






Deep Learning for Image Super-resolution: A Survey
1. 介绍
2. 问题设置和术语
3. 有监督的超分放大
3.1 框架
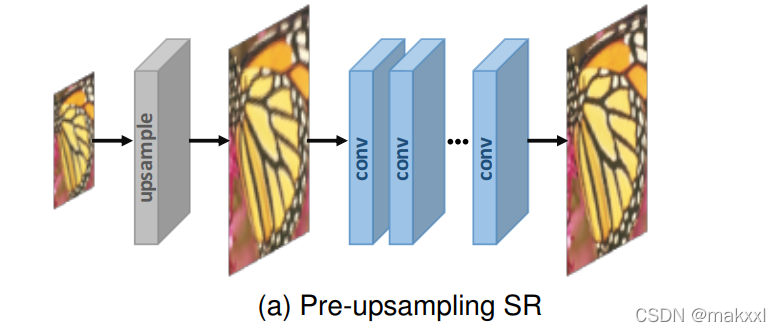
3.1.1预上采样:
采样三次插值上采样得到相应尺寸图像,采用SRCNN完成从插值LR到HR的端到端映射。神经网路并没有发挥太多作用
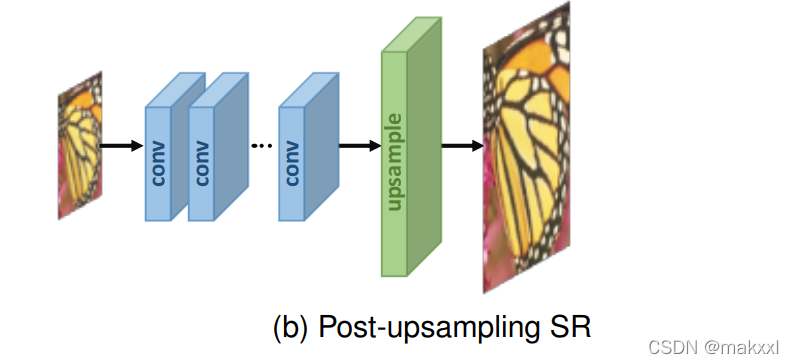
3.1.2后上采样:
将具有大计算量的特征提取工作放在低维,增加分辨率放在后面,计算量和空间复杂度会降低。
缺点:① 上采样只有一步,增加了大尺度因子的学习难度; ② 每个缩放因子需要训练一个独立的超分模型,无法应对多尺度SR的需求。
3.1.3渐进式上采样:
每一阶段,上采样到更高分辨率之后,CNN来修复
优点:将困难的任务分解为简单的任务,降低学习难度,不引入过多空间和时间成本;
——可以整合curriculum learning(3.4.3)和多监督(3.4.4)等一些具体学习策略,进一步降低学习难度
缺点:多阶段模型设计复杂、训练稳定性;
3.1.4迭代上下采样:
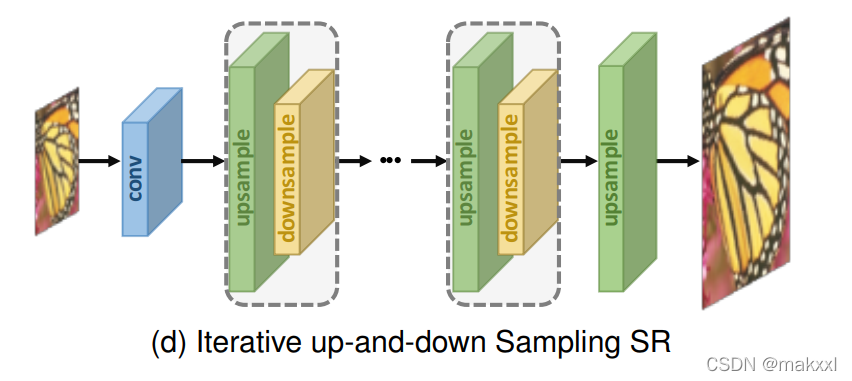
DBPN: 交替连接上采样和下采样,使用中间重建来重建最终的HR结果;
SRFBN: 采用上下采样反馈块,更密集的跳过连接并学习更好的表示;
