







前言
1、算法概述
ER-NeRF是基于NeRF用于生成数字人的方法,可以达到实时生成的效果。具体来说,为了提高动态头部重建的准确性,ER-NeRF引入了一种紧凑且表达丰富的基于NeRF的三平面哈希表示法,通过三个平面哈希编码器剪枝空的空间区域。对于语音音频,ER-NeRF提出了一个区域关注模块,通过注意机制生成区域感知的条件特征。与现有方法不同,它们使用基于MLP的编码器隐式学习跨模态关系不同,注意机制建立了音频特征和空间区域之间的明确连接,以捕获本地动作的先验知识。此外,ER-NeRF引入了一种直接且快速的自适应姿势编码,通过将头部姿势的复杂变换映射到空间坐标,来优化头部和躯干的分离问题。大量实验证明,与先前方法相比,ER-NeRF的方法可以呈现更高保真度和音频嘴唇同步的数字人,细节更加逼真。
2.算法比较
在官方的实验可以看到,与之前的生成的数字人相比,ER-NeRF具有更好的高保真度和音频嘴唇同步的人像谈话视频,具有更真实的细节和更高的效率。
3.讨论群
企鹅:787501969
一、环境安装
注:安装环境的时候,如果不想自己踩坑,最好是按着博客给的配置一模一样的安装,如果你喜欢自己解决各种报错,踩各种莫名其妙的坑,那环境随便装,配置随便改,上面的话当我没说
1.环境配置
官方给的环境配置是Ubuntu 18.04, Pytorch 1.12 和CUDA 11.3,但我在win10下使用这个配置依赖,总是报了一堆莫名的错误,而且win10下在线安装pythorch3d并不容易成功,在安装过程中也报各种各样的错误。
经过几次安装测试,在win10下,最容易装上的配置依赖是: Pytorch 2.0,CUDA11.7(11.8也试过,但在训练的时候,一直卡着不动),cudnn 8.5,要本地安装pytorch3d,所以要安装Visual Studio,版本是2019或者2022都可以。Pytorch如果在官网不好下,这里我上传了一份源码到百度网盘,可以下载使用:链接:https://pan.baidu.com/s/1SLlSoW_YqpeDqQ7JEczVcQ
提取码:rvqf
安装vs要选以下这几个功能:

3.环境安装
#下载源码
git clone https://github.com/Fictionarry/ER-NeRF.git
cd ER-NeRF
#创建虚拟环境
conda create --name vrh python=3.10
activate vrh
#pytorch 要单独对应cuda进行安装,要不然训练时使用不了GPU
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
#安装所需要的依赖
pip install -r requirements.txt
#处理音频时用的
pip install tensorflow
下载pytorch3d源码,如果下载不了,按上面的百度网盘下载:链接:https://pan.baidu.com/s/1xPFo-MQPWzkDMpLHhaloCQ
提取码:1422
git clone https://github.com/facebookresearch/pytorch3d.git
cd pytorch3d
python setup.py install
