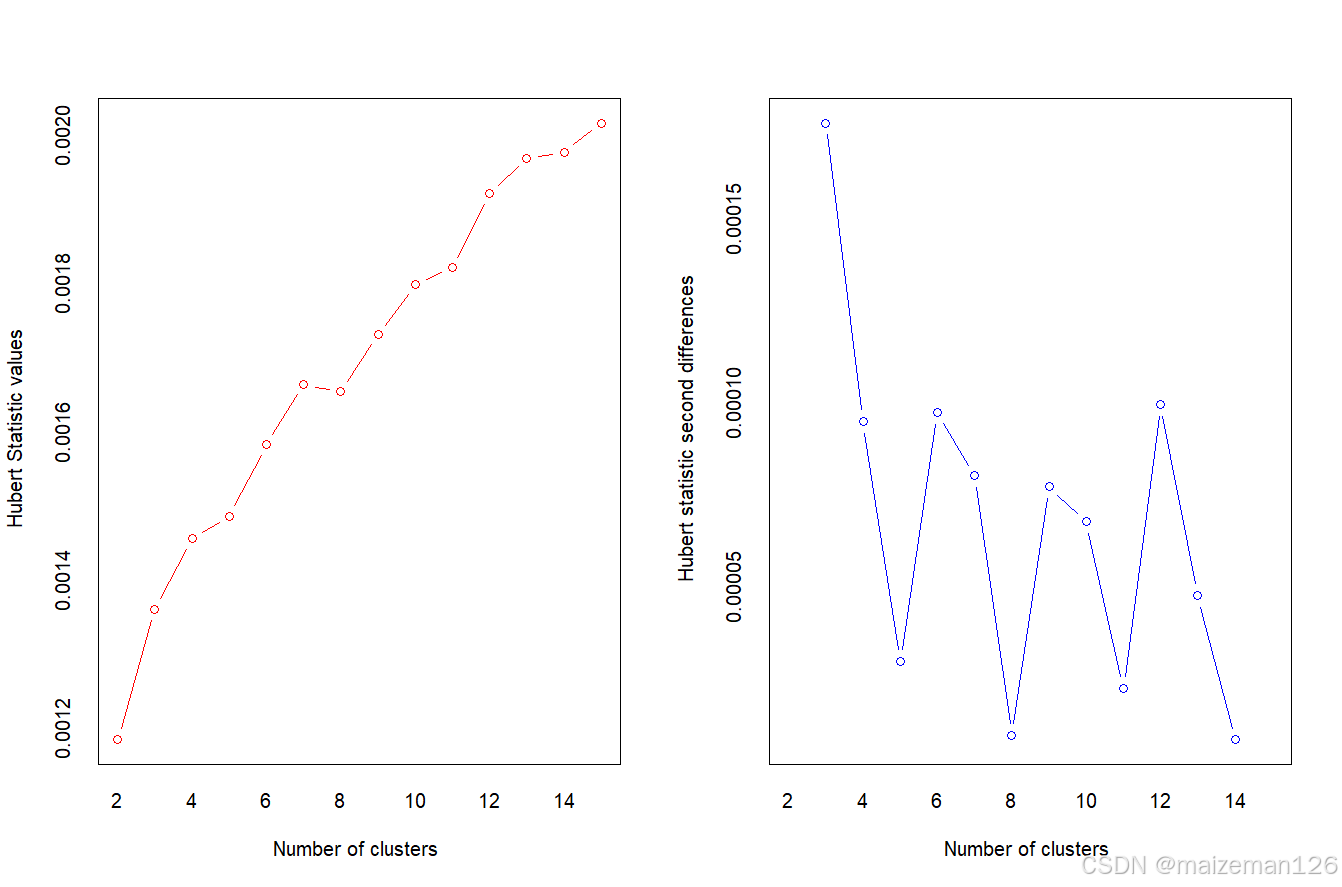
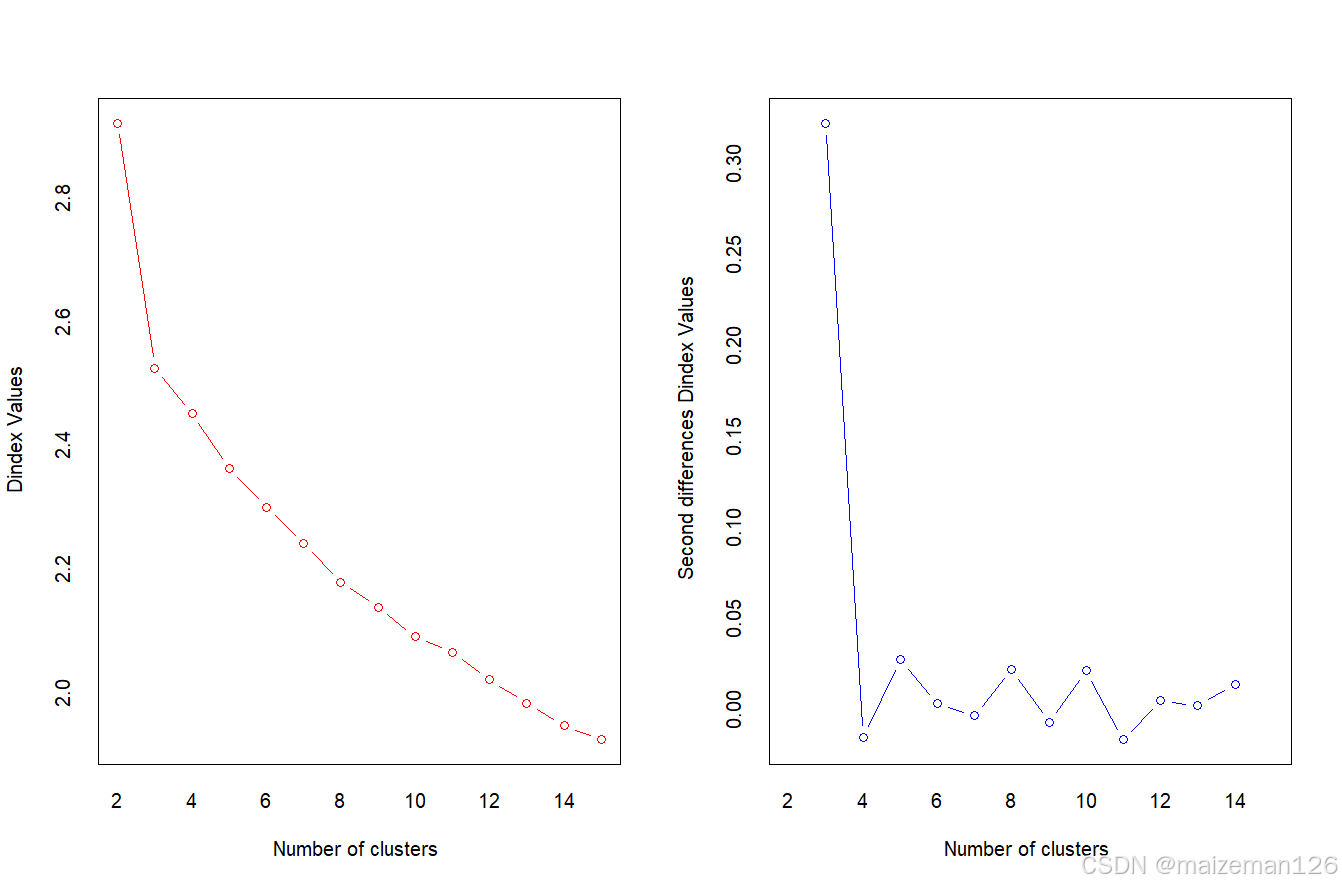
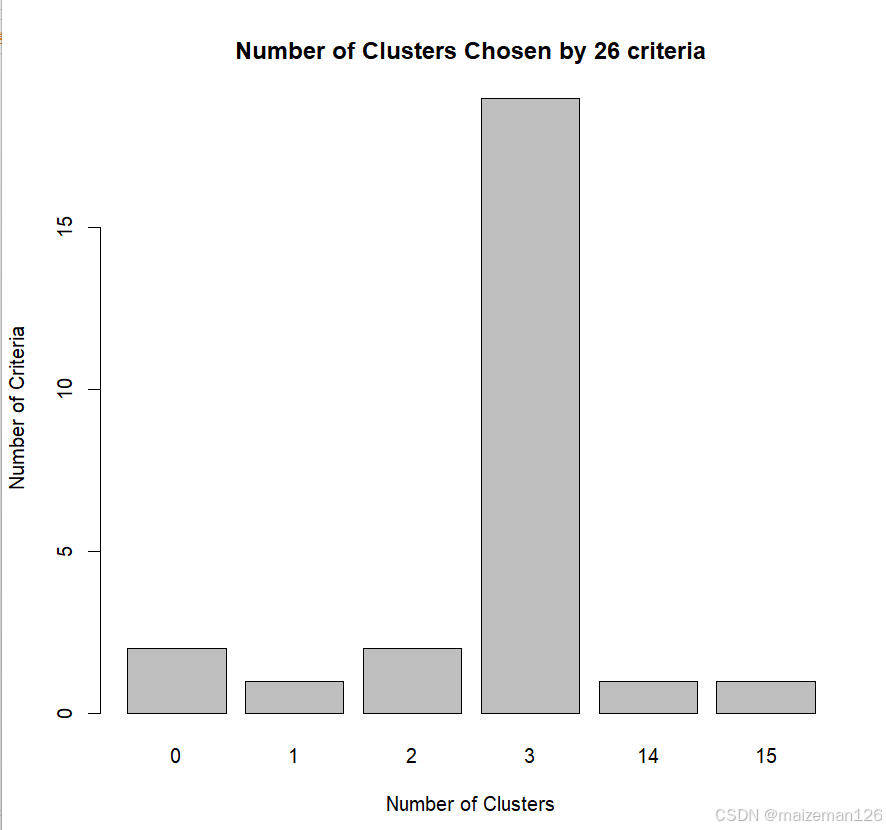
本例中因为变量值变化比较大,需要在聚类前要将其标准化。使用wssplot()自定义函数和NbClust()函数综合判断聚类的个数。wssplot的图显示组内的平方总和有一个明显的下降趋势。三类之后,下降的速度减弱,暗示着聚成三类可能对数据来说是一个很好的拟合。NbClust包中的24种指标中有14种建议使用类别数为三的聚类方案。需要注意的是并非30个指标都可以计算每个数据集。
K均值聚类可以很好地揭示类型变量中真正的数据结构吗?交叉列表类型(葡萄酒品种)和类成员由下面的代码表示:

我们还可以用flexclust包中的兰德指数(Rand index)来量化类型变量与类之间的协议:

调整的兰德指数为两种划分提供了一种衡量两个分区之间的协议,即调整后机会的量度。它的变化范围是从–1(不同意)到1 (完全同意)。葡萄酒品种类型和类的解决方案之间的协定是0.9,说明分类结果不错。

















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









