







 文章介绍了英伟达与特拉维夫大学合作开发的ConsiStory图像生成模型,该模型通过主体驱动自注意力(SDSA)和特征注入等技术,无需额外训练即可保证图像内容的一致性和连贯性,尤其在处理多主体和连环画生成时表现出色,有望推动图像生成技术发展。
文章介绍了英伟达与特拉维夫大学合作开发的ConsiStory图像生成模型,该模型通过主体驱动自注意力(SDSA)和特征注入等技术,无需额外训练即可保证图像内容的一致性和连贯性,尤其在处理多主体和连环画生成时表现出色,有望推动图像生成技术发展。
简介
当前的图像生成技术大多数采用随机采样,这导致每次生成的图像都有所不同,特别是在生成连续图像时难以保持一致性。
举例来说,尝试用AI生成一组图像连环画时,即使使用相似的提示词,也难以达到理想效果。
尽管DALL·E 3和Midjourney在提高图像生成连贯性方面取得了一些进展,但这些产品都是闭源的,限制了它们的广泛应用。
因此,英伟达和特拉维夫大学的研究团队合作开发了一种创新的图像生成模型——ConsiStory。这个模型无需训练即可实现图像内容的一致性和连贯性,并将很快向公众开放源代码。

传统的图像生成模型在保持内容一致性方面存在两个主要不足:
首先,它们缺乏对图像中共同主体的识别和定位能力,没有集成对象检测或分割功能,因此难以自动识别不同图像中的相同元素。
其次,即使能够识别出主体,也存在在保持不同图像中主体的视觉一致性上的困难。这意味着即使识别出主体,也很难确保各个独立生成步骤中的主体细节高度一致。
目前,解决这些问题的主流方法主要基于个性化训练和编码器优化。但这些方法都需要额外的训练过程,例如对特定主体微调模型参数,或使用目标图像训练编码器作为条件输入。
consistory-video
然而,这些优化方法存在训练周期长、难以适应多主体场景,以及容易导致与原始模型分布的偏离等问题。
ConsiStory采用了全新的策略,通过在模型内部表示间共享和调整,实现了无需训练或额外调优即可达到主体一致性的目的。
值得一提的是,ConsiStory还能作为插件辅助其他生成模型,提升生成图像的一致性和连贯性。
算法特点
主体驱动自注意力(SDSA)
主体驱动自注意力(SDSA)是ConsiStory的核心模块之一。它通过扩展生成模型中的自注意力机制,使得在生成的图像批次中能够共享与主体相关的视觉信息,从而确保不同图像中主体的外观保持一致。
SDSA的关键在于扩大了自注意力层,使得一个图像中的“提示词”不仅可以关注自身图像的输出结果,还可以关注批次中其他图像的主体区域的输出结果。
这样一来,主体的视觉特征就可以在整个批次中共享,不同图像中的主体能够相互“对齐”,从而实现主体的一致性。
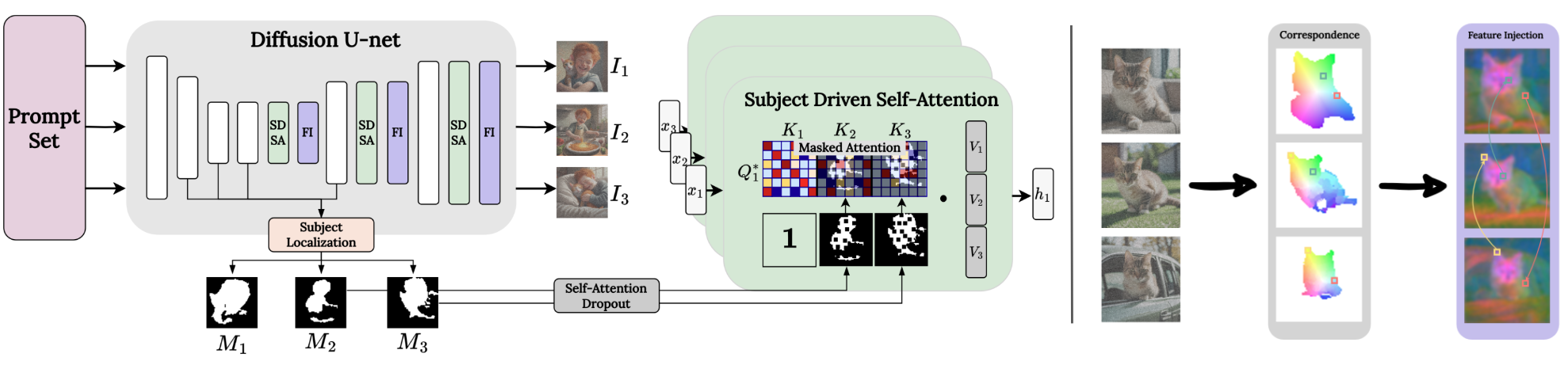
为了避免背景信息的相互干扰,SDSA采用了主体分割蒙版技术,这限制了每个图像只关注其他图像的主体区域。
主体蒙版是通过模型自身的交叉注意力特征自动提取的,这意味着SDSA能够自动识别和提取图像中的主体部分,从而确保在生成图像时只关注主体区域,而背景信息则被有效地剔除或降低了其影响。

