







Recurrent Neural Network
拓展阅读
循环神经网络(RNN)知识入门 - 知乎 (zhihu.com)
循环神经网络(Recurrent Neural Network,RNN)通过使用带自反馈的神经元,能够处理任意长度的时序数据。
给定一个输入序列 x 1 : T = ( x 1 , x 2 , ⋯ , x t , ⋯ , x T ) x_{1:T} = (x_1,x_2,\cdots,x_t,\cdots,x_T) x1:T=(x1,x2,⋯,xt,⋯,xT),循环神经网络通过下面公式更新带反馈边的隐藏层的活性值 h t h_t ht:
h t = f ( h t − 1 , x t ) h_t = f(h_{t-1},x_t) ht=f(ht−1,xt)
该公式可以看成一个动力系统,因此,隐藏层的活性值 h t h_t ht在很多文献上也称为状态或者隐状态。
其中 h 0 = 0 h_0 = 0 h0=0, f ( ⋅ ) f(\cdot) f(⋅)为一个非线性函数,可以是一个前馈网络.
下图给出了循环神经网络的示例,其中“延时器” 为一个虚拟单元,记录神经元的最近一次(或几次)活性值。
循环神经网络的结构由输入层、隐藏层和输出层组成。
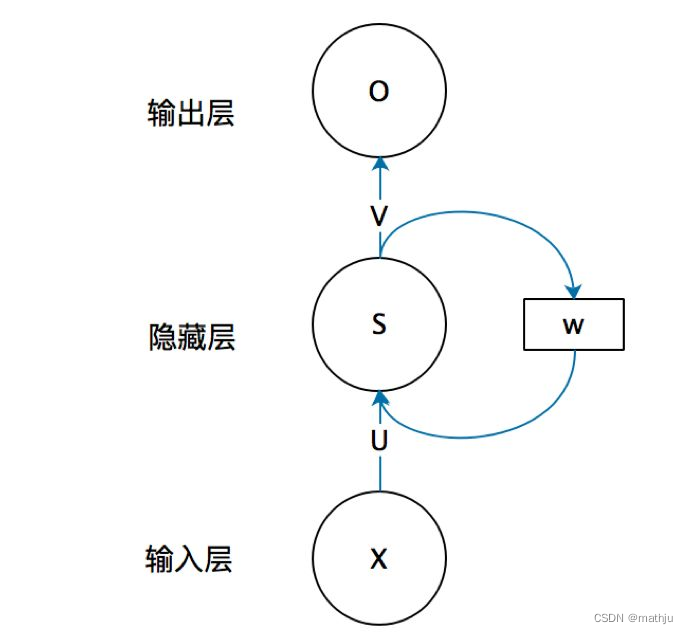
s s s是输入向量, o o o是输出向量, s s s表示隐藏层的值; U U U是输入层到隐藏层的权重矩阵, V V V是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值 s s s不仅仅取决于当前这次的输入 x x x,还取决于上一次隐藏层的值 s s s。权重矩阵 W W W就是隐藏层上一次的值作为这一次的输入的权重。
将上图的基本RNN结构在时间维度展开
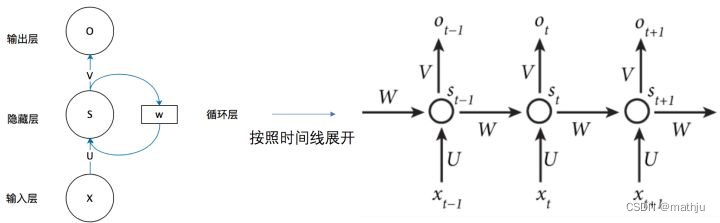
这个网络在 t t t时刻接收到输入 x t x_{t} xt之后,隐藏层的值是 s t s_t st,输出值是 o t o_t ot。关键一点是, s t s_t st的值不仅仅取决于 x t x_t xt,还取决于 s t − 1 s_{t-1} st−1。
假设:
- f f f是隐藏层激活函数,通常是非线性的,如tanh函数或ReLU函数;
- g g g是输出层激活函数,可以是softmax函数
s t = f ( U x t + W s t − 1 + b 1 ) o t = g ( V s t + b 2 ) \begin{align} s_t &= f(Ux_t+Ws_{t-1}+b_1)\\ o_t &=g(Vs_t+b_2) \end{align} stot=f(Uxt+Wst−1+b1)=g(Vst+b2)
