











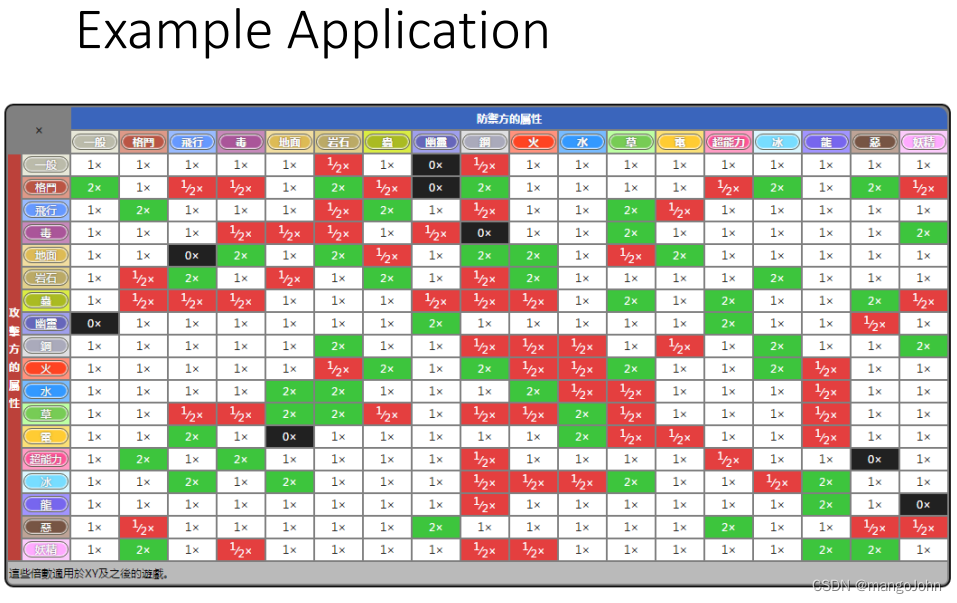
 为分类训练数据
为分类训练数据
把分类问题当作回归问题
以二进制分类为例
class1意味着target为1,class2意味着target为-1
数值接近1为class1,接近-1为class2
 回归模型会惩罚那些太正确的例子,也就是输出值远大于1的点
回归模型会惩罚那些太正确的例子,也就是输出值远大于1的点