RBPN: 从连续视频帧中提取上下文,结合上下文,通过反投影模块生成循环输出帧[87]
3.2 上采样
3.2.1 基于插值
分类:
- 邻近
- 双线性
- 双三次
BCI, 产生更少的伪影,速度慢
——带抗锯齿的BCI是主流方法
缺点:只根据自身图片,而没有引入更多其他信息;
副作用:计算复杂度、噪声放大、结果模糊
3.2.2基于学习
-
转置卷积层
插入0和执行卷积
会在每个像素上引入不均匀重叠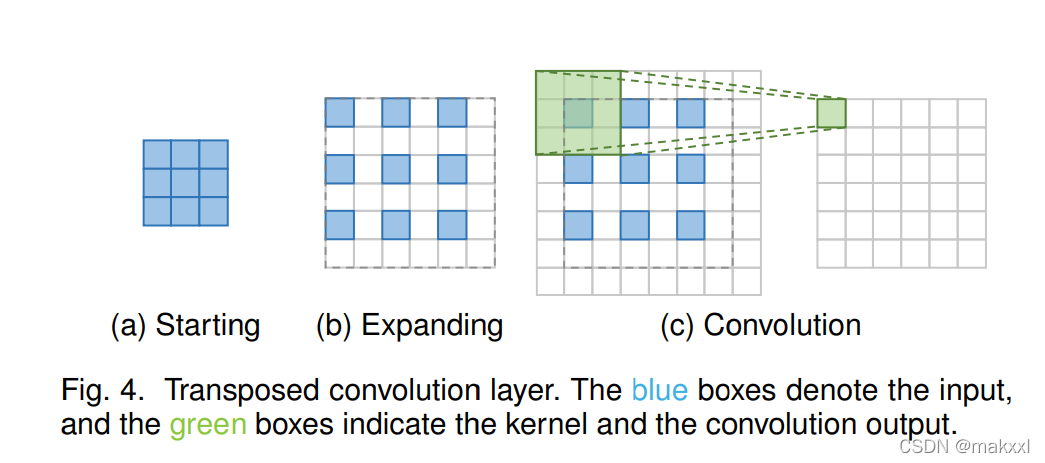
-
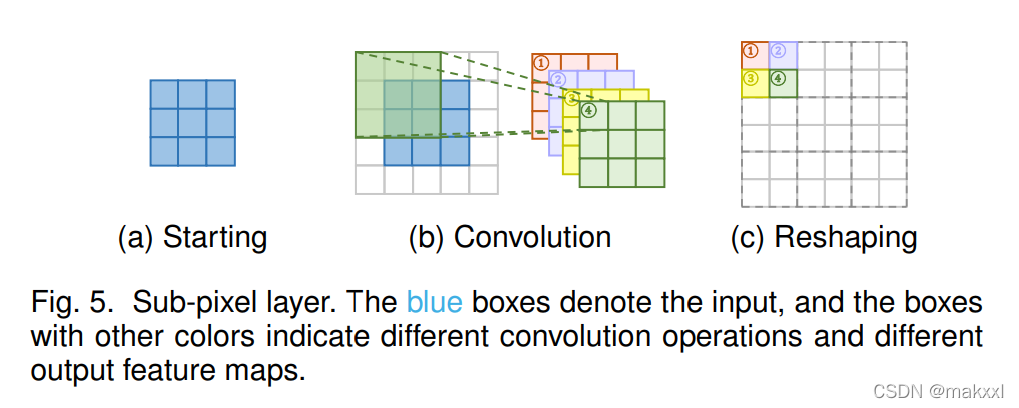
亚像素层
通过卷积生成多个通道,对其进行整形来执行上采样
优点:有更大的感受野,更多的上下文信息,胜场更逼真的细节;
缺点:感受野分布不均匀,块状区域共享相同的感受野,在不同块的边界附近产生伪影;输出不平滑;
Gao et al. [94] propose PixelTCL将独立的预测替换为相互依赖的顺序预测,更加平滑和一致
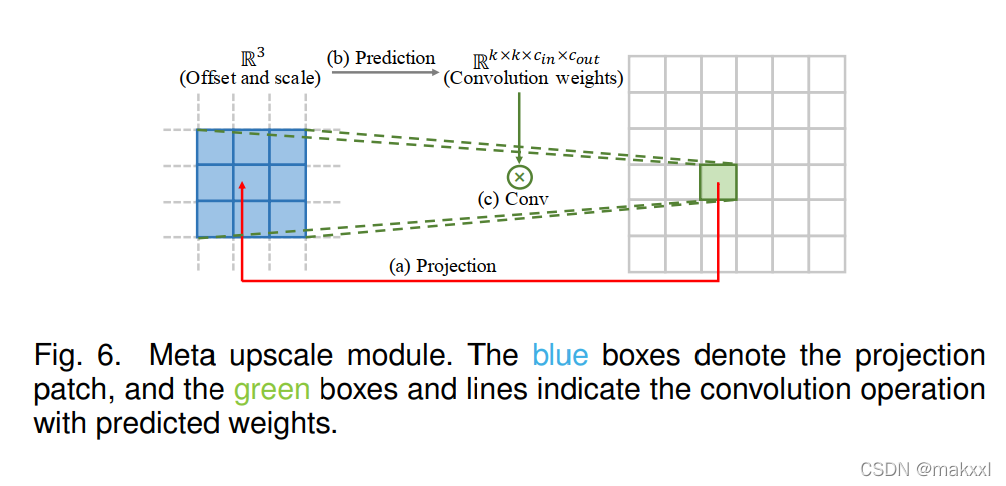
-
元放大模块
不需要提前确定参数,基于元学习的任意比例因子的SR:HR上的一个目标位置投影到LR特征图上的一小块,预测卷积权重,根据投影的偏移和密集层的缩放因子,执行卷积。
预测因子只占据1%的特征提取时间
