



本地基于知识库的大模型的使用教程
启动
双击 大模型启动.bat文件,内容如下:
cmd /k "cd /d G:\Anaconda3\Scripts && activate.bat && cd /d D:\docdb_llm && conda activate python3.11 && python startup.py --all-webui --model-name Qwen-1_8B-Chat
参数解读
- –model-name:可以选择选择不同的模型,目前支持
- –all-webui:启动webui界面。不需要修改
知识库管理
-
选择对应的知识库
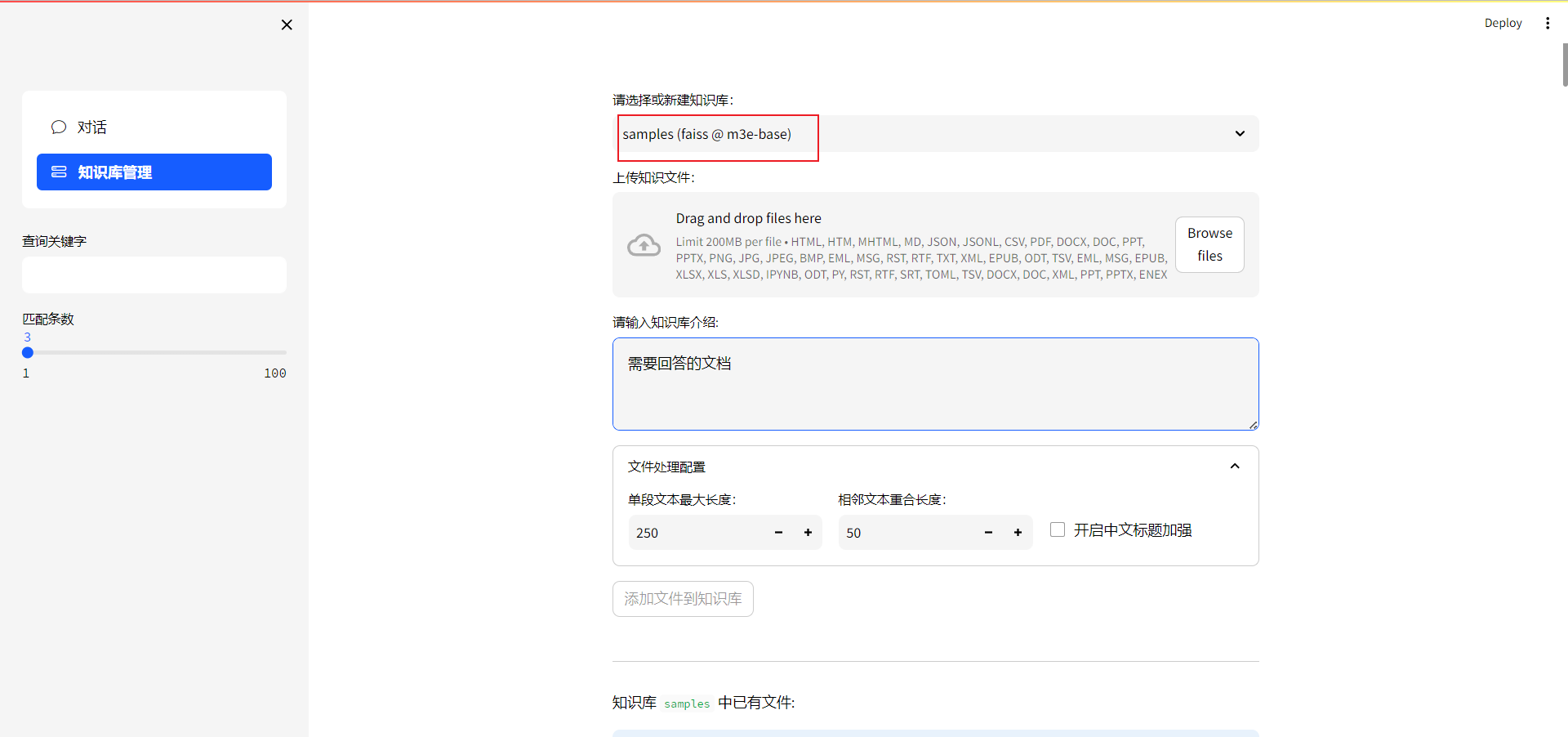
-
上传文件,大小最好不要超过20mb,否则显存不够。pdf最好是纯文本形式
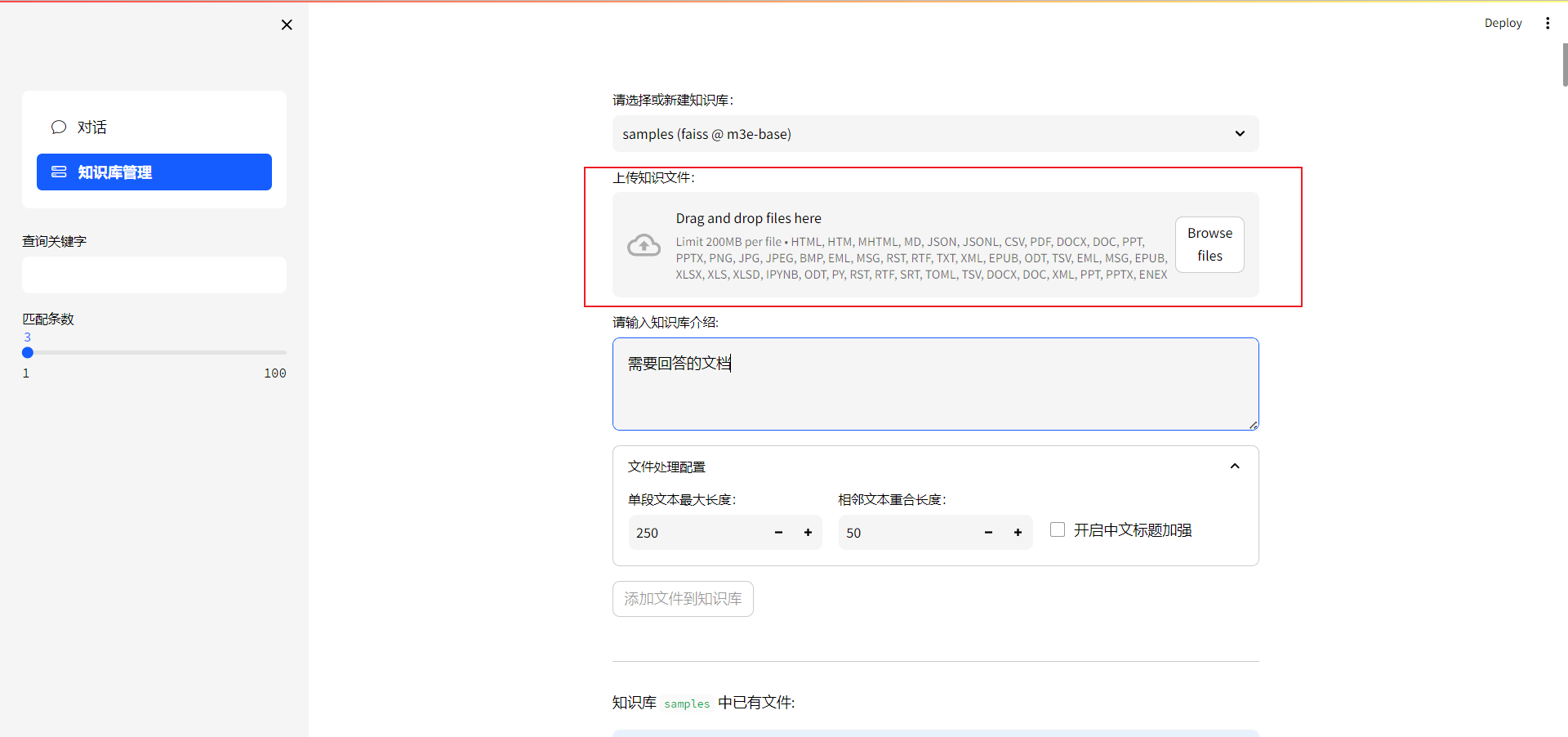
-
