







Class 4:卷积神经网络
Week 1:卷积神经网络基础
目录
1、CNN: Step by Step
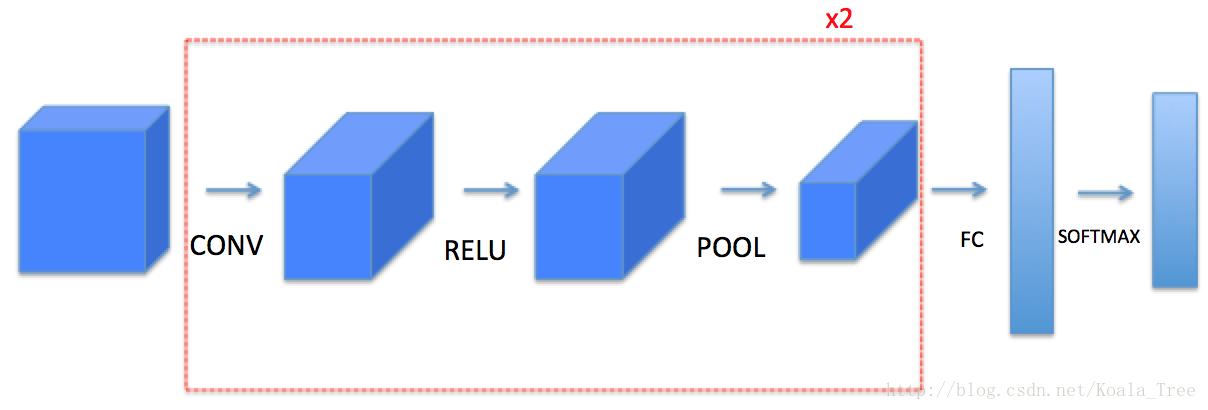
(1)卷积层

(2)池化层
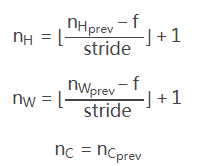
import numpy as np
import matplotlib.pyplot as plt
import h5py
# matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# 1、0填充
def zero_pad(X, pad):
"""
Pad with zeros all images of the dataset X.
The padding is applied to the height and width of an image.
Argument:
X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images
pad -- integer, amount of padding around each image on vertical and horizontal dimensions
Returns:
X_pad -- padded image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C)
"""
X_pad = np.pad(X, ((0,0), (pad,pad), (pad,pad), (0,0)), 'constant')
return X_pad
np.random.seed(1)
x = np.random.randn(4, 3, 3, 2)
x_pad = zero_pad(x, 2)
print ("x.shape =", x.shape)
print ("x_pad.shape =", x_pad.shape)
print ("x[1,1] =", x[1,1])
print ("x_pad[1,1] =", x_pad[1,1])
fig, axarr = plt.subplots(1, 2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
#plt.show()
# 2、单步卷积
def conv_single_step(a_slice_prev, W, b):
"""
Apply one filter defined by parameters W on a single slice (a_slice_prev)
of the output activation of the previous layer.
