







https://www.kaggle.com/c/titanic
特征工程
鉴于自己后来的模型融合的尝试,发现特征工程还是最最有效的手段,这里主要是用到离散化的处理。
- Name特征
提取出Mr,Miss等称呼特征,直接离散化。虽然还可以根据它的条件概率或其他一些文化特征再进行归类,但是当时没有进行后续处理,只是简单的提出然后离散。
#处理Name信息
name = df.values[:, 3].astype(str)
for i in range(len(name)) :
temp = name[i].split(",")[1]
name[i] = temp.split(".")[0]
a_set = []
for i in range(len(name)):
if name[i] in a_set: pass
else:
a_set.append(name[i])
refer = {}
for i in range(len(a_set)):
refer[a_set[i]] = i
for i in range(len(name)):
name[i] = int(refer[name[i]])
name = name.astype(int)- Pclass特征
这个特征没有缺失值,而且比较简单直白,数据之间有大小关系,没什么要处理的
#处理Pclass属性,[1, 2, 3]
pclass = df.values[:, 2].astype(int)- Sex特征
也是直接离散处理
#处理Sex属性,[0 : male, 1 : female]
refer = {'male':0, 'female':1}
sex = df.values[:, 4]
for i in range(891) :
sex[i] = refer[sex[i]]- Age特征
先可视化,这样比较直白
可视化的代码如下:
#联合散点图
def col_scatter(survived, p1, p2, s1, s2) :
scatter1_x = []
scatter1_y = []
scatter0_x = []
scatter0_y = []
for i in range(891) :
if survived[i] == 0 :
scatter0_x.append(p1[i])
scatter0_y.append(p2[i])
else :
scatter1_x.append(p1[i])
scatter1_y.append(p2[i])
plt.scatter(scatter0_x, scatter0_y, marker='+', color='r')
plt.scatter(scatter1_x, scatter1_y, marker='+', color='c')
plt.xlabel(s1)
plt.ylabel(s2)
plt.show()结果图:
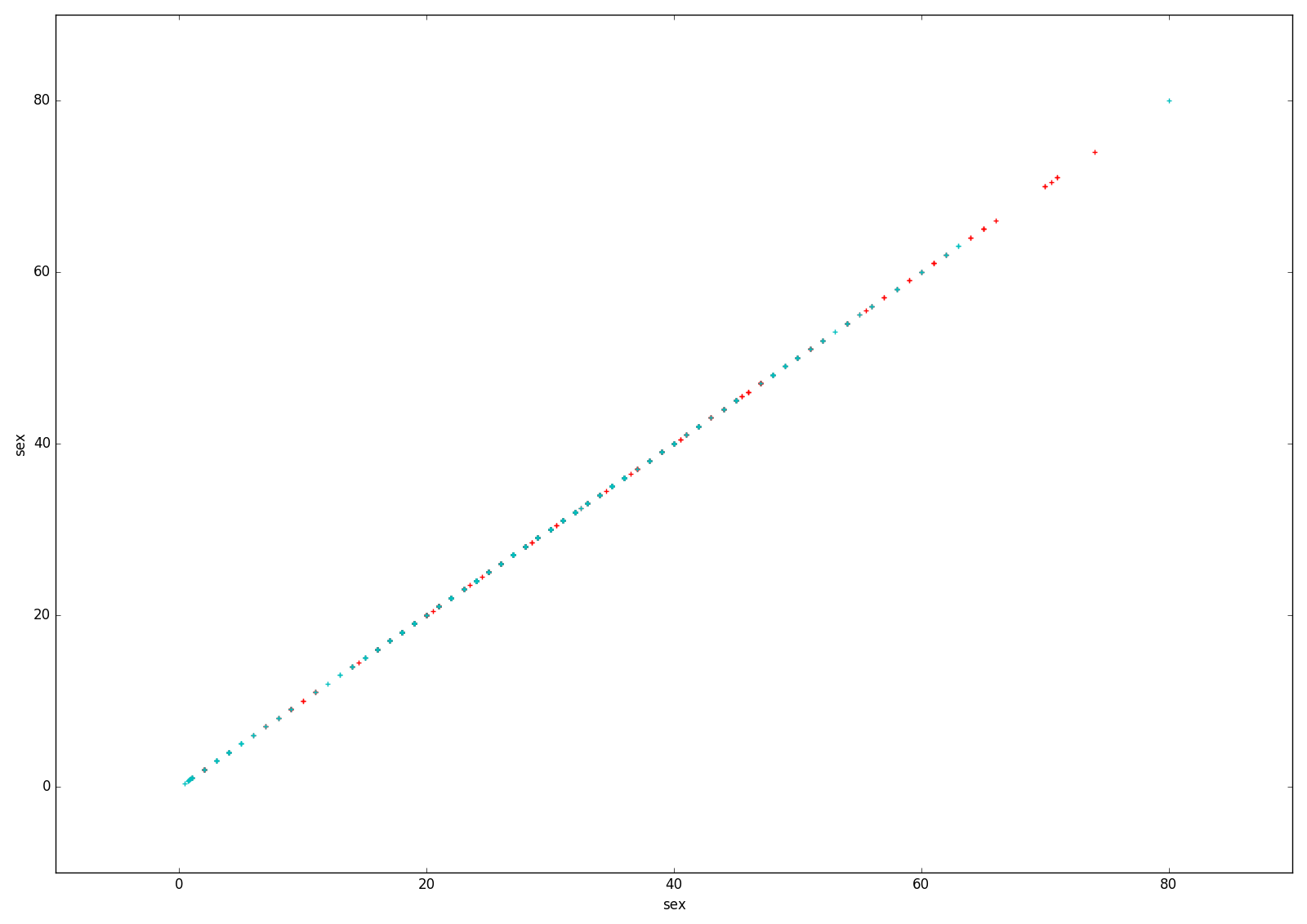
可见大概15,65是个分界点
处理代码:
#处理age信息
age = pd.DataFrame(df.values[:, 5])
age = age.fillna(age.mean()).astype(int)
for i in range(len(age)):
if age[0][i] < 15:
age[0][i] = 0
elif age[0][i] > 65 :
age[0][i] = 2
else :
age[0][i] = 1- Slibsp特征
先查看对应特征的条件概率,即对应特征属性的存活率
# slibsp各属性的条件概率
# 0: 0.3453
# 1: 0.5358
# 2: 0.4642
# 3: 0.25
# 4: 0.1666
# 5: 0.0
# 8: 0.0
def show_sibsp(df) :
content = [0, 1, 2, 3, 4, 5, 8]
for i in range(len(content)) :
print(df.SibSp[(df.SibSp==content[i])&(df.Survived==1)].size / df.SibSp[df.SibSp==content[i]].size)因为比较小白,所以根据存活率手动归类
#处理SibSp信息
#message.show_slibsp(df)
refer = {
'0': 1,
'1': 2,
'2': 2,
'3': 1,
'4': 1,
'5': 0,
'8': 0,
}
sibsp = df.values[:, 6]
for i in range(891) :
