







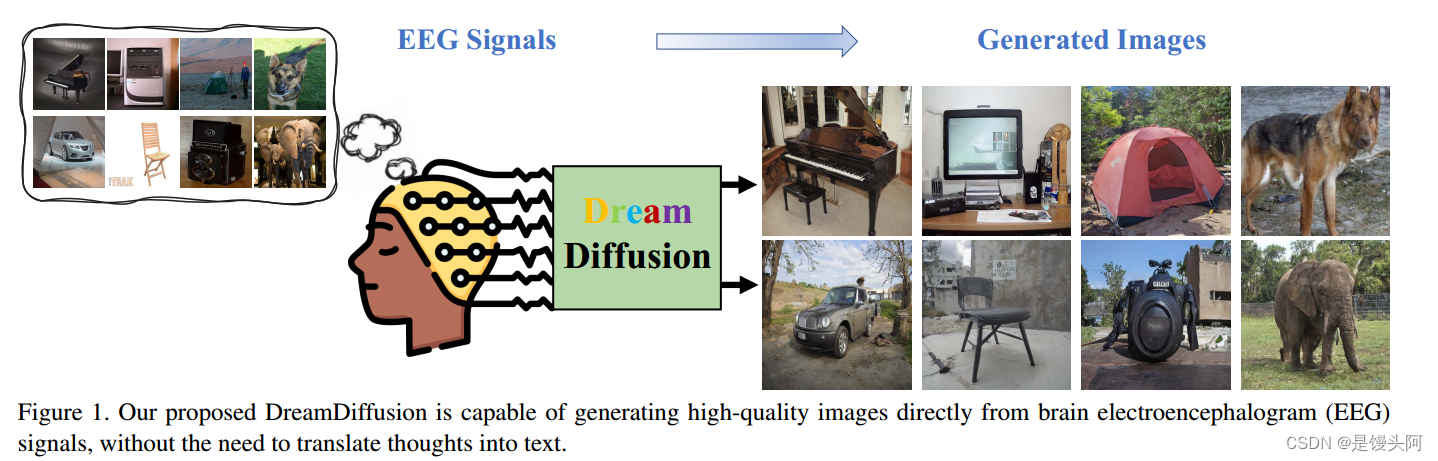
 本文介绍了一种新方法DreamDiffusion,能直接从脑电图信号生成图像,无需文字转译。通过预训练和CLIP辅助,克服了EEG信号的噪声和个体差异,提升了图像质量和潜在应用。
本文介绍了一种新方法DreamDiffusion,能直接从脑电图信号生成图像,无需文字转译。通过预训练和CLIP辅助,克服了EEG信号的噪声和个体差异,提升了图像质量和潜在应用。
本篇文章由深圳清华、腾讯AI Lab、程鹏实验室于2023年6月30日共同发表于<Computer Science >,文章提出的DreamDiffusion能够直接从脑电图(EEG)信号中生成高质量的图像,而无需将思想转换为文本,在与基线模型对比中图像完整性、可读性均最佳。该模型和研究方向有助于人类转瞬即逝的奇思妙想具象化,有助于艺术的发展,并对于儿童的孤独症、语言障碍等疾病具有心理辅助治疗的前景。
文章地址:[2306.16934] DreamDiffusion: Generating High-Quality Images from Brain EEG Signals (arxiv.org)
前言:
This paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate thoughts into text. DreamDiffusion leverages pretrained text-to-image models and employs temporal masked signal modeling to pre-train the EEG encoder for effective and robust EEG representations. Additionally, the method further leverages the CLIP image encoder to provide extra supervision to better align EEG, text, and image embeddings with limited EEG-image pairs. Overall, the proposed method overcomes the challenges of using EEG signals for image generation, such as noise, limited information, and individual differences, and achieves promising results. Quantitative and qualitative results demonstrate the effectiveness of the proposed method as a significant step towards portable and low-cost “thoughts-to-image”, with potential applications in neuroscience and computer vision.