●多重class:class1表示target为1;class2表示target是2;class3意味着target是3…..有问题

L(f)表示f在训练数据上得到错误结果的次数。
 与
与 不等则L(f)为1,否则为0
不等则L(f)为1,否则为0

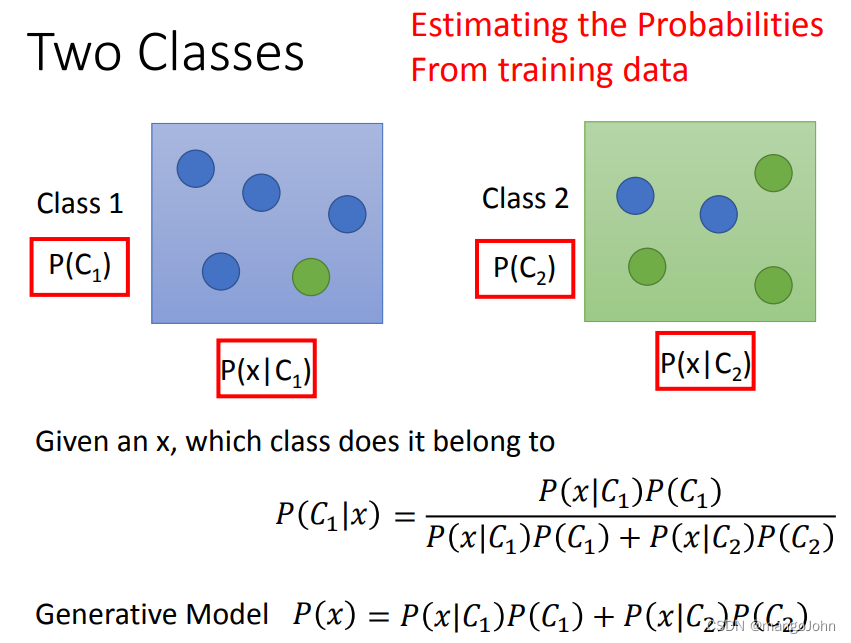

 每个Pokemon用feature描述
每个Pokemon用feature描述
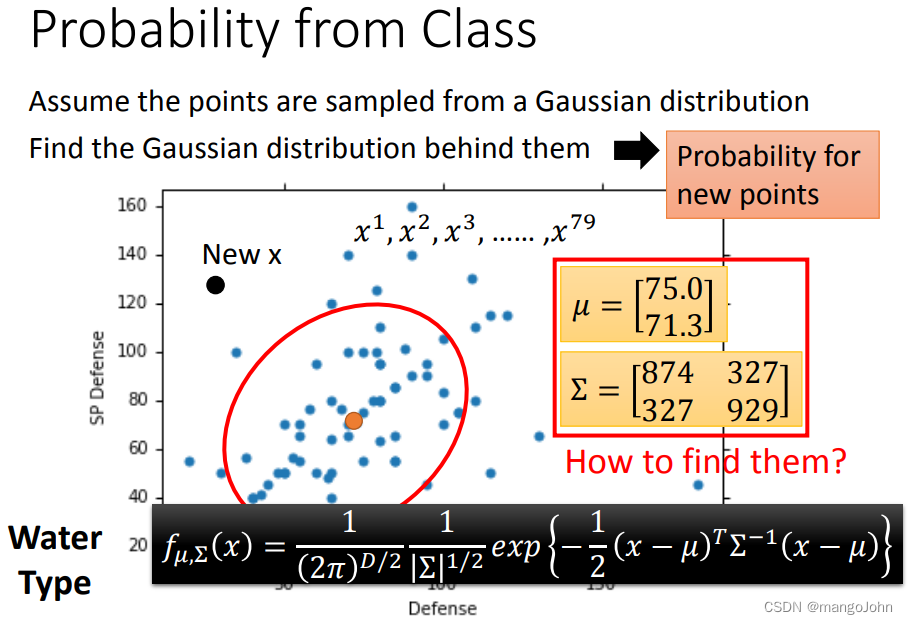
 假设这些点是从高斯分布中采样的。
