




自动编码器
自动编码器(Autoencoders)是无监督学习领域中一种重要的神经网络架构,它们主要用于数据压缩和特征学习。
-
自动编码器的定义:
自动编码器是一种无监督机器学习算法,它通过反向传播进行训练,目标值被设置为与输入值相等。其核心目标是对输入数据进行压缩,转换成一个更小的表示形式,如果需要原始数据,可以从压缩后的数据中重建。 -
自动编码器的组成:
自动编码器由三个主要部分组成:- 编码器(Encoder):负责将输入数据压缩成低维表示形式,即潜在空间(latent space)表示。
- 潜在空间(Code或Bottleneck):表示压缩后的数据,该数据随后被送入解码器。
- 解码器(Decoder):负责将编码后的表示重建成原始数据维度,重建的数据是对原始输入的一个有损近似。
-
自动编码器的工作流程:
- 数据首先被输入到自动编码器中。
- 编码器将数据编码并压缩成较小的潜在表示。
- 然后,解码器学习如何从这个压缩的表示中重建原始数据。
-
训练目的:
训练自动编码器的目的不单是复制输入数据,而是让网络学习输入数据的本质特征。通过最小化损失函数,网络学习到如何从压缩表示中有效地重建数据。 -
应用场景:
- 图像去噪:自动编码器可以被训练来识别并去除图像中的噪声。
- 数据降维:自动编码器用于降低数据的维度,同时尽可能保留重要信息。
- 特征提取:自动编码器可以提取数据中的关键特征,这些特征可以用于其他机器学习任务。
- 图像上色:将黑白图像转换为彩色图像。
- 水印去除:从图像或视频中去除不需要的对象或水印。
-
为何使用自动编码器:
与主成分分析(PCA)等传统技术相比,自动编码器能够学习非线性转换,可以利用非线性激活函数和多层结构。此外,自动编码器可以使用卷积层来学习图像、视频和序列数据,这比PCA更有效。 -
自动编码器的类型:
- 卷积自动编码器(Convolutional Autoencoders):适用于图像数据,可以用于图像重建、上色等。
- 稀疏自动编码器(Sparse Autoencoders):通过惩罚隐藏层的激活来引入信息瓶颈。
- 深度自动编码器(Deep Autoencoders):由多层编码和解码网络组成,可以学习更复杂的数据表示。
- 合同自动编码器(Contractive Autoencoders):通过惩罚隐藏层激活相对于输入的大幅度变化来帮助网络编码未标记的训练数据。
自动编码器架构
先来看看 自动编码器的架构。 :
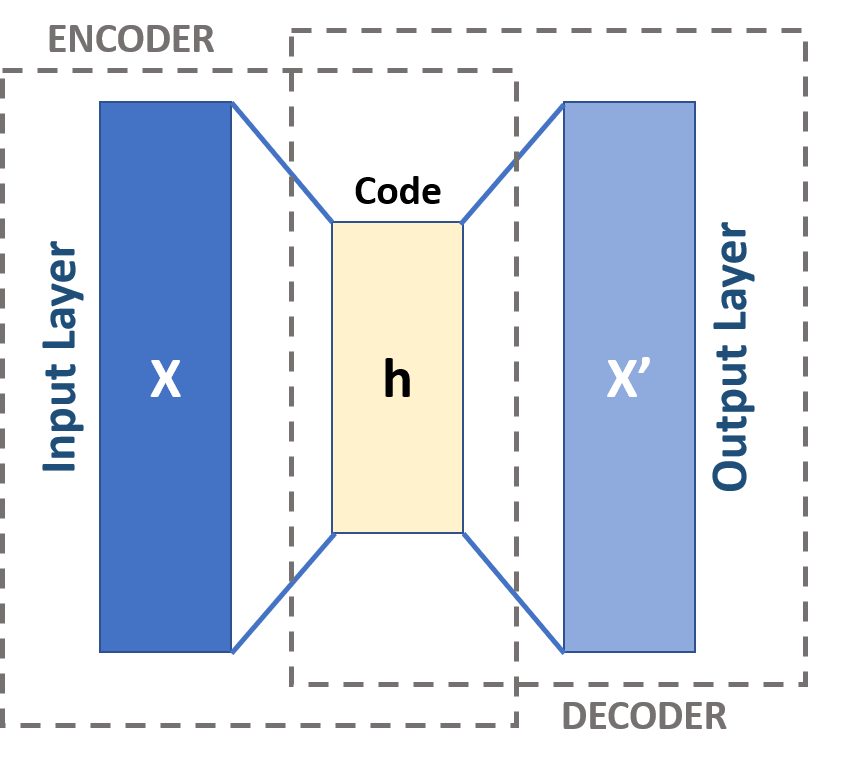
自动编码器的架构可以概括为三个核心组件:编码器、瓶颈(或潜在空间),以及解码器:
-
编码器(Encoder):
编码器是自动编码器的输入部分,通常由前馈、密集连接的网络层组成。它的任务是接收原始输入数据,并通过一系列的变换,将其转换成一个低维的内部表示。这个过程涉及到数据压缩,目的是提取输入数据中的关键特征,并将其编码到一个较小的潜在空间中。 -
瓶颈(Bottleneck):
