







课程地址:https://class.coursera.org/ntumlone-001/class
课件讲义:http://download.csdn.net/download/malele4th/10208897
注明:文中图片来自《机器学习基石》课程和部分博客
建议:建议读者学习林轩田老师原课程,本文对原课程有自己的改动和理解
第1讲
目录
一 什么是机器学习
使用Machine Learning 方法的关键:
1, 存在有待学习的“隐含模式”
2, 该模式不容易准确定义(直接通过程序实现)
3, 存在关于该模式的足够数据
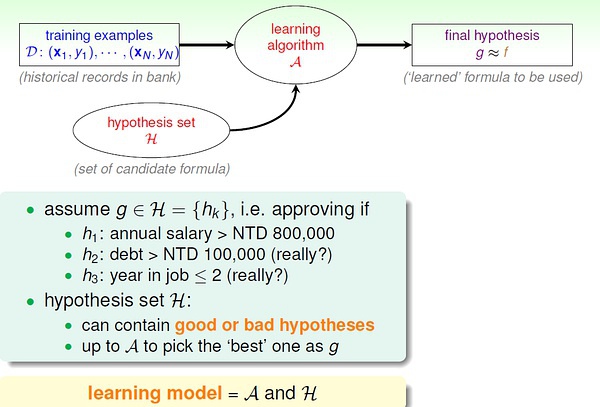
这里的f 表示理想的方案,g 表示我们求解的用来预测的假设。H 是假设空间。
通过算法A, 在假设空间中选择最好的假设作为g。
选择标准是 g 近似于 f。
二 机器学习与数据挖掘、人工智能、统计学的关系
1, Machine Learning vs. Data Mining
数据挖掘是利用(大量的)数据来发现有趣的性质。
1.1 如果这里的”有趣的性质“刚好和我们要求解的假设相同,那么ML=DM。
1.2 如果”有趣的性质“和我们要求的假设相关,那么数据挖掘能够帮助机器学习的任务,反过来,机器学习也有可能帮助挖掘(不一定)。
1.3 传统的数据挖掘关注如果在大规模数据(数据库)上的运算效率。
目前来看,机器学习和数据挖掘重叠越来越多,通常难以分开。
2, Machine Learning vs. Artificial Intelligence(AI)
人工智能是解决(运算)一些展现人的智能行为的任务。
2.1 机器学习通常能帮助实现AI。
2.2 AI 不一定通过ML 实现。
例如电脑下棋,可以通过传统的game tree 实现AI 程序;也可以通过机器学习方法(从大量历史下棋数据中学习)来实现。
3,Machine Learning vs. Statistics
统计学:利用数据来做一些位置过程的推断(推理)。
3.1 统计学可以帮助实现ML。
3.2 传统统计学更多关注数学假设的证明,不那么关心运算。
统计学为ML 提供很多方法/工具(tools)















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