假设这些点是从高斯分布中采样的。
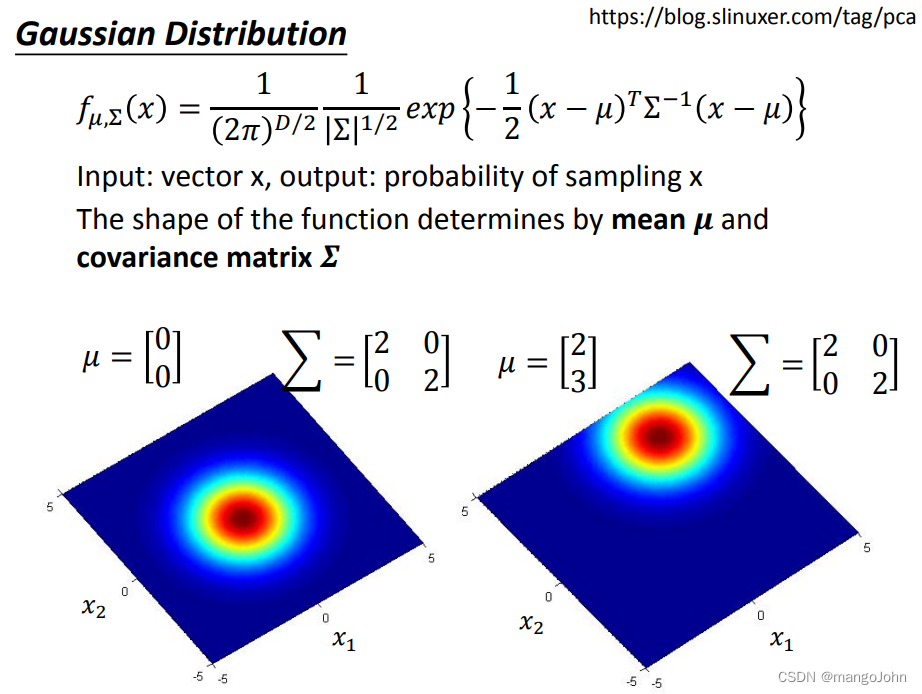
输入:矢量X,输出:采样概率X
函数的形状由平均值μ和协方差矩阵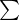 决定
决定
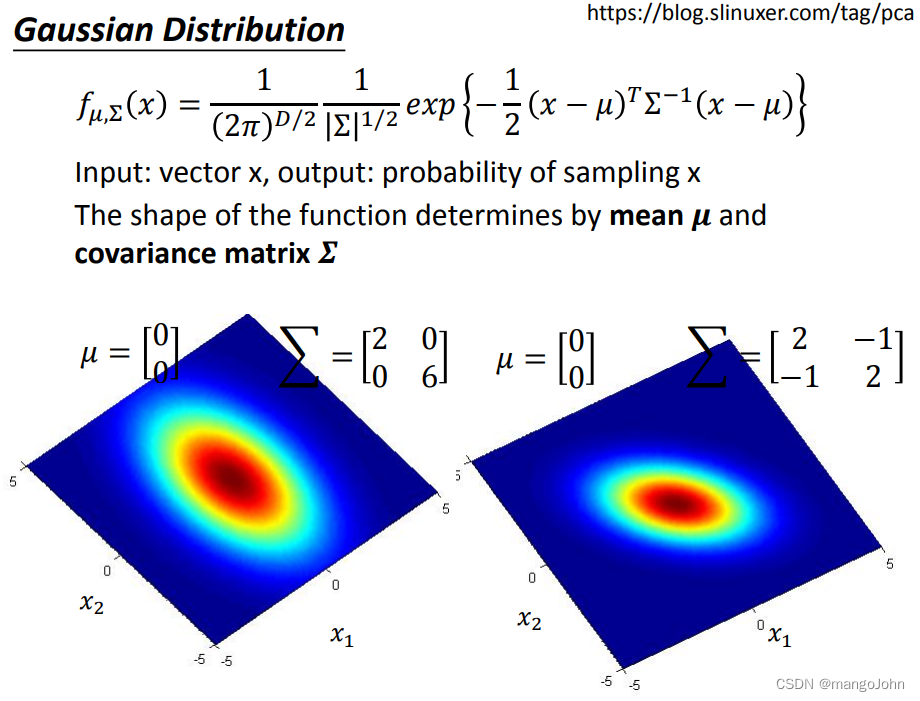
假设这些点是从高斯分布中采样的
找出它们背后的高斯分布,从而找到可能的新点
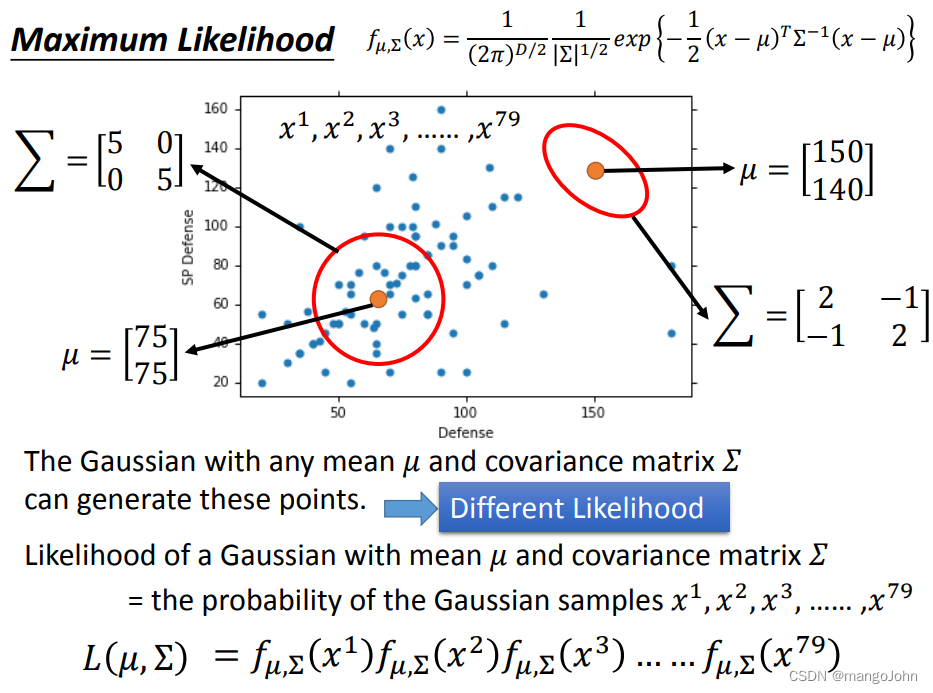 具有任意平均μ和协方差矩阵