sibsp[i] = refer[str(sibsp[i])]后面预测的时候会出现一些在训练集不会出现的属性,但根据规律可以把它归在最小的一类
- Parch特征
处理方法类似sibsp
# parch各属性的条件概率
# 0: 0.3436
# 1: 0.5508
# 2: 0.5
# 3: 0.6
# 4: 0.0
# 5: 0.2
# 6: 0.0
def show_parch(df) :
content = [0, 1, 2, 3, 4, 5, 6]
for i in range(len(content)) :
print(df.Parch[(df.Parch==content[i])&(df.Survived==1)].size / df.Parch[df.Parch==content[i]].size) #处理Parch信息
#message.show_parch(df)
refer = {
'0': 1,
'1': 2,
'2': 2,
'3': 2,
'4': 0,
'5': 1,
'6': 0,
}
parch = df.values[:, 7]
for i in range(891) :
parch[i] = refer[str(parch[i])]Fare特征
跟Age处理方法类似,这里不累述
能得到一个大概6和80的分界Embarked特征
如果是简单的离散化,例如0,1,2的连续特征,但是这些特征之间并没有大小关系,模型可能会学习到他们之间的关系(我猜的)。所以用另外一种方法,叫什么虚拟参数来着,就是离散成(0,0,1),(0,1,0)类似的,这样就不会学到大小的特征Cabin特征
依稀记得这个特征值缺失值比较多,参考别人的想法可能工作人员没有具体的房间,所以用另外的值统一替代。
模型
- 用GBDT,n=100,结果大概是0.78947
- 用PCA加SVM(‘mle’),结果大概是0.80383
总结
1.刚开始以为GBDT是最好的解决方法,但是可能特征处理的时候太离散化了,所以有PCA加svm的效果竟然比GBDT跟好。
2.后续的进步方法:处理ticket中的隐藏信息,可能一些数字的排列方法或者字母会隐含一些其它的有用信息。
3.后续的进步方法:还有就是做特征派生,就是特征之间的组合或相乘等运算,这个还没学到。
补充代码:(因为前后用了两个模型,可能代码有点没有完全注释掉,不过应该可以看出来。还有就是message是另外用来处理训练集和测试集的函数,是上面代码片段的组合吧)
import pandas as pd
import numpy as np
import math
import message
import re
from sklearn.cross_validation import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.decomposition import PCA
from sklearn import svm
df1 = pd.read_csv('train.csv', header=0)
df2 = pd.read_csv('test.csv')
survived = df1.values[:, 1].astype(int)
train = message.normal_train(df1)
test = message.normal_test(df2)
testId = df2.values[:, 0].astype(int)
clf = GradientBoostingClassifier(n_estimators=100)
pca = PCA('mle')
newtrain = pca.fit_transform(train, survived)
clf = svm.SVC().fit(newtrain, survived)
score = cross_val_score(clf, newtrain, survived)
print(score)
# clf.fit(train, survived)
newtest = pca.transform(test)
result = clf.predict(newtest)
np.savetxt('submission_pca_gbdt.csv', np.c_[testId, result],
delimiter=',', header='PassengerId,Survived', comments='', fmt='%d')














 6497
6497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