瓶颈层,也称为潜在表示或潜在变量,是自动编码器中编码过程的结果。这一层捕捉了输入数据的压缩表示,它包含了重建原始数据所必需的最重要信息。瓶颈层的设计至关重要,因为它需要决定哪些数据特征是信息丰富且需要保留的,哪些是可以丢弃的。瓶颈层通过逐元素的激活函数处理网络的权重和偏差,以实现这种压缩和特征选择。 -
解码器(Decoder):
解码器是自动编码器的输出部分,它的任务是将瓶颈层的压缩表示重新转换成原始数据的高维表示。解码器通常由一系列解压缩的层组成,这些层逐步增加数据的维度,直到达到与原始输入数据相同的维度。解码器的目标是从潜在空间表示中重建数据,尽可能地恢复输入数据的原始特征和结构。
自动编码器的训练通常采用反向传播算法,这是一种监督学习技术,用于最小化输入数据和重建数据之间的差异,通常通过损失函数来衡量。损失函数的常见选择包括均方误差(MSE)或二元交叉熵(Binary Cross-Entropy, BCE),具体取决于数据的性质和范围。
自动编码器的属性
自动编码器有多种类型,但它们都具有将它们结合在一起的某些属性。自动编码器自动学习。 它们不需要标签,如果给定足够的数据,很容易让自动编码器在特定类型的输入数据上达到高性能。自动编码器是特定于数据的。 这意味着它们只能压缩与自动编码器已经训练过的数据高度相似的数据。 自动编码器也是有损的,这意味着模型的输出与输入数据相比将会降低。
在设计自动编码器时,机器学习工程师需要注意四个不同的模型超参数:代码大小、层数、每层节点和损失函数。
代码大小决定了有多少节点开始网络的中间部分,节点越少,数据压缩得越多。 在深度自动编码器中,虽然层数可以是工程师认为合适的任何数量,但层中的节点数应该随着编码器的继续而减少。 同时,解码器中的情况正好相反,这意味着随着解码器层接近最后一层,每层的节点数量应该增加。 最后,自动编码器的损失函数通常是二进制交叉熵或均方误差。 二元交叉熵适用于数据输入值在 0 – 1 范围内的情况。
自动编码器类型
如上所述,经典自动编码器架构存在变体。 让我们研究一下不同的自动编码器架构。
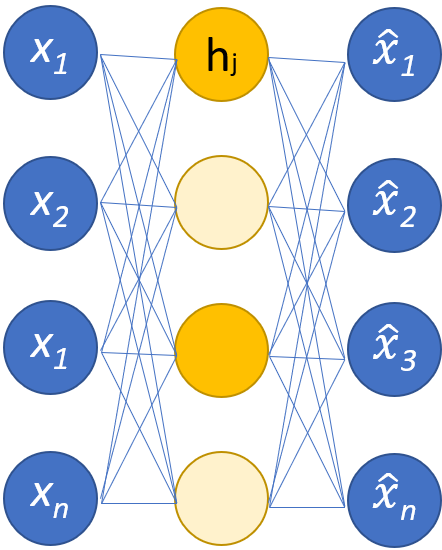
虽然自动编码器通常存在通过减少节点来压缩数据的瓶颈, 稀疏自动编码器s 是典型操作格式的替代方案。 在稀疏网络中,隐藏层保持与编码器和解码器层相同的大小。 相反,给定层内的激活会受到惩罚,对其进行设置,以便损失函数更好地捕获输入数据的统计特征。 换句话说,虽然稀疏自动编码器的隐藏层比传统自动编码器具有更多的单元,但在任何给定时间只有一定比例的隐藏层处于活动状态。 最有影响力的激活函数被保留,其他激活函数被忽略,这种约束有助于网络确定输入数据最显着的特征。
收缩性
收缩自动编码器 旨在对数据中的微小变化具有弹性,从而保持数据的一致表示。 这是通过对损失函数应用惩罚来实现的。 该正则化技术基于输入编码器激活的雅可比矩阵的 Frobenius 范数。 这种正则化技术的效果是,模型被迫构建一种编码,其中相似的输入将具有相似的编码。
卷积