具有任意平均μ和协方差矩阵的高斯函数可以生成这些点。这些点有不同的可能性
具有平均μ和协方差矩阵的高斯函数的可能性=高斯样本x1,x2,x3...x79的概率
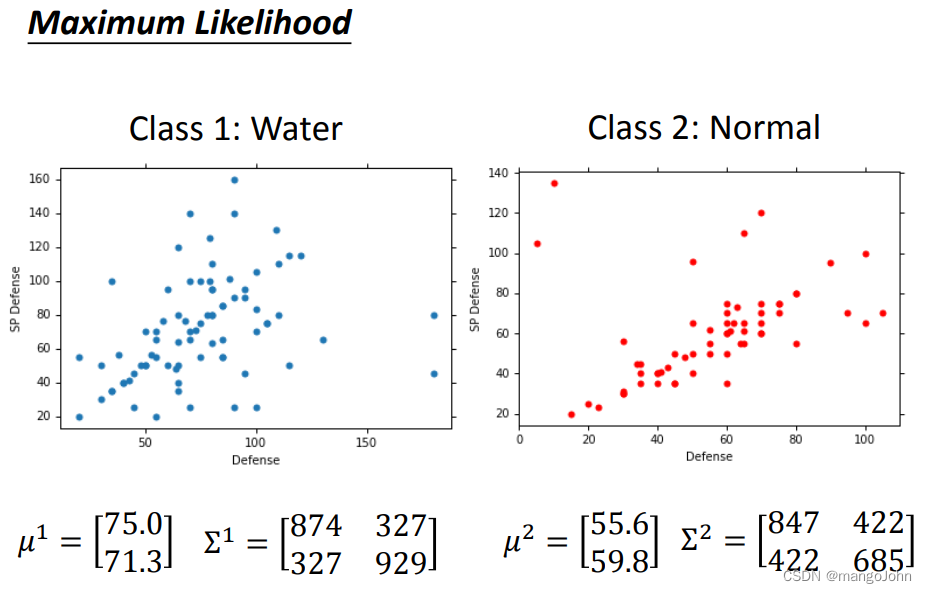
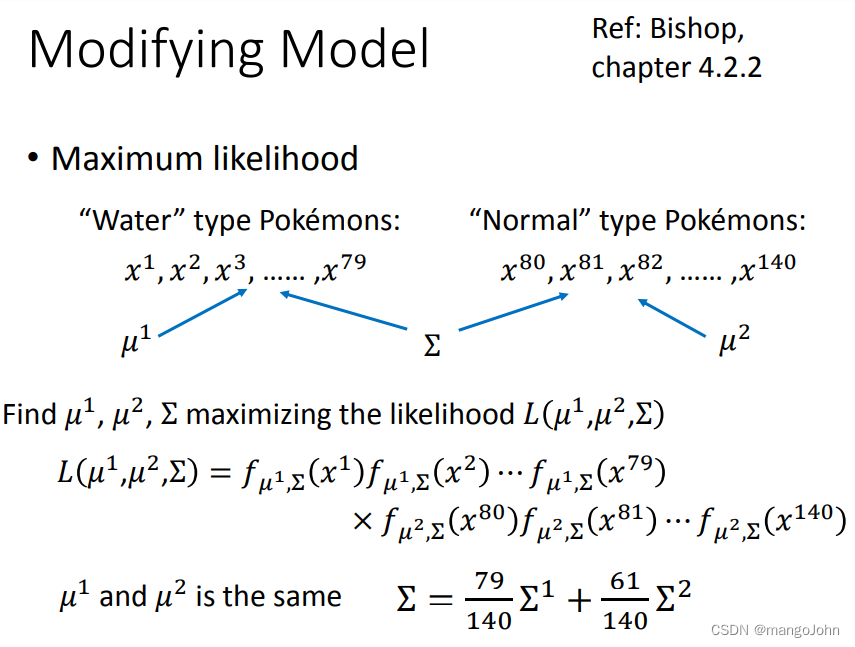
 我们假设x1,x2,x3,…,x79是由高斯函数(μ*,
我们假设x1,x2,x3,…,x79是由高斯函数(μ*,*)产生的,具有最大可能性
