要实现论文中描述的方法,我们需要分几个步骤来构建和训练模型。以下是一个简化版的实现示例,使用Python和TensorFlow/Keras框架。这个示例将包括以下几个部分:
1. **数据准备**:加载和预处理图像数据。
2. **模型定义**:定义基础CNN模型和选择性层注意力网络(SAN)。
3. **特征图可视化**:使用Grad-CAM方法进行特征图可视化。
4. **模型评估**:计算并展示精度指标和特征图重合度分数。
### 1. 数据准备
首先,我们需要准备数据集。假设我们有一个包含损坏图像的数据集,并且已经进行了标注。
```python
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据路径
data_dir = 'path_to_your_data'
train_dir = os.path.join(data_dir, 'train')
val_dir = os.path.join(data_dir, 'val')
test_dir = os.path.join(data_dir, 'test')
# 图像尺寸
img_size = (224, 224)
batch_size = 32
# 数据生成器
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
val_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=img_size,
batch_size=batch_size,
class_mode='categorical'
)
val_generator = val_datagen.flow_from_directory(
val_dir,
target_size=img_size,
batch_size=batch_size,
class_mode='categorical'
)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=img_size,
batch_size=batch_size,
class_mode='categorical',
shuffle=False
)
```
### 2. 模型定义
定义一个基础的VGG19模型,并在此基础上添加选择性层注意力模块(SAN)。
```python
import tensorflow as tf
from tensorflow.keras.applications import VGG19
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, Lambda
def select_layer_attention_module(input_tensor, layer_name):
# 获取指定层的输出
base_model = VGG19(weights='imagenet', include_top=False, input_tensor=input_tensor)
layer_output = base_model.get_layer(layer_name).output
# 添加选择性注意力机制
attention_map = Conv2D(1, (1, 1), activation='sigmoid')(layer_output)
attention_map = UpSampling2D(size=(32, 32))(attention_map)
return attention_map
def build_san_model(input_shape, layer_name):
inputs = Input(shape=input_shape)
attention_map = select_layer_attention_module(inputs, layer_name)
vgg19 = VGG19(weights='imagenet', include_top=False, input_tensor=inputs)
x = vgg19.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(512, activation='relu')(x)
outputs = tf.keras.layers.Dense(len(train_generator.class_indices), activation='softmax')(x)
model = Model(inputs=inputs, outputs=[outputs, attention_map])
return model
input_shape = (224, 224, 3)
layer_name = 'block4_conv4' # 选择中间层
model = build_san_model(input_shape, layer_name)
model.compile(optimizer='adam', loss=['categorical_crossentropy', 'binary_crossentropy'], metrics=['accuracy'])
```
### 3. 特征图可视化
使用Grad-CAM方法进行特征图可视化。
```python
import cv2
import matplotlib.pyplot as plt
def make_gradcam_heatmap(img_array, model, last_conv_layer_name, pred_index=None):
grad_model = tf.keras.models.Model(