Arguments:
a_slice_prev -- slice of input data of shape (f, f, n_C_prev)
W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev)
b -- Bias parameters contained in a window - matrix of shape (1, 1, 1)
Returns:
Z -- a scalar value, result of convolving the sliding window (W, b)
on a slice x of the input data
"""
s = a_slice_prev * W # element_wise product between a_slice and W
Z = np.sum(s) # sum over all entries of the volume s
Z = Z + b # add bias b to Z to a float(),因此 Z in a scalar value
return Z
np.random.seed(2)
a_slice_prev = np.random.randn(4, 4, 3)
W = np.random.randn(4, 4, 3)
b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b)
print("Z =", Z)
# 3、前向卷积
def conv_forward(A_prev, W, b, hparameters):
"""
Implements the forward propagation for a convolution function
Arguments:
A_prev -- output activations of the previous layer,
numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
W -- Weights, numpy array of shape (f, f, n_C_prev, n_C)
b -- Biases, numpy array of shape (1, 1, 1, n_C)
hparameters -- python dictionary containing "stride" and "pad"
Returns:
Z -- conv output, numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward() function
"""
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters["stride"]
pad = hparameters["pad"]
# 计算conv 输出维度
n_H = int((n_H_prev - f + 2*pad)/stride + 1)
n_W = int((n_W_prev - f + 2*pad)/stride + 1)
# 用0初始化输出Z
Z = np.zeros((m, n_H, n_W, n_C))
# padding A_prev
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m): # 循环所有的训练样本
a_prev_pad = A_prev_pad[i,:,:,:]
for h in range(n_H): # 循环输出的所有垂直轴
for w in range(n_W): # 循环输出的所有水平轴
for c in range(n_C): # 循环输出的所有通道数(=滤波器数)
# 寻找当前 “slice” 的 corners
vert_start = stride * h
vert_end = vert_start + f
horiz_start = stride * w
horiz_end = horiz_start + f
# 使用 corners 定义3D slice 在当前的 prev_pad
a_slice_prev = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
# convolve 3D slice
Z[i, h, w, c] = conv_single_step(a_slice_prev, W[:,:,:,c], b[:,:,:,c])
# 确保输出的形状是正确的
assert(Z.shape == (m, n_H, n_W, n_C))
cache = (A_prev, W, b, hparameters)
return Z, cache
np.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
print("Z's mean =", np.mean(Z))
print("Z[3,2,1] =", Z[3,2,1])
print("cache_conv[0][1][2][3] =", cache_conv[0][1][2][3])
# 4、前向池化
def pool_forward(A_prev, hparameters, mode="max"):
"""
Implements the forward pass of the pooling layer
Arguments:
A_prev -- Input data, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
hparameters -- python dictionary containing "f" and "stride"
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
A -- output of the pool layer, a numpy array of shape (m, n_H, n_W, n_C)
cache -- cache used in the backward pass of the pooling layer,
contains the input and hparameters
"""
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
f = hparameters["f"]
stride = hparameters["stride"]
# 定义输出维度
n_H = int(1 + (n_H_prev - f)/stride)
n_W = int(1 + (n_W_prev - f)/stride)
n_C = n_C_prev
# 0初始化输出
A = np.zeros((m, n_H, n_W, n_C))
for i in range(m):
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
# 寻找当前 “slice” 的角
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
if mode == "max":
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":
A[i, h, w, c] = np.mean(a_prev_slice)
cache = (A_prev, hparameters)
assert(A.shape == (m, n_H, n_W, n_C))
return A, cache
np.random.seed(1)
A_prev = np.random.randn(2, 4, 4, 3)
hparameters = {"stride" : 2, "f": 3}
A, cache = pool_forward(A_prev, hparameters)
print("mode = max")
print("A =", A)
print()
A, cache = pool_forward(A_prev, hparameters, mode = "average")
print("mode = average")
print("A =", A)
# 5、卷积层反向传播
def conv_backward(dz, cache):
"""
Implement the backward propagation for a convolution function
Arguments:
dZ -- gradient of the cost with respect to the output of the conv layer (Z),
numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward(), output of conv_forward()
Returns:
dA_prev -- gradient of the cost with respect to the input of the conv layer (A_prev),
numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
dW -- gradient of the cost with respect to the weights of the conv layer (W)
numpy array of shape (f, f, n_C_prev, n_C)
db -- gradient of the cost with respect to the biases of the conv layer (b)
numpy array of shape (1, 1, 1, n_C)
"""
(A_prev, W, b, hparameters) = cache
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters["stride"]
pad = hparameters["pad"]
(m, n_H, n_W, n_C) = dz.shape
# 初始化 dA_prev, dW, db
dA_prev = np.zeros((m, n_H_prev, n_W_prev, n_C_prev))
dW = np.zeros((f, f, n_C_prev, n_C))
db = np.zeros((1, 1, 1, n_C))
# pad A_prev、dA_prev
A_prev_pad = zero_pad(A_prev, pad)
dA_prev_pad = zero_pad(dA_prev, pad)
for i in range(m):
a_prev_pad = A_prev_pad[i,:,:,:]
da_prev_pad = dA_prev_pad[i,:,:,:]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
# Find the corners of the current "slice"
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# Use the corners to define the slice from a_prev_pad
a_slice = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
# 更新梯度,for the window and the filter's parameters
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dz[i, h, w, c]
dW[:,:,:,c] += a_slice * dz[i,h,w,c]
db[:,:,:,c] += dz[i,h,w,c]
dA_prev[i,:,:,:] = da_prev_pad[pad:-pad, pad:-pad, :]
assert(dA_prev.shape ==(m, n_H_prev, n_W_prev, n_C_prev))
return dA_prev, dW, db
np.random.seed(1)
dA, dW, db = conv_backward(Z, cache_conv)
print("dA_mean =", np.mean(dA))
print("dW_mean =", np.mean(dW))
print("db_mean =", np.mean(db))
# 6、池化层后向传播
# 6-1、创建 “mask” 矩阵
def create_mask_from_window(x):
"""
Creates a mask from an input matrix x, to identify the max entry of x.