缺点:基于独立于图像本身的值来预测每个目标像素的大量卷积权重,在面对较大的放大倍率时可能不稳定且效率低。
3.3 网络设计
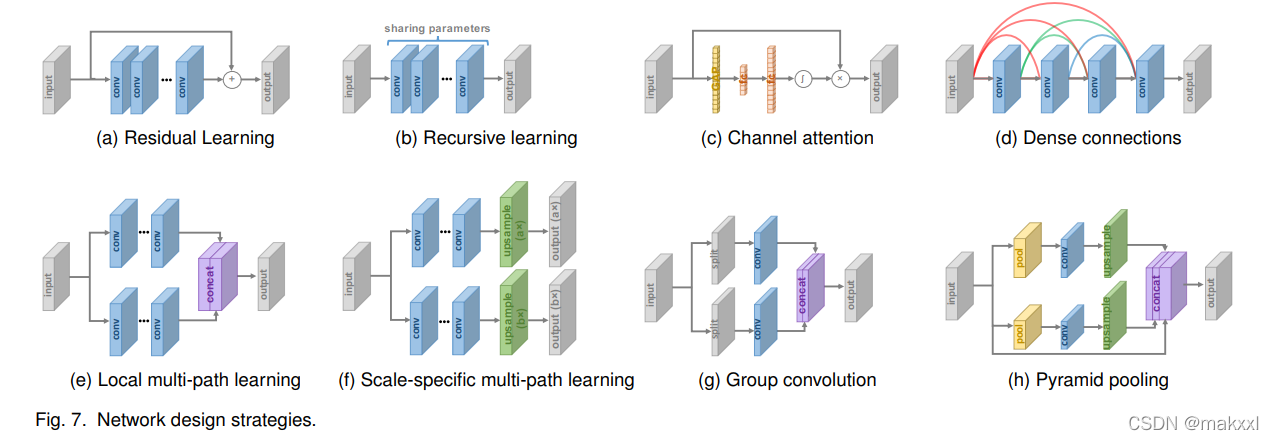
3.3.1 残差学习
ResNet
-
全局
学习输入图像和目标图像之间的残差,来恢复高频细节,由于大部分区域的残差接近于0,复杂度和学习难度降低。 -
局部
减轻网络深度和训练难度,提高学习能力
3.3.2 递归学习
重复使用一个模型,减少参数
① 16-recursive DRCN: 要给单独的卷积层作为递归单元,达到4141的感受野,远大于SRCNN的1313感受野;
② DRRN:使用一个ResBlock作为递归单元,效果好于17-ResBlock
③ MemNet: 基于记忆块,6-recursive ResBlock组成,每个递归的输出连接起来,经过一个额外的1*1卷积用于记忆和遗忘
④ CARN级联残差网络:采用一个类似的递归单元,包括一些ResBlock
还有在不同的部分用不同的递归模块:dual-state recurrent network (DSRN)
优点:不引入过多参数学习更高级的表示
缺点:计算成本高,梯度消失/爆炸
——和残差学习/多监督学习结合以缓解
3.3.3 多路径学习
-
全局
LapSRN、DSRN -
局部
MSRN:两个不同内核的卷积同时提取特征,输出连接再次进行相同的操作,应用1*1的卷积 -
特定尺度
CARN、ProSR
