







【回归算法解析系列】支持向量回归(Support Vector Regression, SVR)
1. 支持向量回归:高维空间的优雅边界
支持向量回归(SVR)是基于支持向量机(SVM)发展而来的回归方法,其核心思想巧妙而独特,是通过构建一个ε-不敏感带(ε-insensitive tube)来捕捉数据的分布趋势。这一方法犹如在数据的海洋中精心勾勒出一条精准的航线,引领着预测的方向。
1.1 独特优势
- 核函数技巧:在实际应用中,许多数据之间的关系并非简单的线性关系,而是复杂的非线性关系。核函数技巧就像是一把神奇的钥匙,能够将低维空间中难以处理的非线性问题,巧妙地映射到高维线性空间。在这个高维空间中,原本复杂的非线性关系变得可以用线性的方式来处理。比如在图像识别领域,图像数据在原始的低维空间中呈现出极其复杂的分布,但通过核函数映射到高维空间后,就能够更容易地找到合适的回归模型,实现对图像特征与目标变量之间关系的准确描述。
- 稀疏解:SVR的另一个显著优势是它能得到稀疏解。在进行预测时,模型仅依赖支持向量进行计算,而支持向量只是数据集中的一小部分样本。这意味着模型在训练和预测过程中,不需要对所有数据进行处理,大大降低了计算开销。这种特性使得SVR在处理大规模数据集时,依然能够保持较高的效率,就像在众多数据中精准地找到了关键的“线索”,避免了不必要的计算负担。
- 鲁棒性:在实际的数据集中,往往会存在一些离群点,这些离群点可能是由于数据采集错误、噪声干扰等原因产生的。SVR对带离群点的数据具有较强的容错能力,通过ε-不敏感带的设计,它可以在一定程度上忽略这些离群点的影响,从而更准确地捕捉数据的真实趋势。例如,在传感器信号拟合中,偶尔出现的异常信号就相当于离群点,SVR能够有效地排除这些异常信号的干扰,准确地拟合出传感器信号的真实变化趋势。
1.2 适用场景
- 中小规模非线性数据集(如传感器信号拟合):传感器在工作过程中产生的信号往往呈现出非线性的变化趋势,而且数据规模通常不会特别大。SVR凭借其强大的非线性拟合能力和对中小规模数据的高效处理能力,成为传感器信号拟合的理想选择。它能够准确地捕捉信号的变化规律,为后续的数据分析和决策提供可靠的依据。
- 需要控制预测误差边界的场景(如工业制造公差控制):在工业制造过程中,对产品的质量控制要求极高,任何超出公差范围的产品都可能成为次品。SVR通过设置ε-不敏感带,可以有效地控制预测误差的边界,确保模型的预测结果在可接受的误差范围内。这使得它在工业制造公差控制中发挥着重要作用,帮助企业提高产品质量,降低生产成本。
2. 数学原理与优化推导
2.1 ε-不敏感损失函数
SVR的核心之一是ε-不敏感损失函数,它定义了一个允许的预测误差范围ε。在这个范围内,模型的预测误差被认为是可以接受的,损失为0;只有当预测误差超过ε时,才会计算损失。其数学表达式为:
[
L_\epsilon(y, \hat{y}) =
\begin{cases}
0 & \text{if } |y - \hat{y}| \leq \epsilon \
|y - \hat{y}| - \epsilon & \text{otherwise}
\end{cases}
]
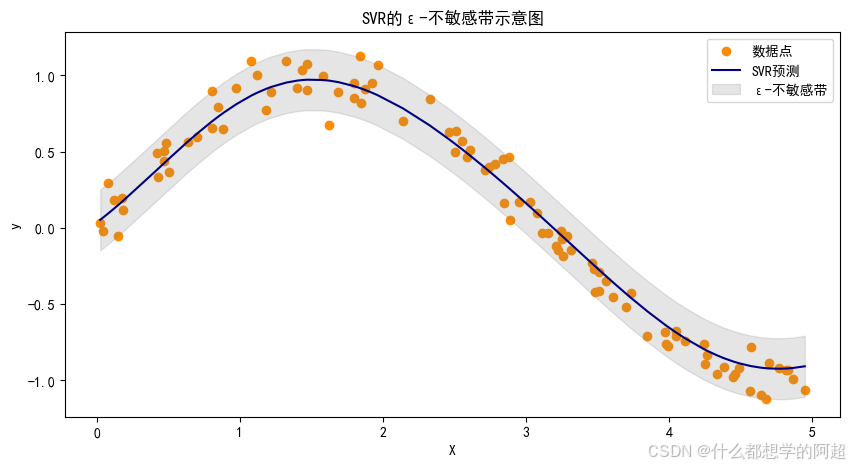