本文介绍了DreamDiffusion,这是一种直接从脑电信号中生成高质量图像的新方法,无需将思想转化为文本。DreamDiffusion利用预训练的文本到图像模型,并采用时间掩蔽信号建模来预训练EEG编码器,以获得有效和稳健的EEG表示。此外,该方法还利用CLIP图像编码器提供额外的监督,以更好地将EEG、文本和图像嵌入与有限的EEG图像对对准。总体而言,所提出的方法克服了使用脑电信号进行图像生成的挑战,如噪声、有限信息和个体差异,并取得了有希望的结果。定量和定性结果表明,所提出的方法是朝着可移植和低成本的“思维到图像”迈出的重要一步,在神经科学和计算机视觉中具有潜在应用。
Introduction
Image generation [16, 22, 4] has made great strides inrecent years, especially after breakthroughs in text-to-image generation [31, 12, 30, 34, 1]. The recent text-to-image generation not only dramatically improves the quality of generated images, but also enables the creation of people’s ideas into exquisite paintings and artworks controlled by text. We are very curious whether we could control image creation directly from brain activities (such as electroencephalogram (EEG) recordings), without translating our thoughts into text before creation. This kind of “thoughts-to-images” has broad prospects and could broaden people’s imagination. For example, it can greatly improve the efficiency of artistic creation and help capture those fleeting inspirations. It also has the potential to help us visualize our dreams at night, (which inspires the name DreamDiffusion). Moreover, it may even aid in psychotherapy, having the potential to help children with autism and those with language disabilities.
近年来,图像生成[16,22,4]取得了长足的进步,尤其是在文本到图像生成[31,12,30,34,1]取得突破之后。最近的文本到图像生成不仅极大地提高了生成图像的质量,而且使人们的想法能够被创作成受文本控制的精美绘画和艺术品。我们非常好奇,我们是否可以直接从大脑活动(如脑电图(EEG)记录)控制图像的创建,而无需在创建前将我们的想法转化为文本。这种“物象思维”具有广阔的前景,可以拓宽人们的想象空间。例如,它可以大大提高艺术创作的效率,并帮助捕捉那些转瞬即逝的灵感。它也有可能帮助我们在晚上想象我们的梦(这激发了DreamDiffusion的名字)。此外,它甚至可能有助于心理治疗,有可能帮助自闭症儿童和语言障碍儿童。
目标:
our goal of using brain signals to create conveniently and efficiently.
1) Since fMRI equipment is not portable and needs to be operated by professionals, it is difficult to capture fMRI signals.
2) The cost of fMRI acquisition is high. They greatly hinder the widespread use of this method in the practical artistic generation. In contrast, EEG (electroencephalogram) is a non-invasive and low-cost method of recording electrical activity in the brain. Portable commercial products are now available for the convenient acquisition of EEG signals, showing great potential for future
art generation.
此技术面临的挑战:
In this work, we aim to leverage the powerful generative capabilities of pre-trained text-to-image models (i.e., Stable Diffusion [32]) to generate high-quality images directly from brain EEG signals. However, this is non-trivial and has two challenges.
1) EEG signals are captured non-invasively and thus are inherently noisy. In addition, EEG data are limited and individual differences cannot be ignored. How to obtain effective and robust semantic representations from EEG signals with so many constraints?
2) Thanks to the use of CLIP [28] and the training on a large number of textimage pairs, the text and image spaces in Stable Diffusion are well aligned. However, the EEG signal has its own characteristics, and its space is quite different from that of text and image. How to align EEG, text and image spaces with limited and noisy EEG-image pairs?
总结:这两个挑战也就是EEG信号固有的问题:噪声信号明显、个体差异性大
对第一个挑战采取的方法:
To address the first challenge, we propose to train EEG representations using large amounts of EEG data instead of only rare EEG-image pairs. Specifically, we adopt masked signal modeling to predict the missing tokens based on contextual cues. Different from MAE [18] and MinD-Vis [7], which treat inputs as two-dimensional images and mask the spatial information, we consider the temporal characteristics of EEG signals, and dig deep into the semantics behind temporal changes in people’s brains. We randomly mask a proportion of tokens and then reconstruct those masked ones in the time domain. In this way, the pre-trained encoder learns a deep understanding of EEG data across different people and various brain activities.