不同规模共享单个网络的多尺度SR,在开始和结束处加上预处理和上采样的特定尺度的结构
只有对应规模的路径会起作用
优点:减少了模型规模,不同规模的输入共享参数
3.3.4 密集连接
DesNet:块里每一层,将前面所有层提取的特征作为输入,l层有l*(l-1)/2个连接
优点:减轻梯度爆炸,扩大信号传播,特征复用,减小模型规模
3.3.5 注意力机制
结合注意力
- 通道注意力
- 非局部注意力
一些远处的像素会对局部补丁生成产生重要影响,用于捕获长距离空间的上下文信息
3.3.6 高级卷积
- 扩张卷积
- 组卷积
- 深度可分离卷积
3.3.7 区域递归学习
像素递归学习,逐像素生成
3.3.8 金字塔池化
更好利用全局和局部的上下文信息
3.3.9 小波变换
表示纹理细节的高频子带+包含全局信息的低频子带,高效图像表示。
3.4 学习策略
3.4.1 损失函数
像素损失:没有考虑图像质量,缺乏高频细节,在感知上对过渡平滑的纹理并不是很好
内容损失:鼓励感知上相似,而不是精确匹配像素
纹理损失:
对抗性损失:把SR看成一个生成器,定义一个新的判别器
循环一致性损失、总变异损失、基于先验的损失(人脸对齐)
ps:内容损失、纹理损失基于先验知识,通过更多的先验知识可以提高性能;可以结合多个损失函数,并赋予权重,但是如何有效规定权重和损失函数组合是个问题。
3.4.2 批量归一化
校准了中间特征分布并且减轻了梯度消失,允许更高的学习率并对初始化不关心;
