







MNIST数据集知识合集
认识MNIST数据集
MNIST数据集是一个手写数字数据集,手写数字包括0~9,共10个类别。训练数据集有60000张28*28单通道(灰度图像)的图像;测试数据集中有10000张28*28单通道图像。
更多详细信息可参见官方网址:MNIST 其中提到数据集包括四个部分:
- training set images: train-images-idx3-ubyte.gz
- training set labels: train-labels-idx1-ubyte.gz
- test set images: t10k-images-idx3-ubyte.gz
- test set labels: t10k-labels-idx1-ubyte.gz
通过本地文件加载MNIST数据集
实验中要使用mnist数据集时,需要先加载数据集。方法之一是从先自己下载MNIST网址中给出的4个文件链接:

之后再写代码读取.gz文件中的信息。
其中细节感觉太过复杂(/(ㄒoㄒ)/~~),在网上看到这篇知乎文章,代码很详细,之后学习!直接解码idx-ubyte文件 以及pytorch中自定义dataset读取 [这里关于pytorch里面如何直接继承Dataset类自定义加载自己本地数据的方法,以及dataset类和dataloder类的关系需要再学习😔]
这是一个直接读取然后转换成numpy的:
import os
import numpy as np
'''直接从ubyte文件读取数据'''
data_dir = "./data/MNIST/raw"
fd = open(os.path.join(data_dir, 'train-images-idx3-ubyte'))
#读取ubyte文件并转换成numpy
loaded = np.fromfile(file=fd, dtype=np.uint8)
#train dataset原始的ubyte文件前面16个字节存的其他的 跳过
trX = loaded[16:].reshape((60000, 28, 28, 1)).astype(np.float64)
fd = open(os.path.join(data_dir, 'train-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd, dtype=np.uint8)
#train label原始的ubyte文件前面8个字节存的其他的 跳过
trY = loaded[8:].reshape((60000)).astype(np.int32)
X = trX
Y = trY
print(X.shape)
print(Y.shape)
torchvision.datasets加载MNIST数据集
torchvision.datasets中有很多数据集的加载方法,比如Cifar10、STL10、SVHM、ImageNet(这个应该是需要自己先下载好,从本地文件加载)等,MNIST能用torchvison.datasets.MNIST()直接加载:
from torchvision import datasets, transforms
#下载测试集
train_dataset = datasets.MNIST('./data', #下载后存储的路径,根据实际情况使用绝对路径or相对路径
train=True, #训练数据集
transform=transforms.ToTensor(), #转换成tensor
download=True #需要下载(如果本地以及下载好文件,可设置成False后从本地加载(不过好像直接设置会报错
)
test_dataset = datasets.MNIST('./data', train=False, #测试数据集
transform=transforms.ToTensor(),
download=True)
运行后目录下多了对应的数据集,有8个文件,仔细看的话是4个可以直接读取的ubyte文件和4个.gz的压缩文件:
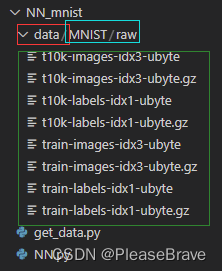
不过需要注意的是,一开始的路径是’./data’,但是实际上下载后还有两级目录,最终存储的路径是"./data/MNIST/raw",在后续加载对应的文件进行读取的时候,需要注意路径问题:
root="./data/MNIST/raw"
可视化(即转换成.jpg/.png之类的文件)
通过上述torchvision.dataset.MNIST加载数据集之后,因为transform=transforms.ToTensor(),所以最终图像数据是tensor类型;而实际上torchvision.dataset.MNIST是将原本ubyte数据处理成PIL的image文件,PIL可以直接存为.jpg/.png:
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import numpy as np
import os
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True,
transform=None) #这里没有转换成其他任何形式
# 获取第一张图像和标签
image, label = train_dataset[0]
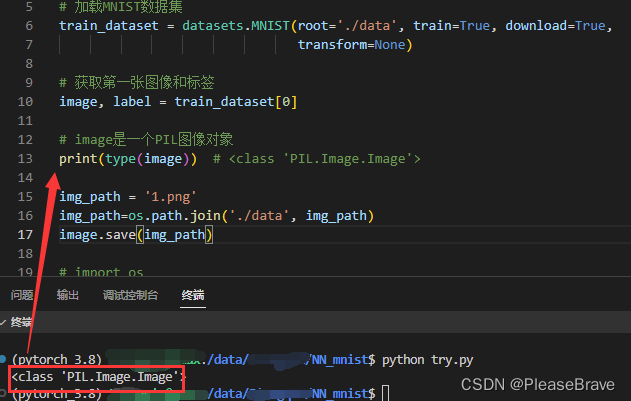
# image是一个PIL图像对象
print(type(image)) # <class 'PIL.Image.Image'>
img_path = '1.png'
img_path=os.path.join('./data', img_path)
image.save(img_path)
运行结果:

