




 本文深入探讨了说话人识别技术,重点在于GMM模型的应用。通过分析TIMIT语料库,研究了语音信号预处理和MFCC特征提取。利用MATLAB实现了一个基于GMM的说话人识别系统,探讨了GMM模型阶数和训练样本时长对系统性能的影响。此外,还展示了部分代码并提供了实验结果。
本文深入探讨了说话人识别技术,重点在于GMM模型的应用。通过分析TIMIT语料库,研究了语音信号预处理和MFCC特征提取。利用MATLAB实现了一个基于GMM的说话人识别系统,探讨了GMM模型阶数和训练样本时长对系统性能的影响。此外,还展示了部分代码并提供了实验结果。
1 简介
目前,针对说话人识别而提出的新的识别技术层出不穷,如结合 GMM-UBM 结构与支持向量机(SupportVectorMachine,SVM)的技术、基于得分规整技术的 HNORM、ZNORM 和 TNORM 技术、潜伏因子分析(LatentFactorAnal⁃ysis,LFA)技术、应用于说话人识别的大词汇表连续语音识别(LargeVocabularyContinuousSpeechRecognition,LVC⁃SR)技术等。然而,如今最出色的说话人识别系统依然是基于 GMM 模型,尤其是基于 UBM-MAP 结构的系统。本文基于 TIMIT 语料库分析研究说话人语音信号预处理,以及说话人语音特征提取原理与方法,并利用 MATLAB进行美尔频率倒谱系数(MelFrequencyCepstrumCoeffi⁃cient,MFCC)提取。在此基础上详细研究了 GMM 模型基本原理,以及 EM 算法和 K-均值聚类算法,最后使用MATLAB 实现了基于 GMM 模型的说话人识别系统,完成了GMM 模型参数训练与识别过程。为分析该系统性能,本文通过实验分析了不同 GMM 模型阶数与不同训练语音样本时长对系统识别性能的影响。








2 部分代码
function graph_gmm(X,mi,sig,c,coefs,ft)%% graph_gmm(X,mi,sig,c,<coefs,ft>)%% plots the distribution of coefficientsDEBUG=0;PRINT=0;[L,T]=size(X);if (nargin<5), coefs=1:L; endif (nargin<6), ft=0; endLL=length(coefs);li=fix(sqrt(LL));co=ceil(LL/li);figure;clf;for ll=1:LLl=coefs(ll);xm=min(X(l,:));xM=max(X(l,:));x=(-ft*(xM-xm)+xm):((ft+1)*(xM-xm)./100):(xM+ft*(xM-xm));subplot(li,co,ll);histn(X(l,:),300);hold on;if DEBUG size(x),end[laux,lmulti]=lmultigauss(x,mi(l,:),sig(l,:),c);aux=exp(laux);multi=exp(lmulti);if DEBUG size(x),size(multi'),pause,endhp=plot(x,multi','r','Linewidth',3);%xlim([ -xM xM ]);ha=get(gca,'Children');%it seem that the bars are children number 4set(ha(2),'FaceColor',[ 0.8 0.8 0.8 ]);set(ha(2),'EdgeColor',[ 0.8 0.8 0.8 ]);%*plot(x,aux);end
3 仿真结果
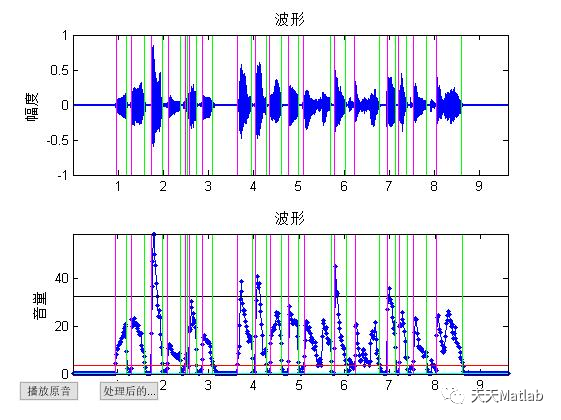
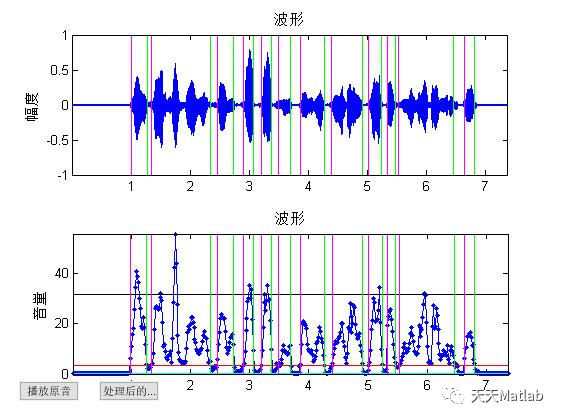
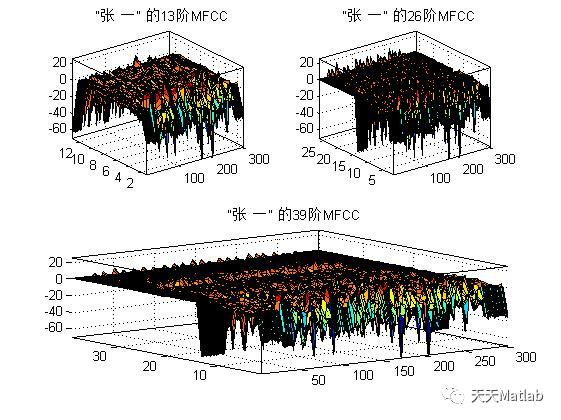
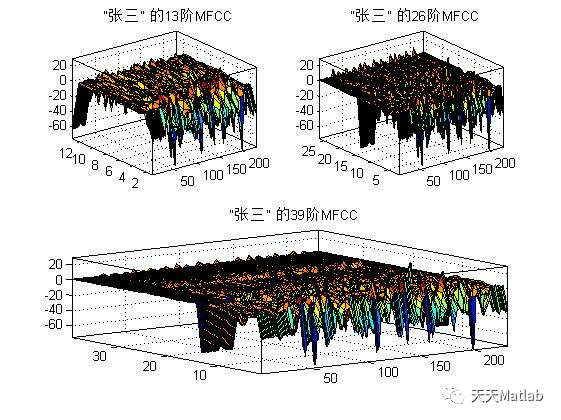
4 参考文献
[1]丁爱明. 基于MFCC和GMM的说话人识别系统研究[D]. 河海大学.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。


















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