通过两个公式的循环迭代,有以下推导:
o t = g ( V ⋅ s t + b 2 ) = g ( V ⋅ f ( U x t + W s t − 1 + b 1 ) + b 2 ) = g ( V ⋅ f ( U x t + W ⋅ f ( U x t − 1 + W s t − 2 + b 1 ) + b 1 ) + b 2 ) = g ( V ⋅ f ( U x t + W ⋅ f ( U x t − 1 + W s t − 2 + ⋯ ) + b 1 ) + b 2 ) \begin{align} o_t &= g(V\cdot s_t + b_2)\\ &= g(V\cdot f(Ux_t+Ws_{t-1}+b_1) + b_2)\\ &= g(V\cdot f(Ux_t + W\cdot f(Ux_{t-1}+Ws_{t-2}+b_1)+b_1)+b_2)\\ &=g(V\cdot f(Ux_t + W\cdot f(Ux_{t-1}+Ws_{t-2}+\cdots)+b_1)+b_2) \end{align} ot=g(V⋅st+b2)=g(V⋅f(Uxt+Wst−1+b1)+b2)=g(V⋅f(Uxt+W⋅f(Uxt−1+Wst−2+b1)+b1)+b2)=g(V⋅f(Uxt+W⋅f(Uxt−1+Wst−2+⋯)+b1)+b2)
上面可以看出,循环神经网络的输出值 o t o_t ot,是受前面历次输入值$x_t,x_{t-1},x_{t-2},\cdots $影响的,这就是为什么循环神经网络可以往前看任意多个输入值的原因。
梯度爆炸与梯度消失问题
RNN并不能很好的处理较长的序列,RNN在训练中很容易发生梯度爆炸和梯度消失,这导致梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。
通常来说,梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。
拓展阅读
梯度爆炸与梯度消失的数学解析
https://www.cnblogs.com/zf-blog/p/12793019.html
也来谈谈RNN的梯度消失/爆炸问题 - 科学空间|Scientific Spaces
Long Short Term Memory
为什么需要LSTM
为了改善循环神经网络的长程依赖问题,一种非常好的解决方案是加入门控机制来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息。这一类网络可以称为基于门控的循环神经网络(Gated RNN)

LSTM结构
输入输出
输入