————————————————
!!!待解决问题!!!:PIL存为图像
这里还有一个在网上看到的MNIST可视化,直接从ubyte文件读取并可视化的,用到了skimage这个库的skimage.io.save,这个方法我没咋明白,代码及运行结果如下:
import os
from skimage import io
import torchvision.datasets.mnist as mnist
from torchvision import datasets, transforms
#下载测试集
train_dataset = datasets.MNIST('./data', #下载后存储的路径
train=True, #训练数据集
transform=transforms.ToTensor(), #转换成tensor
download=True #需要下载(如果本地以及下载好文件,可设置成False后从本地加载(不过好像直接设置会报错
)
test_dataset = datasets.MNIST('./data', train=False, #测试数据集
transform=transforms.ToTensor(),
download=True)
#直接从ubyte文件中读取图像数据
root="./data/MNIST/raw"
train_set = (
mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte'))
)
test_set = (
mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte'))
)
print("training set :",train_set[0].size())
print("test set :",test_set[0].size())
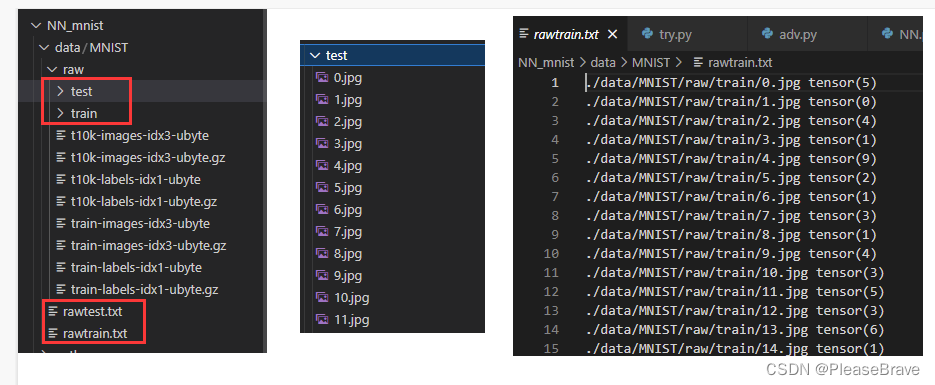
#转换成image(可视化过程)
def convert_to_img(train=True):
if(train):
f=open(root+'train.txt','w')#这是label,单独存在txt文件中
data_path=root+'/train/'
if(not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(train_set[0],train_set[1])):
img_path=data_path+str(i)+'.jpg'
io.imsave(img_path,img.numpy())#转换成.jpg并存储
f.write(img_path+' '+str(label)+'\n')
f.close()
else:
f = open(root + 'test.txt', 'w')
data_path = root + '/test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(test_set[0],test_set[1])):
img_path = data_path+ str(i) + '.jpg'
io.imsave(img_path, img.numpy())
f.write(img_path + ' ' + str(label) + '\n')
f.close()
convert_to_img(True)#转换训练集
convert_to_img(False)#转换测试集
疑惑—datasets.mnist和datasets.MNIST
………………待学习
问题—download=False运行报错
用torchvision.dataset.MNIST加载MNIST数据集,直接设置download=False会报错:
解决参考:参考1 和 参考2
搭建CNN用于数字识别
……………………待学习














 1682
1682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}