Arguments:
x -- Array of shape (f, f)
Returns:
mask -- Array of the same shape as window,
contains a True at the position corresponding to the max entry of x.
"""
mask = (x == np.max(x))
return mask
np.random.seed(1)
x = np.random.randn(2,3)
mask = create_mask_from_window(x)
print('x = ', x)
print("mask = ", mask)
# 6-2、通过维度形状的矩阵来平均分配值dz
def distribute_value(dz, shape):
"""
Distributes the input value in the matrix of dimension shape
Arguments:
dz -- input scalar
shape -- the shape (n_H, n_W) of the output matrix for which
we want to distribute the value of dz
Returns:
a -- Array of size (n_H, n_W) for which we distributed the value of dz
"""
(n_H, n_W) = shape
average = dz/(n_H * n_W)
a = average * np.ones(shape)
return a
a = distribute_value(2, (2,2))
print('distributed value =', a)
# 6-3、Putting it together: Pooling backward
def pool_backward(dA, cache, mode="max"):
"""
Implements the backward pass of the pooling layer
Arguments:
dA -- gradient of cost with respect to the output of the pooling layer,
same shape as A
cache -- cache output from the forward pass of the pooling layer,
contains the layer's input and hparameters
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
dA_prev -- gradient of cost with respect to the input of the pooling layer,
same shape as A_prev
"""
(A_prev, hparameters) = cache
stride = hparameters['stride']
f = hparameters['f']
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
m, n_H, n_W, n_C = dA.shape
# Initialize dA_prev with zeros
dA_prev = np.zeros(np.shape(A_prev))
for i in range(m):
# select training example from A_prev
a_prev = A_prev[i, :, :, :]
for h in range(n_H): # loop on the vertical axis
for w in range(n_W): # loop on the horizontal axis
for c in range(n_C): # loop over the channels (depth)
# Find the corners of the current "slice"
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# Compute the backward propagation in both modes.
if mode == "max":
# Use the corners and "c" to define the current slice from a_prev
a_prev_slice = a_prev[vert_start:vert_end, horiz_start:horiz_end, c]
# Create the mask from a_prev_slice
mask = create_mask_from_window(a_prev_slice)
# Set dA_prev to be dA_prev + (the mask multiplied by the correct entry of dA)
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += np.multiply(mask, dA[i, h, w, c])
elif mode == "average":
# Get the value a from dA
da = dA[i, h, w, c]
# Define the shape of the filter as fxf
shape = (f, f)
