







【CRF系列】第7篇:CRF实战——经典工具与Python库应用
1. 引言
在前面六篇文章中,我们系统地学习了CRF的理论基础、数学模型、参数学习和解码算法。现在,是时候将理论付诸实践了!
本文将介绍两种在实际项目中广泛使用的CRF工具:
- CRF++:一个高效的C++实现,广泛用于各类序列标注任务
- sklearn-crfsuite:一个Python库,提供了类似scikit-learn的易用API
我们将详细介绍这两种工具的安装、使用方法、数据格式要求,并通过实际案例(中文分词和命名实体识别)展示完整的应用流程。无论你是更倾向于命令行工具还是Python编程,本文都将帮助你快速上手CRF模型,并将其应用到自己的项目中。
动手实践是掌握任何技术的最佳方式,让我们开始这个激动人心的实战之旅吧!
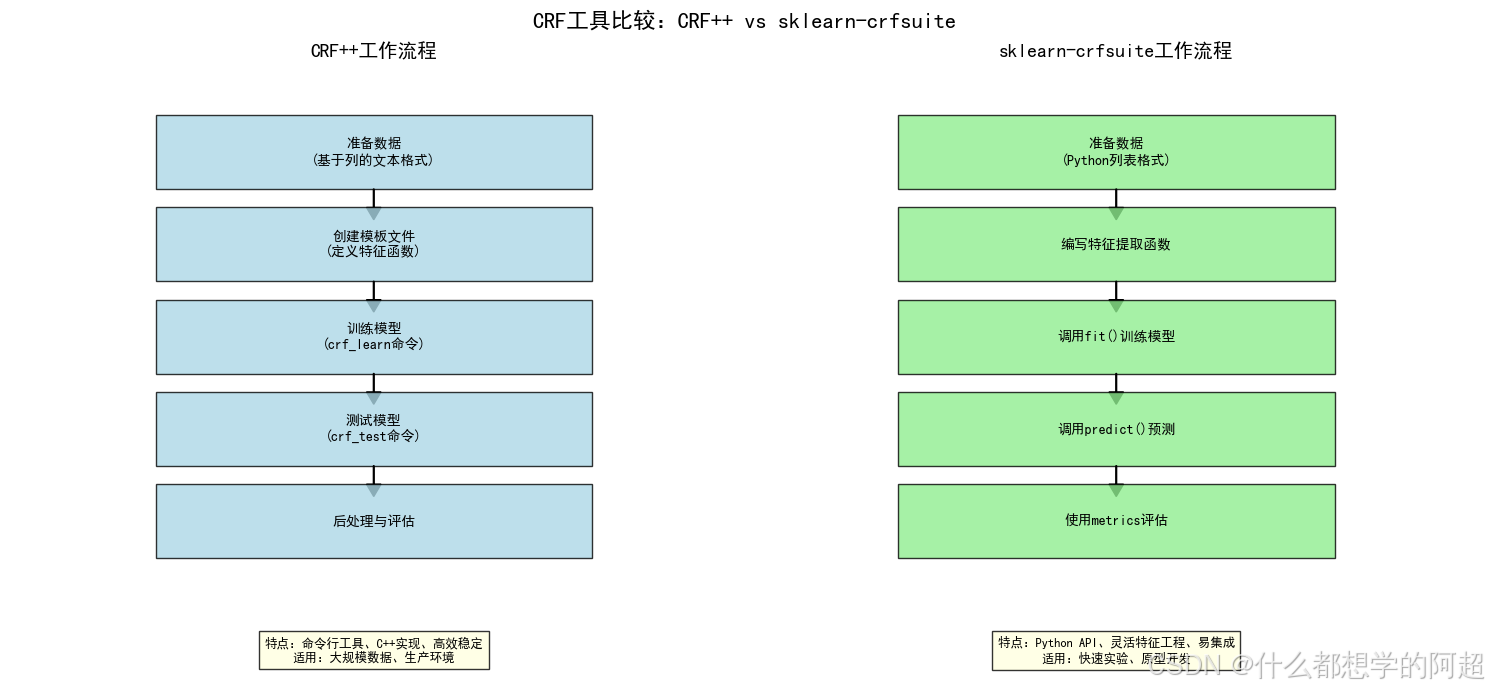
2. 实战工具一:CRF++
2.1 CRF++简介
CRF++是由日本学者Taku Kudo开发的开源CRF实现,具有以下特点:
- 高效:C++实现,运行速度快,支持多线程训练
- 灵活:通过模板文件灵活定义特征
- 稳定:广泛用于学术研究和工业应用
- 资源占用:对大规模数据集有良好支持
CRF++是一个命令行工具,主要包含两个核心命令:crf_learn(训练模型)和crf_test(测试模型)。
2.2 安装CRF++
Linux/Mac安装
# 下载源码
wget https://github.com/taku910/crfpp/archive/master.zip
unzip master.zip
cd crfpp-master
# 编译安装
./configure
make
sudo make install
Windows安装
Windows用户可以下载预编译的二进制文件:
- 访问官方网站
- 下载适合Windows的二进制包
- 解压后将bin目录添加到PATH环境变量
安装完成后,可以在命令行中输入crf_learn -h和crf_test -h来确认是否安装成功。
2.3 CRF++核心命令详解
crf_learn:训练模型
基本语法:
crf_learn [options] template_file train_file model_file
主要参数:
template_file:模板文件,定义特征函数train_file:训练数据文件model_file:输出的模型文件
重要选项:
-a <algorithm>:指定训练算法,默认为CRF-L2,可选CRF-L1(L1正则化)-c <float>:正则化系数,默认为1.0-f <num>:特征频率阈值,低于此频率的特征将被忽略,默认为1-p <num>:线程数,默认为1-t:生成文本格式的模型(默认为二进制)-m <num>:内存上限(MB),默认为1000MB