在安装pytorch3d可能出现错误,可以看文章结尾列的常见错误。
3.项目模型下载
为了避免在运行时下不了模型或者模型下载缓慢,这里我把所需模型我这里都下载好放在网盘上,。链接:链接:https://pan.baidu.com/s/1z83r_2r4_5tsHDbC0ZlWeA
提取码:73bi
下载人脸解析模型79999_iter.pth放到data_utils/face_parsing/这个目录
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth
下载头部姿态估计模型到data_utils/face_tracking/3DMM/
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy
下载01_MorphableModel.mat模型到data_utils/face_trackong/3DMM/目录
https://faces.dmi.unibas.ch/bfm/main.php?nav=1-1-0&id=details
4.运行时所需模型下载
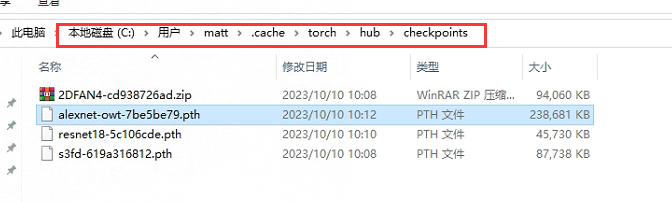
下载这四个模型放到到用户目录xxx.cache\torch\hub\checkpoints下,如果没有这个目录,自己创建出来,如果不先下载,运行再下载的话可能会很慢或者下载不了。
https://download.pytorch.org/models/resnet18-5c106cde.pth
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
https://www.adrianbulat.com/downloads/python-fan/2DFAN4-cd938726ad.zip
https://download.pytorch.org/models/alexnet-owt-7be5be79.pth
语音特征提取模型
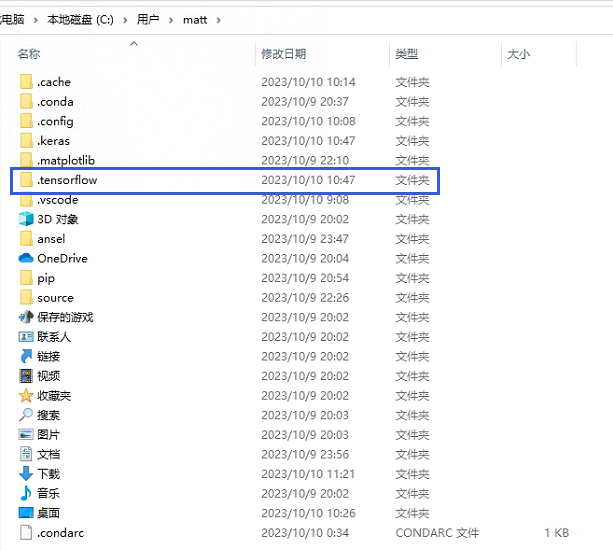
下载deepspeech-0_1_0-b90017e8.pb放到用户xxx.tensorflow\models目录下,第一次运行可能没有这个目录,那就自己创建一个。
二、数据处理
1.数据准备
自己拍摄一段不大于5分钟的视频或者从网上下载不侵权的视频,视频人像单一,面对镜头,背景尽量简单,这是方便等下进行抠人像与分割人脸用的。然后视频编辑软件,只切取一部分上半身和头部的画面。按1比1切取。这里的剪切尺寸不做要求,只是1比1就可以了。
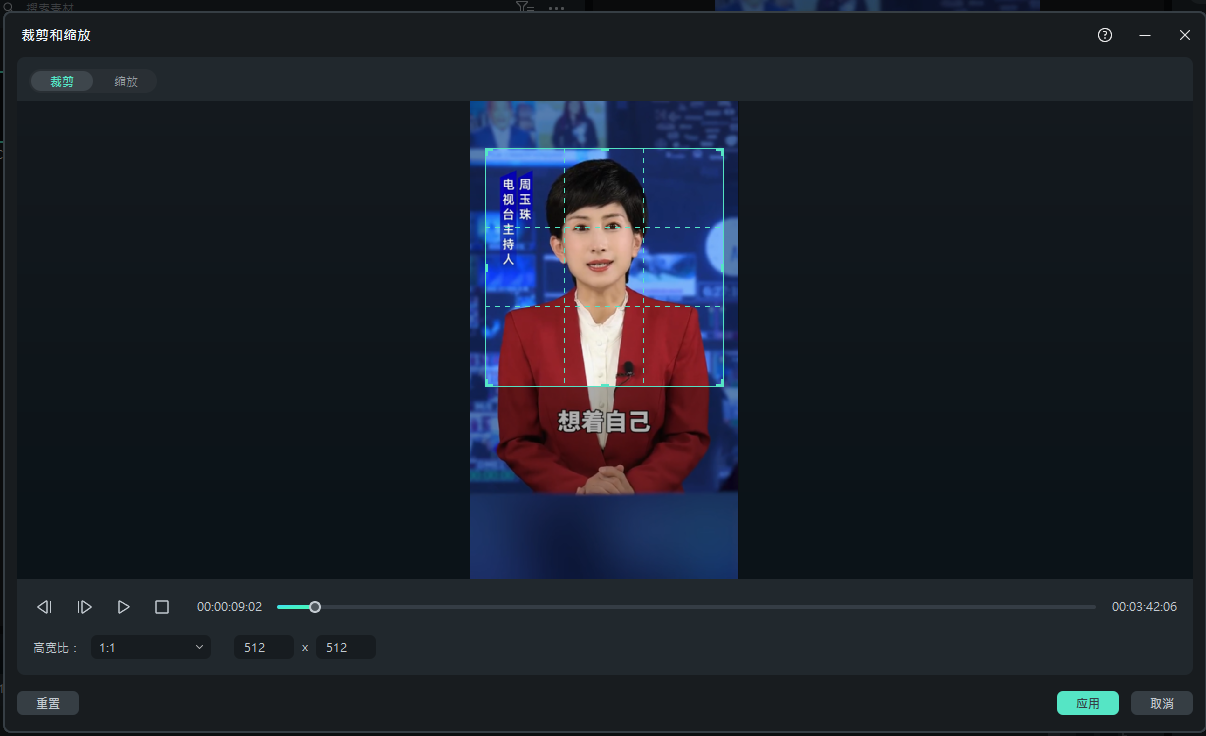
导出的时候,按官方要求的尺寸导出(512*512),但不一定完全按这个尺寸来,就是只要是正方形就可以,帧率是25fps。
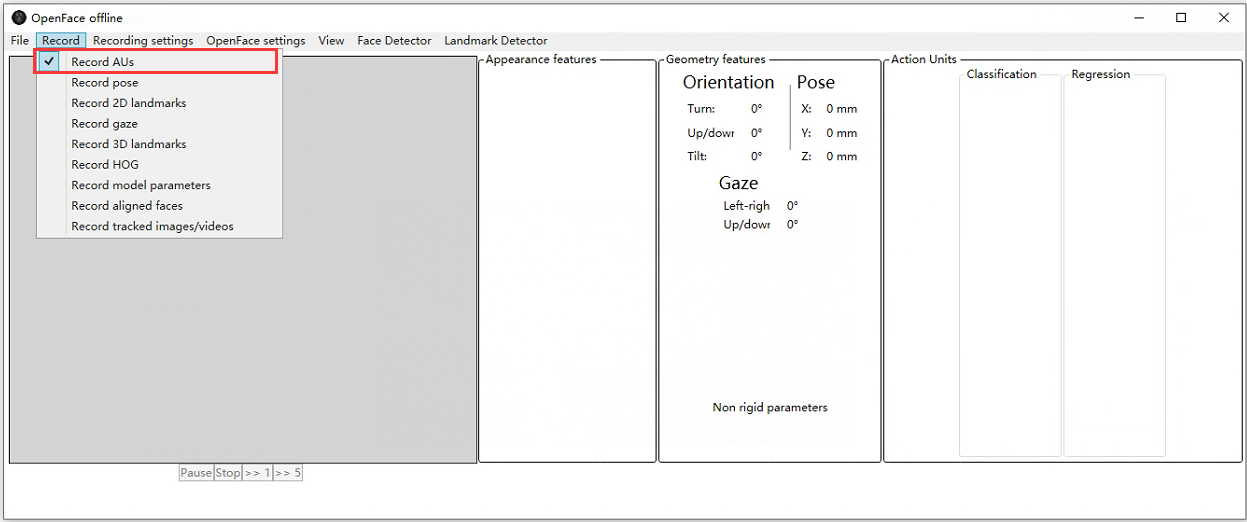
2.获得 AU45眨眼
要获取眨眼数据,要使用OpenFace,可以直接下载OpenFace的可运行文件,然后打开OpenFace目录下的OpenFaceOffline.exe,只选择AUs这个功能就可以。
