






在看论文Network in Network时,发现一个概念很陌生–cross-channel pooling。于是上网查,找到下面的一个回答:

大概意思是说:这个概念在论文Maout Networks中有解释。
假设你有一个线性模块,该模型有50个输出(或者说是有50个channels),但是你想要的是5个输出。你就可以使用cross-channel pooling来减少对channel进行下采样(使用最大池化)。
如果是一个卷积模块,输出了50个特征图,那么通过cross-channel pooling就可以输出5个特征图。具体思路:输出特征图(这里的特征图指的是经过cross-channel pooling输出的5个特征图)中的每个点是10个特征图(这里的特征图指的是原始的50个特征图)中对应点的最大值。
一个cross-channel pooling层不是一个maxout层(这个应该是论文中的概念),两者之间是不同的。Maxout中的每个单元都在50个特征图上操作,而cross-channel pooling的每个单元是在10个特征图上进行操作。Maxout层中的Maxout单元的数量是没有限制的,而cross-channel pooling层中,其数量不能超过输入的数量。
然后又看到另一篇博文,下面的内容是对该博文的翻译:
不管何时,只要我展示或是讨论GoogleNet,就会有一个问题浮现:为什么使用1 * 1的卷积?1*1卷积难道不冗余吗?
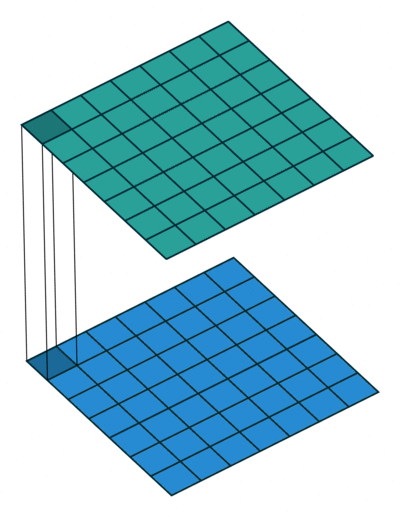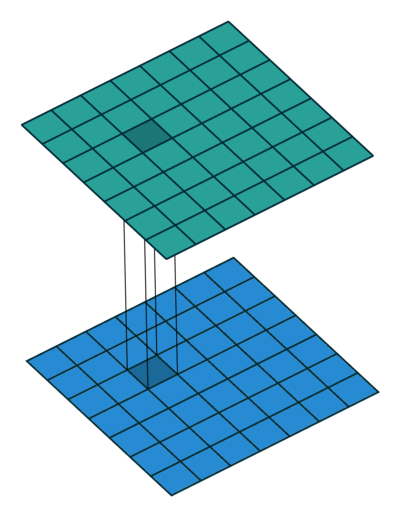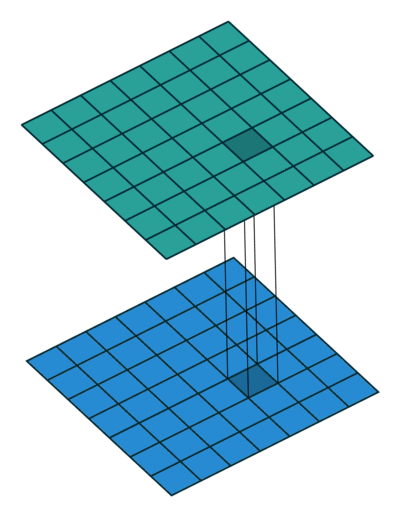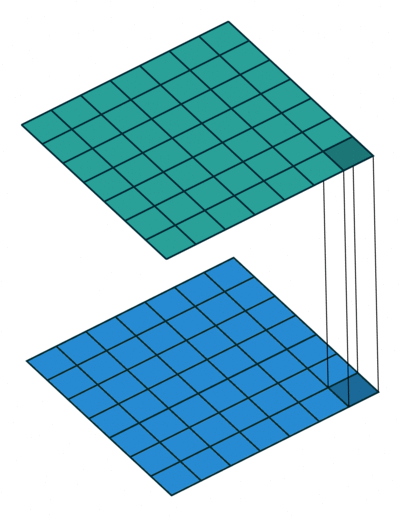
简单回答:
最简单的解释是是1x1卷积可以导致维数减少。例如,一个20020050的特征图,通过20个11的卷积核运算之后,其维度就可以减少为200200*20。但是上述问题仍然没有解决,这是卷积神经网络中最有效的维数约减方法吗?其功效和效率如何?
复杂回答:
特征转换(feature transformation)
尽管1 * 1卷积是一个“特征池化”技术,但是它不仅仅是对给定层的各种通道/特征映射中的特征汇总。1*1卷积在滤波空间中的作用类似与坐标相关的变换。这里需要注意的是,这个转换是严格线性的,但是在1x1卷积的大多数应用中,它是由一个像ReLU这样的非线性激活层代替的。这种转换是通过(随机)梯度下降来学习的。但一个重要的区别是,由于更小的内核大小(1x1),它遭受的过度拟合更少。
更深层的网络(Deeper Network)