# Distribute it to get the correct slice of dA_prev. i.e. Add the distributed value of da.
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)
# Making sure your output shape is correct
assert(dA_prev.shape == A_prev.shape)
return dA_prev
np.random.seed(1)
A_prev = np.random.randn(5, 5, 3, 2)
hparameters = {"stride" : 1, "f": 2}
A, cache = pool_forward(A_prev, hparameters)
dA = np.random.randn(5, 4, 2, 2)
dA_prev = pool_backward(dA, cache, mode = "max")
print("mode = max")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
print()
dA_prev = pool_backward(dA, cache, mode = "average")
print("mode = average")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
x.shape = (4, 3, 3, 2)
x_pad.shape = (4, 7, 7, 2)
x[1,1] = [[ 0.90085595 -0.68372786]
[-0.12289023 -0.93576943]
[-0.26788808 0.53035547]]
x_pad[1,1] = [[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]]
Z = [[[-6.1034344]]]
Z's mean = 0.0489952035289
Z[3,2,1] = [-0.61490741 -6.7439236 -2.55153897 1.75698377 3.56208902 0.53036437
5.18531798 8.75898442]
cache_conv[0][1][2][3] = [-0.20075807 0.18656139 0.41005165]
mode = max
A = [[[[ 1.74481176 0.86540763 1.13376944]]]
[[[ 1.13162939 1.51981682 2.18557541]]]]
mode = average
A = [[[[ 0.02105773 -0.20328806 -0.40389855]]]
[[[-0.22154621 0.51716526 0.48155844]]]]
dA_mean = 1.45243777754
dW_mean = 1.72699145831
db_mean = 7.83923256462
x = [[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]]
mask = [[ True False False]
[False False False]]
distributed value = [[ 0.5 0.5]
[ 0.5 0.5]]
mode = max
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0. 0. ]
[ 5.05844394 -1.68282702]
[ 0. 0. ]]
mode = average
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0.08485462 0.2787552 ]
[ 1.26461098 -0.25749373]
[ 1.17975636 -0.53624893]]2、CNN:TensorFlow
import math
import h5py
import scipy
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.framework import ops
from PIL import Image
from cnn_utils import *
np.random.seed(1)
# 1、搭建 CNN
# 1-1、创建占位符
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
Creates the placeholders for the tensorflow session.
Arguments:
n_H0 -- scalar, height of an input image
n_W0 -- scalar, width of an input image
n_C0 -- scalar, number of channels of the input
n_y -- scalar, number of classes
Returns:
X -- placeholder for the data input, of shape [None, n_H0, n_W0, n_C0] and dtype "float"
Y -- placeholder for the input labels, of shape [None, n_y] and dtype "float"
"""
X = tf.placeholder(tf.float32, shape=[None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32, shape=[None, n_y])
return X,Y
X, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
# 1-2、初始化参数
def initialize_parameters():
"""
Initializes weight parameters to build a neural network with tensorflow.