输入知识库的介绍

-
单段文本最大长度:大模型每批次嵌入的文本大小,数值越大,消耗的显存越多。相邻文本重合长度:每相邻的两个文本段之间重合的部分,数值越大,两文本段语义关联程度越高。
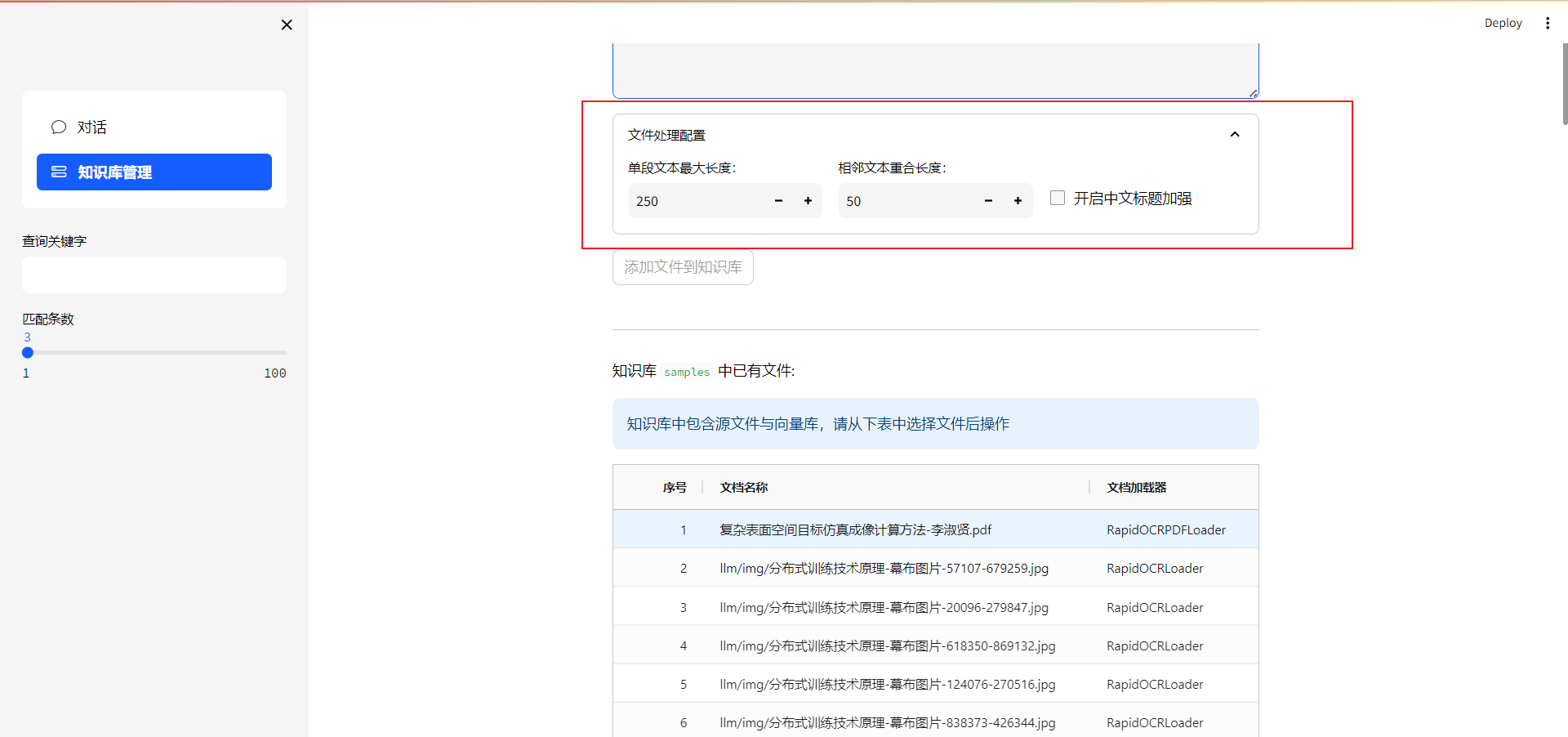
-
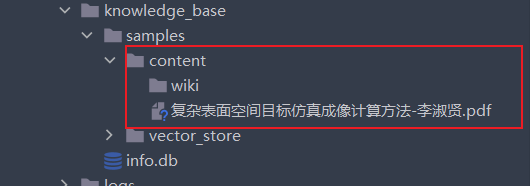