特征注入
为了进一步增强主体在不同图像之间的细节一致性,ConsiStory采用了“特征注入”机制。这一机制通过在图像生成过程中共享自注意力输出特征,加强了图像间相似区域(如纹理、颜色等)的一致性。
特征共享同样采用主体蒙版进行限定,同时设置了相似度阈值,以确保只在足够相似的区域之间执行特征共享。这样一来,只有在主体之间具有足够相似性的区域才会执行特征共享,从而确保了主体细节在不同图像之间的一致性,并避免了背景等不相关部分的影响。
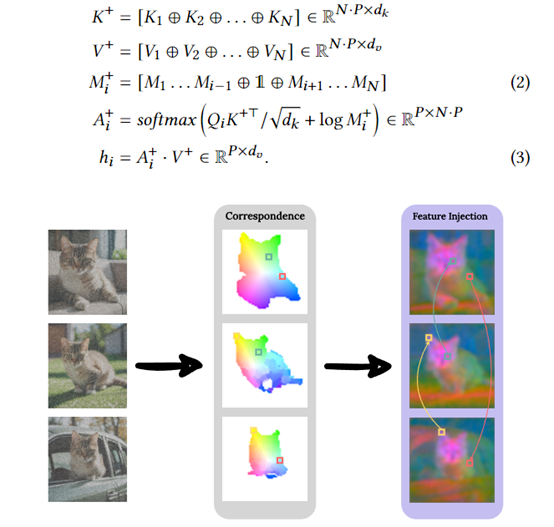
锚图像和可重用主体
ConsiStory还引入了“锚图像”概念,作为生成过程中主题信息的参考,以确保生成图像在主题上的一致性。
锚图像既可以是用户提供的,也可以是从其他来源选取的相关图像。模型会尽可能地参考锚图像的特征和结构,生成风格一致的图像序列。通过共享预训练模型的内部激活,我们可以实现特征表示的高度一致性,这是一种高效的可重用主体使用方法。在图像生成的过程中,该模型依赖于预训练模型的内部特征表示来确保生成图像的质量,从而避免了对外部图像数据进行额外的调整。

通过ConsiStory,不仅能够在无需额外训练的前提下实现图像生成的高度连贯性,还能显著提升生成图像的质量和实用性。随着该模型的开源,预计将会有更多的研究和应用从中受益,为图像生成技术的发展开辟新的道路。这一创新性的方法不仅有助于解决现有技术中存在的连贯性问题,还为图像生成领域带来了更广泛的应用可能性,促进了该领域的进一步研究和探索。
实验
支持多个一致的主题
比如下图,不仅保留了男孩的特征,也保留了球的特征。

跟ControlNet集成
ConsiStory可以跟ControlNet集成,生成不同姿态的一致性的角色。

无需训练的个性化生成
简单理解就是图片转图片,将一张图片中的元素植入到另一张图片中,并保持该元素在新场景中自然融入,比如给左边的红色背包换背景。

变换种子值
每张AI生成的图片都有一个seed值,ConsiStory可以实现通过改变seed值(起始噪音)来变换场景,但主题不改变(如下图每行的猫头鹰)。

支持种族多样性
针对人像,ConsiStory可以保持该人物的种族特征不改变。

比较其他方法
如下图,最上面是ConsiStory方法,底下分别是IP-Adapter、TI、DB-LoRA方法,可以看下角色的一致性和对提示词的遵循程度,至少从官方提供的示例上看,ConsiStory都更胜一筹。


















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