故79个点从 (μ*,*)中取值

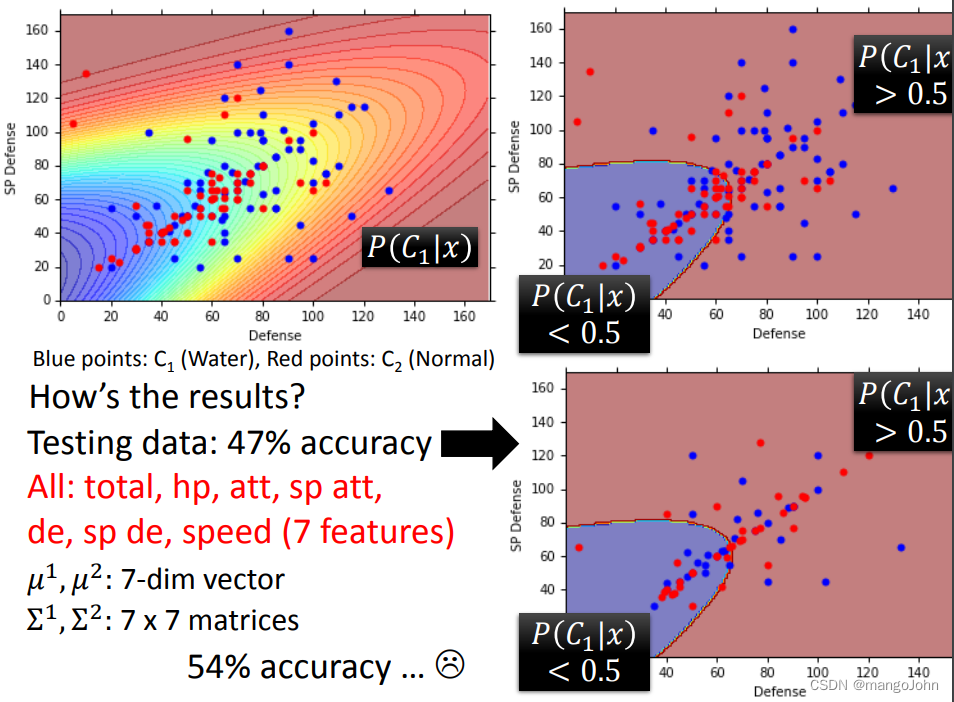
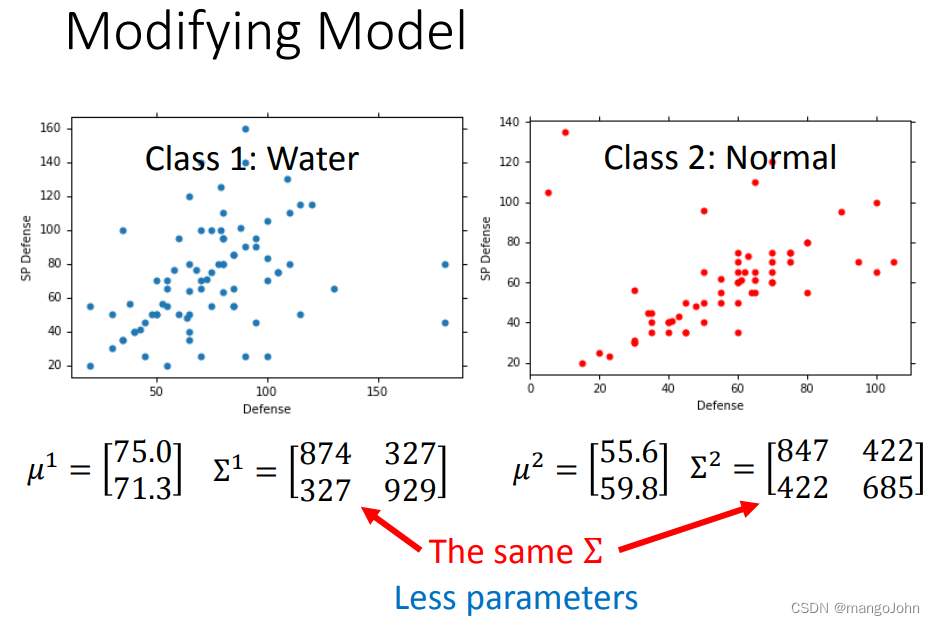
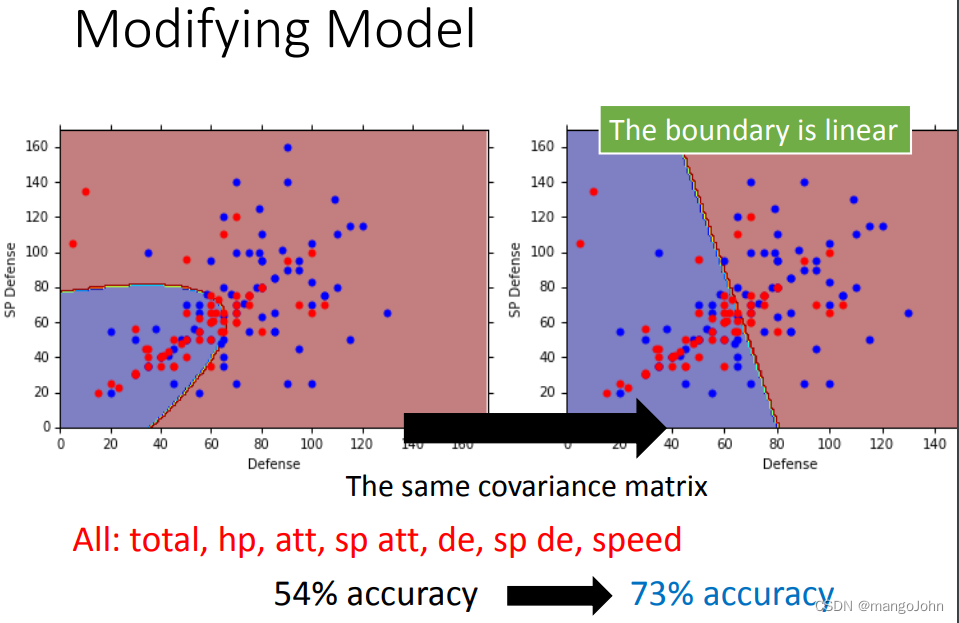 用相同的协方差矩阵让边界变为直线,且正确率增加
用相同的协方差矩阵让边界变为直线,且正确率增加
一、建立函数集模型
二、函数的好处:能获得使概率最大化的平均值μ和协方差矩阵(概率是生成数据的概率)
三、很容易找到最好的函数
 对于二进制特性,你可以假设它们来自伯努利分布。
对于二进制特性,你可以假设它们来自伯努利分布。
如果假设所有维度都是独立的,那么你使用的是Naive Bayes分类器






 如何直接找出w和b,就要关系到逻辑回归的知识
如何直接找出w和b,就要关系到逻辑回归的知识















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