The shapes are:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
Returns:
parameters -- a dictionary of tensors containing W1, W2
"""
tf.set_random_seed(1)
W1 = tf.get_variable("W1", [4,4,3,8], initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2 = tf.get_variable("W2", [2,2,8,16], initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters = {"W1":W1,
"W2":W2}
return parameters
tf.reset_default_graph()
with tf.Session() as sess_test:
parameters = initialize_parameters()
init = tf.global_variables_initializer()
sess_test.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1])) # eval()将字符串转换成列表、字典、元组
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
# 1-3、前向传播
def forward_propagation(X, parameters):
"""
Implements the forward propagation for the model:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "W2"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
W1 = parameters['W1']
W2 = parameters['W2']
# 第一层卷积、激活、最大池化 2*64*64*3 -> 2*64*64*8 -> 2*8*8*8
Z1 = tf.nn.conv2d(X, W1, strides=[1,1,1,1], padding='SAME') #"SAME"输入输出特征维度相同
A1 = tf.nn.relu(Z1)
P1 = tf.nn.max_pool(A1, ksize=[1,8,8,1], strides=[1,8,8,1], padding='SAME')
# 第二层卷积、激活、最大池化 2*8*8*8 -> 2*8*8*16 -> 2*2*2*16
Z2 = tf.nn.conv2d(P1, W2, strides=[1,1,1,1], padding='SAME') #"VALID"没有填充
A2 = tf.nn.relu(Z2)
P2 = tf.nn.max_pool(A2, ksize=[1,4,4,1], strides=[1,4,4,1], padding='SAME')
# 全连接之前,平铺 2*2*2*16 -> 2*64
P2 = tf.contrib.layers.flatten(P2)
# 全连接层 2*64 -> 2*6
# 没有线性激活函数,不调用softmax,输出层6个神经元,
Z3 = tf.contrib.layers.fully_connected(P2, 6, activation_fn=None)
return Z3
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
# 1-4、计算代价函数
def compute_cost(Z3, Y):
"""
Computes the cost
Arguments:
Z3 -- output of forward propagation (output of the last LINEAR unit),
of shape (6, number of examples)
Y -- "true" labels vector placeholder, same shape as Z3
Returns:
cost - Tensor of the cost function
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))
return cost
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
# 1-5、model
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.01,
num_epochs=100, minibatch_size=64, print_cost=True):
"""
Implements a three-layer ConvNet in Tensorflow:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X_train -- training set, of shape (None, 64, 64, 3)
Y_train -- test set, of shape (None, n_y = 6)
X_test -- training set, of shape (None, 64, 64, 3)
Y_test -- test set, of shape (None, n_y = 6)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
train_accuracy -- real number, accuracy on the train set (X_train)
test_accuracy -- real number, testing accuracy on the test set (X_test)
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph() # 能重新运行模型,而不会覆盖tf变量
tf.set_random_seed(1) # 保持结果的一致性(tensorflow seed)
seed=3 # 保持结果的一致性(numpy seed)