为了解决第一个挑战,我们建议使用大量的脑电图数据而不是仅使用罕见的脑电图图像对来训练脑电图表示。具体来说,我们采用掩蔽信号建模来基于上下文线索预测丢失的令牌。与MAE[18]和MinD-Vis[7]将输入视为二维图像并掩盖空间信息不同,我们考虑了EEG信号的时间特征,并深入挖掘了人们大脑时间变化背后的语义。我们随机屏蔽一部分令牌,然后在时域中重建那些被屏蔽的令牌。通过这种方式,经过预训练的编码器可以深入了解不同人群和各种大脑活动的脑电图数据。
对第二个挑战采取的方法:
As for the second challenge, previous methods [40, 7]usually directly fine-tune Stable Diffusion (SD) models using a small number of noisy data pairs. However, it is difficult to learn accurate alignment between brain signals (e.g., EEG and fMRI) and text spaces by end-to-end finetuning SD only using the final image reconstruction loss.We thus propose to employ additional CLIP [28] supervision to assist in the alignment of EEG, text, and image spaces. Specifically, SD itself uses CLIP’s text encoder to generate text embeddings, which are quite different from the masked pre-trained EEG embeddings in the previous stage. We leverage CLIP’s image encoder to extract rich image embeddings that align well with CLIP text embeddings. Those CLIP image embeddings are then used to fur ther optimize EEG embedding representations. Therefore,
the refined EEG feature embeddings can be well aligned with the CLIP image and text embeddings, and are more suitable for SD image generation, which in turn improves the quality of generated images.
至于第二个挑战,以前的方法[40,7]通常使用少量噪声数据对直接微调稳定扩散(SD)模型。然而,通过仅使用最终图像重建损失的端到端微调SD,很难学习大脑信号(例如EEG和fMRI)和文本空间之间的精确对准。因此,我们建议使用额外的CLIP[28]监督来帮助对齐EEG、文本和图像空间。具体来说,SD本身使用CLIP的文本编码器来生成文本嵌入,这与前一阶段的掩蔽预训练EEG嵌入截然不同。我们利用CLIP的图像编码器来提取与CLIP文本嵌入很好对齐的丰富图像嵌入。然后使用这些CLIP图像嵌入来进一步优化EEG嵌入表示。因此精细的EEG特征嵌入可以与CLIP图像和文本嵌入很好地对齐,并且更适合于SD图像生成,这反过来提高了生成图像的质量。
模型贡献:
Our contributions can be summarized as follows.
1) We propose DreamDiffusion, which leverages the powerful pre-trained text-to-image diffusion models to generate realistic images from EEG signals only. It is a further step towards portable
and low-cost “thoughts-to-images”.
2) A temporal masked signal modeling is employed to pre-train EEG encoder for effective and robust EEG representations.
3) We further leverage the CLIP image encoder to provide extra supervision to better align the EEG, text, and image embeddings with limited EEG-image pairs.
4) Quantitative and qualitative results have shown the effectiveness of our DreamDiffusion.
模型预训练:
Pre-training models have become increasingly popular in the field of computer vision, with various self-supervised learning approaches focusing on different pretext tasks [13,
