







1. 基本运动检测
基本运动检测方法的核心在于计算视频帧之间的差异,或者是将某一帧设定为“背景”,然后将其与后续的帧进行比较。这个过程在概念上非常简单:首先保存视频的第一帧作为背景参考,随后将这一帧与新接收到的帧进行逐像素的比较。通过简单的图像相减操作,理论上可以将移动对象从静止背景中分离出来。
然而,这种方法虽然实现起来速度较快,但在实际应用中存在明显的局限性。因为需要将某一帧固定作为背景,而实际情况中背景往往是不断变化的。例如,在汽车检测的场景中,由于汽车和其他物体的移动,以及光照条件的不断变化,这种静态的背景设定很快就会变得不再适用。如果将第一帧设为背景,而其中包含了三辆汽车,那么一秒钟后,这些汽车的位置可能已经发生了变化,原本的背景图像就不再准确。这样一来,算法的准确性就会受到影响,尤其是在那些环境变化迅速的场合。
观察实际的检测图像,可以看到,尽管基本运动检测算法能够捕捉到一些移动对象,但其结果并不精确。在图像的左侧,甚至可以看到一些毫无意义的区域被错误地标记为移动对象。这是因为视频中的背景几乎每秒钟都在变化,而算法中的背景却是固定不变的。