这里我把OpenFace打好包放网盘上,可以直接下载使用,链接:https://pan.baidu.com/s/12MGt2mFpd6-zmiHL4BG0SQ
提取码:g105
选择要获取眨眼数据的视频:
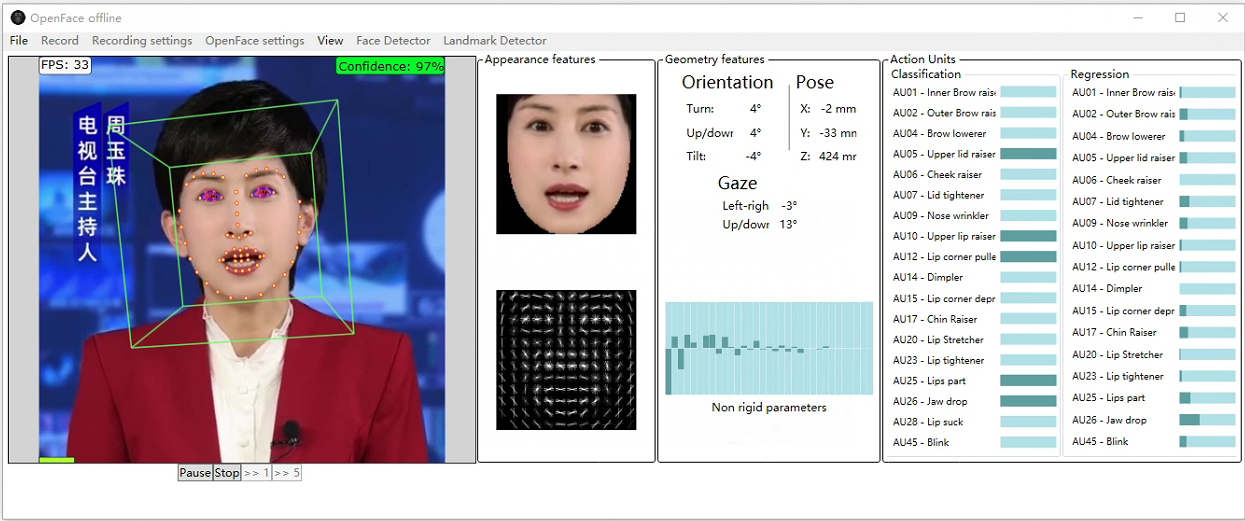
运行完之后,在processed目录下就有与视频名相同的csv文件:
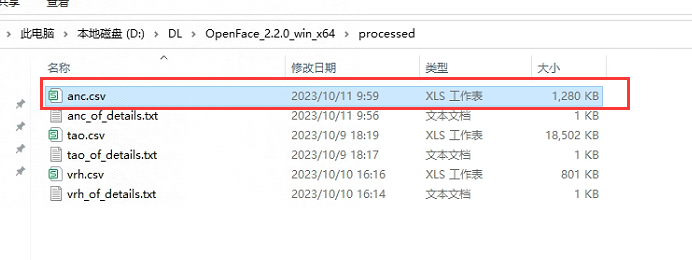
3.数据处理
在ER-NERF/data目录,创建一个与视频名同名的目录:
数据处理要花的时间跟视频长短有关,一般要1个小时以上,有两种处理方式,一种是直接一次运行所有步骤,但处理过程可能存在错误,所以建议使用第二种,按步骤来处理.
1.一次性处理数据
cd data_utils/face_tracking
python convert_BFM.py
#按自己的数据与目录来运行对应的路径
python data_utils/process.py data/anc/anc.mp4
2.分步处理
按步骤处理时,
python data_utils/process.py data/anc/anc.mp4 --task x
--task 1 #分离音频
--task 2 #生成aud_eo.npy
--task 3 #把视频拆分成图像
--task 4 #分割人像
--task 5 #提取背景图像
--task 6 #分割出身体部分
--task 7 #获取人脸landmarks lms文件
--task 8 #获取人脸跟踪数据,这步要训练一个追踪模型,会很慢
--task 9 #保存所有数据
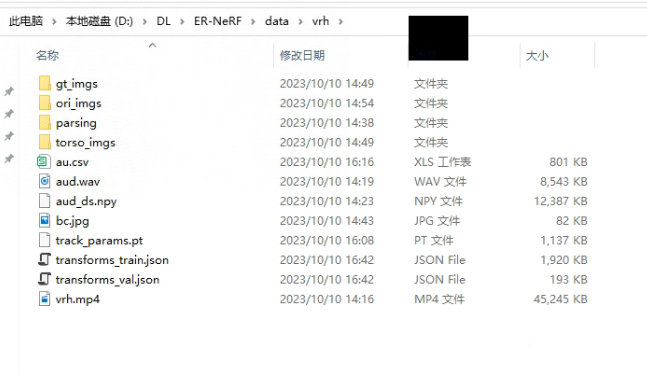
4.数据说明
处理完成之后,把OpenFace处理出来的眨眼数据复制到当前目录,重新命名成au.csv,把原本的aud.npy重新命名成aud_ds.npy,如果不想改数据,就改在代码里面改。
5.人像分割问题
当分步处理数据时,到第四步是人像分割,这个分割如果没有分割好,就会影响训练的效果,比如下面的图像,第一个下巴分割的位置不对,第二个地方是把白色的衣服错误的分割成背景了,这里可以借助别人工具进行分割,我这里Segment-and-Track Anything进行分割,效果会好很多,关于Segment-and-Track Anything可以看我之前的博客:Segment-and-Track Anything——通用智能视频分割、跟踪、编辑算法解读与源码部署

上面那张图像使用Segment-and-Track Anything分割出来的效果:

Segment-and-Track Anything分割出来的图像,要转换成模型所需要的数据格式,下面是我用来转的C++代码,可以用参考改自己的数据:
int main()
{
for (int i = 0; i < 3418; i++)
{
std::string name = "";
if (i < 10)
{
name = "tao6_masks/0000" + std::to_string(i) + ".png";
}
else if (i > 9 && i < 100)
{
name = "tao6_masks/000" + std::to_string(i) + ".png";
}