例如:
crf_learn -f 3 -c 1.5 -p 4 template.txt train.data model
这个命令使用4个线程训练模型,特征频率阈值为3,L2正则化系数为1.5。
crf_test:测试模型
基本语法:
crf_test -m model_file test_files
主要参数:
-m model_file:训练好的模型文件test_files:测试数据文件
重要选项:
-o <filename>:输出结果到文件-v:输出概率值-n <num>:输出N-best结果-t:使用文本格式的模型(如果模型是文本格式的)
例如:
crf_test -m model -o output.txt test.data
2.4 CRF++文件格式
训练/测试数据格式
CRF++使用简单的基于列的文本格式。每行对应一个token(如单词或字符),不同的特征和标签以列的形式排列。空行表示序列的边界(如句子的结束)。最后一列必须是标签列。
例如,词性标注任务的数据:
I PRP
love VB
New NNP
York NNP
. .
He PRP
hates VBZ
Washington NNP
. .
如果有更多特征,可以添加额外的列:
I I PRP B-NP
love love VB B-VP
New New NNP B-NP
York York NNP I-NP
. . . O
He He PRP B-NP
hates hate VBZ B-VP
Washington Washington NNP B-NP
. . . O
这里第一列是单词,第二列是词干,第三列是词性,第四列是短语标签。
模板文件语法
模板文件定义了如何从训练数据中生成特征函数。上一篇文章已经详细介绍过模板的语法,这里简要回顾:
# Unigram模板,只与当前标签相关
U00:%x[0,0] # 当前词
U01:%x[-1,0] # 前一个词
U02:%x[1,0] # 后一个词
# Bigram模板,与当前标签和前一个标签相关
B
其中:
%x[row,col]表示相对于当前位置的特征,row是相对行偏移,col是列索引U开头的行定义Unigram特征B开头的行定义Bigram特征
输出格式
crf_test的标准输出格式是在原始测试数据的每行末尾添加一列预测标签:
I PRP PRP
love VB VB
New NNP NNP
York NNP NNP
. . .
He PRP PRP
hates VBZ VBZ
Washington NNP NNP
. . .