2. 背景减除
背景减除的目的是从视频序列中分离出移动对象。这项技术通过对比每一帧与一个背景模型,来识别出那些与背景有显著差异的区域,这些区域通常就是前景对象。这些前景信息随后可以用对象的检测和跟踪。
2.1 解决背景问题
在背景减除的过程中,背景图像并不是静态不变的。由于光照条件的变化、物体的移动以及场景的动态变化等多种因素的影响,背景是随时间不断变化的。因此,背景减除算法需要能够自适应地对背景模型进行建模和更新,以便在环境发生变化时仍能准确地检测到前景对象。通过这种动态更新的方式,背景减除技术能够有效地解决背景问题。
在OpenCV提供了多种背景减除器,可以检测并排除阴影,从而提高对象检测的准确性。这一点非常重要,因为如果阴影没有被正确处理,它们可能会被错误地识别为独立的移动对象。
OpenCV中的背景减除器主要有以下几种:
-
K-最近邻 (KNN):这是一种基于像素邻域的背景减除方法,它通过计算像素与其K个最近邻像素的差异来进行背景建模和更新。
-
高斯混合 (MOG2):这种方法通过将背景建模为多个高斯分布的混合来实现背景的动态更新。每个像素都有一个对应的高斯混合模型,该模型会根据每一帧的新数据进行调整。
2.2 MOG2背景减除器
混合高斯模型(GMM)作为背景建模的经典算法,在目标检测和跟踪等领域有着广泛的应用。自从提出以来,围绕GMM的改进和应用已经产生了大量研究论文。
OpenCV中的BackgroundSubtractorMOG是GMM算法的一个基本实现。这个版本的算法通过创建一个背景模型来实现背景减除,该模型由多个高斯分布组成,每个高斯分布对应图像中的一个像素。这些高斯分布的参数(均值、方差和权重)会根据视频帧中的像素值动态更新,以便更好地适应场景的变化。这种方法能够有效地适应各种背景变化,如光照变化和动态背景。
BackgroundSubtractorMOG2是GMM算法的一个改进版本,它在BackgroundSubtractorMOG的基础上进行了优化和增强。改进的主要点包括:
阴影检测:BackgroundSubtractorMOG2增加了对阴影的检测能力。通过分析像素的HSV值,算法能够区分出阴影和前景物体,从而避免将阴影错误地识别为前景物体。
算法效率提升:BackgroundSubtractorMOG2在运行时间上进行了优化,通过多线程并行执行,提高了算法的处理速度。这使得BackgroundSubtractorMOG2在实时应用中更加高效。
BackgroundSubtractorMOG2的源代码位于OpenCV的源代码目录中,具体位置为opencv\sources\modules\video\src\bgfg_gaussmix2.cpp。源码中详细实现了GMM的参数更新、背景模型的构建、阴影检测等关键功能。
实现步骤:
-
初始化:在开始处理视频之前,首先初始化K个高斯分布的混合模型,用来模拟场景的背景。每个像素都有一个由高斯分布组成的背景模型,K是预先设定的参数。
-
适应:随着视频的进行,每个像素的背景模型会根据新接收到的帧数据进行更新,调整高斯分布的参数以适应场景的变化。
-
前景检测:对于每个像素,根据其高斯混合模型计算它属于背景的概率。那些概率较低的像素会被判定为前景对象。
-
更新背景:对于那些被判定为背景的像素,更新它们的高斯分布模型,以包含新的观察数据,并继续适应场景的变化。
-
后处理:在得到初步的前景掩码后,通过应用形态学操作(如腐蚀和膨胀)或其他技术来进一步优化掩码,去除噪声,从而得到更准确的前景对象信息。
在实际的代码实现中,通过复制和运行示例代码,可以观察到每一帧处理后的结果。通过背景减除、阈值处理和形态学膨胀等步骤,可以得到清晰的前景对象检测结果。这些技术在视频监控、自动驾驶车辆、人流统计等领域有着广泛的应用。
代码实现
# 导入库
import cv2
import numpy as np
# KNN
KNN_subtractor = cv2.createBackgroundSubtractorKNN(detectShadows = True)
# MOG2
MOG2_subtractor = cv2.createBackgroundSubtractorMOG2(detectShadows = True)
bg_subtractor=MOG2_subtractor
camera = cv2.VideoCapture("resources/run.mp4")
while True:
ret, frame = camera.read()
# 每一帧既用于计算前景掩码,也用于更新背景。
foreground_mask = bg_subtractor.apply(frame)
# 如果大于240像素,则阈值设为255,如果小于则设为0 # 创建二值图像,它只包含白色和黑色像素
ret , treshold = cv2.threshold(foreground_mask.copy(), 120, 255, cv2.THRESH_BINARY)
# 膨胀扩展或加厚图像中的兴趣区域。
dilated = cv2.dilate(treshold, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3,3)), iterations = 2)
# 查找轮廓
contours, hier = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 检查每个轮廓是否超过某个值,如果超过则绘制边界框
for contour in contours:
if cv2.contourArea(contour) > 50:
(x,y,w,h) = cv2.boundingRect(contour)
cv2.rectangle(frame, (x,y), (x+w, y+h), (255,255,0), 2)
cv2.imshow("Subtractor", foreground_mask)
cv2.imshow("threshold", treshold)
cv2.imshow("detection", frame)
if cv2.waitKey(30) & 0xff == 27:
break
camera.release()
cv2.destroyAllWindows()
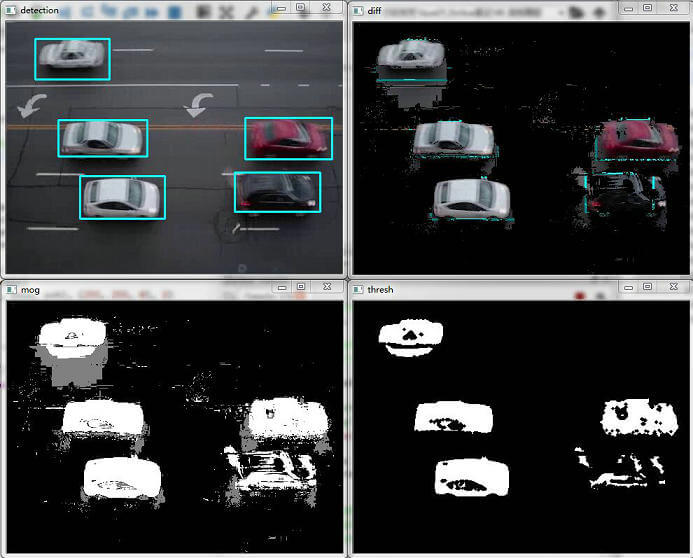

BackgroundSubtractorMOG2作为GMM算法的改进版本,在保持原有优点的基础上,通过增加阴影检测和提高算法效率,使得它在处理复杂场景时更加鲁棒和高效。

















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