点击添加到知识库,文件添加到源码的knowledge_base/samples/content 文件夹下面。samples:对应的知识库名字。
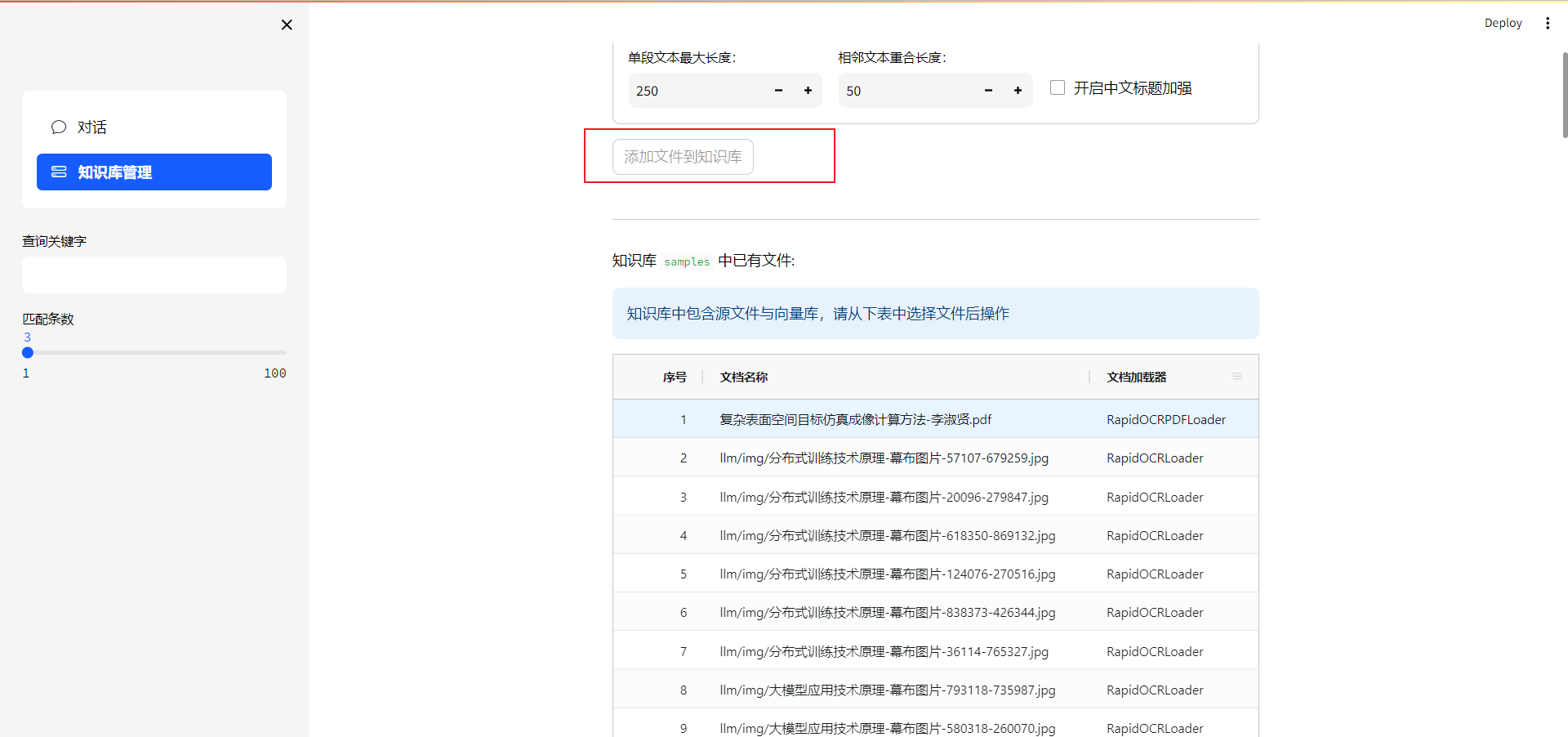
-
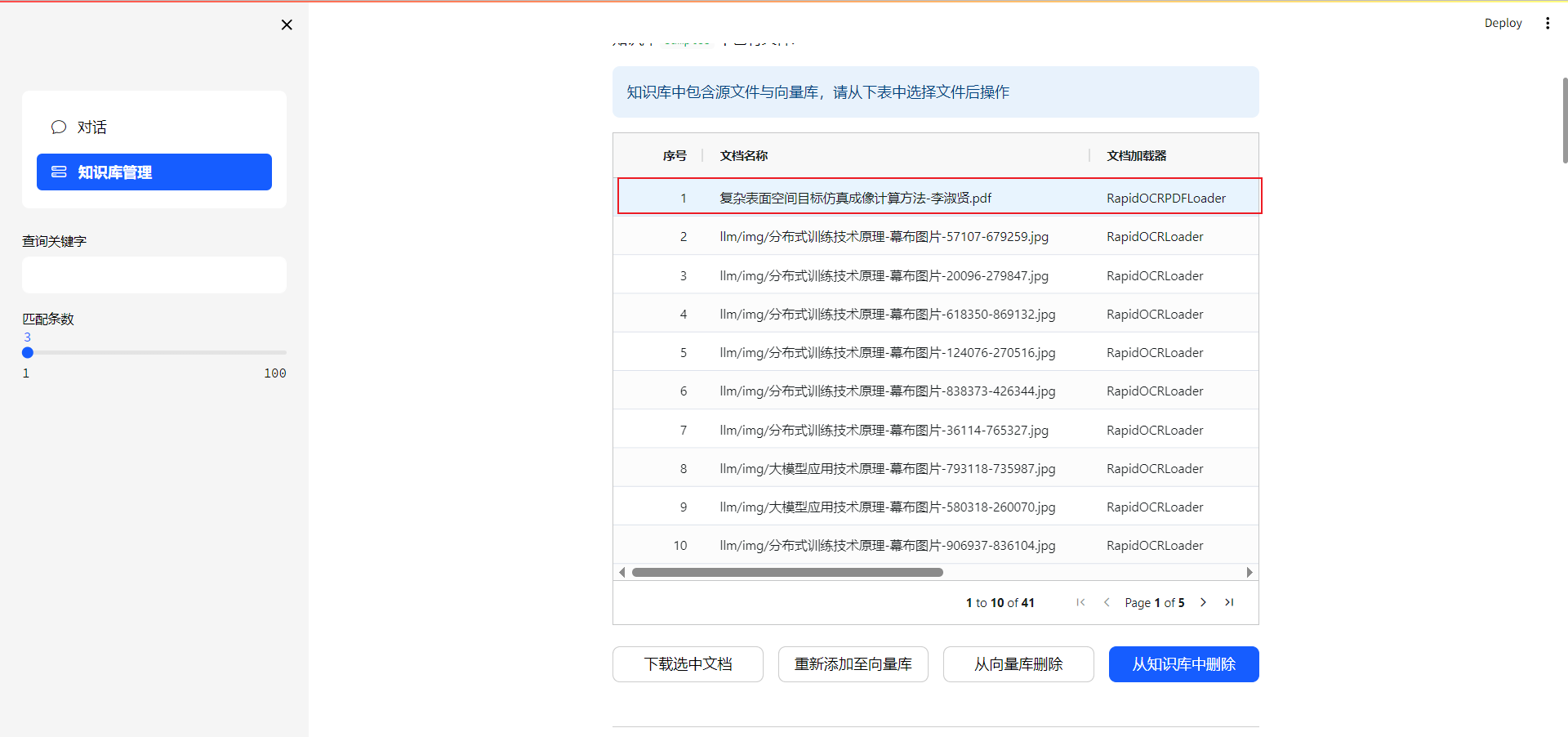
选择一条文件,显示文档加载器列为空白,说明文档没有嵌入到向量数据库的,需要点击重新添加至向量数据库。从向量数据库删除:文件数据从量数据库中删除,但知识库的content目录下还有源文件。