使用-v选项时,还会输出标签的概率信息。
2.5 实战案例:中文分词
让我们通过一个中文分词案例来展示CRF++的完整使用流程。
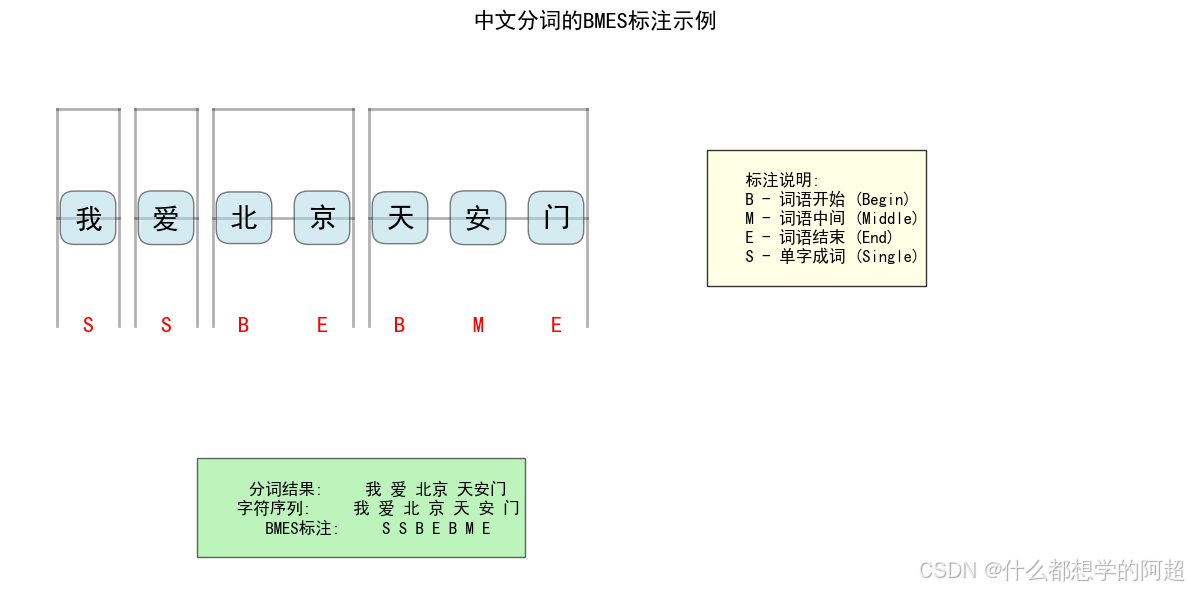
第一步:准备数据
中文分词通常使用BMES标注体系:
- B: 词的开始
- M: 词的中间
- E: 词的结束
- S: 单字成词
训练数据示例(已分词的句子转换为字级别的BMES标注):
# 转换脚本示例
def convert_to_bmes(sentence):
"""将已分词的句子转换为BMES标注"""
words = sentence.strip().split()
chars = []
tags = []
for word in words:
if len(word) == 1:
chars.append(word)
tags.append('S')
else:
for i, char in enumerate(word):
chars.append(char)
if i == 0:
tags.append('B')
elif i == len(word) - 1:
tags.append('E')
else:
tags.append('M')
return chars, tags
# 示例
sentence = "我 爱 北京 天安门"
chars, tags = convert_to_bmes(sentence)
for char, tag in zip(chars, tags):
print(f"{
char}\t{
tag}")
输出将是:
我 S
爱 S
北 B
京 E
天 B
安 M
门 E
将大量已分词文本转换为这种格式,得到训练和测试数据。
第二步:创建模板文件
我们为中文分词创建一个模板文件template.txt:
# 字符特征
U00:%x[0,0] # 当前字
U01:%x[-1,0] # 前一个字
U02:%x[1,0] # 后一个字
U03:%x[-2,0] # 前两个字
U04:%x[2,0] # 后两个字
# 字符组合特征
U05:%x[-1,0]/%x[0,0] # 前一个字+当前字
U06:%x[0,0]/%x[1,0] # 当前字+后一个字
U07:%x[-1,0]/%x[0,0]/%x[1,0] # 前一个字+当前字+后一个字
# 是否为标点、数字等(假设额外有一列表示字符类型)
U10:%x[0,1] # 当前字的类型
# Bigram特征
B
第三步:训练模型
假设我们已经准备好了训练数据train.data,现在使用以下命令训练模型:
crf_learn -f 3 -c 1.5 -p 4 template.txt train.data model_seg
第四步:应用模型进行分词
准备一个测试文件test.data,其格式与训练数据相同,但不包含标签列,或包含标签列但仅用于评估。
crf_test -m model_seg test.data > output.txt
第五步:将BMES标注结果转回分词结果
def convert_bmes_to_words(chars, tags):
"""将BMES标注转换回分词结果"""
words = []
current_word = ""
for char, tag in zip(chars, tags):
if tag == 'S':
words.append(char)
elif tag == 'B':
current_word = char
elif tag == 'M':
current_word += char
elif tag == 'E':
current_word += char
words.append(current_word)
current_word = ""
return ' '.join(words)
# 处理c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