卷积自动编码器 通过将数据分成多个子部分,然后将这些子部分转换为简单信号,将这些信号相加以创建新的数据表示,对输入数据进行编码。 与卷积神经网络类似,卷积自动编码器专门研究图像数据的学习,它使用一个在整个图像上逐节移动的滤波器。 编码层生成的编码可用于重建图像、反映图像或修改图像的几何形状。 一旦网络学习了滤波器,它们就可以用于任何足够相似的输入来提取图像的特征。
去噪

去噪自动编码器 将噪声引入编码中,导致编码成为原始输入数据的损坏版本。 这个损坏的数据版本用于训练模型,但损失函数将输出值与原始输入而不是损坏的输入进行比较。 目标是网络将能够重现图像的原始、未损坏版本。 通过将损坏的数据与原始数据进行比较,网络可以了解数据的哪些特征最重要以及哪些特征不重要/损坏。 换句话说,为了让模型对损坏的图像进行去噪,它必须提取图像数据的重要特征。
变分
变分自动编码器 通过假设数据的潜在变量如何分布来进行操作。 变分自动编码器为训练图像/潜在属性的不同特征生成概率分布。 训练时,编码器为输入图像的不同特征创建潜在分布。
 由于该模型将特征或图像学习为高斯分布而不是离散值,因此它能够用于生成新图像。 对高斯分布进行采样以创建一个向量,该向量被馈送到解码网络,解码网络根据该样本向量渲染图像。 本质上,该模型学习训练图像的共同特征,并为其分配一些发生的概率。 然后,概率分布可用于对图像进行逆向工程,生成与原始训练图像相似的新图像。
由于该模型将特征或图像学习为高斯分布而不是离散值,因此它能够用于生成新图像。 对高斯分布进行采样以创建一个向量,该向量被馈送到解码网络,解码网络根据该样本向量渲染图像。 本质上,该模型学习训练图像的共同特征,并为其分配一些发生的概率。 然后,概率分布可用于对图像进行逆向工程,生成与原始训练图像相似的新图像。
训练网络时,分析编码数据,识别模型输出两个向量,得出图像的平均值和标准差。 根据这些值创建分布。 这是针对不同的潜在状态完成的。 然后,解码器从相应的分布中获取随机样本,并使用它们来重建网络的初始输入。
自动编码器应用
自动编码器可用于广泛 多种应用,但它们通常用于降维、数据去噪、特征提取、图像生成、序列到序列预测和推荐系统等任务。
数据去噪是使用自动编码器从图像中去除颗粒/噪声。 同样,自动编码器可用于修复其他类型的图像损坏,例如模糊图像或图像缺失部分。 降维可以帮助高容量网络学习图像的有用特征,这意味着自动编码器可用于增强其他类型神经网络的训练。 使用自动编码器进行特征提取也是如此,因为自动编码器可用于识别其他训练数据集的特征来训练其他模型。
在图像生成方面,自动编码器可用于生成假人类图像或动画角色,这可用于设计人脸识别系统或自动化动画的某些方面。
序列到序列预测模型可用于确定数据的时间结构,这意味着自动编码器可用于生成序列中的下一个偶数。 因此,可以使用自动编码器来生成视频。 最后,深度自动编码器可用于通过拾取与用户兴趣相关的模式来创建推荐系统,编码器分析用户参与数据,解码器创建适合已建立模式的推荐。



















 8万+
8万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