43, 26]. These methods often utilize pretext tasks such as contrastive learning [2, 17], which models image similarity and dissimilarity, or autoencoding [6], which recovers the original data from a masked portion. In particular, masked signal modeling (MSM) has been successful
in learning useful context knowledge for downstream tasks by recovering the original data from a high mask ratio for visual signals [18, 44] and a low mask ratio for natural languages [10, 29]. Another recent approach, CLIP [28], builds a multi-modal embedding space by pre-training on
400 million text-image pairs collected from various sources on the Internet. The learned representations by CLIP are extremely powerful, enabling state-of-the-art zero-shot image
classification on multiple datasets, and providing a method to estimate the semantic similarity between text and images.
预训练模型在计算机视觉领域越来越流行,各种自我监督学习方法专注于不同的借口任务[13,43,26]。这些方法通常利用借口任务,如对比学习[2,17],其对图像相似性和不相似性进行建模,或自动编码[6],其从掩蔽部分恢复原始数据。特别是,掩蔽信号建模(MSM)通过从视觉信号的高掩蔽比[18,44]和自然语言的低掩蔽比[10,29]中恢复原始数据,成功地为下游任务学习了有用的上下文知识。最近的另一种方法,CLIP[28],通过对从互联网上的各种来源收集的4亿对文本图像。CLIP的学习表示非常强大,能够在多个数据集上进行最先进的零镜头图像分类,并提供了一种估计文本和图像之间语义相似性的方法。
Diffusion models:
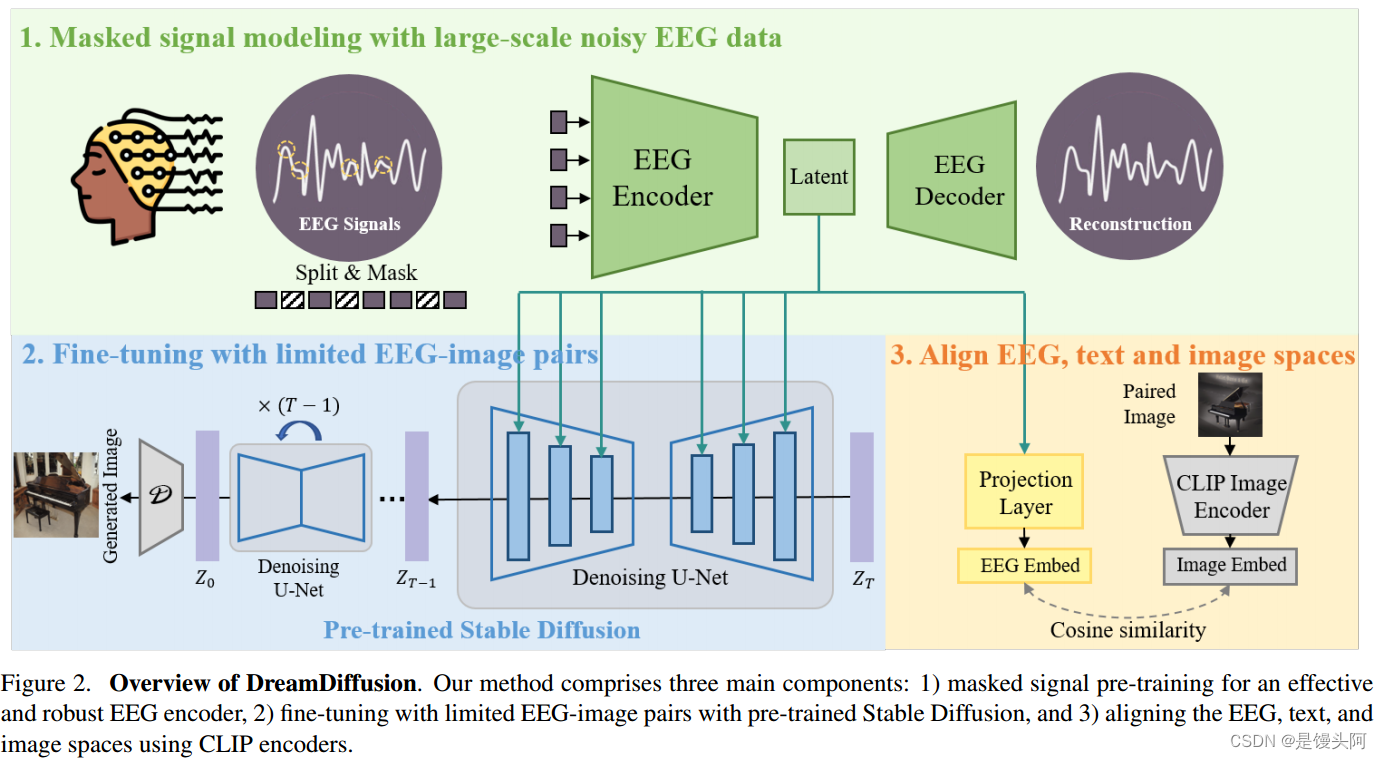
Our method comprises three main components:
1)masked signal pre-training for an effective and robust EEG encoder
2) fine-tuning with limited EEG-image pairs with pre-trained Stable Diffusion
3) aligning the EEG, text, and image spaces using CLIP encoders. Firstly, we leverage masked signal modeling with lots of noisy EEG data to train an EEG encoder to extract contextual knowledge. The resulting EEG encoder is then employed to provide conditional features for Stable Diffusion via the cross-attention mechanism. In order to enhance the compatibility of EEG features with Stable Diffusion, we further align the EEG,text, and image embedding spaces by reducing the distance between EEG embeddings and CLIP image embeddings during fine-tuning. As a result, we can obtain DreamDiffusion, which is capable of generating high-quality images from EEG signals only.
与基线模型对比:

DreamDiffusion模型在生成的图像中质量都是最高的


但模型也有失败的生成例子
对此作者认为:
其中一些类别被映射到具有相似形状的其他类别或颜色。这可能是由于人脑认为形状和颜色是两个重要识别因素。
Conclusion
本文提出了一种新的方法——DreamDiffusion,用于从脑电信号中生成高质量的图像,这是一种无创且易于获取的大脑活动来源。该方法利用从大型脑电图数据集中学习到的知识和图像扩散模型强大的生成能力,解决了基于脑电图的图像生成所面临的挑战。通过预训练和微调方案,利用稳定扩散技术将脑电信号编码为适合图像生成的表示形式。我们的方法代表了大脑活动图像生成领域的重大进步。


















 2817
2817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