缺点:丢失了图像的尺度信息
3.4.3 课程学习
简单的任务开始并逐步增加难度,减少了训练时间
3.4.4 多监督
添加多个监督信号,防止梯度爆炸/消失
噪声放大问题
DNSR:分别训练去噪网络和SR网络,防止超分带来的噪声放大
模糊问题
GAN会有,网络插值来改进:训练一个基于PSNR的模型+训练一个基于GAN的模型,两者插值推导出中间模型,减少伪影
自集成(增强预测)
LR进行变换得到8组图像,分别进行相应变换,最终8个预测结果求平均
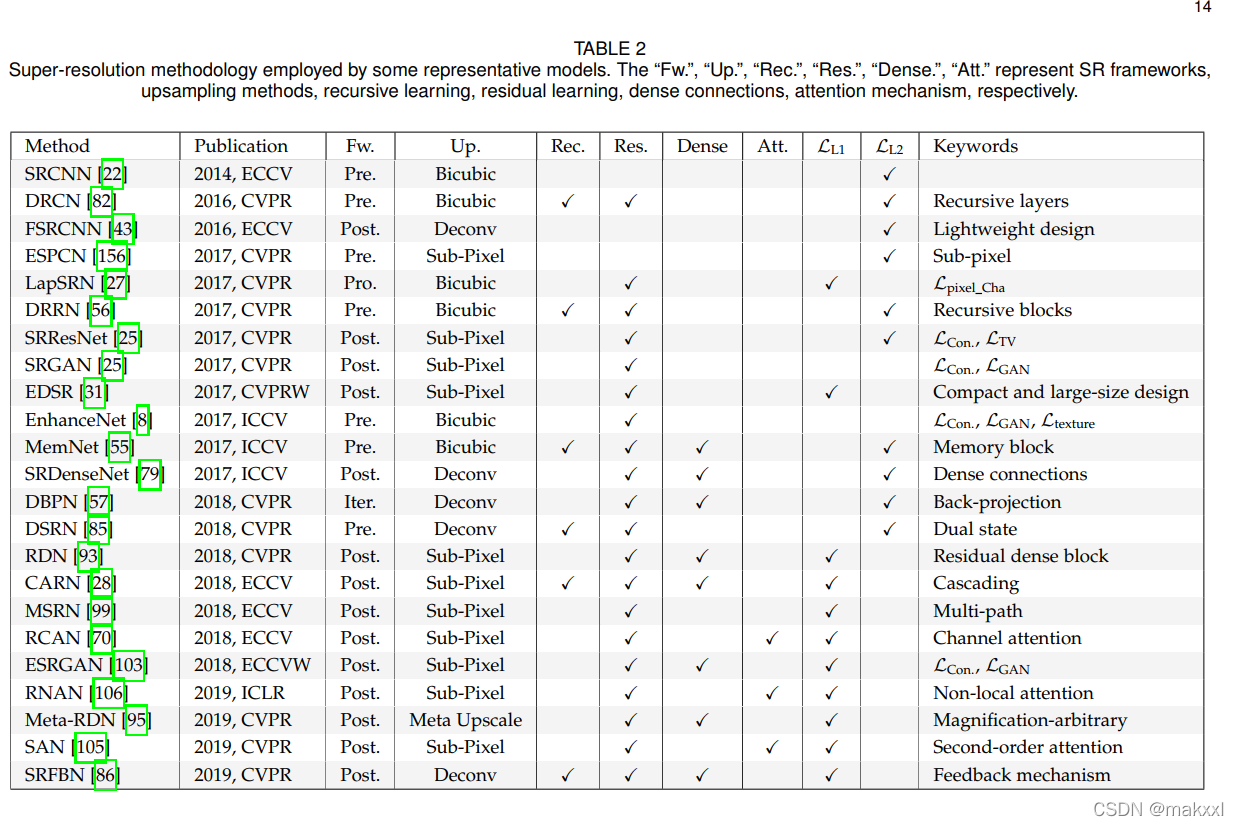
3.6 先进的SR模型
由上述的一些模块拼接而成
RCAN:通道注意力机制+亚像素上采样+残差学习+L1损失+自集成
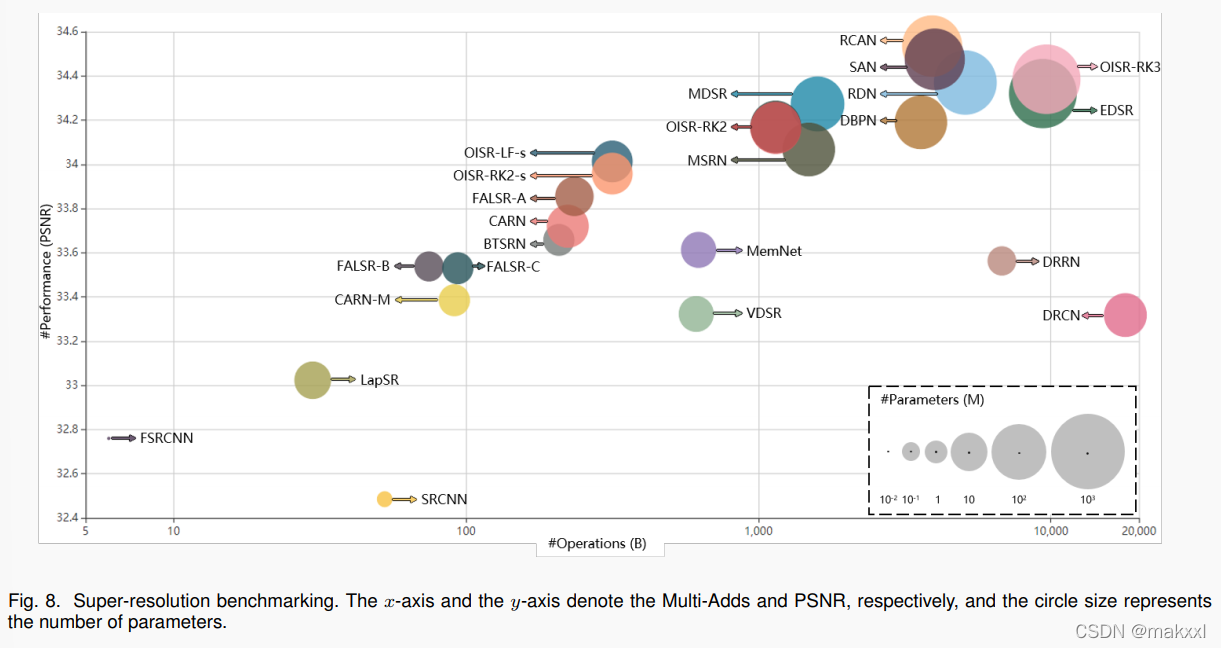
测试:模型大小和计算成本——PyTorch-OpCounter
4. 无监督的超分放大
4.1 零镜头
针对单个图像设计网络,估计退化内核,使用内核在图像上使用不同的缩放因子和增强执行退化来得到小型数据集,训练小型CNN
4.2 弱监督
使用未配对的LR-HR图像
- 学习退化
根据已有的配对图像,来学习退化机理,采用两个阶段的生成对抗网络,第一步先学习HR-LR退化机理,第二步SR - 循环的SR
把LR和HR看成两个领域,CinCGAN、CycleGAN
4.3 深度图像先验
用深度学习来构建网络初始化?