从知识库中删除:删除content下的源文件。
-
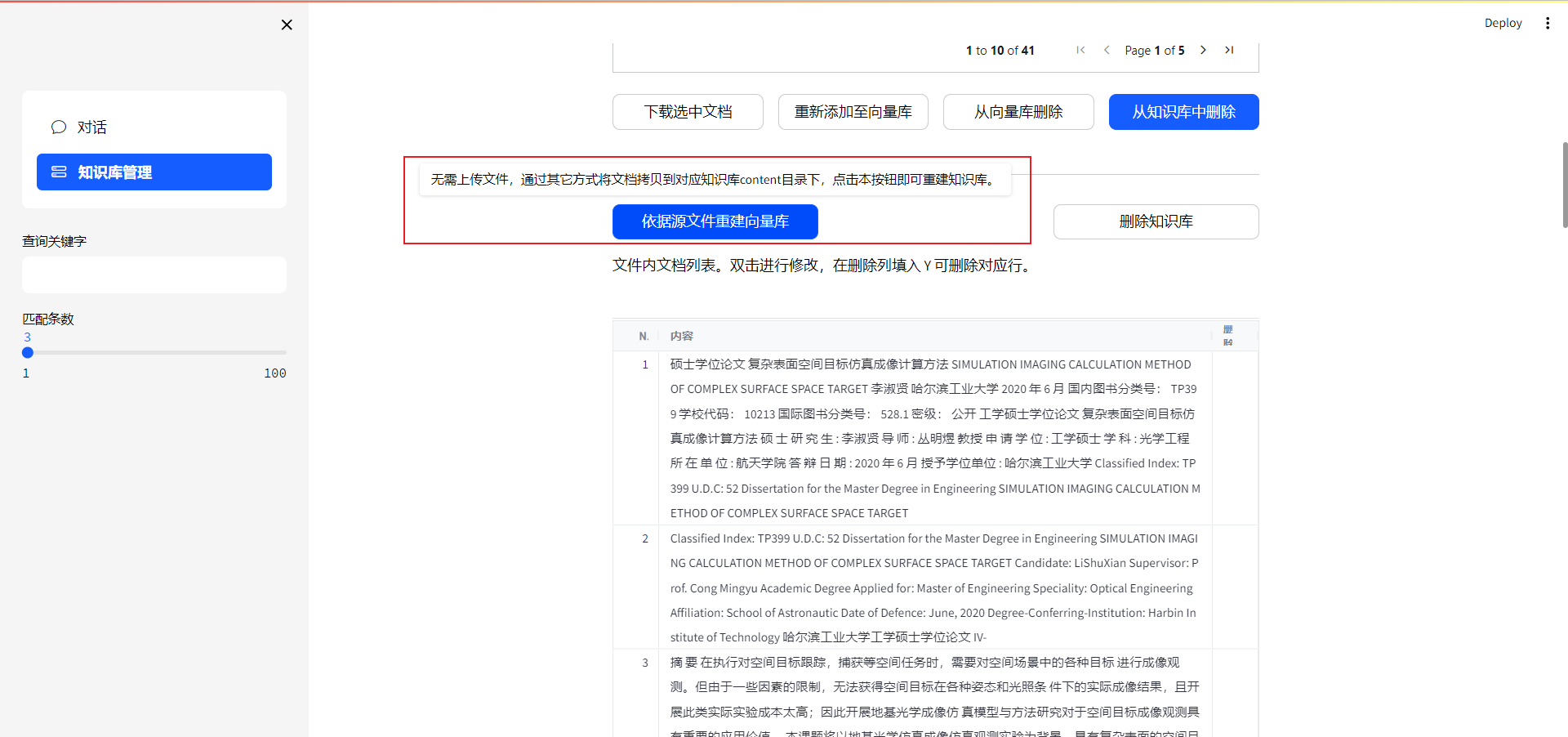
如果第一次启动项目,之前没有知识库,推荐使用将需要上传的文件放入 知识库名称/content/ 下,点击从源文件重建数据库,即可将所有文件嵌入到向量数据库,文件多的化,运行时间会比较久(跟文件的质量也有关系,如果很多图片pdf需要orc,也会很占时间和显存)。