else if (i > 99 && i < 1000)
{
name = "tao6_masks/00" + std::to_string(i) + ".png";
}
else if (i > 999 && i < 10000)
{
name = "tao6_masks/0" + std::to_string(i) + ".png";
}
cv::Mat cv_src = cv::imread(name);
cv::Mat cv_seg(cv_src.size(), CV_8UC3, cv::Scalar(255, 255, 255));
cv::Mat cv_neck(cv_src.size(), CV_8UC3, cv::Scalar(0, 0, 0));
cv::Mat cv_body = cv_neck.clone();
cv::Mat cv_face = cv_neck.clone();
for (int i = 0; i < cv_src.rows; i++)
{
for (int j = 0; j < cv_src.cols; j++)
{
if (cv_src.at<cv::Vec3b>(i, j)[2] == 140 &&
cv_src.at<cv::Vec3b>(i, j)[1] == 238 &&
cv_src.at<cv::Vec3b>(i, j)[0] == 157)
{
cv_neck.at<cv::Vec3b>(i, j)[2] = 0;
cv_neck.at<cv::Vec3b>(i, j)[1] = 255;
cv_neck.at<cv::Vec3b>(i, j)[0] = 0;
}
}
}
cv::Mat element_n = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(7, 7));
morphologyEx(cv_neck, cv_neck, cv::MORPH_DILATE, element_n); //结果保存到自身
for (int i = 0; i < cv_neck.rows; i++)
{
for (int j = 0; j < cv_neck.cols; j++)
{
if (cv_neck.at<cv::Vec3b>(i, j)[2] == 0 &&
cv_neck.at<cv::Vec3b>(i, j)[1] == 255 &&
cv_neck.at<cv::Vec3b>(i, j)[0] == 0)
{
cv_seg.at<cv::Vec3b>(i, j)[2] = 0;
cv_seg.at<cv::Vec3b>(i, j)[1] = 255;
cv_seg.at<cv::Vec3b>(i, j)[0] = 0;
}
}
}
for (int i = 0; i < cv_src.rows; i++)
{
for (int j = 0; j < cv_src.cols; j++) {
if (cv_src.at<cv::Vec3b>(i, j)[2] == 152 &&
cv_src.at<cv::Vec3b>(i, j)[1] == 212 &&
cv_src.at<cv::Vec3b>(i, j)[0] == 77)
{
cv_body.at<cv::Vec3b>(i, j)[2] = 255;