向量 x t x_t xt,上一时刻LSTM输出隐藏向量 h t − 1 h_{t-1} ht−1,上一时刻记忆单元 c t − 1 c_{t-1} ct−1
输出
当前LSTM输出隐藏向量 h t h_{t} ht,当前时刻的记忆单元状态向量
LSTM状态h与状态c
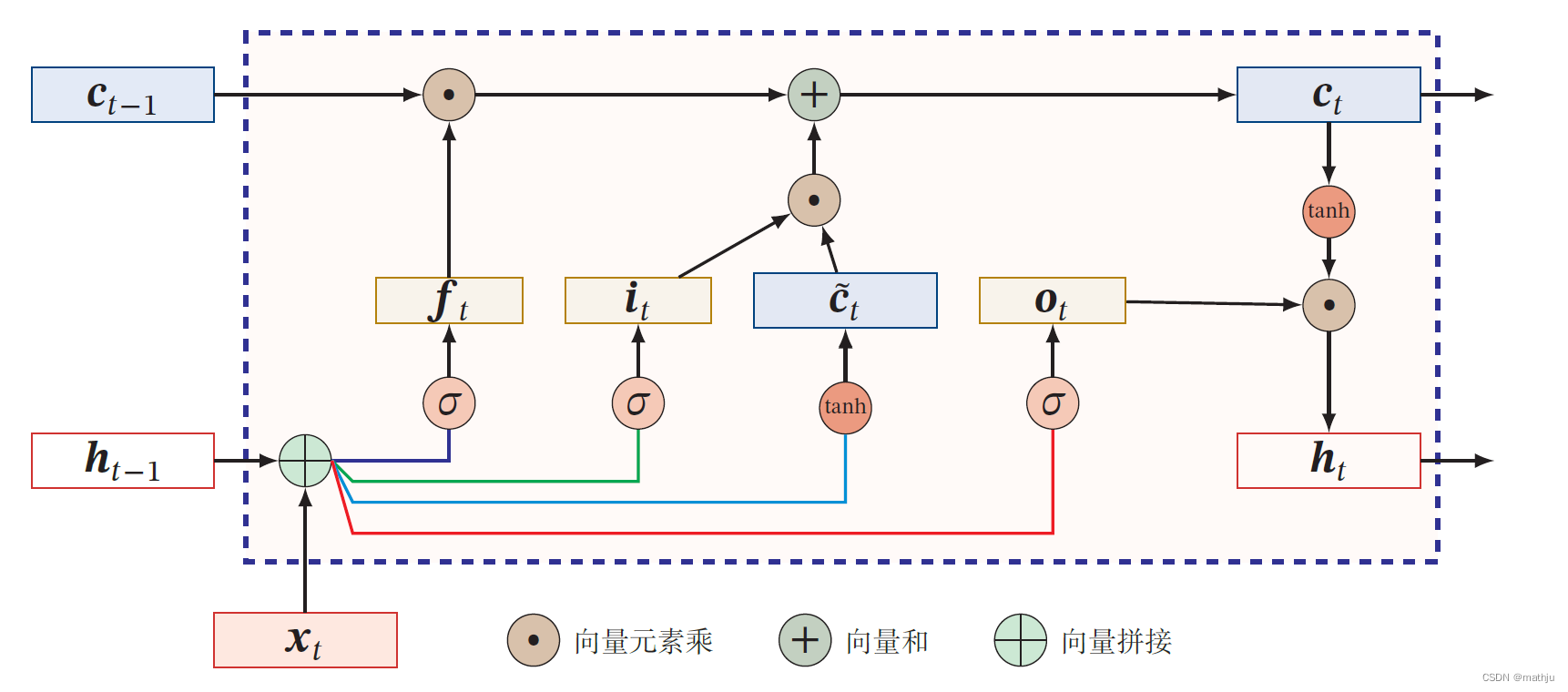
LSTM 网络引入一个新的内部状态(internal state) c t ∈ R D c_t\in \mathbb{R}^{D} ct∈RD专门进行线性的循环信息传递,同时(非线性地)输出信息给隐藏层的外部状态 h t ∈ R D h_t \in \mathbb{R}^D ht∈RD.内部状态 c t c_t ct通过下面公式计算
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t h t = o t ⊙ tanh ( c t ) \begin{align} c_t &= f_t\odot c_{t-1}+i_{t}\odot\tilde{c}_t\\ h_t &= o_t \odot \tanh(c_t) \end{align} ctht=ft⊙ct−1+it⊙c~t=ot⊙tanh(ct)
其中 f t ∈ [ 0 , 1 ] D f_t \in [0,1]^D ft∈[0,1]D、 i t ∈ [ 0 , 1 ] D i_t \in[0,1]^D it∈[0,1]D和 o t ∈ [ 0 , 1 ] D o_t \in[0,1]^D ot∈[0,1]D为三个门(gate)来控制信息传递的路径; ⊙ \odot ⊙为向量元素乘积; c t − 1 c_{t-1} ct−1为上一时刻的记忆单元; c ~ t ∈ R D \tilde{c}_t\in \mathbb{R}^{D} c~t∈RD 是通过非线性函数得到的候选状态:
c ~ t = tanh ( W c x t + U c h t − 1 + b c ) \tilde{c}_t = \tanh(W_cx_t+U_ch_{t-1}+b_c) c~t=tanh(Wcxt+Ucht−1+bc)
门控机制
在数字电路中,门(gate)为一个二值变量{0, 1},0 代表关闭状态,不许任何信息通过;1 代表开放状态,允许所有信息通过.
LSTM 网络引入门控机制(Gating Mechanism)来控制信息传递的路径,三个“门”分别为输入门 i t i_t it、遗忘门 f t f_t ft和输出门 o t o_t ot.这三个门的作用为
- 遗忘门 f t f_t ft控制上一个时刻的内部状态$c_{t-1} $需要遗忘多少信息.
- 输入门 i t i_t it控制当前时刻的候选状态 c t c_t ct有多少信息需要保存.