以后每次添加新文件可以使用步骤6的方法。如果已有知识库,点击此按钮会将之前的所有文件重新向量化,比较耗时间。建议少量的添加文件使用步骤6。
-
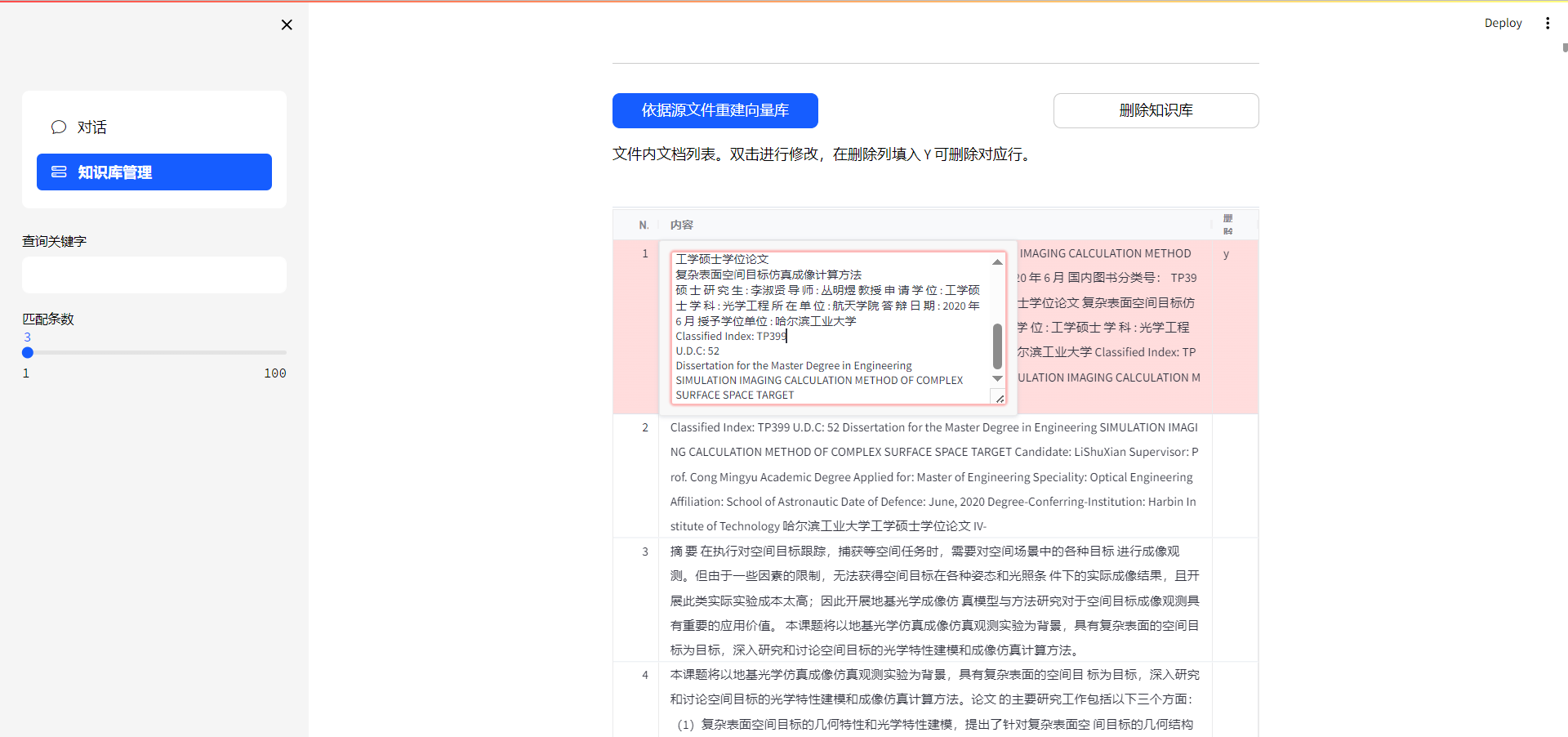
可视化修改知识库里的文件内容(如果orc识别的文件,可能会出现需要错误的问题,所以高质量的文档很重要)
大模型对话
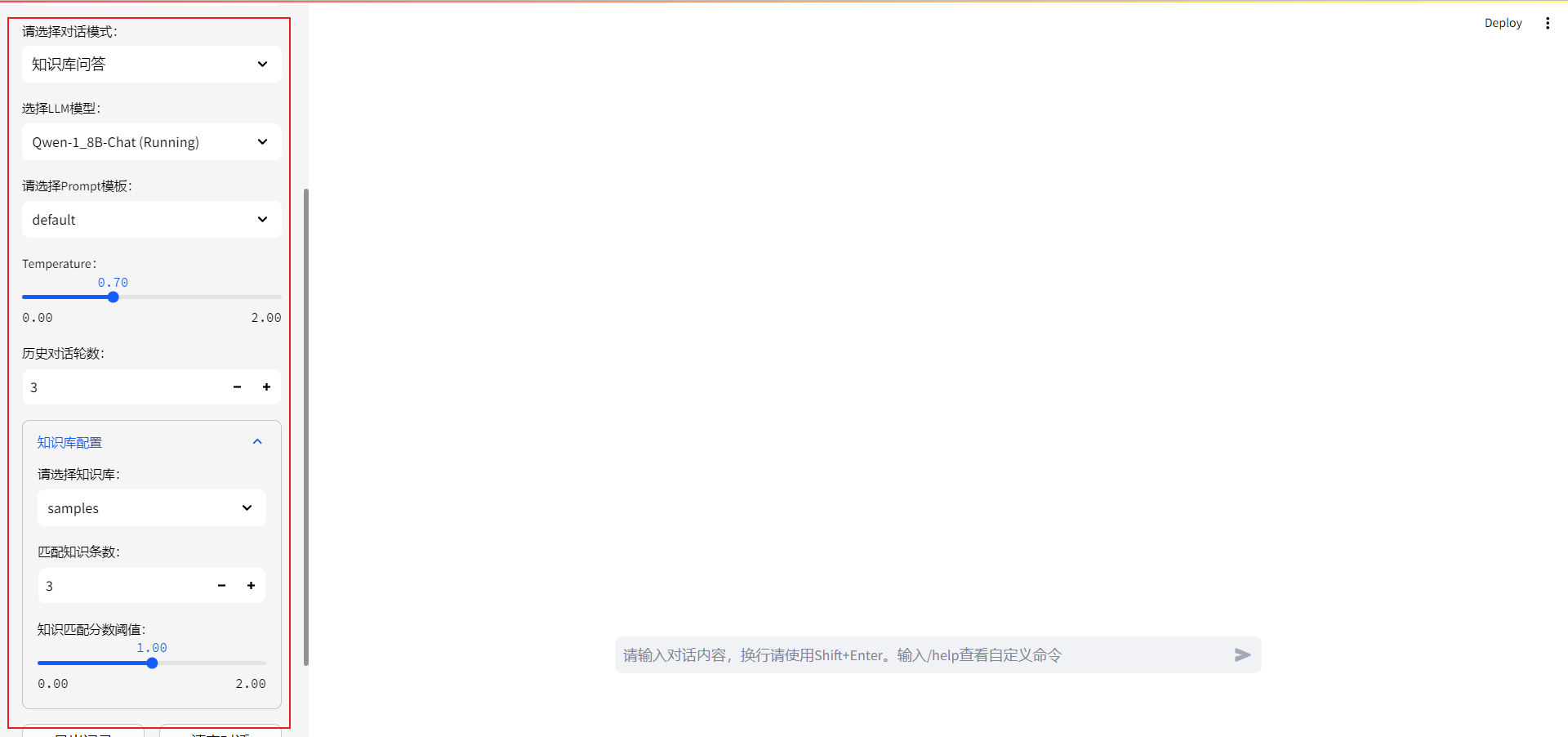