cv_body.at<cv::Vec3b>(i, j)[1] = 0;
cv_body.at<cv::Vec3b>(i, j)[0] = 0;
}
}
}
cv::Mat element_b = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(7, 7));
cv::morphologyEx(cv_body, cv_body, cv::MORPH_DILATE, element_b);
cv::morphologyEx(cv_body, cv_body, cv::MORPH_OPEN, element_b);
for (int i = 0; i < cv_body.rows; i++)
{
for (int j = 0; j < cv_body.cols; j++) {
if (cv_body.at<cv::Vec3b>(i, j)[2] == 255 &&
cv_body.at<cv::Vec3b>(i, j)[1] == 0 &&
cv_body.at<cv::Vec3b>(i, j)[0] == 0)
{
cv_seg.at<cv::Vec3b>(i, j)[2] = 255;
cv_seg.at<cv::Vec3b>(i, j)[1] = 0;
cv_seg.at<cv::Vec3b>(i, j)[0] = 0;
}
}
}
for (int i = 0; i < cv_src.rows; i++)
{
for (int j = 0; j < cv_src.cols; j++)
{
if (cv_src.at<cv::Vec3b>(i, j)[2] == 251 &&
cv_src.at<cv::Vec3b>(i, j)[1] == 231 &&
cv_src.at<cv::Vec3b>(i, j)[0] == 252)
{
cv_face.at<cv::Vec3b>(i, j)[2] = 0;
cv_face.at<cv::Vec3b>(i, j)[1] = 0;
cv_face.at<cv::Vec3b>(i, j)[0] = 255;
}
}
}
cv::Mat element_f = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::morphologyEx(cv_face, cv_face, cv::MORPH_DILATE, element_f);
cv::morphologyEx(cv_face, cv_face, cv::MORPH_OPEN, element_b);
for (int i = 0; i < cv_face.rows; i++)
{
for (int j = 0; j < cv_face.cols; j++)
{
if (cv_face.at<cv::Vec3b>(i, j)[2] == 0 &&
cv_face.at<cv::Vec3b>(i, j)[1] == 0 &&
cv_face.at<cv::Vec3b>(i, j)[0] == 255)
{
cv_seg.at<cv::Vec3b>(i, j)[2] = 0;
cv_seg.at<cv::Vec3b>(i, j)[1] = 0;