- 输出门 o t o_t ot控制当前时刻的内部状态 c t c_t ct有多少信息需要输出给外部状态 h t h_t ht.
LSTM 网络中的“门”是一种“软”门,取值在$(0, 1) $之间,表示以一定的比例允许信息通过.三个门的计算方式为
i t = σ ( W i x t + U i h t − 1 + b i ) f t = σ ( W f x t + U f h t − 1 + b f ) o t = σ ( W o x t + U o h t − 1 + b o ) \begin{align} i_t &= \sigma(W_ix_t + U_ih_{t-1} + b_i)\\ f_t &= \sigma(W_fx_t+U_fh_{t-1}+b_f)\\ o_t &= \sigma(W_ox_t +U_oh_{t-1}+b_o) \end{align} itftot=σ(Wixt+Uiht−1+bi)=σ(Wfxt+Ufht−1+bf)=σ(Woxt+Uoht−1+bo)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅)为Logistic 函数,其输出区间为 ( 0 , 1 ) (0, 1) (0,1), x t x_t xt为当前时刻的输入,$h_{t-1} $为上一时刻的外部状态
计算过程
-
首先利用上一时刻的外部状态 h t − 1 h_{t-1} ht−1和当前时刻的输入 x t x_t xt,计算出三个门,以及候选状态 c ~ t \tilde{c}_t c~t;
-
结合遗忘门 f t f_t ft和输入门 i t i_t it来更新记忆单元 c t c_t ct;
-
结合输出门 o t o_t ot,将内部状态的信息传递给外部状态 h t h_t ht.
Gated Recurrent Unit
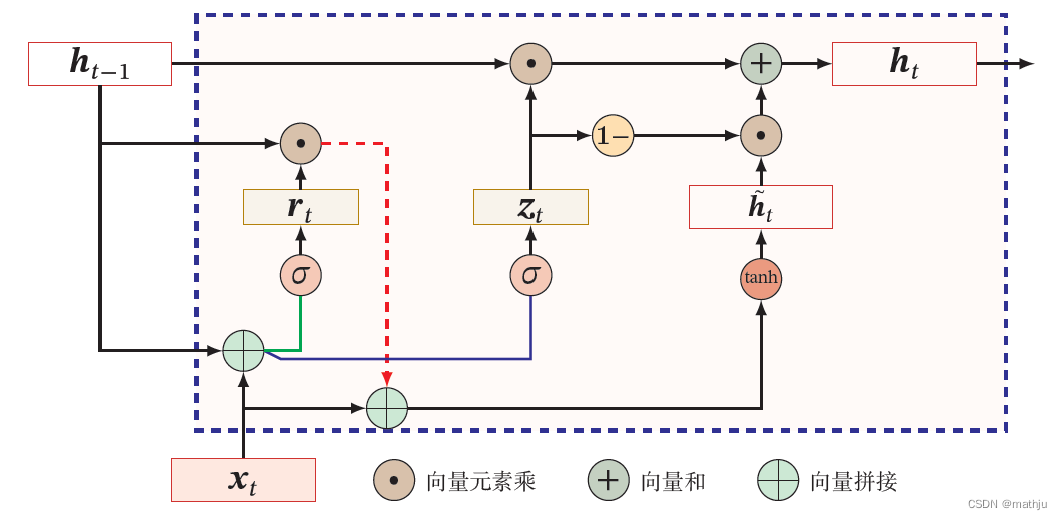
门控循环单元(Gated Recurrent Unit,GRU)网络是一种比LSTM 网络更加简单的循环神经网络。
相对于 LSTM 使用隐藏状态和记忆单元两条线,GRU只使用隐藏状态。
输入输出
输入
向量 x t x_t xt,上一时刻GRU输出隐藏向量 h t − 1 h_{t-1} ht−1。
输出
当前LSTM输出隐藏向量 h t h_{t} ht
状态h更新
GRU 网络的状态更新方式为
h t = z t ⊙ h t − 1 + ( 1 − z t ) ⊙ h ~ t h ~ t = tanh ( W h x t + U h ( r t ⊙ h t − 1 ) + b h ) \begin{align} h_t &= z_t \odot h_{t-1} + (1-z_t)\odot \tilde{h}_t\\ \tilde{h}_t &= \tanh(W_hx_t + U_h (r_t \odot h_{t-1})+b_h) \end{align} hth~t=zt⊙ht−1+(1−zt)⊙h~t=tanh(Whxt+Uh(rt⊙ht−1)+bh)
h ~ t \tilde{h}_t h~t表示当前时刻的候选状态。
门控机制
在LSTM 网络中,输入门和遗忘门是互补关系,具有一定的冗余性.GRU 网络直接使用一个门来控制输入和遗忘之间的平衡,称为更新门 z t ∈ [ 0 , 1 ] D z_t \in [0,1]^D zt∈[0,1]D(update),它用来控制是否更新隐藏状态
z t = σ ( W z x t + U z h t − 1 + b z ) z_t = \sigma(W_zx_t + U_z h_{t-1} + b_z) zt=σ(Wzxt+Uzht−1+bz)