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
# 构建 tf 模型
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
# start the Session to compute the tensorflow graph
with tf.Session() as sess:
# run the initialization
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m/minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
# run the session to execute the optimizer and the cost
# the feed_dict should contain a minibatch for (X, Y)
_, temp_cost = sess.run([optimizer, cost], feed_dict={X:minibatch_X, Y:minibatch_Y})
minibatch_cost += temp_cost/num_minibatches
if print_cost==True and epoch%10==0:
print("cost after epoch %i:%f" % (epoch, minibatch_cost))
if print_cost==True and epoch%1==0:
costs.append(minibatch_cost)
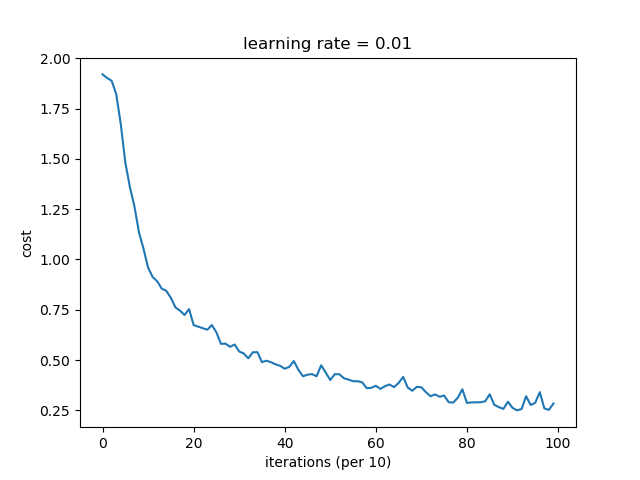
# plot cost
plt.plot(np.squeeze(costs))
plt.xlabel("iterations (per 10)")
plt.ylabel("cost")
plt.title("learning rate = " + str(learning_rate))
plt.show()
# 计算正确预测
predict_op = tf.argmax(Z3, 1)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
# 计算测试集正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(accuracy)
train_accuracy = accuracy.eval({X:X_train, Y:Y_train})
test_accuracy = accuracy.eval({X:X_test, Y:Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
# 2、数据处理
# 2-1、下载数据
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# 2-2、显示数据图片
index = 6
plt.imshow(X_train_orig[index])
plt.show()
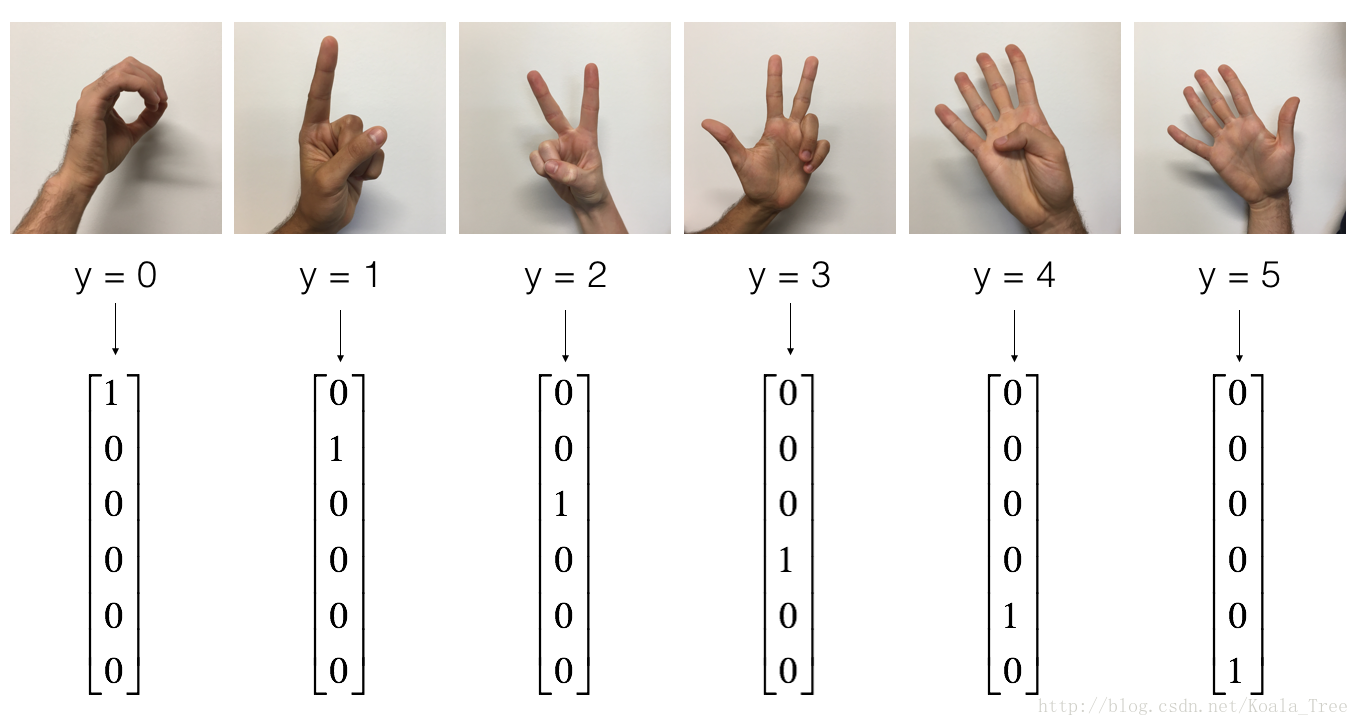
print("y = " + str(np.squeeze(Y_train_orig[:, index])))
# 2-3、将数据归一化,标签one-hot
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print(X_train.shape, Y_train.shape, X_test.shape, Y_test.shape)
# 3、测试模型
train_accuracy, test_accuracy, parameters = model(X_train, Y_train, X_test, Y_test)
运行结果:
X = Tensor("Placeholder:0", shape=(?, 64, 64, 3), dtype=float32)
Y = Tensor("Placeholder_1:0", shape=(?, 6), dtype=float32)
W1 = [ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394
-0.06847463 0.05245192]
W2 = [-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058
-0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228
-0.22779644 -0.1601823 -0.16117483 -0.10286498]
Z3 = [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064]
[-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]
cost = 2.91034
(1080, 64, 64, 3) (1080, 6) (120, 64, 64, 3) (120, 6)
cost after epoch 0:1.920053
cost after epoch 10:0.959578
cost after epoch 20:0.673839
cost after epoch 30:0.542799
cost after epoch 40:0.457058
cost after epoch 50:0.400885
cost after epoch 60:0.372362
cost after epoch 70:0.364956
cost after epoch 80:0.287130
cost after epoch 90:0.263035
Tensor("Mean_1:0", shape=(), dtype=float32)
Train Accuracy: 0.85
Test Accuracy: 0.691667














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