5. 特定领域的应用
5.1 深度图像
姿态识别、语义分割
目前主流:用HR的同场景图像来指导LR的深度图
5.2 人脸图像
5.3 高光谱
与全色图像(PANs,具有三个波段)相比,高光谱(HSIs)提供了丰富的光谱特征
目前主流:结合HR的PAN和LR的HSI
5.4 真实世界
相机捕获12位/14位,通过相机ISP(图像处理器)来得到8位,丢掉很多原始信号,所以直接采用手动下采样的图像是次优的。
RV退化、数据采集策略得到数据集City100,相机的光学变焦构建数据集SR-RAW
5.5 视频
基于帧间时间空间依赖性:显式运动补偿(基于光流、基于学习)、循环方法
5.5.1 一些方法
①
采用光流方法来生成HR的候选帧,通过CNN集成
Among the optical flow-based methods, Liao et al. [190] employ optical flow methods to generate HR candidates and ensemble them by CNNs.
用Druleas算法来处理运动补偿,用CNN将连续帧作为输入预测HR帧
VSRnet [191] and CVSRnet [192] deal with motion compensation by Druleas algorithm [193], and uses CNNs to take successive frames as input
and predict HR frames.
进行校正光流对齐,提出一种时间自适应网络来生成各种时间尺度的HR并自适应聚合他们
While Liu et al. [194], [195] perform rectified optical flow alignment, and propose a temporal adaptive net to generate HR frames in various temporal scales and aggregate them adaptively
也可以直接学习运动补偿(基于相邻帧)
VESPCN使用可训练的空间转换器
精确的LR成像模型,提出了一种类似亚像素的模型来同时实现运动补偿和SR,更有效融合对其的帧
②
循环方法捕获时空依赖性,而不需要运动补偿
采用双向框架,CNN、RNN和条件CNN——时间、空间和时空依赖性建模
Specifically, the BRCN [197], [198] employs a bidirectional framework, and uses CNN, RNN, and conditional CNN to model the spatial, temporal and spatialtemporal dependency, respectively.
深度CNN和双向LSTM来提取空间和时间信息
Similarly, STCN [199] uses a deep CNN and a bidirectional LSTM [200] to extract spatial and temporal information.
使用先前推断的HR估计,用两个深度CNN以循环方式重建后续HR
And FRVSR [201] uses previously inferred HR estimates to reconstruct the subsequent HR frames by two deep CNNs in a recurrent manner.
两个很小的3D卷积滤波器代替大滤波器,更深的CNN提高性能
Recently the FSTRN [202] employs two much smaller 3D convolution filters to replace the original large filter, and thus enhances the performance through deeper CNNs while maintaining low computational cost.
循环编码-解码器来提取更深的时空上下文,将它们与基于反投影的迭代细化框架结合
While the RBPN [87] extracts spatial and temporal contexts by a recurrent encoder-decoder, and combines them with an iterative refinement framework based on the back-projection mechanism
FAST利用压缩算法提取结构和像素相关性的紧凑描述,将SR结果从一帧传输到相邻帧
[204]根据每个像素的局部时空邻域生成动态上采样滤波器和HR残差图像,同时避免显式运动补偿
5.6 其他应用
小物体检测、图像检索、立体图像















 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