重置门 r t ∈ [ 0 , 1 ] D r_t \in [0,1]^D rt∈[0,1]D决定在多大程度上“忽略”过去的隐藏状态。
r t = σ ( W r x t + U r h t − 1 + b r ) r_t = \sigma(W_rx_t+U_rh_{t-1}+b_r) rt=σ(Wrxt+Urht−1+br)
用来控制候选状态 h ~ t \tilde{h}_t h~t的计算是否依赖上一时刻的状态 h t − 1 h_{t-1} ht−1。
面试题
为什么需要RNN
无论是 全连接网络 还是 卷积神经网络 他们的前提假设都是 元素间相互独立,也就是输入和输出的一一对应,也就是一个输入得到一个输出。不同的输入之间是没有联系的。
然而,在 序列数据(自然语言处理任务、时间序列任务)中,对于每一个输出,他不仅和他所对应的输入相关,还与前面其他词 和 词间的顺序相关。
这个时候,全连接网络 还是 卷积神经网络 将不能很好解决该问题。
RNN 之所以被称为"循环",是因为它对序列中的每个元素执行相同的任务,输出取决于先前的计算。考虑RNN的另一种方式是它们有一个“记忆”,它可以捕获到目前为止计算的信息。
CNN和RNN的区别
相同点
- 传统神经网络的扩展。
- 前向计算产生结果,反向计算模型更新。
- 每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。
不同点
- CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
- RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出
RNN和FNN区别
- RNNs引入了定向循环,能够处理输入之间前后关联问题。
- RNNs可以记忆之前步骤的训练信息。
RNN训练和传统ANN训练异同点
相同点
- RNNs与传统ANN都使用BP误差反向传播算法。
不同点
- RNNs网络参数W,U,V是共享的,而传统神经网络各层参数间没有直接联系。
- 对于RNNs,在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。
为什么RNN训练的时候Loss波动很大
由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏。为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
RNN的优缺点
优点
- 传统网络无法结合上下文去训练模型,导致对于序列特性数据场景的处理效果不佳,而RNN结构决定了其具有了短期记忆性,每一时刻隐藏层信息不仅由该时刻的输入层决定,还可以由上一时刻的隐藏层决定,做到挖掘数据张量的时序信息以及语义信息。
缺点
- 随着网络层数增加,RNN在长序列场景处理时会出现梯度消失或梯度爆炸的弊端
LSTM的优缺点
优点
- LSTM通过引入包含了遗忘门、输入门、输出门的cell状态的结构改善了RNN中存在的长期依赖问题,并且其表现通常比时间递归神经网络和隐马尔科夫模型更好,而LSTM本身也可以作为复杂的非线性单元构造更大型深度网络。
缺点
- 梯度问题在LSTM中得到了一定程度的优化解决,但是并没有彻底搞定,在处理N量级的序列有一定效果,但是处理10N或者更长的序列依然会暴露,另外,每一个LSTM的单元节点都意味着有4个全连接层,如果时间序列跨度较大,并且网络较深,会出现计算量大和耗时偏多的问题。
有哪些解决RNN梯度消失和梯度爆炸的方法
- 门控结构
- 选择relu激活函数,替代sigmoid函数。
- 梯度剪切
- 合理的初始化权重值















 5644
5644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









