






标准RNN的更新方式:

这里g()是指有界的有界函数例如sigmoid函数,xt是指在t时刻输入的量,给定当前状态ht,输出序列下一个元素的概率分布。
GRU激活,既是先前状态和候选状态的插值。

更新门:

候选状态计算:

重置门:

该模型的三个主要内容:
1.证明RNN可以用于会话推荐
2.针对稀疏序列建模
3.设计适配于该推荐任务的损失函数
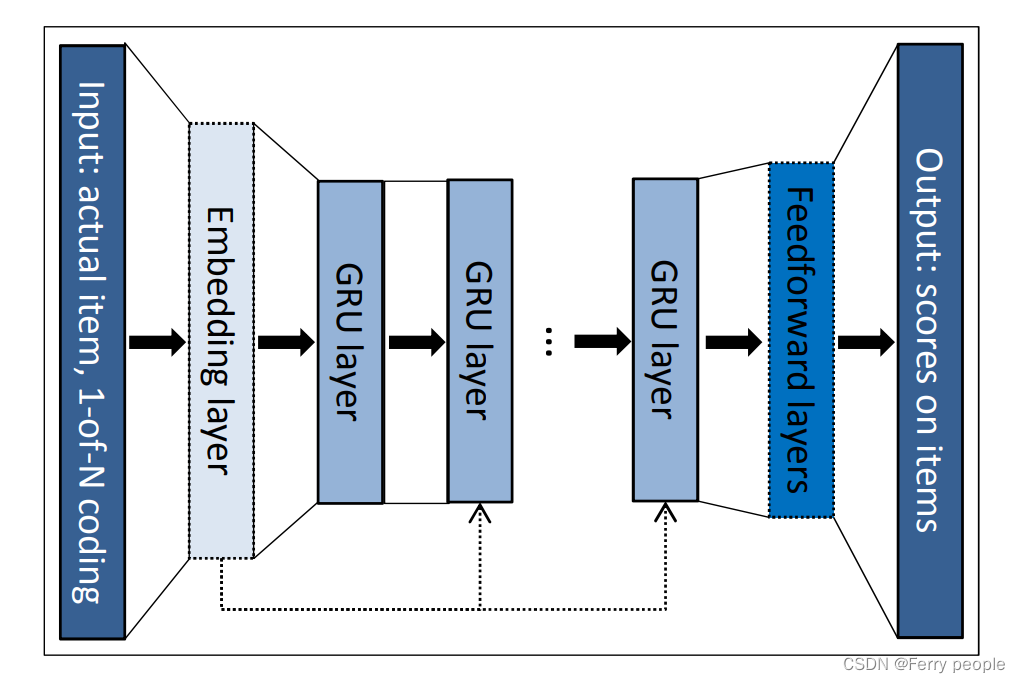
1.推荐模型的初始化输入是用户进入该网站第一个点击的项目;
2.GRU的输入是session当前的输入item(event),输出是下一个item(event);
3.模型输出是item的预测偏好,例如每个item成为session的下一个item的可能性;
4.本文实验证明 weighted one-hot representation 优于embedding layer;weighted的含义是权重值随时序向前递减。
5.本文实验证明将input介入深层GRU有助于提高效果。
6.使用1-of-N encoding,这里假设这个vector的维数就等于世界上所有单词的数目,那么对每一个单词来说,只需要某一维为1,其余都是0即可;但这会导致任意两个vector都是不一样的,你无法建立起同类word之间的联系。这里1-of-N encoding表现较好
图示为网络总结构,这里一次处理事件流中的一个事件。
1.会话并行的小型批处理
该任务不像序列标注任务那样,可以对序列不等长的情况进行序列补长(PADDING),所以本文采取了以下方法:
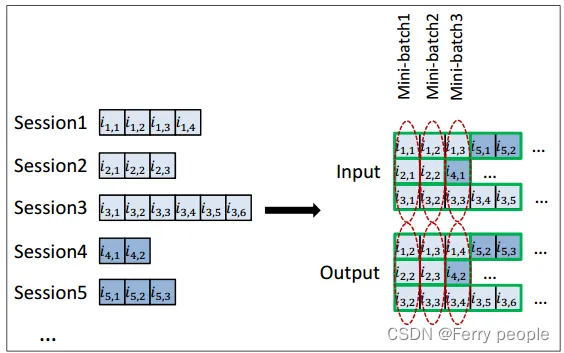
为会话创建一个表单,前x个会话的第一个事件构成第一个小批量的输入(期望输出的是会话的第二个事件),第二小批量由第二个事件组成,依次类推。
当该batch内的session结束时,用batch以外session填补,当然模型的参数要重置。
2.对输出进行采样
由于item数量过大,本文选择对正样本和负样本分别采样计算score及更新weight;并且本文做了一个假设,missing item即dislike,所以本文的负样本为该batch中其他训练数据中的item。
missing item:用户不知道该项目存在,因此没有交互,不喜欢的可能性大。
3.RANKING LOSS
推荐系统的核心是项目的基于相关性的排名。本文使用Pairwise ranking,即比较正样本和负样本的得分或排名,并确保正样本的loss要低于负样本。
本文使用了两种基于Pairwise ranking的loss function:


参考:https://zhuanlan.zhihu.com/p/28776432
















 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









