







第十四章 核方法
14.1 简介
到目前为止,我们书上提到的各种方法,包括分类,聚类或者是其它的一些处理手段,我们的特征都是固定大小的一个向量,一般具有如下的形式,![]() 。然而,对于某些类型的对象,如何最好地将其表示为固定大小的特征向量尚不清楚。例如,我们如何表示长度可变的文本文档或蛋白质序列?或者分子结构,具有复杂的三维几何?或者是进化树,它的大小和形状都是可变的。
。然而,对于某些类型的对象,如何最好地将其表示为固定大小的特征向量尚不清楚。例如,我们如何表示长度可变的文本文档或蛋白质序列?或者分子结构,具有复杂的三维几何?或者是进化树,它的大小和形状都是可变的。
解决这类问题的一种方法是为数据定义生成模型,并使用推断出的潜在表示和/或模型的参数作为特征,然后将这些特征插入到标准方法中。比如后面的深度学习,其实从某种程度上就是进行特征的学习。
另一种方法是假设我们有某种方法来测量对象之间的相似性,而不需要将它们预处理成特征向量格式(目前还不太理解)。例如,在比较字符串时,我们可以计算它们之间的edit距离。令![]() 是测量目标
是测量目标![]() 之间的相似性,其中
之间的相似性,其中![]() 是某个抽象的空间。我们就叫
是某个抽象的空间。我们就叫![]() 核函数。
核函数。
在本章中,我们将讨论几种核函数。然后我们描述了一些算法,这些算法可以完全用核函数计算来编写。当我们无法访问(或选择不查看)正在处理的对象x的内部时,可以使用这些方法。
其实读到这里只是大概知道核函数有什么用,不过具体的还没明白是什么个意思。核函数能够从比较原始的数据中,获得一些结构信息,得到一些潜在的表示作为特征
14.2 核函数
我们将核函数定义为两个参数的实值函数,即![]() ,对任何的
,对任何的![]() 。一般来说这个函数是对称以及非负的,即
。一般来说这个函数是对称以及非负的,即![]() 和
和![]() 。所以它可以用来看
。所以它可以用来看![]() 的相似性,但是这个要求也不是必须的。下面我们将给几个具体的例子:
的相似性,但是这个要求也不是必须的。下面我们将给几个具体的例子:
14.2.1 RBF 核函数
平方指数核或者高斯核的定义如下:
![]()
如果![]() 是对角阵,那么可以进一步被简化为:
是对角阵,那么可以进一步被简化为:
那么这里![]() 就是定义第j个维度的特征的重要性的一个尺度。如果
就是定义第j个维度的特征的重要性的一个尺度。如果![]() ,那么相应的维度就可以被忽略,因此这个就被称作ARD核。如果
,那么相应的维度就可以被忽略,因此这个就被称作ARD核。如果![]() 是各向同性的,那么我们就会得到各向同性的核,即:
是各向同性的,那么我们就会得到各向同性的核,即:
这里![]() 称之为带宽。上面的式子是径向基函数(radial basis function, RBF)的一个例子,因为它只是
称之为带宽。上面的式子是径向基函数(radial basis function, RBF)的一个例子,因为它只是![]() 的一个函数。
的一个函数。
14.2.2 比较文档的内核
当我们进行文档的分类或者是检索时,那么我们常常要去比较两个文档![]() 的相似性。如果我们使用词袋模型来表示,即
的相似性。如果我们使用词袋模型来表示,即![]() 表示第j个单词在文档i里面出现的次数。那么基于此,我们可以使用cosine 相似性,即:
表示第j个单词在文档i里面出现的次数。那么基于此,我们可以使用cosine 相似性,即:
![]()
这个其实就是计算向量![]() 之间夹角的cosine值,由于在这里是进行计数,所以说每一个数都是非负的,所以cosine相似性的结果都是介于[0,1]之间的。
之间夹角的cosine值,由于在这里是进行计数,所以说每一个数都是非负的,所以cosine相似性的结果都是介于[0,1]之间的。
但是这样的简单的方法呢并不能工作的很好,主要有两个原因:第一就是由于文章中会有很多流形的单词,比如“the”,“and”等,这些单词会使得![]() 计算出来非常相似,但是实际上并不是这样的。第二就是有很多单词只要出现了一次,可能它就会反复的出现,所以其实这个东西是有点不靠谱的。
计算出来非常相似,但是实际上并不是这样的。第二就是有很多单词只要出现了一次,可能它就会反复的出现,所以其实这个东西是有点不靠谱的。
幸运的是,我们可以使用一些简单的预处理来显著提高性能。其思想是用一种称为TF-IDF表示的新特征向量替换单词计数向量,TF-IDF表示术语频率-逆文档频率(term frequency - inverse document frequency)。
首先,术语频率被定义为计数的对数转换:
![]()
这减少了在一个文档中多次出现的单词的影响。其次,逆文档频率定义为:
其中N是文档的总的数目,分母的话就表示包含术语j的文档有多少个。最终我们定义:
![]()
定义tf和idf术语还有其他几种方法,参见(Manning et al. 2008)了解详细信息。
然后我们把这个应用到cosine 相似性的测量里面去。这样,我们新的核函数就会具有如下形式:
![]()
其中![]() ,这为信息检索提供了良好的结果(Manning et al. 2008)。(Elkan 2005)给出了tf-idf核的概率解释。
,这为信息检索提供了良好的结果(Manning et al. 2008)。(Elkan 2005)给出了tf-idf核的概率解释。
14.2.3 Mercer(正定)核函数