1*1卷积第一次在Network in Network中提出,在这篇论文中,作者的目标是在不简单地堆叠更多层的情况下生成更深层的网络,它用1x1和3x3的混合卷积的较小感知器层代替少数滤波器,也就是说,它可以被看作是“变宽”而不是“变深”,但是应该注意的是,在机器学习术语中,“变宽”通常意味着给训练增加更多的数据。1x1 (x F)卷积的组合在数学上等价于一个多层感知器.
Inception Module
在GoogltNet 框架中,使用1*1卷积的目的有两个:
- 通过添加“Inception module”使得神经网络加深,像Network in Network论文中一样
- 减少“Inception module”内的维度
另外,通过在每次1x1卷积后立即使用ReLU来增加更多的非线性
下面是GoogleNet论文中的框架图:
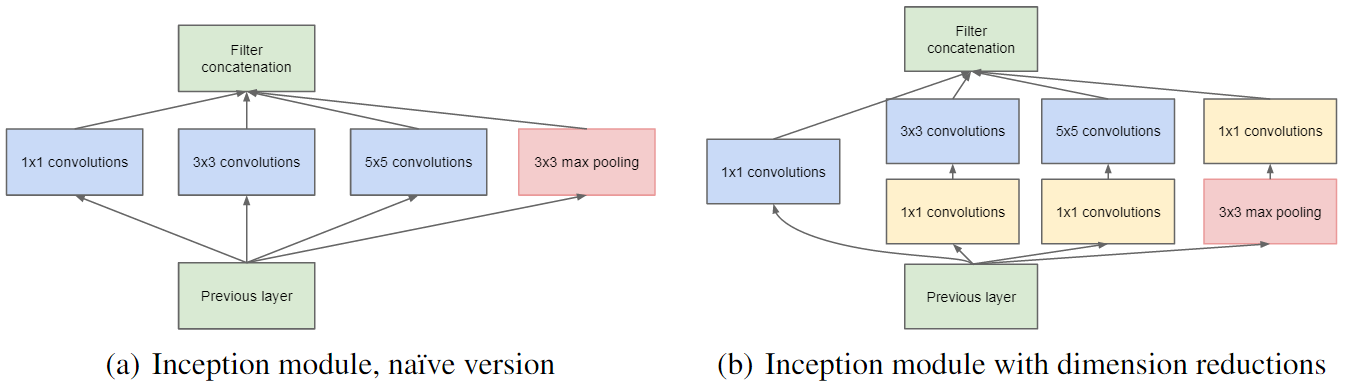
从上图的右半部分可以看出,1*1卷积核(黄色)是在5 * 5 和 3 * 3卷积核之前用来减少维度。需要注意的是,一个两步卷积运算总是可以合并成一个卷积运算,但是在这种情况下,以及在大多数其他深度学习网络中,卷积之后都会被非线性激活,因此卷积不再是线性的计算,也不能被合并。
在设计这样一个网络时,需要注意的是,初始卷积核的大小应该大于1x1,以便具有能够捕获局部空间信息的感受野。在NIN论文中,1X1卷积层相当于跨信道参数池化层。论文中的原话:“这种级联的跨通道参数池结构允许跨通道信息的复杂和可学习的交互”。
跨渠道信息学习(级联1x1卷积)具有生物学启发,因为人类视觉皮层具有调整到不同方向的感受域(内核)。 如下图

更多用处:
-
1×1卷积可以与最大池化合并

这个图原博文也没有解释,我也没有搞懂,有知道的小伙伴,欢迎评论指正。 -
1×1卷积的步幅越大,通过降低分辨率,数据的减少就越大,而丢失的非空间相关信息很少

- 像Yann Lecun 说的那样,可以使用1×1卷积来代替全连接层

具体做法:
假设原来的卷积神经网络:输入为[224 , 224 , 3],经过一系列卷积层之后,最后一个卷积层(+池化层)的输出为[7 , 7 , 512],接下来就将输出的[7 , 7 , 512] 的feature map展开成7 * 7 * 512,再进行全连接层,全连接层的神经元数量分别为4096,1000(最后的输出结果为1000个)。
如果使用1*1的卷积来代替全连接层的话,可以:
- 在最后一个卷积层输出的feature map为[7,7,512],我们使用一个7 * 7 * 4096的卷积核对其卷积,得到feature map为[1 , 1 , 4096].
- 然后使用一个1 * 1 * 1000的卷积核进行卷积操作,最终得到的输出为[1,1,1000]。















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