cv_seg.at<cv::Vec3b>(i, j)[0] = 255;
}
}
}
cv::imwrite("mask/" + std::to_string(i) + ".png", cv_seg);
/*cv::imshow("src", cv_neck);
cv::imshow("seg", cv_seg);
cv::waitKey();*/
}
}
三、模型训练
1.头部训练
python main.py data/vrh/ --workspace trial_vrh/ -O --iters 100000
这步训练完成之后,

2.微调嘴型动作
python main.py data/vrh/ --workspace trial_vrh/ -O --iters 125000 --finetune_lips --patch_size 32
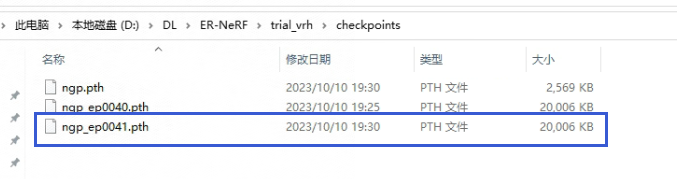
运行完成之后,会保存最后的一个模型,这个模型下一步训练身体时用到:
3.训练身体
训练身体时,导入上一步生成的头部模型,模型路径和名称按项目按自己环境生成的结果来写:
python main.py data/vrh/ --workspace trial_vrh_torso/ -O --torso --head_ckpt trial_vrh/ngp_ep0041.pth --iters 200000
下面的模型就是我们最终需要的模型:

四、测试项目
1.测试
python main.py data/vrh/ --workspace trial_vrh/ -O --test
python main.py data/vrh/ --workspace trial_vrh_torso/ -O --torso --test
2.使用音频进行推理
这里要提取音频的特征才能进行推理,提取特征可以参考数据处理第二步:
python main.py data/vrh/ --workspace trial_vrh_torso/ -O --torso --test --test_train --aud <audio>.npy
五、常见错误
pytorch3d安装时常见错误
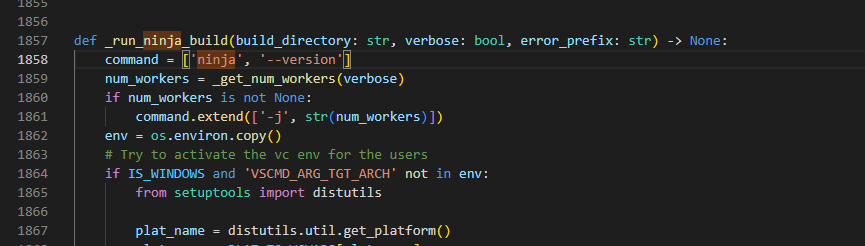
subprocess.CalledProcessError: Command ‘[‘ninja’, ‘-v’]’ returned non-zero exit status 1.
出现这个错误时,找到dist-packages/torch/utils/cpp_extension.py这个文件,找到command = [‘ninja’, ‘-v’],改成 command = [‘ninja’, ‘–version’],改了效果如下:
# command = ['ninja', '-v']
command = ['ninja', '--version']
AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’
把cuda改成11.7就可以解决这个错误。



















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











