






使用卷积神经网络通过 TensorFlow 和 Keras 对手写数字进行分类 | 监督深度学习
MNIST 数据集和数字分类
当您开始使用不同的神经网络架构学习深度学习时,您会意识到最强大的监督深度学习技术之一是卷积神经网络(简称“CNN”)。CNN 的最终结构实际上与常规神经网络 (RegularNets) 非常相似,其中包含具有权重和偏差的神经元。此外,就像在 RegularNets 中一样,我们在 CNN 中使用损失函数(例如交叉熵或 softmax)和优化器(例如 adam 优化器)。此外,在 CNN 中,还有卷积层、池化层和展平层。CNN 主要用于图像分类,但同样也可以适用于其他应用领域,例如自然语言处理。
为什么选择卷积神经网络?
RegularNets 的主要结构特征是所有的神经元都相互连接。例如,当我们有 28 x 28 像素的灰度图像输入时,我们在输入层和第一个隐藏层之间有 784(28 x 28 x 1)个神经元。然而,大多数图像有更多的像素,而且它们不是灰度级的。因此,假设我们有一组 4K 超高清彩色图像,我们将有 26,542,080(4096 x 2160 x 3)个不同的神经元在第一层相互连接,太大的参数量并不现实。因此,我们可以说 RegularNets 不适合用于图像分类。然而,尤其是在涉及图像时,两个单独的像素之间似乎几乎没有相关性或关系,除非它们彼此靠近。这促进了添加卷积层和池化层的想法。
CNN 中的层
我们能够在卷积神经网络中使用许多不同的层。然而,卷积层、池化层和全连接层是最重要的。因此,在实现它图像分类网络的构建之前,我将快速介绍这些层。
卷积层
卷积层是我们从数据集中的图像中提取特征的第一层。由于像素仅与相邻和靠近的像素相关,因此卷积使我们能够保留图像不同部分之间的关系。卷积基本上是用较小的像素过滤器对图像进行过滤,以减小图像的尺寸而不丢失像素之间的关系。当我们使用步幅为 1x1 的 3x3 滤波器(每步移动 1 个像素)对 5x5 图像应用卷积时。我们最终会得到 3x3 的输出(复杂度降低 64%)。
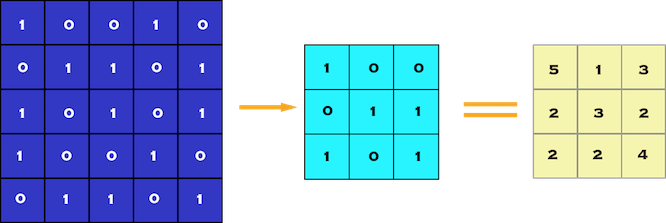
图 1:5 x 5 像素图像与 3 x 3 像素滤波器的卷积(步长 = 1 x 1 像素)
池化层
在构造 CNN 时,通常在每个卷积层之后插入池化层以减少表示的空间大小,从而减少参数数量,降低计算复杂度。此外,池化层也有助于解决过拟合问题。基本上,我们通过计算这些像素内的最大值、平均值或求和值来选择池化方式以减少参数量。Max Pooling 是最常见的池化技术之一,其演示如下:
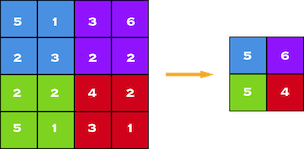
最大池化 - 2 x 2
全连接层
一个完全连接的网络是我们的 RegularNet,其中每个参数相互链接以确定每个参数对 label 的真实关系和影响。由于卷积层和池化层大大降低了我们的空间复杂度,因此我们最终可以构建一个完全连接的网络来对我们的图像进行分类。一组全连接层如下所示:
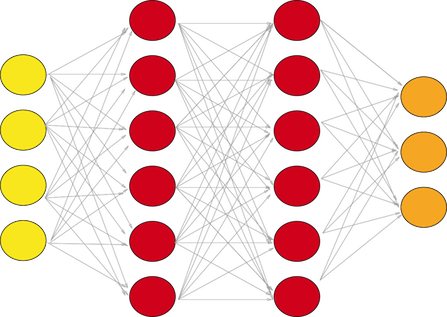
具有两个隐藏层的全连接层
现在您对我们将使用的各个层有了一些了解,我认为是时候分享一个完整的卷积神经网络的概览了。
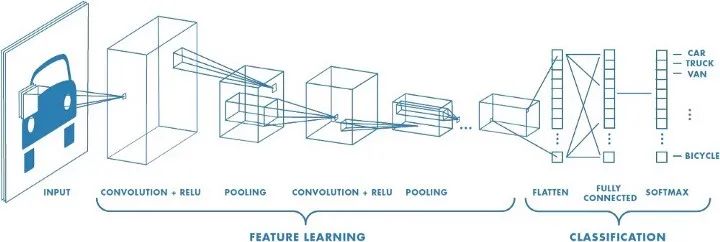
卷积神经网络示例
现在您已经了解了如何构建可用于图像分类的卷积神经网络,我们可以获得最常用的分类数据集:MNIST 数据集,它是一个大型手写数字数据库,通常用于训练各种图像处理。
下载 MNIST 数据集
MNIST 数据集是最常用于图像分类的数据集之一,可以从许多不同的网址下载。事实上,Tensorflow 和 Keras 允许我们直接从它们的 API 导入和下载 MNIST 数据集。因此,我将用以下两行代码 import TensorFlow,并通过 Keras API 下载 MNIST 数据集。
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()MNIST 数据库包含 60,000 张训练图像和 10,000 张来自美国人口普查局员工和美国高中生的测试图像。因此,在第二行中,我将这两组分开作为训练和测试,并将标签和图像分开。x_train 和 x_test 部分包含灰度 RGB 代码(从 0 到 255),而 y_train 和 y_test 部分包含从 0 到 9 的标签,代表它们实际是哪个数字。为了可视化这些数字,我们可以使用 matplotlib 进行展示。
import matplotlib.pyplot as plt
%matplotlib inline # Only use this if using iPython
image_index = 7777 # You may select anything up to 60,000
print(y_train[image_index]) # The label is 8
plt.imshow(x_train[image_index], cmap='Greys')当我们运行上面的代码时,我们将得到如下所示的图像。