我们有一些研究的方法需要我们的核函数满足如下的特性,即:
我们称这个矩阵叫做Gram matrix,这个矩阵对于任何的输入![]() ,都要是正定的。我们称这样的核函数就是Mercer核函数或者是正定核函数。有文章证明了,其实高斯核函数以及cosine 相似性核函数都是Mercer核函数。
,都要是正定的。我们称这样的核函数就是Mercer核函数或者是正定核函数。有文章证明了,其实高斯核函数以及cosine 相似性核函数都是Mercer核函数。
为什么说Mercer核函数比较重要呢,因为我们有一个叫做Mercer定理的东西。如果Gram matrix是正定的,那么我们就可以对其进行特征分解,即:![]() ,那么对于
,那么对于![]() 中的任何一个元素,我们都有:
中的任何一个元素,我们都有:![]() ,如果我们定义:
,如果我们定义:![]() ,那么可以简化为:
,那么可以简化为:![]() 。因此,我们看到核矩阵中的项可以通过执行特征向量的内积来计算,这些特征向量是由
。因此,我们看到核矩阵中的项可以通过执行特征向量的内积来计算,这些特征向量是由![]() 隐式定义的。总的来说就是,如果核函数是Mercer,那么就会存在一个函数
隐式定义的。总的来说就是,如果核函数是Mercer,那么就会存在一个函数![]() ,使得
,使得![]() ,其中
,其中![]() 取决于
取决于![]() 的特征函数。
的特征函数。
我们考虑一个多项式的核函数,![]() ,其中
,其中![]() 。在这个情况下,对应的特征向量
。在这个情况下,对应的特征向量![]() 将会包含一直到M阶的任何项。举个例子,如果
将会包含一直到M阶的任何项。举个例子,如果![]() ,以及
,以及![]() ,我们有:
,我们有:
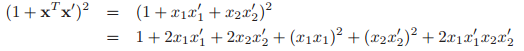
这个可以被改写为![]() 这样的形式,其中:
这样的形式,其中:
![]()
所以使用这个核就相当于在一个6维的特征空间中工作。在高斯核的情况下,特征映射存在于无限维空间中。在这种情况下,明确表示特征向量显然是不可行的。
关于不是Mercer 核函数的一个例子就是sigmoid核函数,定义如下:
![]()
(注意这里虽然叫做sigmoid核函数,但是实际上用的tanh函数),这个核函数的出现是由于多层感知器激发的(在16.5中有),但是其实并没有什么直接的理由。(关于真实的神经网络核函数,在15.4.5中会有一个正定的)。
一般来说,直接建立一个Mercer核函数是困难的,需要函数分析的技术。但是,可以通过使用一组标准规则从简单的Mercer核函数构建新的Mercer核函数。例如,如果![]() 都是Mercer核函数,那么
都是Mercer核函数,那么![]() 也是Mercer核函数。
也是Mercer核函数。
14.2.4 线性核函数
从核函数中推导出特征向量一般来说是比较困难的,可能仅仅在核是Mercer的情况下有用,但是呢从特征向量去得到核函数却是非常简单的,因为我们只需要计算:![]() 。
。
如果![]() ,我们可以得到线性的核函数,定义如下:
,我们可以得到线性的核函数,定义如下:![]() 。
。
这个一般适用于原始的数据已经具有很高的维度了,这样的话很有可能原始数据之间相互的信息就是独立的,在这种情况下,决策边界很可能是原始特征的线性组合,因此不需要在其他特征空间中工作。
当然不是说所有的特征维度很高的数据都适用,因为有可能维度很高,但是信息却不独立,比如图像,这个时候往往我们就需要非线性的核函数。
14.2.5 Matern 核函数
Matern 核函数经常用于高斯过程回归当中(见15.2节中),具有如下的形式,即:
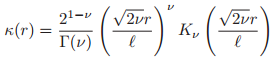
其中![]() ,
,![]() ,
,![]() 是修正的贝塞尔函数。当
是修正的贝塞尔函数。当![]() ,这个方法接近于SE核函数(高斯核函数)。当
,这个方法接近于SE核函数(高斯核函数)。当![]() ,核函数简化为:
,核函数简化为:
![]()
如果D = 1,我们用这个核函数来定义一个高斯过程(见第15章),那么我们会得到奥恩斯坦-乌伦贝克过程,它描述了一个粒子经历布朗运动的速度。
14.2.6 字符串核函数
如果我们的输入是结构化的对象时,那么我们的核函数的威力就能够真正的展现出来了。下面举个例子,我们现在描述一种使用字符串核函数比较两个可变长度字符串的方法。
考虑两个字符串![]() 和
和![]() ,它们的长度分别是
,它们的长度分别是![]() 和
和![]() ,每个都是从一个字母表
,每个都是从一个字母表![]() 中定义的。例如,考虑两个氨基酸序列,是从一个有20个字母的字母表中定义的,即:
中定义的。例如,考虑两个氨基酸序列,是从一个有20个字母的字母表中定义的,即:![]()
![]() 。
。![]() 是一个长度为110的序列,如下:
是一个长度为110的序列,如下:
![]()
![]() 是一个长度为153的序列:
是一个长度为153的序列:

这些字符串都有子字符串LQE。我们可以将两个字符串的相似性定义为它们共有的子字符串的数量。
更正式的,我们定义对于一个字符串![]() ÿ
ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5434
5434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