为了更直观地理解这一函数,我们可以通过图像来展示。假设我们有一组数据点和一条预测曲线,当预测值与真实值之间的差值在ε范围内时,损失为0,对应到图像上就是在真实值上下ε的范围内,预测曲线与真实值之间的区域没有损失。而当差值超出ε范围时,损失就等于差值减去ε,在图像上表现为超出范围部分的差值计算损失。
2.2 原始优化问题
SVR的原始优化问题旨在最小化权重范数,同时控制松弛变量。其数学表达式如下:
[
\begin{aligned}
\min_{\mathbf{w}, b} &\quad \frac{1}{2} |\mathbf{w}|^2 + C \sum_{i=1}^N (\xi_i + \xi_i^) \
\text{s.t.} &\quad y_i - (\mathbf{w}^T \phi(\mathbf{x}_i) + b) \leq \epsilon + \xi_i \
&\quad (\mathbf{w}^T \phi(\mathbf{x}_i) + b) - y_i \leq \epsilon + \xi_i^ \
&\quad \xi_i, \xi_i^* \geq 0
\end{aligned}
]
在这个优化问题中,( \phi(\cdot) ) 是核映射函数,它将原始数据映射到高维空间;( C ) 为惩罚系数,用于平衡权重范数和松弛变量的影响。惩罚系数 ( C ) 就像是一个调节器,它决定了模型对误差的容忍程度。当 ( C ) 较大时,模型对误差的容忍度较低,会更加注重对每个样本的拟合精度;当 ( C ) 较小时,模型对误差的容忍度较高,更注重模型的平滑性和泛化能力。
2.3 对偶问题与核技巧
为了更高效地求解原始优化问题,我们通过拉格朗日乘子法将其转化为对偶形式:
[
\begin{aligned}
\max_{\alpha, \alpha^} &\quad -\frac{1}{2} \sum_{i,j} (\alpha_i - \alpha_i^)(\alpha_j - \alpha_j^) K(\mathbf{x}_i, \mathbf{x}j) - \epsilon \sum{i} (\alpha_i + \alpha_i^) + \sum_{i} y_i (\alpha_i - \alpha_i^) \
\text{s.t.} &\quad \sum_{i} (\alpha_i - \alpha_i^) = 0 \
&\quad 0 \leq \alpha_i, \alpha_i^* \leq C
\end{aligned}
]
经过转化后,预测函数变为:
[
\hat{y} = \sum_{i=1}^N (\alpha_i - \alpha_i^*) K(\mathbf{x}_i, \mathbf{x}) + b
]
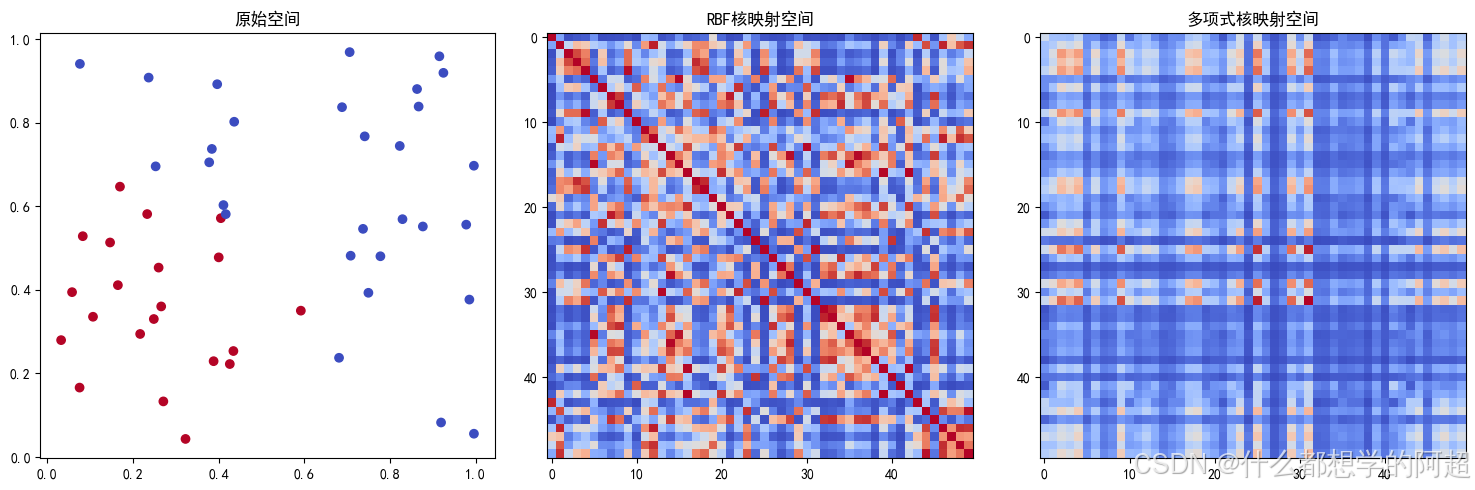
这里的 ( K(\mathbf{x}_i, \mathbf{x}_j) ) 就是核函数,它巧妙地实现了在高维空间中进行内积运算,而无需显式地将数据映射到高维空间,大大降低了计算复杂度。常见的核函数有线性核、多项式核、径向基函数(RBF)核等,不同的核函数适用于不同的数据分布和问题类型。
3. 代码实战:非线性函数拟合
3.1 生成带噪声的正弦数据
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
X = np.sort(5 * np.random 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