索引 7777 处示例图像的可视化结果
我们还需要知道数据集的形状以将其输入至卷积神经网络。因此,我将通过以下代码使用 NumPy 数组的“shape”属性:
x_train.shape你会得到一个 (60000, 28, 28) 维度的数组。您可能已经猜到,60000 表示训练数据集中的图像数量,(28, 28) 表示图像的大小:28 x 28 像素。
图像 reshape 和归一化
为了能够在 Keras API 中使用数据集,我们需要 4-dims NumPy 数组。然而,正如我们在上面看到的,我们的数组是 3-dims。此外,我们必须对我们的数据进行归一化处理,因为它在神经网络模型中始终是必需的(此处不再详细阐述原因)。我们可以通过将每个像素值除以 255(最大值减去最小值)来实现这一点。这可以通过以下代码完成:
# Reshaping the array to 4-dims so that it can work with the Keras API
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
# Making sure that the values are float so that we can get decimal points after division
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Normalizing the RGB codes by dividing it to the max RGB value.
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print('Number of images in x_train', x_train.shape[0])
print('Number of images in x_test', x_test.shape[0])构建卷积神经网络
我们将使用在后端使用 TensorFlow 或 Theano 的高级 Keras API 来构建我们的模型。我想提一下,有几个高级 TensorFlow API,例如 Layers、Keras 和 Estimators,可以帮助我们创建更高级的神经网络。但是,这可能会导致混淆,因为它们的实现结构各不相同。因此,如果你看到同一个神经网络具有完全不同的代码,尽管它们都使用 TensorFlow。我将使用最直接的 API,即 Keras。因此,我将从 Keras 导入顺序模型并添加 Conv2D、MaxPooling、Flatten、Dropout 和 Dense 层。我已经谈到了 Conv2D、Maxpooling 和 Dense 层。此外,Dropout 层通过在训练时忽略一些神经元来对抗过拟合,而 Flatten 层在构建完全连接的层之前将二维数组扁平化为一维数组。
# Importing the required Keras modules containing model and layers
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D
# Creating a Sequential Model and adding the layers
model = Sequential()
model.add(Conv2D(28, kernel_size=(3,3), input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # Flattening the 2D arrays for fully connected layers
model.add(Dense(128, activation=tf.nn.relu))
model.add(Dropout(0.2))
model.add(Dense(10,activation=tf.nn.softmax))我们可以在第一个 Dense 层尝试任何值;然而,最终的全连接层必须有 10 个神经元,因为我们有 10 个数字类别(0、1、2、...、9)。您可以随时修改 kernel 的大小、池化大小、激活函数、dropout的比例和第一个全连接层中的神经元数量以获得更好的结果。
编译和训练模型
使用上面的代码,我们创建了一个随机初始化的 CNN。现在是时候使用给定的损失函数基于特定指标设置一个优化器。然后,我们可以使用我们的训练数据来训练模型。我们将使用以下代码来完成这些任务:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x=x_train,y=y_train, epochs=10)您可以试验不同的优化器、损失函数、超参数和 epoch。但是,我可以说 adam 优化器通常优于其他优化器(经验之谈)。我不确定您是否真的可以更改多分类的损失函数。epoch 可能看起来有点小,但是,您将在测试集达到 98-99% 准确率。由于 MNIST 数据集不需要大量的计算能力,您也可以轻松地使用 epoch 进行试验。
评估模型
最后,您可以使用下面一行代码对训练的模型进行评估:
model.evaluate(x_test, y_test)对于这么一个简单的模型训练 10 个 epoch,结果非常好。

评估显示在测试集上的准确率为 98.5%
我们用这样一个模型实现了 98.5% 的准确率。坦率地说,在许多图像分类案例中(例如对于自动驾驶汽车),我们甚至不能容忍 0.1% 的错误,因为打个比方,它会在 1000 个案例中导致 1 个事故。然而,对于我们的第一个模型,我想说结果还是相当不错的。我们还可以使用以下代码对单张图像进行预测:
image_index = 4444
plt.imshow(x_test[image_index].reshape(28, 28),cmap='Greys')
pred = model.predict(x_test[image_index].reshape(1, 28, 28, 1))
print(pred.argmax())我们的模型将图像分类为“9”,以下是图像的视觉效果:
我们的模型正确地将此图像分类为 9
虽然它写的并不是很规整,但我们的模型能够将其分类为 9。
尾记
您已经成功构建了一个卷积神经网络来使用 Tensorflow 的 Keras API 对手写数字进行分类,并且已经达到了 98% 以上的准确率,现在你甚至可以保存这个模型并创建一个数字分类器应用程序!如果您对保存模型感到好奇,可以直接访问 Keras 文档。毕竟,要能够有效地使用 API,必须学会如何阅读和使用文档。
· END ·
HAPPY LIFE
















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