[model.inputs], [model.get_layer(last_conv_layer_name).output, model.output]
)
with tf.GradientTape() as tape:
last_conv_layer_output, preds = grad_model(img_array)
if pred_index is None:
pred_index = tf.argmax(preds[0])
class_channel = preds[:, pred_index]
grads = tape.gradient(class_channel, last_conv_layer_output)
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
heatmap = last_conv_layer_output[0].numpy()
for i in range(pooled_grads.shape[-1]):
heatmap[:, :, i] *= pooled_grads[i]
heatmap = np.mean(heatmap, axis=-1)
heatmap = np.maximum(heatmap, 0) / np.max(heatmap)
return heatmap
def plot_heatmap(img_path, heatmap, cam_path="cam.jpg", alpha=0.4):
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = heatmap * alpha + img
cv2.imwrite(cam_path, superimposed_img)
plt.imshow(cv2.cvtColor(superimposed_img, cv2.COLOR_BGR2RGB))
plt.show()
# 示例图像路径
img_path = 'path_to_your_image.jpg'
img = tf.keras.preprocessing.image.load_img(img_path, target_size=(224, 224))
img_array = tf.keras.preprocessing.image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
heatmap = make_gradcam_heatmap(img_array, model, 'block4_conv4')
plot_heatmap(img_path, heatmap)
```
### 4. 模型评估
计算并展示精度指标和特征图重合度分数。
```python
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 预测
predictions = model.predict(test_generator)
predicted_classes = np.argmax(predictions[0], axis=1)
true_classes = test_generator.classes
# 计算精度指标
accuracy = accuracy_score(true_classes, predicted_classes)
precision = precision_score(true_classes, predicted_classes, average='weighted')
recall = recall_score(true_classes, predicted_classes, average='weighted')
f1 = f1_score(true_classes, predicted_classes, average='weighted')
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
# 计算特征图重合度分数
def calculate_coincidence_score(heatmaps, ground_truth_masks):
scores = []
for heatmap, mask in zip(heatmaps, ground_truth_masks):
normalized_heatmap = heatmap / np.max(heatmap)
error = np.abs(normalized_heatmap - mask)
score = np.exp(np.log(1 - error)).mean()
scores.append(score)
return np.array(scores)
# 假设我们有ground truth masks
ground_truth_masks = ... # 加载或生成ground truth masks
heatmaps = predictions[1]
coincidence_scores = calculate_coincidence_score(heatmaps, ground_truth_masks)
print(f"Coincidence Scores: {coincidence_scores.mean()}")
```
以上代码提供了一个完整的流程,从数据准备到模型定义、特征图可视化以及模型评估。你可以根据具体需求进行调整和优化。








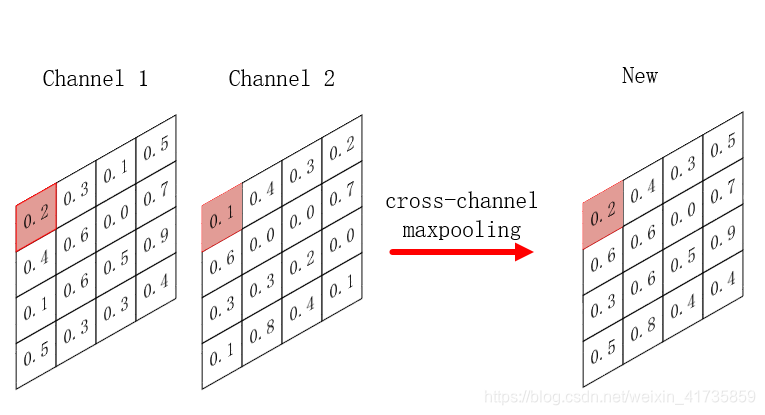
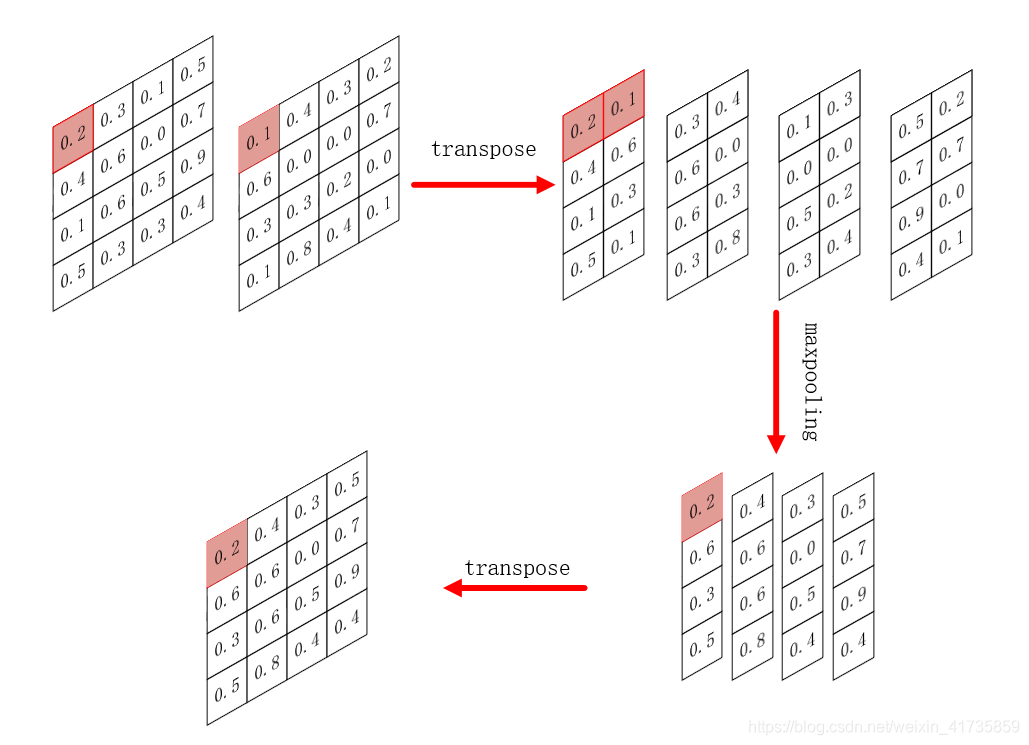

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