参数解释:
- 选择模型:可以切换模型
- 选择prompt模板,可以修改大模型指令。默认即可。
- temperature:大模型回答的随机性,数值越大,回答的创造性(随机性)越高
- 历史对话轮数:数值越大,上下文关联的历史对话轮数越高,消耗的显存也高。
- =择知识库:选择要问答的知识库
- 匹配知识条数:匹配的知识库内容个数,大模型将结合匹配的内容回答问题。数据越高,消耗的显存也高。
- 知识匹配分数阈值:用于确定两个知识实体是否匹配。默认1即可。
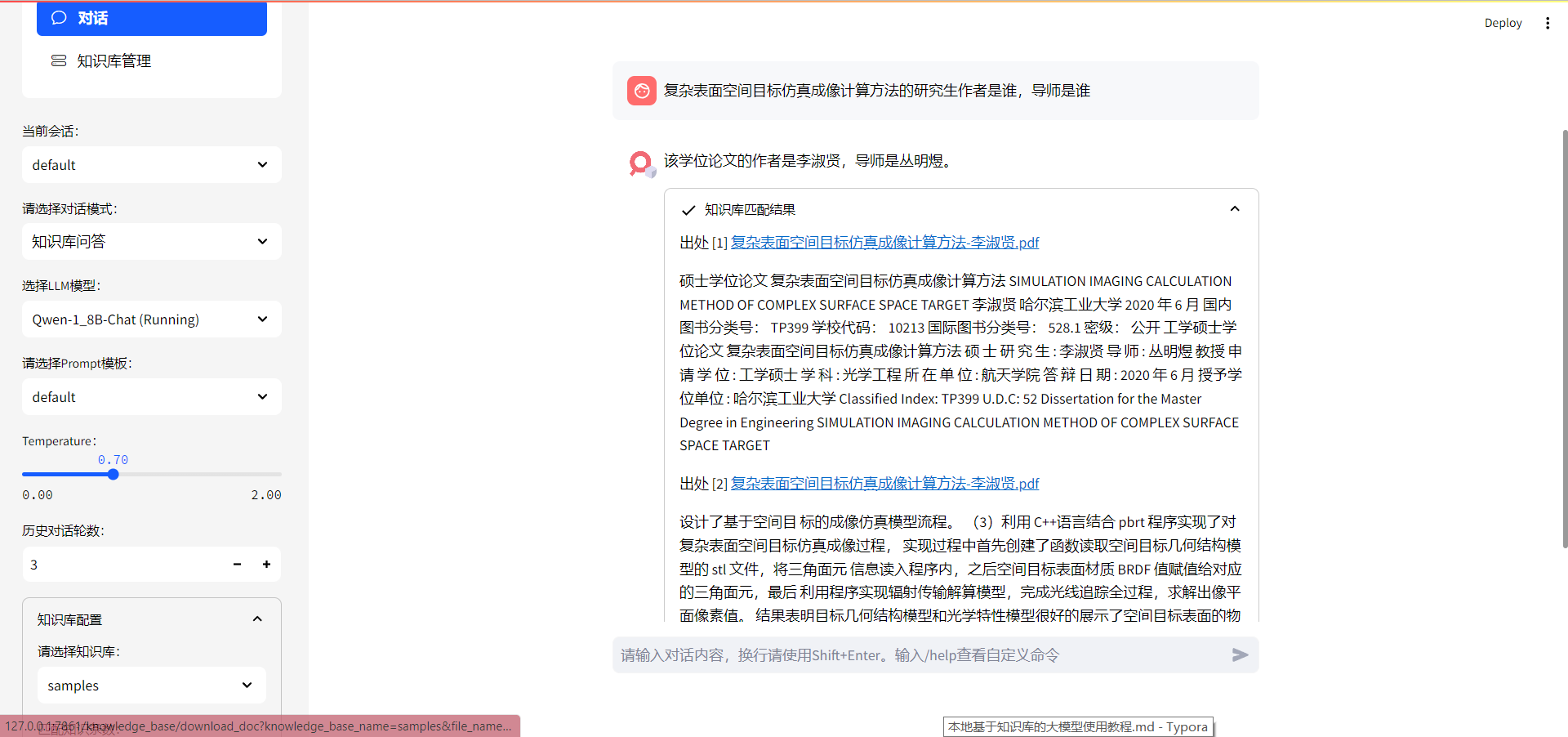
对话内容
上面是对问题的回答,下面知识库匹配的结果是匹配到的知识库内容


















 8529
8529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











